HDSL: A Hierarchical Domain-Specific Language for Structured 3D Indoor Scene Generation and Localized Editing with LLM Agents
Pith reviewed 2026-06-27 17:11 UTC · model grok-4.3
The pith
HDSL is a hierarchical XML-style language that lets LLM agents generate 3D indoor scenes as trees and perform localized edits by rewriting only the relevant subtree.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
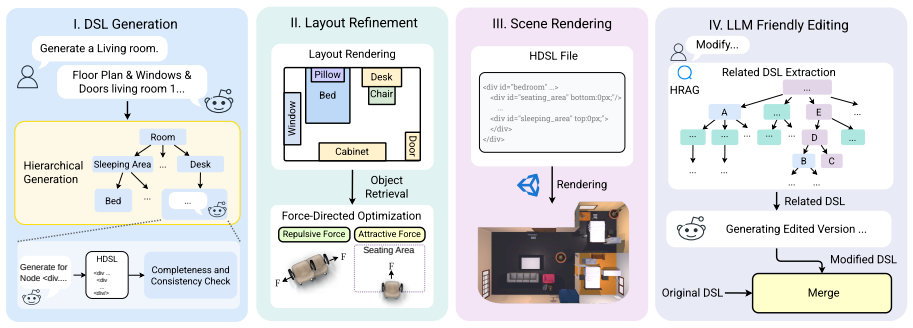
HDSL represents indoor scenes as a tree of rooms, regions, objects, and support surfaces using local coordinates in an XML/CSS-style syntax; LLM agents generate valid subtrees under bounded verification, non-virtual nodes are grounded by multimodal retrieval, boundary and collision errors are repaired by force-directed layout, and edits are performed by retrieving the relevant subtree, rewriting only that local context, and merging the result back through a deterministic three-way merge.
What carries the argument
HDSL, the tree-structured DSL with local coordinates that turns scene generation into recursive subtree production and editing into isolated subtree repair plus deterministic merge.
If this is right
- Average object coverage rises compared with full text-to-scene baselines.
- Text-scene alignment and generation time both improve.
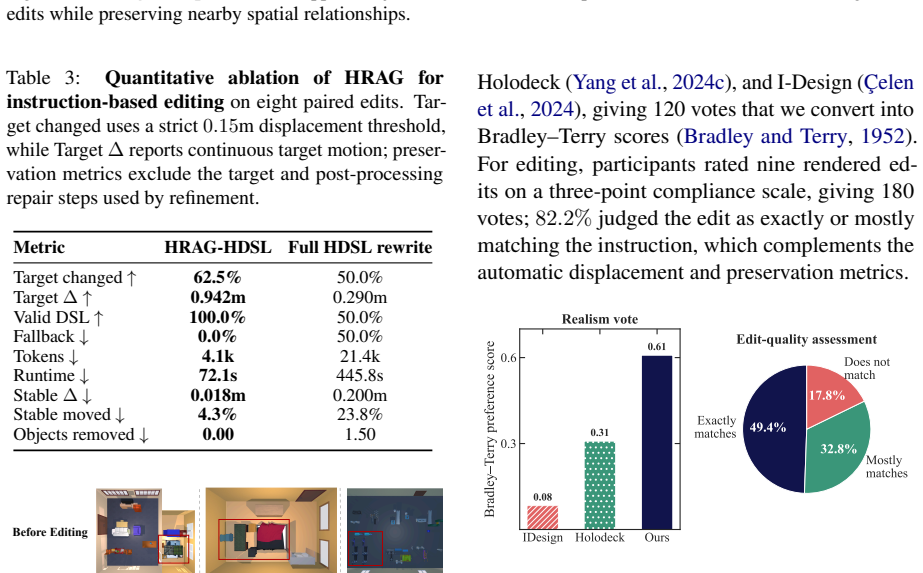
- HRAG cuts token consumption by 5.22 times and runtime by 6.19 times on editing tasks.
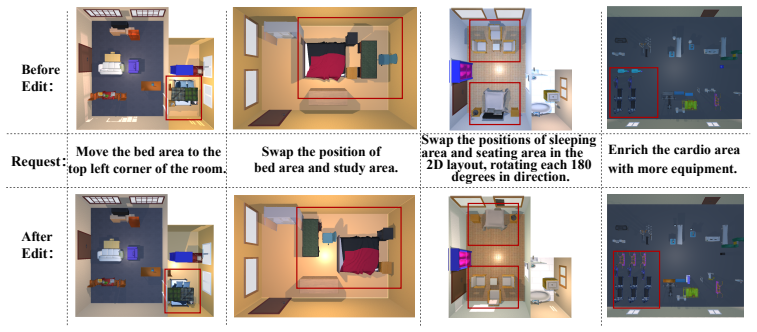
- All eight tested paired edits yield valid DSL output while leaving unrelated scene objects unchanged.
- Geometry metrics stay competitive with recent layout-only reproduction methods.
Where Pith is reading between the lines
- The tree representation could let users iterate on large scenes by editing one region at a time rather than regenerating the entire model.
- The same subtree-generation-plus-merge pattern might transfer to other structured outputs such as floor plans or furniture assemblies.
- Because verification is bounded, the method may scale to longer prompts by decomposing them into independent subtrees that are later assembled.
Load-bearing premise
LLM agents can reliably produce and repair valid HDSL subtrees under bounded verification, and asset retrieval plus force-directed optimization can ground and fix the scenes without creating new structural problems.
What would settle it
A benchmark run in which LLM-generated HDSL subtrees for complex rooms repeatedly fail verification or produce collisions that force-directed optimization cannot resolve without breaking the tree structure.
Figures







read the original abstract
Text-driven indoor scene generation and editing require an intermediate representation that language models can both produce and revise. Existing LLM-based systems often rely on scene graphs or global constraint lists, which are compact but underspecify local geometry and make instruction-based edits difficult to localize. We frame this problem as structured program generation and local program repair, and propose Hierarchical Descriptive Scene Language (HDSL), an XML/CSS-style domain-specific language for structured 3D indoor scenes. HDSL represents rooms, regions, objects, and support surfaces as a tree with local coordinates, making complex scenes easier to plan recursively and easier to retrieve for editing. Our pipeline uses LLM agents to generate HDSL subtrees with bounded verification, grounds non-virtual nodes through multimodal asset retrieval, and applies force-directed layout optimization to repair boundary and collision errors. For editing, Hierarchical Retrieval-Augmented Generation retrieves the relevant subtree, asks the LLM to rewrite only that local context, and merges the result back through a deterministic three-way merge. In our reproduced benchmark, HDSL improves average object coverage, text-scene alignment, and generation time over full text-to-scene baselines while remaining competitive with recent layout-only reproductions on geometry metrics; for editing, HRAG reduces token use by $5.22\times$ and runtime by $6.19\times$, produces valid DSL for all eight paired edits, and better preserves unrelated scene objects.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Hierarchical Descriptive Scene Language (HDSL), an XML/CSS-style domain-specific language for structured 3D indoor scene representation as hierarchical trees with local coordinates. It presents a pipeline where LLM agents generate HDSL subtrees with bounded verification, ground objects via multimodal retrieval, and use force-directed optimization for layout repair. For editing, Hierarchical Retrieval-Augmented Generation (HRAG) enables localized subtree retrieval, LLM rewriting, and deterministic merge. The authors claim that in a reproduced benchmark, HDSL outperforms full text-to-scene baselines in object coverage, text-scene alignment, and generation time, while being competitive on geometry metrics, and that HRAG achieves 5.22× token reduction, 6.19× runtime reduction, valid DSL for all eight edits, and better preservation of unrelated objects.
Significance. If the reported results hold after proper experimental documentation, the work supplies a structured intermediate representation that supports recursive planning and localized editing for LLM-based 3D scene tasks. The hierarchical DSL and HRAG mechanism directly target the localization and editability shortcomings of scene graphs and global constraints, offering a practical advance for controllable text-to-3D synthesis. The explicit design for bounded verification and deterministic merge is a methodological strength.
major comments (3)
- [Abstract] Abstract: the quantitative claims of improvements in object coverage, text-scene alignment, generation time, and editing metrics (5.22× token use, 6.19× runtime) rest on a 'reproduced benchmark' but supply no dataset size, statistical tests, baseline implementation details, or error analysis. This information is load-bearing for assessing whether the central empirical claims are supported.
- [§4 (Experiments)] §4 (Experiments): the pipeline's reliance on LLM agents reliably producing valid HDSL subtrees under bounded verification and on force-directed optimization correcting collisions without new structural errors lacks supporting ablation studies or failure-mode analysis, leaving the weakest assumption untested in the reported results.
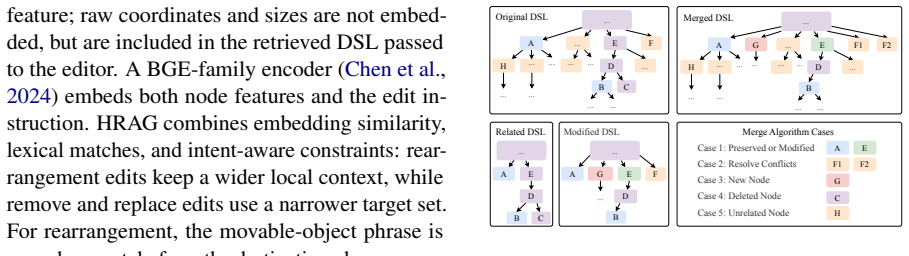
- [§3.2 (HRAG editing)] §3.2 (HRAG editing): the deterministic three-way merge is asserted to preserve unrelated objects, yet the manuscript provides no concrete specification of conflict resolution rules or merge invariants, making it impossible to verify the claim that all eight paired edits succeed while maintaining scene integrity.
minor comments (2)
- [§2 (HDSL Definition)] The HDSL syntax examples would benefit from a compact formal grammar or BNF fragment in the main text to clarify the tree structure and local coordinate rules.
- [Figures] Figure captions for editing results should explicitly label which objects were modified versus preserved to make the preservation claim visually verifiable.
Simulated Author's Rebuttal
We thank the referee for the thorough review and positive assessment of the significance of our work on HDSL and HRAG. We provide point-by-point responses to the major comments and commit to revisions that address the concerns regarding experimental documentation and technical specifications.
read point-by-point responses
-
Referee: [Abstract] Abstract: the quantitative claims of improvements in object coverage, text-scene alignment, generation time, and editing metrics (5.22× token use, 6.19× runtime) rest on a 'reproduced benchmark' but supply no dataset size, statistical tests, baseline implementation details, or error analysis. This information is load-bearing for assessing whether the central empirical claims are supported.
Authors: We agree that the abstract would benefit from additional context on the experimental setup to make the claims more self-contained. In the revised version, we will include the dataset size (number of test scenes in the reproduced benchmark), note the use of paired t-tests or similar for statistical significance, provide brief details on baseline reproductions, and mention that error analysis is detailed in §4. This will strengthen the abstract without altering the reported results. revision: yes
-
Referee: [§4 (Experiments)] §4 (Experiments): the pipeline's reliance on LLM agents reliably producing valid HDSL subtrees under bounded verification and on force-directed optimization correcting collisions without new structural errors lacks supporting ablation studies or failure-mode analysis, leaving the weakest assumption untested in the reported results.
Authors: We acknowledge the value of ablation studies for validating the core assumptions. While the current results demonstrate overall performance improvements, we will add an ablation study in the revised manuscript examining the impact of bounded verification on HDSL validity rates and the effect of force-directed optimization on collision resolution without introducing new errors. Failure modes will be analyzed based on cases where verification bounds were reached or optimization iterations exceeded thresholds. revision: yes
-
Referee: [§3.2 (HRAG editing)] §3.2 (HRAG editing): the deterministic three-way merge is asserted to preserve unrelated objects, yet the manuscript provides no concrete specification of conflict resolution rules or merge invariants, making it impossible to verify the claim that all eight paired edits succeed while maintaining scene integrity.
Authors: We agree that a concrete specification of the merge procedure is necessary for reproducibility and verification. In the revision, we will expand §3.2 with a detailed description of the three-way merge algorithm, including conflict resolution rules (e.g., priority to the edited subtree for overlapping nodes) and the invariants maintained (e.g., tree structure preservation and local coordinate consistency). This will allow readers to verify the success on the eight edits. revision: yes
Circularity Check
No significant circularity
full rationale
The paper introduces an original DSL (HDSL) and a pipeline of LLM-based subtree generation, multimodal retrieval, force-directed optimization, and hierarchical RAG for editing. All reported improvements (object coverage, alignment, token/runtime reductions) are empirical comparisons against external baselines on a reproduced benchmark. No equations, fitted parameters renamed as predictions, or load-bearing self-citations appear in the abstract or described derivation; the central claims rest on experimental outcomes rather than reducing to inputs by construction. This is the common case of a self-contained empirical contribution.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption LLM agents can generate and repair structured HDSL subtrees with bounded verification
invented entities (2)
-
HDSL
no independent evidence
-
HRAG
no independent evidence
Reference graph
Works this paper leans on
-
[1]
FirstName Alpher , title =
-
[2]
Journal of Foo , volume = 13, number = 1, pages =
FirstName Alpher and FirstName Fotheringham-Smythe , title =. Journal of Foo , volume = 13, number = 1, pages =
-
[3]
Journal of Foo , volume = 14, number = 1, pages =
FirstName Alpher and FirstName Fotheringham-Smythe and FirstName Gamow , title =. Journal of Foo , volume = 14, number = 1, pages =
-
[4]
FirstName Alpher and FirstName Gamow , title =
-
[5]
Computer Vision -- ECCV 2022 , year =
2022
-
[6]
FirstName LastName , title =
-
[7]
Communication, Simulation, and Intelligent Agents: Implications of Personal Intelligent Machines for Medical Education
Clancey, William J. Communication, Simulation, and Intelligent Agents: Implications of Personal Intelligent Machines for Medical Education. Proceedings of the Eighth International Joint Conference on Artificial Intelligence (IJCAI-83)
-
[8]
Classification Problem Solving
Clancey, William J. Classification Problem Solving. Proceedings of the Fourth National Conference on Artificial Intelligence
-
[9]
, title =
Robinson, Arthur L. , title =. 1980 , doi =. https://science.sciencemag.org/content/208/4447/1019.full.pdf , journal =
1980
-
[10]
New Ways to Make Microcircuits Smaller---Duplicate Entry
Robinson, Arthur L. New Ways to Make Microcircuits Smaller---Duplicate Entry. Science
-
[11]
Clancey and Glenn Rennels , abstract =
Diane Warner Hasling and William J. Clancey and Glenn Rennels , abstract =. Strategic explanations for a diagnostic consultation system , journal =. 1984 , issn =. doi:https://doi.org/10.1016/S0020-7373(84)80003-6 , url =
-
[12]
and Rennels, Glenn R
Hasling, Diane Warner and Clancey, William J. and Rennels, Glenn R. and Test, Thomas. Strategic Explanations in Consultation---Duplicate. The International Journal of Man-Machine Studies
-
[13]
Poligon: A System for Parallel Problem Solving
Rice, James. Poligon: A System for Parallel Problem Solving
-
[14]
Transfer of Rule-Based Expertise through a Tutorial Dialogue
Clancey, William J. Transfer of Rule-Based Expertise through a Tutorial Dialogue
-
[15]
The Engineering of Qualitative Models
Clancey, William J. The Engineering of Qualitative Models
-
[16]
2017 , eprint=
Attention Is All You Need , author=. 2017 , eprint=
2017
-
[17]
Pluto: The 'Other' Red Planet
NASA. Pluto: The 'Other' Red Planet
-
[18]
A survey on in-context learning
Dong, Qingxiu and Li, Lei and Dai, Damai and Zheng, Ce and Ma, Jingyuan and Li, Rui and Xia, Heming and Xu, Jingjing and Wu, Zhiyong and Chang, Baobao and Sun, Xu and Li, Lei and Sui, Zhifang. A Survey on In-context Learning. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing. 2024. doi:10.18653/v1/2024.emnlp-main.64
-
[19]
Chen, Jianlyu and Xiao, Shitao and Zhang, Peitian and Luo, Kun and Lian, Defu and Liu, Zheng. M 3-Embedding: Multi-Linguality, Multi-Functionality, Multi-Granularity Text Embeddings Through Self-Knowledge Distillation. Findings of the Association for Computational Linguistics: ACL 2024. 2024. doi:10.18653/v1/2024.findings-acl.137
-
[20]
Aho and Jeffrey D
Alfred V. Aho and Jeffrey D. Ullman , title =. 1972
1972
-
[21]
Publications Manual , year = "1983", publisher =
1983
-
[22]
Ashok K. Chandra and Dexter C. Kozen and Larry J. Stockmeyer , year = "1981", title =. doi:10.1145/322234.322243
-
[23]
Scalable training of
Andrew, Galen and Gao, Jianfeng , booktitle=. Scalable training of. 2007 , url=
2007
-
[24]
Dan Gusfield , title =. 1997
1997
-
[25]
Tetreault , title =
Mohammad Sadegh Rasooli and Joel R. Tetreault , title =. Computing Research Repository , volume =. 2015 , url =
2015
-
[26]
A Framework for Learning Predictive Structures from Multiple Tasks and Unlabeled Data , Volume =
Ando, Rie Kubota and Zhang, Tong , Issn =. A Framework for Learning Predictive Structures from Multiple Tasks and Unlabeled Data , Volume =. Journal of Machine Learning Research , Month = dec, Numpages =. 2005 , url=
2005
-
[27]
and Tukey, John W
Cooley, James W. and Tukey, John W. , journal=. An algorithm for the machine calculation of complex. 1965 , url=
1965
-
[28]
Johnson, Justin and Krishna, Ranjay and Stark, Michael and Li, Li-Jia and Shamma, David A. and Bernstein, Michael S. and Fei-Fei, Li , year=. Image retrieval using scene graphs , url=. doi:10.1109/cvpr.2015.7298990 , booktitle=
-
[29]
Proceedings of NeurIPS , year =
SatLM: Satisfiability-Aided Language Models Using Declarative Prompting , author =. Proceedings of NeurIPS , year =
-
[30]
Arithmetic Reasoning with LLM : P rolog Generation & Permutation
Yang, Xiaocheng and Chen, Bingsen and Tam, Yik-Cheung. Arithmetic Reasoning with LLM : P rolog Generation & Permutation. Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 2: Short Papers). 2024. doi:10.18653/v1/2024.naacl-short.61
-
[31]
NeurIPS , year=
Matt Deitke and Eli VanderBilt and Alvaro Herrasti and Luca Weihs and Jordi Salvador and Kiana Ehsani and Winson Han and Eric Kolve and Ali Farhadi and Aniruddha Kembhavi and Roozbeh Mottaghi , title=. NeurIPS , year=
-
[32]
2023 , archivePrefix=
Habitat 3.0: A Co-Habitat for Humans, Avatars and Robots , author =. 2023 , archivePrefix=
2023
-
[33]
Advances in Neural Information Processing Systems (NeurIPS) , year =
Habitat 2.0: Training Home Assistants to Rearrange their Habitat , author =. Advances in Neural Information Processing Systems (NeurIPS) , year =
-
[34]
Habitat:
Manolis Savva and Abhishek Kadian and Oleksandr Maksymets and Yili Zhao and Erik Wijmans and Bhavana Jain and Julian Straub and Jia Liu and Vladlen Koltun and Jitendra Malik and Devi Parikh and Dhruv Batra , booktitle =. Habitat:
-
[35]
Proceedings of the Computer Vision and Pattern Recognition Conference (CVPR) , month =
Zhang, Yunzhi and Li, Zizhang and Zhou, Matt and Wu, Shangzhe and Wu, Jiajun , title =. Proceedings of the Computer Vision and Pattern Recognition Conference (CVPR) , month =. 2025 , pages =
2025
-
[36]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , month =
Yang, Yue and Sun, Fan-Yun and Weihs, Luca and VanderBilt, Eli and Herrasti, Alvaro and Han, Winson and Wu, Jiajun and Haber, Nick and Krishna, Ranjay and Liu, Lingjie and Callison-Burch, Chris and Yatskar, Mark and Kembhavi, Aniruddha and Clark, Christopher , title =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR...
2024
-
[37]
Retrieval-augmented generation for knowledge-intensive NLP tasks , year =
Lewis, Patrick and Perez, Ethan and Piktus, Aleksandra and Petroni, Fabio and Karpukhin, Vladimir and Goyal, Naman and K\". Retrieval-augmented generation for knowledge-intensive NLP tasks , year =. Proceedings of the 34th International Conference on Neural Information Processing Systems , articleno =
-
[38]
Kenny and Fu, Kailiang and Aguina-Kang, Rio and Morris, Stewart and Ritchie, Daniel , title =
Gumin, Maxim and Han, Do Heon and Yoo, Seung Jean and Ganeshan, Aditya and Jones, R. Kenny and Fu, Kailiang and Aguina-Kang, Rio and Morris, Stewart and Ritchie, Daniel , title =. Proceedings of the SIGGRAPH Asia 2025 Conference Papers , articleno =. 2025 , isbn =. doi:10.1145/3757377.3763930 , abstract =
-
[39]
Proceedings of the European Conference on Computer Vision (ECCV) , year=
AnyHome: Open-Vocabulary Generation of Structured and Textured 3D Homes , author=. Proceedings of the European Conference on Computer Vision (ECCV) , year=
-
[40]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
DiffInDScene: Diffusion-based High-Quality 3D Indoor Scene Generation , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[41]
arXiv preprint arXiv:2409.08215 , year=
LT3SD: Latent Trees for 3D Scene Diffusion , author=. arXiv preprint arXiv:2409.08215 , year=
-
[42]
2024 , editor =
Zhou, Xiaoyu and Ran, Xingjian and Xiong, Yajiao and He, Jinlin and Lin, Zhiwei and Wang, Yongtao and Sun, Deqing and Yang, Ming-Hsuan , booktitle =. 2024 , editor =
2024
-
[43]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , year=
Diffuscene: Denoising diffusion models for generative indoor scene synthesis , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , year=
-
[44]
Proceedings of Conference on Computer Vision and Pattern Recognition (CVPR) , year=
PhyScene: Physically Interactable 3D Scene Synthesis for Embodied AI , author=. Proceedings of Conference on Computer Vision and Pattern Recognition (CVPR) , year=
-
[45]
2024 , eprint=
I-Design: Personalized LLM Interior Designer , author=. 2024 , eprint=
2024
-
[46]
2024 , booktitle=
Architect: Generating Vivid and Interactive 3D Scenes with Hierarchical 2D Inpainting , author=. 2024 , booktitle=
2024
-
[47]
2024 , eprint=
DStruct2Design: Data and Benchmarks for Data Structure Driven Generative Floor Plan Design , author=. 2024 , eprint=
2024
-
[48]
2025 , eprint=
Qwen2.5 Technical Report , author=. 2025 , eprint=
2025
-
[49]
2024 , editor =
Wang, Yufei and Xian, Zhou and Chen, Feng and Wang, Tsun-Hsuan and Wang, Yian and Fragkiadaki, Katerina and Erickson, Zackory and Held, David and Gan, Chuang , booktitle =. 2024 , editor =
2024
-
[50]
2025 , eprint=
DesignBench: A Comprehensive Benchmark for MLLM-based Front-end Code Generation , author=. 2025 , eprint=
2025
-
[51]
2025 , eprint=
ScanEdit: Hierarchically-Guided Functional 3D Scan Editing , author=. 2025 , eprint=
2025
-
[52]
arXiv , year=
Eric Kolve and Roozbeh Mottaghi and Winson Han and Eli VanderBilt and Luca Weihs and Alvaro Herrasti and Daniel Gordon and Yuke Zhu and Abhinav Gupta and Ali Farhadi , title=. arXiv , year=
-
[53]
and Savva, Manolis , title =
Khanna, Mukul and Mao, Yongsen and Jiang, Hanxiao and Haresh, Sanjay and Shacklett, Brennan and Batra, Dhruv and Clegg, Alexander and Undersander, Eric and Chang, Angel X. and Savva, Manolis , title =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , month =. 2024 , pages =
2024
-
[54]
ScanNet: Richly-annotated 3D Reconstructions of Indoor Scenes , author=. Proc. Computer Vision and Pattern Recognition (CVPR), IEEE , year =
-
[55]
CLIP- Score: A reference-free evaluation metric for image captioning
Hessel, Jack and Holtzman, Ari and Forbes, Maxwell and Le Bras, Ronan and Choi, Yejin. CLIPS core: A Reference-free Evaluation Metric for Image Captioning. Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing. 2021. doi:10.18653/v1/2021.emnlp-main.595
-
[56]
LayoutGPT: Compositional Visual Planning and Generation with Large Language Models , url =
Feng, Weixi and Zhu, Wanrong and Fu, Tsu-Jui and Jampani, Varun and Akula, Arjun and He, Xuehai and Basu, S and Wang, Xin Eric and Wang, William Yang , booktitle =. LayoutGPT: Compositional Visual Planning and Generation with Large Language Models , url =
-
[57]
Objaverse: A Universe of Annotated 3D Objects , year=
Deitke, Matt and Schwenk, Dustin and Salvador, Jordi and Weihs, Luca and Michel, Oscar and VanderBilt, Eli and Schmidt, Ludwig and Ehsanit, Kiana and Kembhavi, Aniruddha and Farhadi, Ali , booktitle=. Objaverse: A Universe of Annotated 3D Objects , year=
-
[58]
doi:10.5281/zenodo.5143773 , url =
Ilharco, Gabriel and Wortsman, Mitchell and Wightman, Ross and Gordon, Cade and Carlini, Nicholas and Taori, Rohan and Dave, Achal and Shankar, Vaishaal and Namkoong, Hongseok and Miller, John and Hajishirzi, Hannaneh and Farhadi, Ali and Schmidt, Ludwig , title =. doi:10.5281/zenodo.5143773 , url =
-
[59]
Proceedings of the 38th International Conference on Machine Learning , pages =
Learning Transferable Visual Models From Natural Language Supervision , author =. Proceedings of the 38th International Conference on Machine Learning , pages =. 2021 , editor =
2021
-
[60]
Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks
Reimers, Nils and Gurevych, Iryna. Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks. Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing. 2019
2019
-
[61]
2012 , eprint=
Spring Embedders and Force Directed Graph Drawing Algorithms , author=. 2012 , eprint=
2012
-
[62]
2022 , eprint=
A Survey of Embodied AI: From Simulators to Research Tasks , author=. 2022 , eprint=
2022
-
[63]
IEEE Transactions on Visualization and Computer Graphics , month = dec, pages =
Luong, Tiffany and Lecuyer, Anatole and Martin, Nicolas and Argelaguet, Ferran , title =. IEEE Transactions on Visualization and Computer Graphics , month = dec, pages =. 2022 , issue_date =. doi:10.1109/TVCG.2021.3110459 , abstract =
-
[64]
Proceedings of the 2022 CHI Conference on Human Factors in Computing Systems , articleno =
Suzuki, Ryo and Karim, Adnan and Xia, Tian and Hedayati, Hooman and Marquardt, Nicolai , title =. Proceedings of the 2022 CHI Conference on Human Factors in Computing Systems , articleno =. 2022 , isbn =. doi:10.1145/3491102.3517719 , abstract =
-
[65]
Text2Room: Extracting Textured 3D Meshes from 2D Text-to-Image Models , booktitle =
H\"ollein, Lukas and Cao, Ang and Owens, Andrew and Johnson, Justin and Nie. Text2Room: Extracting Textured 3D Meshes from 2D Text-to-Image Models , booktitle =. 2023 , pages =
2023
-
[66]
International Conference on Learning Representations (ICLR) , year=
InstructScene: Instruction-Driven 3D Indoor Scene Synthesis with Semantic Graph Prior , author=. International Conference on Learning Representations (ICLR) , year=
-
[67]
arXiv preprint arXiv:2506.05341 , year=
Direct Numerical Layout Generation for 3D Indoor Scene Synthesis via Spatial Reasoning , author=. arXiv preprint arXiv:2506.05341 , year=
-
[68]
Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
LayoutVLM: Differentiable Optimization of 3D Layout via Vision-Language Models , author=. Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
-
[69]
arXiv preprint arXiv:2506.02459 , year=
ReSpace: Text-Driven Autoregressive 3D Indoor Scene Synthesis and Editing , author=. arXiv preprint arXiv:2506.02459 , year=
-
[70]
and Huo, Xiaoliang and Chang, Angel X
Pun, Hou In Derek and Tam, Hou In Ivan and Wang, Austin T. and Huo, Xiaoliang and Chang, Angel X. and Savva, Manolis , booktitle=
-
[71]
Ouyang, Long and Wu, Jeff and Jiang, Xu and Almeida, Diogo and Wainwright, Carroll L. and Mishkin, Pamela and Zhang, Chong and Agarwal, Sandhini and Slama, Katarina and Ray, Alex and Schulman, John and Hilton, Jacob and Kelton, Fraser and Miller, Luke and Simens, Maddie and Askell, Amanda and Welinder, Peter and Christiano, Paul and Leike, Jan and Lowe, R...
2022
-
[72]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
3d-front: 3d furnished rooms with layouts and semantics , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[73]
2009 IEEE conference on computer vision and pattern recognition , pages=
Recognizing indoor scenes , author=. 2009 IEEE conference on computer vision and pattern recognition , pages=. 2009 , organization=
2009
-
[74]
2013 Picture Coding Symposium (PCS) , pages=
Subjective quality evaluations using crowdsourcing , author=. 2013 Picture Coding Symposium (PCS) , pages=. 2013 , organization=
2013
-
[75]
Terry , journal =
Ralph Allan Bradley and Milton E. Terry , journal =. Rank Analysis of Incomplete Block Designs: I. The Method of Paired Comparisons , urldate =
-
[76]
Recognizing indoor scenes , year=
Quattoni, Ariadna and Torralba, Antonio , booktitle=. Recognizing indoor scenes , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.