SemCEB: A Cardinality Estimation Benchmark for Semantic Operators
Pith reviewed 2026-06-26 06:30 UTC · model grok-4.3
The pith
SemCEB introduces the first benchmark for testing cardinality estimation on semantic filters and joins using 102 real-world queries.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
SemCEB is the first benchmark for cardinality estimation over semantic operators. It rests on a real-world dataset of semi-structured text and images together with 102 hand-curated queries that span a wide range of selectivities. The benchmark isolates semantic filters and joins and compares sampling-based estimators against Semantic Histograms on accuracy, cost, latency, and memory. Sampling remains robust across predicate categories yet fails to scale because of high costs; the adapted Semantic Histograms method shows limited applicability and performance that depends on the predicate category.
What carries the argument
SemCEB benchmark of 102 hand-curated queries on text and image data that isolates cardinality estimation for semantic filters and joins.
If this is right
- Query optimizers for systems that expose semantic operators can now compare candidate cardinality estimators against a common, public set of filter and join cases.
- Sampling remains viable only when data volumes stay small or when estimates are allowed to be expensive.
- Histogram-style summaries for semantic data require predicate-specific tuning before they become broadly usable.
- Plan enumeration that includes semantic operators will continue to suffer large cost penalties until better estimators appear.
Where Pith is reading between the lines
- Developers of new estimators can treat the 102 queries as a fixed test suite and add their own methods without re-collecting data.
- The observed predicate-category sensitivity points to a possible need for hybrid estimators that switch strategies inside a single query.
- Extending the benchmark to include correlated predicates or multi-way joins would expose whether current conclusions hold under more complex workloads.
Load-bearing premise
The 102 hand-curated queries on the real-world text and image dataset are representative enough to reveal the general strengths and weaknesses of cardinality estimation methods for semantic operators.
What would settle it
A cardinality estimation technique that delivers low error rates at low latency and low memory cost on every one of the 102 queries and on additional queries drawn from the same data distribution would show that the reported limitations of sampling and Semantic Histograms are not fundamental.
Figures




read the original abstract
Modern data systems increasingly expose multi-modal large language models as semantic operators: SQL operators, including filters and joins, whose predicates are defined by a natural-language instruction. Query optimization in these systems still rests on the same foundations as in traditional databases$\unicode{x2013}$plan enumeration and cost models$\unicode{x2013}$yet faces new challenges, e.g., a larger plan space and the lack of efficient cardinality estimates. The elevated per-tuple costs of semantic operators make bad plan choices worse by orders of magnitude. Therefore, precise$\unicode{x2013}$but also fast and cheap$\unicode{x2013}$cardinality estimates for semantic filters and joins are of high importance for optimizing query plans that include semantic operators. In this paper, we introduce SemCEB, the first benchmark for cardinality estimation over semantic operators, based on a real-world dataset of (semi-)structured text and images with 102 hand-curated, diverse queries spanning a wide range of selectivities, assessing cardinality estimation for semantic filters and joins in isolation. We evaluate sampling-based algorithms and Semantic Histograms, a state-of-the-art cardinality estimation algorithm for semantic operators, with respect to their accuracy, cost, latency, and memory overhead. We show that, while sampling is robust across different predicate categories, it does not scale and comes with high costs. Our adaptation of Semantic Histograms, on the other hand, is limited in its applicability, and its performance appears sensitive to the predicate category.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces SemCEB, the first benchmark for cardinality estimation over semantic operators (NL-defined filters and joins) on a real-world (semi-)structured text/image dataset. It contributes 102 hand-curated queries spanning selectivities, evaluates sampling-based estimators and an adaptation of Semantic Histograms on accuracy/cost/latency/memory, and concludes that sampling is robust across predicate categories but does not scale, while the adapted Semantic Histograms method has limited applicability and appears sensitive to predicate category.
Significance. If the benchmark queries are representative, the work fills a practical gap in query optimization for multi-modal systems that expose LLMs as semantic operators. The empirical comparison of robustness vs. scalability trade-offs supplies concrete guidance for estimator design in this emerging setting.
major comments (1)
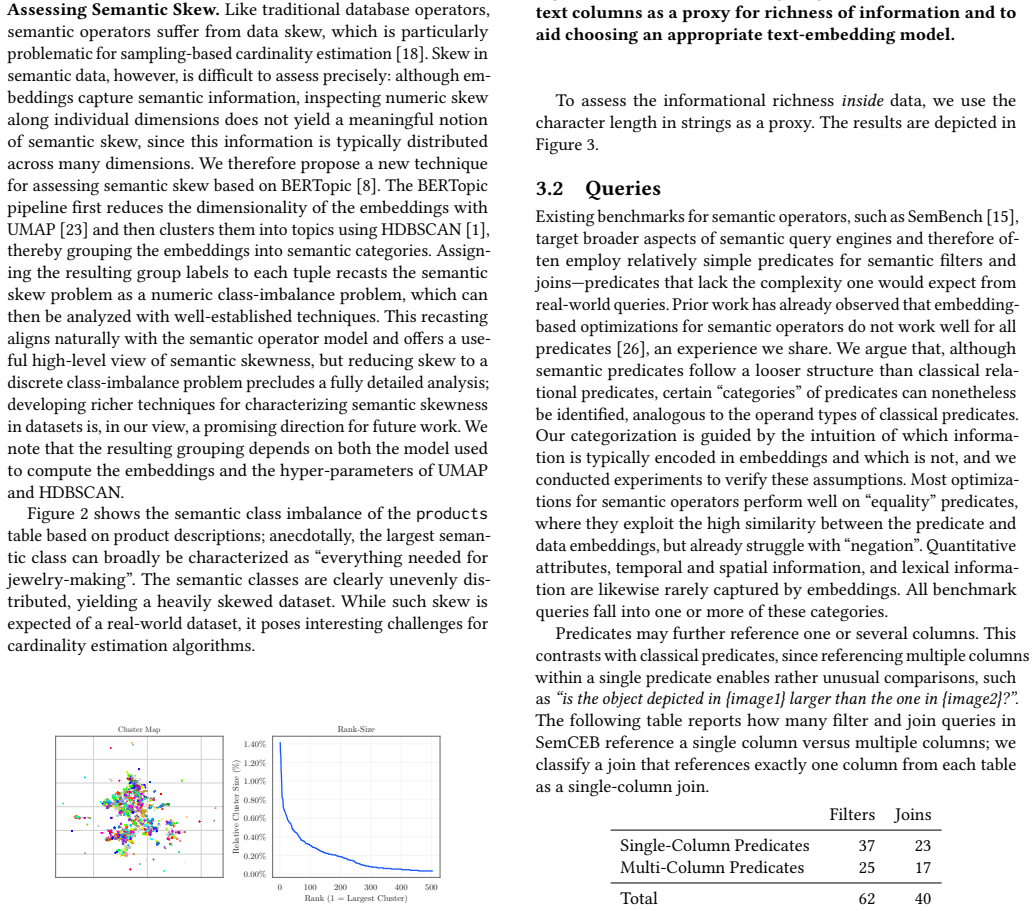
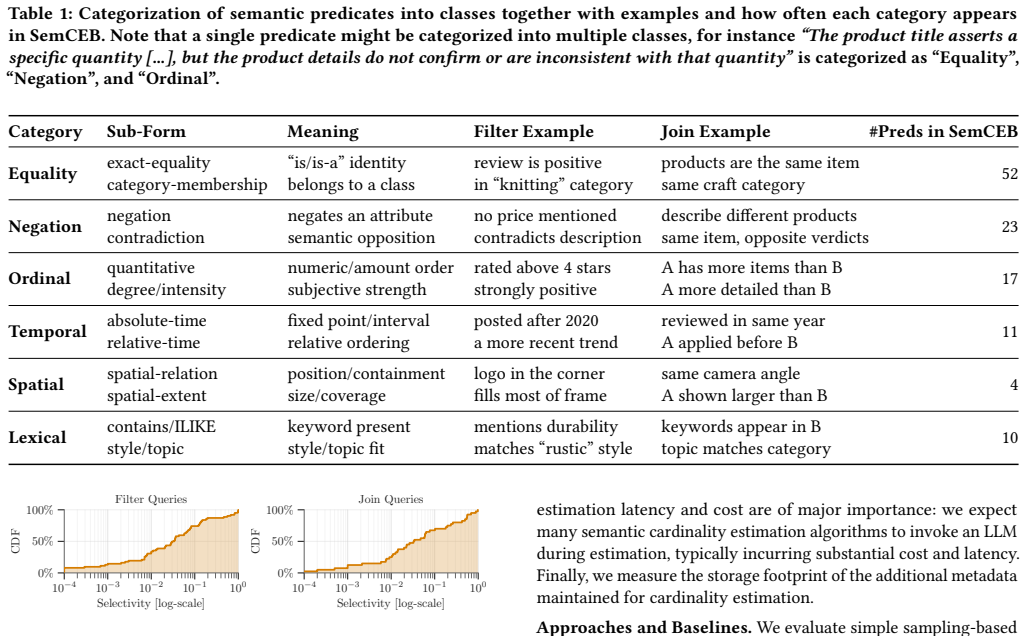
- [Benchmark construction section] Section describing the 102 queries (benchmark construction): the queries are characterized only as 'hand-curated, diverse' with a wide range of selectivities; no curation criteria, per-category counts (text/image filters, joins), or quantitative diversity metrics are supplied. This is load-bearing for the central claim that sampling is robust across categories while Semantic Histograms is category-sensitive, because the observed differences could be artifacts of query selection rather than intrinsic method properties.
minor comments (1)
- [Abstract] Abstract: the phrasing 'precise–but also fast and cheap' is informal; a more precise statement of the three-way trade-off would improve clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the benchmark construction. We agree that additional details on query curation will strengthen the paper and address the concern about potential selection artifacts in the robustness claims.
read point-by-point responses
-
Referee: [Benchmark construction section] Section describing the 102 queries (benchmark construction): the queries are characterized only as 'hand-curated, diverse' with a wide range of selectivities; no curation criteria, per-category counts (text/image filters, joins), or quantitative diversity metrics are supplied. This is load-bearing for the central claim that sampling is robust across categories while Semantic Histograms is category-sensitive, because the observed differences could be artifacts of query selection rather than intrinsic method properties.
Authors: We acknowledge that the manuscript provides only a high-level characterization of the queries. In the revision, we will expand the benchmark construction section with: explicit curation criteria (ensuring balanced coverage of text filters, image filters, and joins across selectivity ranges, drawn from real-world query patterns on the dataset); a table with per-category counts; and a breakdown of how queries were selected for diversity. While we did not originally compute formal quantitative diversity metrics (e.g., category entropy), the added table and criteria will allow readers to evaluate whether performance differences reflect intrinsic method properties. The core empirical findings on sampling robustness and histogram sensitivity remain unchanged, as they are based on the observed per-query results. revision: yes
Circularity Check
No circularity: empirical benchmark paper with no derivation chain
full rationale
This is an empirical benchmark introduction and evaluation study. The paper defines SemCEB, curates 102 queries on a real-world dataset, and reports accuracy/cost/latency results for sampling and an adapted Semantic Histograms method. No equations, first-principles derivations, fitted parameters renamed as predictions, or self-citation chains appear in the abstract or described structure. The central claims rest on experimental measurements rather than any reduction of outputs to inputs by construction. Representativeness of the query set is an external-validity question, not a circularity issue.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Ricardo J. G. B. Campello, Davoud Moulavi, and Jörg Sander. 2013. Density-Based Clustering Based on Hierarchical Density Estimates. InAdvances in Knowledge Discovery and Data Mining, 17th Pacific-Asia Conference, PAKDD 2013, Gold Coast, Australia, April 14-17, 2013, Proceedings, Part II (Lecture Notes in Computer Science), Jian Pei, Vincent S. Tseng, Long...
-
[2]
Yu Chen and Ke Yi. 2017. Two-Level Sampling for Join Size Estimation. In Proceedings of the 2017 ACM International Conference on Management of Data (Chicago, Illinois, USA)(SIGMOD ’17). Association for Computing Machinery, New York, NY, USA, 759–774. https://doi.org/10.1145/3035918.3035921
-
[3]
Yannis Chronis, Yawen Wang, Yu Gan, Sami Abu-El-Haija, Chelsea Lin, Carsten Binnig, and Fatma Özcan. 2024. Cardbench: A benchmark for learned cardinality 6 estimation in relational databases.arXiv preprint arXiv:2408.16170(2024)
arXiv 2024
-
[4]
Yeounoh Chung, Rushabh Desai, Jian He, Yu Xiao, Thibaud Hottelier, Yves- Laurent Kom Samo, Pushkar Khadilkar, Xianshun Chen, Sam Idicula, Fatma Özcan, Alon Halevy, and Yannis Papakonstantinou. 2026. 100x Cost & Latency Reduction: Performance Analysis of AI Query Approximation using Lightweight Proxy Models. (4 2026). https://doi.org/10.1145/3802002
-
[5]
Hanjun Dai, Bethany Wang, Xingchen Wan, Bo Dai, Sherry Yang, Azade Nova, Pengcheng Yin, Phitchaya Mangpo Phothilimthana, Charles Sutton, and Dale Schuurmans. 2024. UQE: A Query Engine for Unstructured Databases. InAd- vances in Neural Information Processing Systems 38: Annual Conference on Neural Information Processing Systems 2024, NeurIPS 2024, Vancouve...
2024
-
[6]
Anas Dorbani, Sunny Yasser, Jimmy Lin, and Amine Mhedhbi. 2025. Beyond Quacking: Deep Integration of Language Models and RAG into DuckDB.Proc. VLDB Endow.18, 12 (2025). https://doi.org/10.14778/3750601.3750685
-
[7]
2024.BLEND- SQL: A Scalable Dialect for Unifying Hybrid Question Answering in Relational Algebra
Parker Glenn, Pravin Dakle, Liang Wang, and Preethi Raghavan. 2024.BLEND- SQL: A Scalable Dialect for Unifying Hybrid Question Answering in Relational Algebra. Technical Report. 453–466 pages. https://www.sqlite.org/
2024
-
[8]
Maarten Grootendorst. 2022. BERTopic: Neural topic modeling with a class-based TF-IDF procedure.CoRRabs/2203.05794 (2022). https://doi.org/10.48550/ARXIV. 2203.05794 arXiv:2203.05794
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv 2022
-
[9]
Yuxing Han, Ziniu Wu, Peizhi Wu, Rong Zhu, Jingyi Yang, Liang Wei Tan, Kai Zeng, Gao Cong, Yanzhao Qin, Andreas Pfadler, Zhengping Qian, Jingren Zhou, Jiangneng Li, and Bin Cui. 2021. Cardinality Estimation in DBMS: A Comprehensive Benchmark Evaluation.Proc. VLDB Endow.15, 4 (2021), 752–765. https://doi.org/10.14778/3503585.3503586
-
[10]
Benjamin Hilprecht, Andreas Schmidt, Moritz Kulessa, Alejandro Molina, Kris- tian Kersting, and Carsten Binnig. 2020. DeepDB: Learn from Data, not from Queries!, journal = Proc. VLDB Endow. 13, 7 (2020), 992–1005. https: //doi.org/10.14778/3384345.3384349
-
[11]
Yupeng Hou, Jiacheng Li, Zhankui He, An Yan, Xiusi Chen, and Julian McAuley
-
[12]
Bridging Language and Items for Retrieval and Recommendation.arXiv preprint arXiv:2403.03952(2024)
Pith/arXiv arXiv 2024
-
[13]
Saehan Jo and Immanuel Trummer. 2024. ThalamusDB: Approximate Query Processing on Multi-Modal Data.Proc. ACM Manag. Data2, 3 (2024), 186. https: //doi.org/10.1145/3654989
-
[14]
Andreas Kipf, Thomas Kipf, Bernhard Radke, Viktor Leis, Peter Boncz, and Al- fons Kemper. 2019. Learned Cardinalities: Estimating Correlated Joins with Deep Learning. In9th Biennial Conference on Innovative Data Systems Re- search, CIDR 2019, Asilomar, CA, USA, January 13-16, 2019, Online Proceedings. www.cidrdb.org. https://vldb.org/cidrdb/2019/learned-c...
2019
-
[15]
Udesh Kumarasinghe, Tyler Liu, Chunwei Liu, and Walid G Aref. 2026. iPDB– Optimizing SQL Queries with ML and LLM Predicates.arXiv preprint arXiv:2601.16432(2026)
Pith/arXiv arXiv 2026
-
[16]
Jiale Lao, Andreas Zimmerer, Olga Ovcharenko, Tianji Cong, Matthew Russo, Gerardo Vitagliano, Michael Cochez, Fatma Özcan, Gautam Gupta, Thibaud Hottelier, H. V. Jagadish, Kris Kissel, Sebastian Schelter, Andreas Kipf, and Im- manuel Trummer. 2025. SemBench: A Benchmark for Semantic Query Processing Engines.CoRRabs/2511.01716 (2025). arXiv:2511.01716
arXiv 2025
-
[17]
Viktor Leis, Andrey Gubichev, Atanas Mirchev, Peter Boncz, Alfons Kemper, and Thomas Neumann. 2015. How Good Are Query Optimizers, Really?Proc. VLDB Endow.9, 3 (2015), 204–215. https://doi.org/10.14778/2850583.2850594
-
[18]
Viktor Leis, Bernhard Radke, Andrey Gubichev, Alfons Kemper, and Thomas Neumann. 2017. Cardinality Estimation Done Right: Index-Based Join Sam- pling. In8th Biennial Conference on Innovative Data Systems Research, CIDR 2017, Chaminade, CA, USA, January 8-11, 2017, Online Proceedings. www.cidrdb.org. http://cidrdb.org/cidr2017/papers/p9-leis-cidr17.pdf
2017
-
[19]
Richard J. Lipton, Jeffrey F. Naughton, and Donovan A. Schneider. 1990. Practical Selectivity Estimation through Adaptive Sampling. InProceedings of the 1990 ACM SIGMOD International Conference on Management of Data, Atlantic City, NJ, USA, May 23-25, 1990, Hector Garcia-Molina and H. V. Jagadish (Eds.). ACM Press, 1–11. https://doi.org/10.1145/93597.93611
-
[20]
Pawel Liskowski, Benjamin Han, Paritosh Aggarwal, Bowei Chen, Boxin Jiang, Ni- tish Jindal, Zihan Li, Aaron Lin, Kyle Schmaus, Jay Tayade, Weicheng Zhao, Anu- pam Datta, Nathan Wiegand, and Dimitris Tsirogiannis. 2026. Cortex AISQL: A Production SQL Engine for Unstructured Data. InCompanion of the International Conference on Management of Data, SIGMOD Com...
-
[21]
Chunwei Liu, Matthew Russo, Michael Cafarella, Lei Cao, Peter Baile Chen, Zui Chen, Michael Franklin, Tim Kraska, Samuel Madden, Rana Shahout, and Gerardo Vitagliano. [n.d.]. Palimpzest: Optimizing AI-Powered Analytics with Declarative Query Processing. InProceedings of the Conference on Innovative Database Research (CIDR)(2025)
2025
-
[22]
Qiuyang Mang, Yufan Xiang, Hangrui Zhou, Runyuan He, Jiaxiang Yu, Hanchen Li, Aditya Parameswaran, and Alvin Cheung. 2026. PLOP: Cost-Based Placement of Semantic Operators in Hybrid Query Plans.arXiv preprint arXiv:2604.09944 (2026)
Pith/arXiv arXiv 2026
-
[23]
Ryan Marcus, Parimarjan Negi, Hongzi Mao, Chi Zhang, Mohammad Alizadeh, Tim Kraska, Olga Papaemmanouil, and Nesime Tatbul. 2019. Neo: A Learned Query Optimizer.Proc. VLDB Endow.12, 11 (July 2019), 1705–1718. https: //doi.org/10.14778/3342263.3342644
-
[24]
Leland McInnes, John Healy, and James Melville. 2018. Umap: Uniform man- ifold approximation and projection for dimension reduction.arXiv preprint arXiv:1802.03426(2018)
Pith/arXiv arXiv 2018
-
[25]
Guido Moerkotte, Thomas Neumann, and Gabriele Steidl. 2009. Preventing Bad Plans by Bounding the Impact of Cardinality Estimation Errors.Proc. VLDB Endow.2, 1 (2009), 982–993. https://doi.org/10.14778/1687627.1687738
-
[26]
Liana Patel, Siddharth Jha, Melissa Pan, Harshit Gupta, Parth Asawa, Carlos Guestrin, and Matei Zaharia. 2024. Semantic operators: a declarative model for rich, ai-based data processing.arXiv preprint arXiv:2407.11418(2024)
arXiv 2024
-
[27]
Liana Patel, Siddharth Jha, Melissa Pan, Harshit Gupta, Parth Asawa, Carlos Guestrin, and Matei Zaharia. 2025. Semantic operators and their optimization: En- abling llm-based data processing with accuracy guarantees in lotus.Proceedings of the VLDB Endowment18, 11 (2025), 4171–4184
2025
-
[28]
Matthew Russo, Sivaprasad Sudhir, Gerardo Vitagliano, Chunwei Liu, Tim Kraska, Samuel Madden, and Michael Cafarella. 2025. Abacus: A Cost-Based Optimizer for Semantic Operator Systems. (5 2025). http://arxiv.org/abs/2505.14661
arXiv 2025
-
[29]
Shreya Shankar, Tristan Chambers, Tarak Shah, Aditya G. Parameswaran, and Eugene Wu. 2025. DocETL: Agentic Query Rewriting and Evaluation for Complex Document Processing.Proc. VLDB Endow.18, 9 (Sept. 2025), 3035–3048. https: //doi.org/10.14778/3746405.3746426
-
[30]
Immanuel Trummer. 2025. Implementing Semantic Join Operators Effi- ciently.CoRRabs/2510.08489 (2025). https://doi.org/10.48550/ARXIV.2510.08489 arXiv:2510.08489
-
[31]
Michael Tschannen, Alexey Gritsenko, Xiao Wang, Muhammad Ferjad Naeem, Ibrahim Alabdulmohsin, Nikhil Parthasarathy, Talfan Evans, Lucas Beyer, Ye Xia, Basil Mustafa, Olivier Hénaff, Jeremiah Harmsen, Andreas Steiner, and Xiaohua Zhai. 2025. SigLIP 2: Multilingual Vision-Language Encoders with Improved Semantic Understanding, Localization, and Dense Featur...
Pith/arXiv arXiv 2025
-
[32]
Matthias Urban and Carsten Binnig. 2024. CAESURA: Language Models as Multi-Modal Query Planners. In14th Conference on Innovative Data Systems Research, CIDR 2024, Chaminade, HI, USA, January 14-17, 2024. www.cidrdb.org. https://www.cidrdb.org/cidr2024/papers/p14-urban.pdf
2024
-
[33]
Matthias Urban, Vu Huy Nguyen, Gabriele Sanmartino, Paolo Papotti, and Carsten Binnig. 2026. Selectivity Estimation for Semantic Filters on Image Data.arXiv preprint arXiv:2606.04610(2026)
Pith/arXiv arXiv 2026
-
[34]
Jiayi Wang, Yuan Li, Jianming Wu, Shihui Xu, and Guoliang Li. 2025. Unify: A System For Unstructured Data Analytics.Proc. VLDB Endow.18, 12 (2025), 5287–5290. https://doi.org/10.14778/3750601.3750653
-
[35]
Shihui Xu, Jiayi Wang, and Guoliang Li. 2026. Bridging the Gap: Cardinality Estimation for Semantic Queries on Unstructured Data.Proceedings of the ACM on Management of Data4, 3 (SIGMOD (2026), 1–26
2026
-
[36]
Zongheng Yang, Wei-Lin Chiang, Sifei Luan, Gautam Mittal, Michael Luo, and Ion Stoica. 2022. Balsa: Learning a Query Optimizer Without Expert Demonstrations. InSIGMOD ’22: International Conference on Management of Data, Philadelphia, PA, USA, June 12 - 17, 2022, Zachary G. Ives, Angela Bonifati, and Amr El Abbadi (Eds.). ACM, 931–944. https://doi.org/10.1...
-
[37]
Yanzhao Zhang, Mingxin Li, Dingkun Long, Xin Zhang, Huan Lin, Baosong Yang, Pengjun Xie, An Yang, Dayiheng Liu, Junyang Lin, Fei Huang, and Jingren Zhou
-
[38]
Qwen3 Embedding: Advancing Text Embedding and Reranking Through Foundation Models.arXiv preprint arXiv:2506.05176(2025). 7
Pith/arXiv arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.