FTibSuite: A Comprehensive Resource Suite for Tibetan Vision-Language Modeling
Pith reviewed 2026-06-29 18:30 UTC · model grok-4.3
The pith
FTibSuite supplies training data, benchmarks, and a baseline model to enable Tibetan vision-language research.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
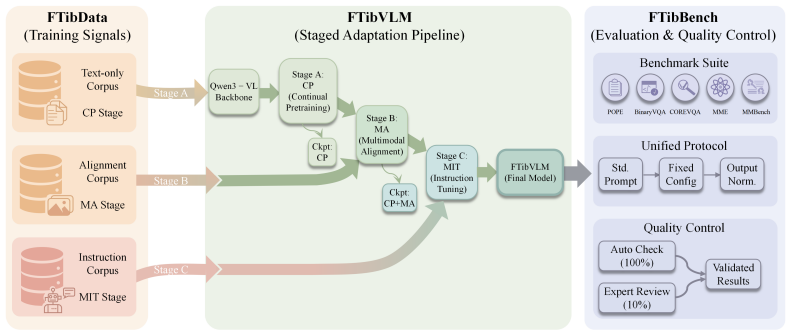
The authors claim that FTibSuite, built from FTibData for continual pretraining, image-text alignment and instruction tuning, FTibBench consisting of Tibetan versions of five mainstream multimodal benchmarks with hierarchical quality-control workflow, and FTibVLM obtained by three-stage adaptation of Qwen3-VL-8B-Instruct, produces consistent performance gains on Tibetan tasks such as lifting MMBench accuracy from 42.97 to 67.78 and POPE-random accuracy from 47.53 to 80.56 while retaining the backbone's original Chinese capabilities with minimal degradation.
What carries the argument
The three-stage adaptation pipeline that fine-tunes the backbone on FTibData to produce the FTibVLM baseline.
If this is right
- Future Tibetan vision-language models can be trained and compared using the same standardized data and benchmarks.
- The adapted model maintains most of its original performance on Chinese multimodal tasks after the three-stage process.
- The quality-control workflow reduces translation noise enough to support measurable gains across multiple evaluation tasks.
- The suite supplies the first reproducible starting point for research on Tibetan multimodal capabilities.
Where Pith is reading between the lines
- The same staged adaptation and quality workflow could be tested on other low-resource languages that lack native multimodal data.
- Retention of Chinese performance suggests the pipeline may limit interference with previously learned languages during adaptation.
- Independent groups could extend FTibBench with additional tasks or languages using the same hierarchical verification steps.
Load-bearing premise
The human-verified training data and the quality-controlled benchmarks contain low enough noise and sufficient scale for the adaptation steps to produce genuine capability gains rather than artifacts.
What would settle it
A controlled test in which a model trained on raw machine-translated data or evaluated on unfiltered translations matches or exceeds the reported Tibetan-task scores would undermine the claim that the suite's quality controls are necessary.
Figures


read the original abstract
Vision-language models have progressed rapidly, but Tibetan remains a severely underserved low-resource language due to the lack of reproducible training and evaluation infrastructure. To fill this gap, we introduce FTibSuite, a comprehensive resource suite for Tibetan vision-language research, consisting of FTibData (human-verified multimodal training corpora spanning continual pretraining, image-text alignment, and instruction tuning data), FTibBench (Tibetan adaptations of five mainstream multimodal benchmarks with a hierarchical quality-control workflow to reduce translation noise), and FTibVLM, a reproducible baseline built on Qwen3-VL-8B-Instruct via a three-stage adaptation pipeline. Experiments on FTibBench show FTibVLM delivers consistent performance gains across all tasks, such as improving MMBench accuracy from 42.97 to 67.78 and POPE-random accuracy from 47.53 to 80.56, while retaining the backbone's original Chinese capabilities with minimal degradation, providing the first standardized foundation for Tibetan multimodal research.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces FTibSuite, a resource suite for Tibetan vision-language modeling consisting of FTibData (human-verified multimodal corpora for continual pretraining, image-text alignment, and instruction tuning), FTibBench (Tibetan adaptations of five mainstream multimodal benchmarks constructed via a hierarchical quality-control workflow), and FTibVLM (a reproducible baseline obtained by three-stage adaptation of Qwen3-VL-8B-Instruct). Experiments on FTibBench report consistent gains, including MMBench accuracy rising from 42.97 to 67.78 and POPE-random accuracy from 47.53 to 80.56, while the adapted model largely retains the backbone's original Chinese capabilities.
Significance. If the reported gains and data quality hold, the work supplies the first standardized, reproducible foundation for Tibetan multimodal research and demonstrates a viable adaptation pathway for low-resource languages. The release of human-verified training corpora, benchmark adaptations, and the three-stage pipeline constitutes a concrete enabling contribution that can support subsequent model development and evaluation in this underserved language.
major comments (2)
- [§4] §4 (Experiments) and abstract: the central claim of 'consistent performance gains across all tasks' is supported only by point estimates (e.g., MMBench 42.97 o 67.78, POPE-random 47.53 o 80.56) without error bars, standard deviations across runs, or statistical significance tests; this omission directly affects the strength of the empirical conclusion.
- [§3.2] §3.2 (FTibBench construction): the hierarchical quality-control workflow is presented without quantitative validation such as inter-annotator agreement scores, measured residual translation error rates, or ablation of the workflow stages; because the weakest link in the argument is precisely whether translation noise has been sufficiently reduced, these metrics are load-bearing for the benchmark's reliability.
minor comments (3)
- [§3.1] The scale (number of samples or tokens) of each component of FTibData should be stated explicitly in §3.1 to allow readers to assess whether the three-stage adaptation is supported by adequate verified data volume.
- [Figure 2] Figure 2 and Table 2: axis labels and column headers use inconsistent capitalization and abbreviation style; standardize for clarity.
- A brief discussion of potential limitations (e.g., domain coverage of FTibData or remaining translation artifacts) would strengthen the manuscript even if the results are positive.
Simulated Author's Rebuttal
We thank the referee for the constructive review and the recommendation of minor revision. We address each major comment below with honest assessment of the manuscript's current state and planned changes.
read point-by-point responses
-
Referee: [§4] §4 (Experiments) and abstract: the central claim of 'consistent performance gains across all tasks' is supported only by point estimates (e.g., MMBench 42.97 o 67.78, POPE-random 47.53 o 80.56) without error bars, standard deviations across runs, or statistical significance tests; this omission directly affects the strength of the empirical conclusion.
Authors: We agree that reliance on single-run point estimates limits the strength of the empirical claims. The reported numbers reflect one adaptation run of Qwen3-VL-8B-Instruct under the three-stage pipeline. In revision we will add explicit language in §4 and the abstract stating that results are from individual runs without statistical testing, and we will discuss this as a limitation. Additional runs for standard deviations are not feasible within minor-revision scope due to compute cost, but the text will be updated to reflect this constraint. revision: partial
-
Referee: [§3.2] §3.2 (FTibBench construction): the hierarchical quality-control workflow is presented without quantitative validation such as inter-annotator agreement scores, measured residual translation error rates, or ablation of the workflow stages; because the weakest link in the argument is precisely whether translation noise has been sufficiently reduced, these metrics are load-bearing for the benchmark's reliability.
Authors: The absence of IAA scores, residual error rates, and stage ablations is a genuine gap in the current §3.2. The manuscript describes the hierarchical workflow but provides no quantitative validation of its effectiveness. For revision we will expand the section with additional process details (e.g., annotator count and review steps) already available from the construction logs. However, the requested quantitative metrics were never collected during the original annotation and cannot be retroactively produced without new annotation effort. revision: partial
- Quantitative validation metrics (IAA, residual translation error rates, workflow ablations) for FTibBench construction, as these were not measured during the original data creation process.
Circularity Check
No significant circularity
full rationale
The paper consists of resource construction (FTibData, FTibBench) and empirical reporting of a three-stage adaptation of an external backbone model (Qwen3-VL-8B-Instruct). No equations, derivations, fitted parameters presented as predictions, or self-citation chains appear in the provided text. All load-bearing claims rest on external model usage and reported benchmark numbers rather than reducing to self-referential definitions or fits. This is the expected non-finding for a dataset-and-fine-tuning paper.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Gpt-4 techni- cal report.arXiv preprint arXiv:2303.08774. Nahid Alam, Karthik Reddy Kanjula, Surya Guthikonda, Timothy Chung, Bala Krishna S Vegesna, Abhipsha Das, Anthony Susevski, Ryan Sze-Yin Chan, SM Ud- din, Shayekh Bin Islam, and 1 others
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
arXiv preprint arXiv:2505.08910
Behind maya: Building a multilingual vision language model. arXiv preprint arXiv:2505.08910. Jean-Baptiste Alayrac, Jeff Donahue, Pauline Luc, Antoine Miech, Iain Barr, Yana Hasson, Karel Lenc, Arthur Mensch, Katherine Millican, Malcolm Reynolds, and 1 others
-
[3]
Qwen technical report. arXiv preprint arXiv:2309.16609. Ali Borji
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Lifeng Chen, Ryan Lai, and Tianming Liu
Binaryvqa: A versatile test set to evalu- ate the out-of-distribution generalization of vqa mod- els.arXiv preprint arXiv:2301.12032. Lifeng Chen, Ryan Lai, and Tianming Liu
-
[5]
arXiv preprint arXiv:2512.03976
Adapt- ing large language models to low-resource tibetan: A two-stage continual and supervised fine-tuning study. arXiv preprint arXiv:2512.03976. Xi Chen, Xiao Wang, Soravit Changpinyo, Anthony J Piergiovanni, Piotr Padlewski, Daniel Salz, Sebas- tian Goodman, Adam Grycner, Basil Mustafa, Lucas Beyer, and 1 others
-
[6]
PaLI: A Jointly-Scaled Multilingual Language-Image Model
Pali: A jointly-scaled multilingual language-image model.arXiv preprint arXiv:2209.06794. Ishant Chintapatla, Kazuma Choji, Naaisha Agar- wal, Andrew Lin, Hannah You, Charles Duong, Kevin Zhu, Sean O’Brien, and Vasu Sharma
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
Corevqa: A crowd observation and reasoning entail- ment visual question answering benchmark.arXiv preprint arXiv:2507.13405. Alexis Conneau, Kartikay Khandelwal, Naman Goyal, Vishrav Chaudhary, Guillaume Wenzek, Francisco Guzmán, Edouard Grave, Myle Ott, Luke Zettle- moyer, and Veselin Stoyanov
-
[8]
No Language Left Behind: Scaling Human-Centered Machine Translation
No language left behind: Scaling human-centered machine translation.arXiv preprint arXiv:2207.04672. Wenliang Dai, Junnan Li, Dongxu Li, Anthony Tiong, Junqi Zhao, Weisheng Wang, Boyang Li, Pascale N Fung, and Steven Hoi
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
DeepSeek-V3.2: Pushing the Frontier of Open Large Language Models
Deepseek-v3.2: Pushing the frontier of open large language models.Preprint, arXiv:2512.02556. Chaoyou Fu, Peixian Chen, Yunhang Shen, Yulei Qin, Mengdan Zhang, Xu Lin, Jinrui Yang, Xiawu Zheng, Ke Li, Xing Sun, and 1 others
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
Don’t stop pretraining: Adapt language models to domains and tasks.arXiv preprint arXiv:2004.10964. Jordan Hoffmann, Sebastian Borgeaud, Arthur Men- sch, Elena Buchatskaya, Trevor Cai, Eliza Ruther- ford, Diego de Las Casas, Lisa Anne Hendricks, Johannes Welbl, Aidan Clark, and 1 others
-
[11]
Training Compute-Optimal Large Language Models
Training compute-optimal large language models. arXiv preprint arXiv:2203.15556. Neil Houlsby, Andrei Giurgiu, Stanislaw Jastrzebski, Bruna Morrone, Quentin De Laroussilhe, Andrea Gesmundo, Mona Attariyan, and Sylvain Gelly
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
Ti- betan language and ai: A comprehensive survey of resources, methods and challenges.arXiv preprint arXiv:2510.19144. Chao Jia, Yinfei Yang, Ye Xia, Yi-Ting Chen, Zarana Parekh, Hieu Pham, Quoc Le, Yun-Hsuan Sung, Zhen Li, and Tom Duerig
-
[13]
Scaling Laws for Neural Language Models
Scaling laws for neural language models.arXiv preprint arXiv:2001.08361. Fenfang Li, Zhengzhang Zhao, Li Wang, and Han Deng
work page internal anchor Pith review Pith/arXiv arXiv 2001
-
[14]
Evaluating Object Hallucination in Large Vision-Language Models
Blip: Bootstrapping language-image pre- training for unified vision-language understanding and generation. InInternational conference on ma- chine learning, pages 12888–12900. PMLR. Yifan Li, Yifan Du, Kun Zhou, Jinpeng Wang, Wayne Xin Zhao, and Ji-Rong Wen. 2023b. Eval- uating object hallucination in large vision-language models.arXiv preprint arXiv:2305...
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
Bushi Xiao, Qian Shen, and Daisy Zhe Wang
AI challenger : A large-scale dataset for going deeper in image understanding.CoRR, abs/1711.06475. Bushi Xiao, Qian Shen, and Daisy Zhe Wang
-
[16]
InProceedings of the Eighth Workshop on Technologies for Machine Translation of Low-Resource Languages (LoResMT 2025), pages 24–35
From text to multi-modal: Advancing low-resource- language translation through synthetic data genera- tion and cross-modal alignments. InProceedings of the Eighth Workshop on Technologies for Machine Translation of Low-Resource Languages (LoResMT 2025), pages 24–35. Zhiyang Xu, Chao Feng, Rulin Shao, Trevor Ashby, Ying Shen, Di Jin, Yu Cheng, Qifan Wang, ...
2025
-
[17]
Vision-flan: Scaling human-labeled tasks in visual instruction tuning.arXiv preprint arXiv:2402.11690. An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, Chujie Zheng, Day- iheng Liu, Fan Zhou, Fei Huang, Feng Hu, Hao Ge, Haoran Wei, Huan Lin, Jialong Tang, and 41 others
-
[18]
Qwen3 technical report.Preprint, arXiv:2505.09388. Ziqing Yang, Zihang Xu, Yiming Cui, Baoxin Wang, Min Lin, Dayong Wu, and Zhigang Chen
work page internal anchor Pith review Pith/arXiv arXiv
-
[19]
arXiv preprint arXiv:2202.13558
Cino: A chinese minority pre-trained language model. arXiv preprint arXiv:2202.13558. Chen Zhang, Mingxu Tao, Quzhe Huang, Jiuheng Lin, Zhibin Chen, and Yansong Feng
-
[20]
Wenzhen Zheng, Wenbo Pan, Xu Xu, Libo Qin, Li Yue, and Ming Zhou
Enhancing multimodal continual instruction tuning with branchlora.arXiv preprint arXiv:2506.02041. Wenzhen Zheng, Wenbo Pan, Xu Xu, Libo Qin, Li Yue, and Ming Zhou
-
[21]
unchanged task def- inition, unchanged answer space, and structure aligned as much as possible
Breaking language barriers: Cross-lingual continual pre-training at scale.arXiv preprint arXiv:2407.02118. A FTibBench benchmark adaptation and quality control details A.1 Benchmark Composition, Splits, and Scale FTibBench currently includes Tibetan versions of five representative multimodal evaluation bench- marks, covering complementary dimensions such ...
-
[22]
au- tomatic scoring + human fallback
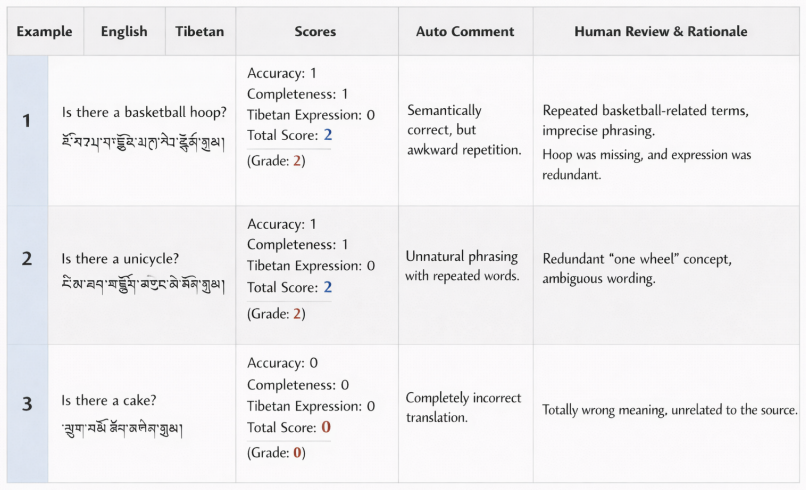
A.5 Score-Triggered Revision and Manual Review Strategy We adopt a tiered quality-control strategy of“au- tomatic scoring + human fallback”to balance quality and cost: • Total ≤2 : mandatory revision and manda- tory human review.Such samples typically exhibit missing key terms, semantic drift, or clearly unnatural phrasing, which may com- promise evaluati...
2056
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.