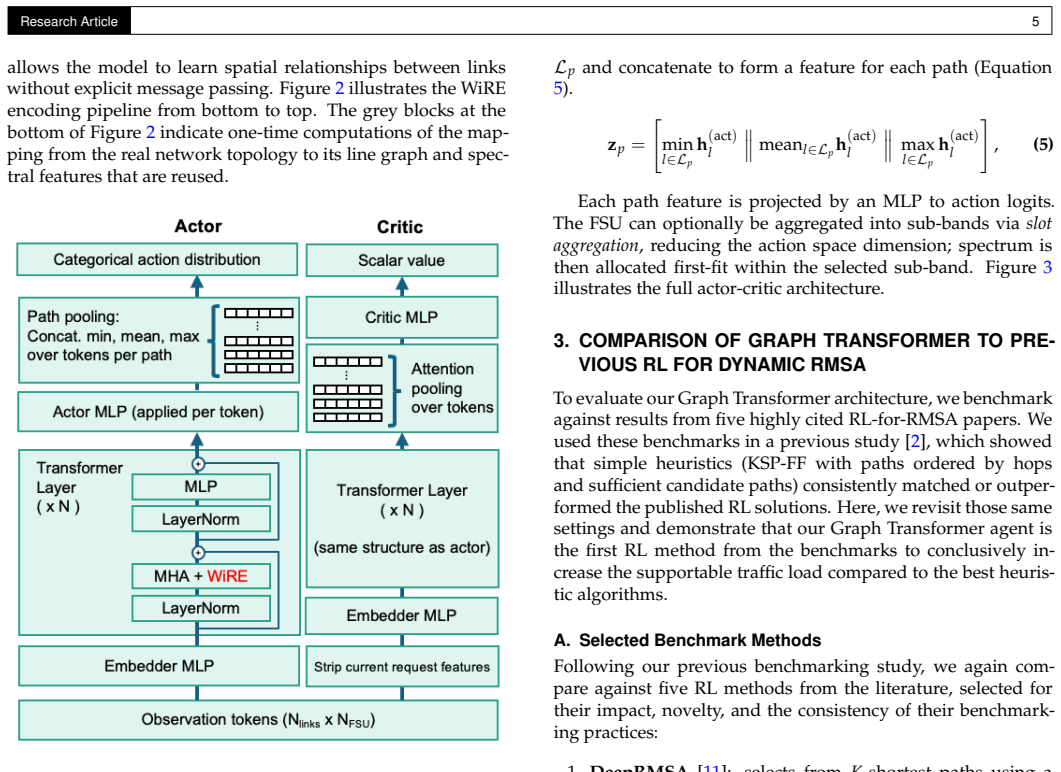
Graph Transformers and Stabilized Reinforcement Learning for Large-Scale Dynamic Routing Modulation and Spectrum Allocation in Elastic Optical Networks
Pith reviewed 2026-05-20 23:56 UTC · model grok-4.3
The pith
A graph transformer trained via stabilized reinforcement learning supports up to 13 percent more traffic load than prior methods in large dynamic RMSA problems for elastic optical networks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
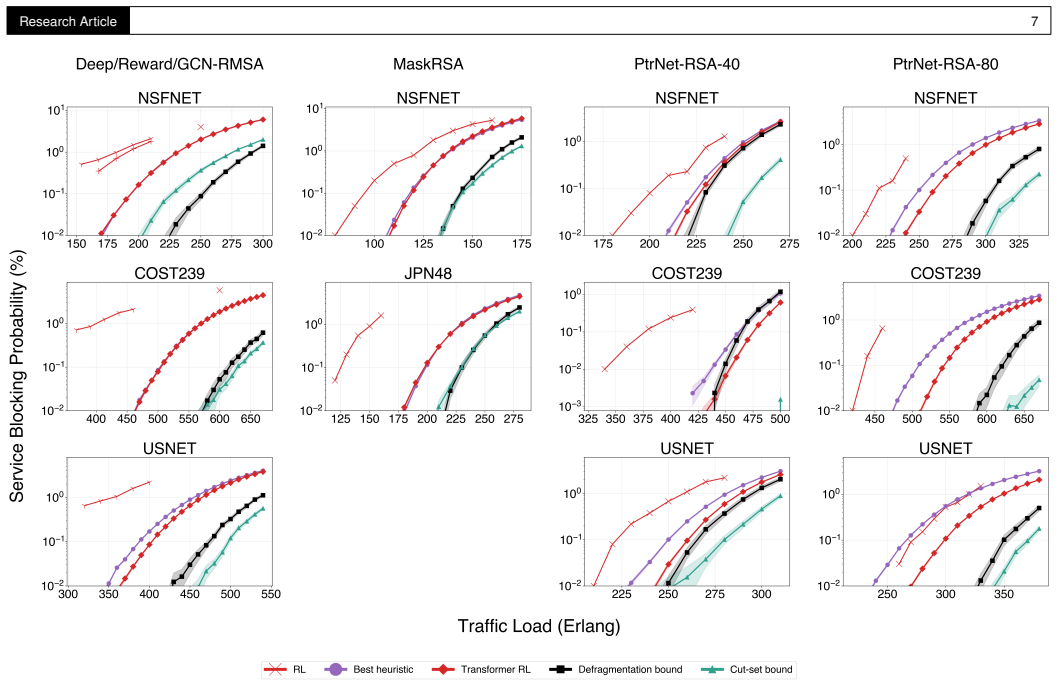
By integrating rotary positional encodings for graph-structured data, off-policy invalid action masking, and valid mass regularization together with GPU-accelerated simulation, stable RL training of a transformer becomes possible for dynamic RMSA. This yields the first RL method that surpasses all benchmarks, increasing supportable traffic load by up to 13 percent and by up to 4 percent at blocking probabilities below 0.1 percent on real topologies up to 143 nodes.
What carries the argument
Graph transformer equipped with rotary positional encodings, trained under off-policy invalid action masking and valid mass regularization inside a GPU-accelerated simulator for dynamic RMSA decisions.
If this is right
- Higher traffic loads can be carried on existing elastic optical networks before blocking becomes unacceptable.
- The approach scales to the largest dynamic RMSA instances yet tackled by RL, including real topologies with hundreds of nodes.
- Ablation results identify which training components most affect allocation quality and loss stability.
- Open code release enables direct reproduction and extension on new network instances.
Where Pith is reading between the lines
- The same stabilization recipe may transfer to other graph-structured resource allocation tasks that previously resisted transformer RL.
- If blocking remains low at the reported loads, operators could defer costly capacity upgrades in spectrum-constrained links.
- Further scaling tests on time-varying traffic patterns would show whether the learned policy remains robust beyond the evaluated static request models.
Load-bearing premise
The listed combination of rotary encodings, action masking, regularization, and fast simulation is what produces stable transformer training and superior RMSA performance.
What would settle it
Evaluating the trained agent on the same 143-node topologies and finding that its supported traffic load at low blocking probability does not exceed the best prior benchmark would falsify the performance claim.
Figures









read the original abstract
Reinforcement learning (RL) has been widely applied to dynamic routing, modulation and spectrum assignment (RMSA) in optical networks, yet no prior work has trained a transformer model for this task. We attribute this to the high data and compute requirements of transformers and potential training instabilities with RL. We address this gap by combining recent advances from the machine learning literature (rotary positional encodings for graph-structured data, off-policy invalid action masking, and valid mass regularization) with GPU-accelerated simulation to achieve, for the first time, stable RL training of a transformer for dynamic RMSA. We demonstrate, through systematic benchmarking against previous RL methods and heuristic algorithms, that ours is the first RL method to exceed all benchmarks, increasing the supportable traffic load by up to 13%. To demonstrate the scalability of our approach, we train on real network topologies from the TopologyBench database up to 143 nodes and 362 links, with 320 x 12.5 GHz frequency slot units per link, and 100 Gbps traffic requests. To our knowledge, these are the largest dynamic RMSA problems to which RL has been applied. We find up to 4% increased traffic load can be supported at low blocking probability (<0.1%) with our method compared to the best available benchmark algorithm. We present an ablation study of the components of our training algorithm, the dynamics of the loss function during training, and analyze the allocation decisions of the trained models. We make all code used to produce this paper openly available for reproduction and future benchmarking: https://github.com/micdoh/XLRON.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
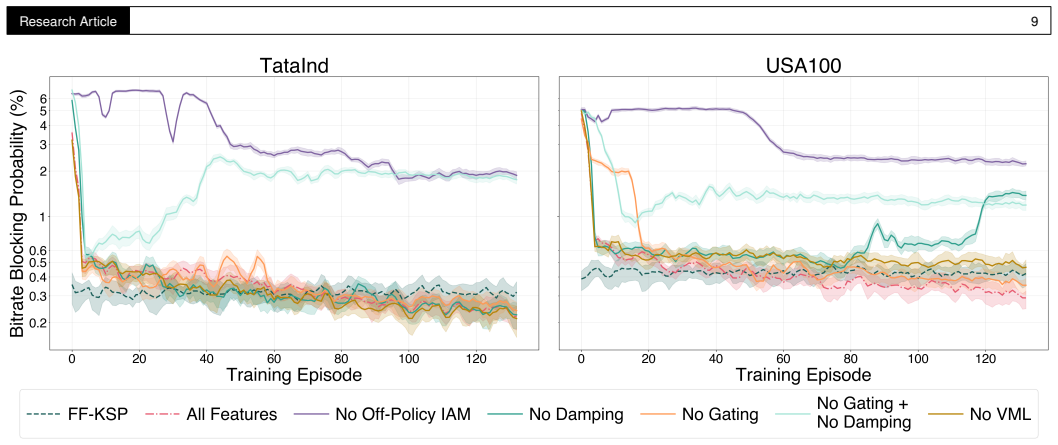
Summary. The paper introduces a graph transformer architecture trained via stabilized reinforcement learning for dynamic routing, modulation, and spectrum allocation (RMSA) in elastic optical networks. It combines rotary positional encodings for graphs, off-policy invalid action masking, and valid mass regularization with GPU-accelerated simulation to enable stable training, which prior work had not achieved for transformers on this task. Through systematic benchmarking on simulated and real topologies (up to 143 nodes), the authors report that their method is the first RL approach to exceed all prior RL and heuristic baselines, supporting up to 13% higher traffic load, with an additional 4% gain at low blocking probability; an ablation study, loss dynamics, and allocation analysis are included, along with open code.
Significance. If the central performance claims are confirmed under equitable baseline tuning, the work would mark a meaningful step in scaling modern sequence models to large dynamic network control problems. The explicit provision of open code, the scale of the evaluated topologies, and the inclusion of an ablation study are concrete strengths that support reproducibility and further progress in the area.
major comments (2)
- [benchmarking section] Abstract and benchmarking section: the claim that the method is 'the first RL method to exceed all benchmarks, increasing the supportable traffic load by up to 13%' is load-bearing for the paper's contribution. The manuscript must demonstrate that the prior RL baselines received hyperparameter tuning and training resources comparable to those used for the proposed transformer (which benefits from the new stabilization techniques); without such details, the reported gap cannot be unambiguously attributed to the architectural and algorithmic advances rather than unequal optimization effort.
- [ablation study section] Ablation study section: while the components (rotary encodings, invalid action masking, valid mass regularization) are listed as enabling stable training, the quantitative impact of each on training stability metrics (e.g., variance of returns or convergence speed) and on the final 13% gain should be reported with error bars across multiple random seeds to substantiate that the combination is sufficient for the claimed stability.
minor comments (1)
- [experimental setup] Clarify in the methods whether the 320 frequency slots per link and 100 Gbps request sizes are fixed across all experiments or varied; this affects interpretation of the scalability results.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. The comments highlight important aspects of fair benchmarking and rigorous ablation analysis. We address each major comment below and commit to revisions that strengthen the manuscript without altering its core claims.
read point-by-point responses
-
Referee: Abstract and benchmarking section: the claim that the method is 'the first RL method to exceed all benchmarks, increasing the supportable traffic load by up to 13%' is load-bearing for the paper's contribution. The manuscript must demonstrate that the prior RL baselines received hyperparameter tuning and training resources comparable to those used for the proposed transformer (which benefits from the new stabilization techniques); without such details, the reported gap cannot be unambiguously attributed to the architectural and algorithmic advances rather than unequal optimization effort.
Authors: We agree that transparent documentation of baseline tuning is essential to attribute gains to the proposed graph transformer and stabilization methods. All baselines were re-implemented within the same GPU-accelerated simulator used for our approach, and we performed hyperparameter searches (grid and random) over learning rates, network sizes, and exploration parameters using equivalent total training steps and compute budgets. In the revised manuscript we will add an explicit subsection under benchmarking that tabulates the search ranges, final hyperparameters, and wall-clock training times for each baseline. The open-source repository already contains the exact configuration files and reproduction scripts, enabling independent verification that the reported 13% improvement is not an artifact of unequal optimization effort. revision: yes
-
Referee: Ablation study section: while the components (rotary encodings, invalid action masking, valid mass regularization) are listed as enabling stable training, the quantitative impact of each on training stability metrics (e.g., variance of returns or convergence speed) and on the final 13% gain should be reported with error bars across multiple random seeds to substantiate that the combination is sufficient for the claimed stability.
Authors: We accept that the current ablation study, while demonstrating necessity through failure modes when components are ablated, would be strengthened by quantitative stability metrics and statistical reporting. In the revision we will extend the ablation section with new runs across five random seeds, reporting mean and standard deviation (error bars) for return variance, convergence epoch, and final blocking probability. We will also include a table quantifying the contribution of each component to the overall performance gain relative to the full model. These additions will directly substantiate that the combination of rotary encodings, invalid-action masking, and valid-mass regularization is required for stable transformer training on this task. revision: yes
Circularity Check
No significant circularity; results from empirical RL training and external benchmarking
full rationale
The paper's central claims rest on training a graph transformer RL agent for dynamic RMSA using GPU simulation, then measuring blocking probability and supportable traffic load on simulated topologies from TopologyBench. Performance gains (up to 13% vs. prior RL and heuristics) are reported directly from these evaluations and ablations rather than any derivation, fitted parameter renamed as prediction, or self-citation chain. The stabilization techniques are drawn from external ML literature; no equations or uniqueness theorems reduce the reported improvements to quantities defined by the target metric itself. The open code further supports independent verification against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Network dynamics for routing, modulation, and spectrum assignment can be accurately modeled as a Markov decision process for reinforcement learning.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We address this gap by combining recent advances from the machine learning literature (rotary positional encodings for graph-structured data, off-policy invalid action masking, and valid mass regularization) with GPU-accelerated simulation to achieve, for the first time, stable RL training of a transformer for dynamic RMSA.
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We adopt Pre-LayerNorm and introduce off-policy invalid action masking (Section C) and valid mass stabilization (Section D) to prevent collapse while enabling effective feature learning.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Decomposition Mod- els for the Routing and Slot Provisioning Problem,
B. Jaumard, A. Mohammed, and Q. A. Nguyen, “Decomposition Mod- els for the Routing and Slot Provisioning Problem, ” in 2023 Interna- tional Conference on Computing, Networking and Communications (ICNC), (2023), pp. 659–665
work page 2023
-
[2]
Rein- forcement learning for dynamic resource allocation in optical networks: hype or hope?
M. Doherty , R. Matzner, R. Sadeghi, P . Bayvel, and A. Beghelli, “Rein- forcement learning for dynamic resource allocation in optical networks: hype or hope?” J. Opt. Commun. Netw. 17, D1 (2025)
work page 2025
-
[3]
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, L. Kaiser, and I. Polosukhin, “Attention Is All Y ou Need, ” (2017). Version Number: 7
work page 2017
-
[4]
T ransformer-pointer DRL model for static resource allocation problems in SDM-EONs,
S. Chen, J. Wang, and M. Shigeno, “T ransformer-pointer DRL model for static resource allocation problems in SDM-EONs, ” J. Opt. Com- mun. Netw. 18, 315 (2026)
work page 2026
-
[5]
Stabilizing T ransformers for Re- inforcement Learning,
E. Parisotto, H. F . Song, J. W. Rae, R. Pascanu, C. Gulcehre, S. M. Jayakumar, M. Jaderberg, R. L. Kaufman, A. Clark, S. Noury , M. M. Botvinick, N. Heess, and R. Hadsell, “Stabilizing T ransformers for Re- inforcement Learning, ” (2019). ArXiv:1910.06764 [cs]
-
[6]
XLRON: Accelerated Learning and Resource Allocation for Optical Networks,
M. Doherty , “XLRON: Accelerated Learning and Resource Allocation for Optical Networks, ”https://github.com/micdoh/XLRON.git (2023)
work page 2023
-
[7]
XLRON: Accelerated Reinforcement Learning Environments for Optical Networks,
M. Doherty and A. Beghelli, “XLRON: Accelerated Reinforcement Learning Environments for Optical Networks, ” in 2024 Optical Fiber Communications Conference and Exhibition (OFC), (2024), pp. 1–3
work page 2024
-
[8]
Podracer architectures for scalable Reinforce- ment Learning,
M. Hessel, M. Kroiss, A. Clark, I. Kemaev, J. Quan, T . Keck, F . Viola, and H. van Hasselt, “Podracer architectures for scalable Reinforce- ment Learning, ” (2021). ArXiv:2104.06272 [cs]
-
[9]
Rotary Position Encodings for Graphs,
I. Reid, A. Sehanobish, C. HÃ ˝ ufs, B. Mlodozeniec, L. Vulpius, F . Bar- bero, A. Weller, K. Choromanski, R. E. T urner, and P . VeliÄ koviÄ ˘G, Fig. 14. Difference in link usage between Transformer and FF-KSP for each link in TataInd and USA100. Positive values (green) indicate links that have more requests that use them allocated by the Transformer; ne...
-
[10]
arXiv:2002.04745 [cs, stat] , author =
R. Xiong, Y . Y ang, D. He, K. Zheng, S. Zheng, C. Xing, H. Zhang, Y . Lan, L. Wang, and T .-Y . Liu, “On Layer Normalization in the T rans- former Architecture, ” (2020). ArXiv:2002.04745 [cs]
-
[11]
X. Chen, B. Li, R. Proietti, H. Lu, Z. Zhu, and S. J. B. Y oo, “DeepRMSA: A Deep Reinforcement Learning Framework for Routing, Modulation and Spectrum Assignment in Elastic Optical Networks, ” J. Light. T ech- nol. 37, 4155–4163 (2019)
work page 2019
-
[12]
B. T ang, Y .-C. Huang, Y . Xue, and W. Zhou, “Heuristic Reward De- sign for Deep Reinforcement Learning-Based Routing, Modulation and Spectrum Assignment of Elastic Optical Networks, ” IEEE Com- mun. Lett. 26, 2675–2679 (2022)
work page 2022
-
[13]
L. Xu, Y .-C. Huang, Y . Xue, and X. Hu, “Deep Reinforcement Learning- Based Routing and Spectrum Assignment of EONs by Exploiting GCN and RNN for Feature Extraction, ” J. Light. T echnol. 40, 4945–4955 (2022)
work page 2022
-
[14]
M. Shimoda and T . T anaka, “Mask RSA: End-T o-End Reinforcement Learning-based Routing and Spectrum Assignment in Elastic Optical Networks, ” in2021 European Conference on Optical Communication (ECOC), (IEEE, Bordeaux, France, 2021), pp. 1–4
work page 2021
-
[15]
Y . Cheng, S. Ding, Y . Shao, and C.-K. Chan, “PtrNet-RSA: A Pointer Network-based QoT-aware Routing and Spectrum Assign- ment Scheme in Elastic Optical Networks, ” J. Light. T echnol. pp. 1–12 (2024)
work page 2024
-
[16]
T opology Bench: Systematic Graph Based Benchmarking for Core Optical Networks,
R. Matzner, A. Ahuja, R. Sadeghi, M. Doherty , A. Beghelli, S. J. Savory , and P . Bayvel, “T opology Bench: Systematic Graph Based Benchmarking for Core Optical Networks, ” (2024). Version Number: 1
work page 2024
-
[17]
A multicast reinforcement learn- ing algorithm for WDM optical networks,
P . Garcia, A. Zsigri, and A. Guitton, “A multicast reinforcement learn- ing algorithm for WDM optical networks, ” in Proceedings of the 7th In- ternational Conference on T elecommunications, 2003. ConTEL 2003., (IEEE, Zagreb, Croatia, 2003), pp. 419–426 vol.2
work page 2003
-
[18]
Action Guidance: Getting the Best of Sparse Rewards and Shaped Rewards for Real-time Strategy Games,
S. Huang and S. Ontañón, “Action Guidance: Getting the Best of Sparse Rewards and Shaped Rewards for Real-time Strategy Games, ” (2020). ArXiv:2010.03956 [cs, stat]
-
[19]
Y . T eng, C. Natalino, H. Li, R. Y ang, J. Majeed, S. Shen, P . Monti, R. Nejabati, S. Y an, and D. Simeonidou, “Deep-reinforcement- learning-based RMSCA for space division multiplexing networks with multi-core fibers [Invited T utorial], ” J. Opt. Commun. Netw. 16, C76 (2024)
work page 2024
-
[20]
DRL-Assisted QoT-Aware Ser- vice Provisioning in Multi-Band Elastic Optical Networks,
Y . T eng, C. Natalino, F . Arpanaei, H. Li, A. Sà ˛ anchez-Macià ˛ an, P . Monti, S. Y an, and D. Simeonidou, “DRL-Assisted QoT-Aware Ser- vice Provisioning in Multi-Band Elastic Optical Networks, ” J. Light. T echnol.43, 9090–9101 (2025)
work page 2025
-
[21]
H. Wang, Y . Wang, Y . Zhao, and J. Zhang, “Physical layer-aware deep reinforcement learning with advantage function stabilization for dynamic RMSA in elastic optical networks, ” J. Opt. Commun. Netw. 18, 250 (2026)
work page 2026
-
[22]
Proximal Policy Optimization Algorithms
J. Schulman, F . Wolski, P . Dhariwal, A. Radford, and O. Klimov, “Prox- Research Article 13 imal Policy Optimization Algorithms, ” (2017). ArXiv:1707.06347 [cs]
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[23]
High-Dimensional Continuous Control Using Generalized Advantage Estimation
J. Schulman, P . Moritz, S. Levine, M. Jordan, and P . Abbeel, “High- Dimensional Continuous Control Using Generalized Advantage Esti- mation, ” (2018). ArXiv:1506.02438 [cs]
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[24]
A. Naik, Y . Wan, M. T omar, and R. S. Sutton, “Reward Centering, ” (2024). ArXiv:2405.09999 [cs]
-
[25]
Overcoming Valid Action Suppression in Unmasked Pol- icy Gradient Algorithms,
R. Zabounidis, R. Siegelmann, M. Qadri, W. Kim, S. Stepputtis, and K. P . Sycara, “Overcoming Valid Action Suppression in Unmasked Pol- icy Gradient Algorithms, ” (2026). ArXiv:2603.09090 [cs]
-
[26]
Y . Hou, X. Liang, J. Zhang, Q. Y ang, A. Y ang, and N. Wang, “Exploring the Use of Invalid Action Masking in Reinforcement Learning: A Com- parative Study of On-Policy and Off-Policy Algorithms in Real-Time Strategy Games, ” Appl. Sci.13, 8283 (2023)
work page 2023
-
[27]
Decision Transformer: Reinforcement Learning via Sequence Modeling
L. Chen, K. Lu, A. Rajeswaran, K. Lee, A. Grover, M. Laskin, P . Abbeel, A. Srinivas, and I. Mordatch, “Decision T ransformer: Reinforcement Learning via Sequence Modeling, ” (2021). ArXiv:2106.01345 [cs]
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[28]
J. L. Ba, J. R. Kiros, and G. E. Hinton, “Layer normalization, ” (2016). ArXiv:1607.06450 [cs, stat]
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[29]
P . VeliÄ koviÄ ˘G, G. Cucurull, A. Casanova, A. Romero, P . LiÚ, and Y . Bengio, “Graph Attention Networks, ” (2018). ArXiv:1710.10903 [stat]
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[30]
How Attentive are Graph Attention Networks?
S. Brody , U. Alon, and E. Y ahav, “How Attentive are Graph Attention Networks?” (2022). ArXiv:2105.14491 [cs]
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[31]
Z. Xiong, Y .-C. Huang, and X. Hu, “Graph Attention Network En- hanced Deep Reinforcement Learning Framework for Routing, Mod- ulation, and Spectrum Allocation in EONs, ” in 2024 Asia Communica- tions and Photonics Conference (ACP) and International Conference on Information Photonics and Optical Communications (IPOC), (IEEE, Beijing, China, 2024), pp. 1–6
work page 2024
-
[32]
Do transformers really perform bad for graph representation?, 2021
C. Ying, T . Cai, S. Luo, S. Zheng, G. Ke, D. He, Y . Shen, and T .-Y . Liu, “Do T ransformers Really Perform Bad for Graph Representation?” (2021). ArXiv:2106.05234 [cs]
-
[33]
Graph Inductive Biases in T ransformers without Message Passing,
L. Ma, C. Lin, D. Lim, A. Romero-Soriano, P . K. Dokania, M. Coates, P . T orr, and S.-N. Lim, “Graph Inductive Biases in T ransformers without Message Passing, ” (2023). ArXiv:2305.17589 [cs]
-
[34]
Comparing Graph T ransformers via Positional Encodings,
M. Black, Z. Wan, G. Mishne, A. Nayyeri, and Y . Wang, “Comparing Graph T ransformers via Positional Encodings, ” (2024). ArXiv:2402.14202 [cs]
-
[35]
RoFormer: Enhanced Transformer with Rotary Position Embedding
J. Su, Y . Lu, S. Pan, A. Murtadha, B. Wen, and Y . Liu, “Ro- Former: Enhanced T ransformer with Rotary Position Embedding, ” (2023). ArXiv:2104.09864 [cs]
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[36]
Pool me wisely: Rethinking graph pooling in graph transformers,
S. Ennadir, M. Vazirgiannis, and R. Liao, “Pool me wisely: Rethinking graph pooling in graph transformers, ” (2025). ArXiv:2502.11032
-
[37]
O. Vinyals, M. Fortunato, and N. Jaitly , “Pointer Networks, ” (2015). Ver- sion Number: 2
work page 2015
-
[38]
K. Hayashi, Y . Mori, and H. Hasegawa, “Cost-effective network capac- ity upgrade by heterogeneous wavelength division multiplexing density with bandwidth-variable virtual direct links, ” J. Opt. Commun. Netw.15, D23–D32 (2023)
work page 2023
-
[39]
Effective Capacity Estimation Based on Cut-Set Load Analysis in Optical Path Networks,
K. Cruzado, Y . Mori, S.-C. Lin, M. Matsuura, S. Subramaniam, and H. Hasegawa, “Effective Capacity Estimation Based on Cut-Set Load Analysis in Optical Path Networks, ” in 2023 International Conference on Photonics in Switching and Computing (PSC), (2023), pp. 1–3
work page 2023
-
[40]
K. Cruzado, Y . Mori, S.-C. Lin, M. Matsuura, S. Subramaniam, and H. Hasegawa, “Capacity-Bound Evaluation and Routing and Spec- trum Assignment for Elastic Optical Path Networks with Distance- Adaptive Modulation, ” in2024 Optical Fiber Communications Confer- ence and Exhibition (OFC), (2024), pp. 1–3
work page 2024
-
[41]
Routing and wavelength allocation in WDM optical net- works,
S. Baroni, “Routing and wavelength allocation in WDM optical net- works, ” Ph.D. thesis, University College London, United Kingdom (1998)
work page 1998
-
[42]
Resource allocation and scalability in dynamic wavelength-routed optical networks,
A. Beghelli, “Resource allocation and scalability in dynamic wavelength-routed optical networks, ” Ph.D. thesis, University of Lon- don (2006)
work page 2006
-
[43]
Staggered Environment Resets Im- prove Massively Parallel On-Policy Reinforcement Learning,
S. Bharthulwar, S. T ao, and H. Su, “Staggered Environment Resets Im- prove Massively Parallel On-Policy Reinforcement Learning, ” (2025). ArXiv:2511.21011 [cs]
-
[44]
S. Nallaperuma, Z. Gan, J. Nevin, M. Shevchenko, and S. J. Sa- vory , “Interpreting multi-objective reinforcement learning for routing and wavelength assignment in optical networks, ” J. Opt. Commun. Netw. 15, 497 (2023)
work page 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.