EmbodimentSemantic: A Spatial Scene-Graph Dataset and Benchmark for Vision-Language Models on Embodied Manipulation Trajectories
Pith reviewed 2026-07-02 22:44 UTC · model grok-4.3
The pith
A spatial scene-graph benchmark shows vision-language models predict plausible relations but fail on exact depth-aware and viewpoint-dependent structure in manipulation scenes.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
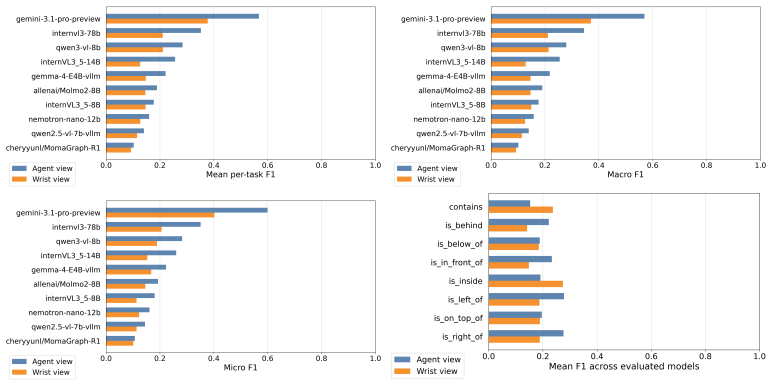
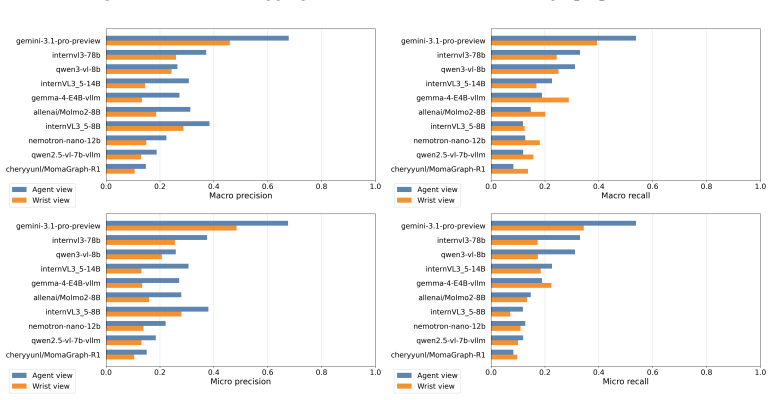
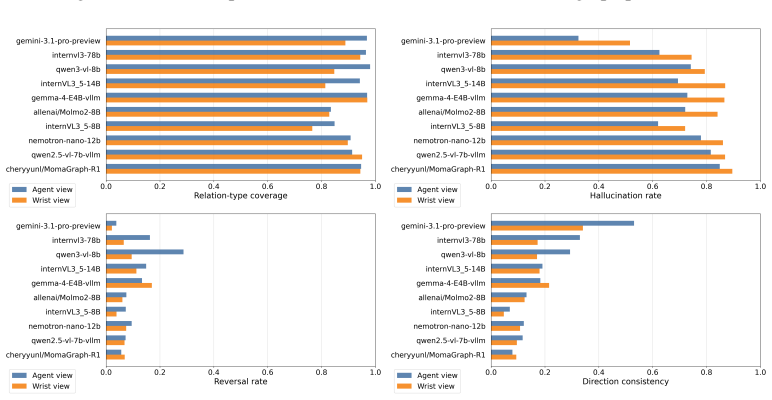
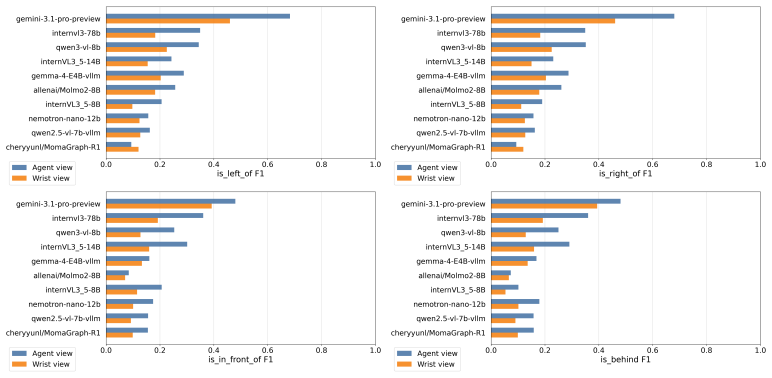
EmbodimentSemantic represents scenes as directed object-relation-object triplets that enable direct evaluation of object binding, relation prediction, and spatial consistency; the accompanying simulator-grounded benchmark supplies over 60K frames and 120K camera-specific scene graphs whose ground-truth relations are derived from MuJoCo geometry, world coordinates, camera projections, and visibility constraints, revealing that current VLMs often predict plausible relations but struggle with exact depth-aware and viewpoint-dependent spatial structure.
What carries the argument
Directed object-relation-object triplets that encode spatial relations between ordered object pairs, evaluated for binding accuracy, relation correctness, and cross-view consistency.
If this is right
- Scene graphs provide an explicit diagnostic for object binding and relation errors in VLM perception pipelines.
- Paired third-person and wrist-view graphs allow controlled measurement of viewpoint dependence.
- Injecting scene graphs into existing VLA prompts supplies a direct test of whether explicit spatial structure improves downstream control.
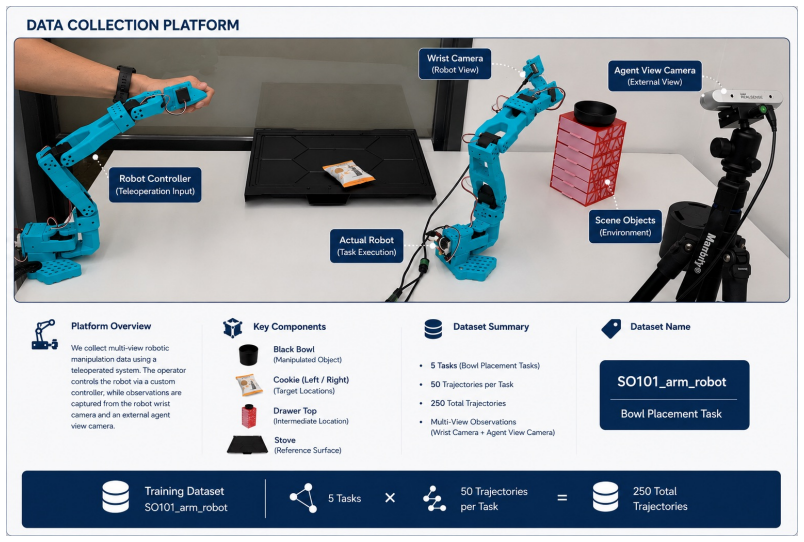
- The real-world SO101 trajectories extend the benchmark beyond simulation to practical robotic settings.
Where Pith is reading between the lines
- The triplet format could be used to generate synthetic training data that targets specific depth and occlusion failures observed in the models.
- Extending the relation vocabulary or adding temporal edges across frames might expose whether current limitations are static or motion-related.
- The benchmark setup offers a template for testing whether other relational representations, such as graphs with probabilistic edges, close the observed gaps.
Load-bearing premise
Ground-truth relations derived automatically from simulator geometry and projections match the spatial facts that determine successful manipulation.
What would settle it
An experiment in which VLA policies prompted with the derived scene graphs achieve no higher task success rate than identical policies without the graphs, or in which human judges systematically disagree with the simulator-derived relations on the same frames.
Figures



read the original abstract
Spatial grounding remains a key limitation of vision-language-action (VLA) systems for robotic manipulation. While current models can recognize objects and follow language instructions, they often lack an explicit representation of how objects are arranged in space, including support, containment, ordering, occlusion, and depth-sensitive relations. We introduce EmbodimentSemantic, a spatial scene-graph dataset and benchmark for evaluating relational grounding in embodied manipulation. EmbodimentSemantic represents scenes as directed object-relation-object triplets, where each triplet specifies a spatial relation between an ordered pair of objects using a fixed set of relations. This representation enables direct evaluation of object binding, relation prediction, and spatial consistency. The dataset includes real-world manipulation observations collected with the low-cost SO101 robot arm, together with generated scene graphs for studying spatial grounding in practical robotic settings. To provide controlled validation, we also introduce a simulator-grounded LIBERO benchmark with over 60K manipulation frames and more than 120K camera-specific scene graphs across paired third-person and wrist views, where ground-truth relations are derived automatically from MuJoCo geometry, world coordinates, camera projections, and visibility constraints. We further test whether scene graphs improve downstream control by injecting them into existing VLA policy prompts. Experiments across open-source and commercial VLMs show that current models often predict plausible relations but struggle with exact depth-aware and viewpoint-dependent spatial structure. EmbodimentSemantic provides a unified framework for diagnosing spatial grounding in VLM perception and testing its utility for VLA manipulation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces EmbodimentSemantic, a spatial scene-graph dataset and benchmark for evaluating relational grounding in vision-language models (VLMs) and vision-language-action (VLA) systems on embodied manipulation. It represents scenes as directed object-relation-object triplets using a fixed relation vocabulary, provides real-world trajectories from a SO101 robot arm, and introduces a simulator-grounded LIBERO benchmark with over 60K frames and >120K camera-specific scene graphs whose ground-truth relations are derived automatically from MuJoCo geometry, world coordinates, camera projections, and visibility constraints. Experiments on open-source and commercial VLMs are reported to show that models predict plausible relations but struggle with exact depth-aware and viewpoint-dependent structure; the paper also tests whether injecting scene graphs into VLA policy prompts improves downstream control.
Significance. If the automatically derived ground-truth relations prove reliable proxies for manipulation-relevant spatial facts, the benchmark would offer a concrete, scalable tool for diagnosing spatial grounding failures in VLMs and for measuring whether explicit scene-graph representations aid VLA policies. The dual real/simulated construction and evaluation across multiple model classes are positive features. The absence of any reported validation of the automatic labels against human judgments or task-success correlation, however, leaves the central diagnostic claim unsupported at present.
major comments (1)
- [Abstract] Abstract (benchmark construction paragraph): The headline claim that current VLMs 'struggle with exact depth-aware and viewpoint-dependent spatial structure' depends on the validity of the >120K MuJoCo-derived triplets as proxies for the spatial facts that determine manipulation success. No human-annotation agreement study, correlation with task success rates, or ablation of specific relation types is described to confirm that the automatic labels capture intended semantics rather than projection/visibility artifacts.
minor comments (1)
- [Abstract] Abstract: The phrasing 'over 60K manipulation frames and more than 120K camera-specific scene graphs across paired third-person and wrist views' leaves the exact counting convention (whether 120K counts both views separately or includes only valid visible triplets) unclear; a short clarifying sentence would help.
Simulated Author's Rebuttal
We thank the referee for their review and the opportunity to address concerns about the validity of our automatically derived ground-truth relations. We respond to the major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract (benchmark construction paragraph): The headline claim that current VLMs 'struggle with exact depth-aware and viewpoint-dependent spatial structure' depends on the validity of the >120K MuJoCo-derived triplets as proxies for the spatial facts that determine manipulation success. No human-annotation agreement study, correlation with task success rates, or ablation of specific relation types is described to confirm that the automatic labels capture intended semantics rather than projection/visibility artifacts.
Authors: The >120K triplets are derived deterministically from MuJoCo's exact 3D geometry, object poses, world coordinates, camera intrinsics/extrinsics, and visibility/occlusion computations. This produces objective, viewpoint-specific relations that directly encode the spatial facts (including depth ordering and occlusion) present in the simulated environment; projection and visibility are not artifacts but explicit components of the intended semantics for testing embodied perception. The benchmark therefore evaluates whether VLMs recover these precise structures rather than approximate human-like judgments. No human agreement study or task-success correlation is reported because the focus is on objective geometric grounding in a controlled simulator setting (with real-world SO101 trajectories providing a separate, manually annotated complement). An ablation across relation types is not included but the aggregate results already demonstrate consistent failures on depth- and viewpoint-sensitive relations across models. revision: no
Circularity Check
No circularity: dataset/benchmark definition with no equations or derivations
full rationale
The paper introduces EmbodimentSemantic as a new spatial scene-graph dataset and benchmark. Ground-truth relations are defined by construction from MuJoCo geometry, coordinates, projections, and visibility rules, but this is an explicit labeling procedure for the benchmark itself rather than a claimed derivation of a result from first principles. No equations, fitted parameters, predictions, or self-citation chains appear in the provided text. The experimental claims are direct evaluations of VLMs on this benchmark, with no reduction of outputs to inputs by construction. This matches the default case of a self-contained dataset contribution.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Vaswani, N
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, L. Kaiser, and I. Polosukhin. Attention is all you need. InAdvances in Neural Information Processing Systems, volume 30, 2017
2017
-
[2]
Ichter, A
B. Ichter, A. Brohan, Y . Chebotar, C. Finn, K. Hausman, A. Herzog, D. Ho, J. Ibarz, A. Irpan, E. Jang, R. Julian, D. Kalashnikov, S. Levine, Y . Lu, C. Parada, K. Rao, P. Sermanet, A. T. Toshev, V . Vanhoucke, F. Xia, T. Xiao, P. Xu, M. Yan, N. Brown, M. Ahn, O. Cortes, N. Sievers, C. Tan, S. Xu, D. Reyes, J. Rettinghouse, J. Quiambao, P. Pastor, L. Luu,...
-
[3]
URLhttps://proceedings.mlr.press/v205/ichter23a.html
-
[4]
K. Black, N. Brown, D. Driess, A. Esmail, M. R. Equi, C. Finn, N. Fusai, L. Groom, K. Hausman, B. Ichter, S. Jakubczak, T. Jones, L. Ke, S. Levine, A. Li-Bell, M. Mothukuri, S. Nair, K. Pertsch, L. X. Shi, L. Smith, J. Tanner, Q. Vuong, A. Walling, H. Wang, and U. Zhilinsky.π0: A vision- language-action flow model for general robot control. InProceedings ...
-
[5]
Zitkovich, T
B. Zitkovich, T. Yu, S. Xu, P. Xu, T. Xiao, F. Xia, J. Wu, P. Wohlhart, S. Welker, A. Wahid, Q. Vuong, V . Vanhoucke, H. Tran, R. Soricut, A. Singh, J. Singh, P. Sermanet, P. R. Sanketi, G. Salazar, M. S. Ryoo, K. Reymann, K. Rao, K. Pertsch, I. Mordatch, H. Michalewski, Y . Lu, S. Levine, L. Lee, T.-W. E. Lee, I. Leal, Y . Kuang, D. Kalashnikov, R. Julia...
2023
-
[6]
M. J. Kim, K. Pertsch, S. Karamcheti, T. Xiao, A. Balakrishna, S. Nair, R. Rafailov, E. P. Foster, P. R. Sanketi, Q. Vuong, T. Kollar, B. Burchfiel, R. Tedrake, D. Sadigh, S. Levine, P. Liang, and C. Finn. OpenVLA: An open-source vision-language-action model. InProceedings of The 8th Conference on Robot Learning, volume 270 ofProceedings of Machine Learni...
2025
-
[7]
Y . Xing, X. Luo, J. Xie, L. Gao, H. T. Shen, and J. Song. Shortcut learning in generalist robot policies: The role of dataset diversity and fragmentation. In J. Lim, S. Song, and H.-W. Park, editors,Proceedings of The 9th Conference on Robot Learning, volume 305 of Proceedings of Machine Learning Research, pages 3239–3266. PMLR, 27–30 Sep 2025. URL https...
2025
-
[8]
Zhang, S
J. Zhang, S. Wu, X. Luo, H. Wu, L. Gao, H. T. Shen, and J. Song. InSpire: Vision-language- action models with intrinsic spatial reasoning, 2025
2025
-
[9]
I. Fang, J. Zhang, S. Tong, and C. Feng. From intention to execution: Probing the generalization boundaries of vision-language-action models.arXiv preprint arXiv:2506.09930, 2025. doi: 10.48550/arXiv.2506.09930
-
[10]
B. Chen, Z. Xu, S. Kirmani, B. Ichter, D. Sadigh, L. Guibas, and F. Xia. Spatialvlm: Endowing vision-language models with spatial reasoning capabilities. In2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 14455–14465, 2024. doi:10.1109/ CVPR52733.2024.01370
-
[11]
C. H. Song, V . Blukis, J. Tremblay, S. Tyree, Y . Su, and S. Birchfield. RoboSpatial: Teaching spatial understanding to 2D and 3D vision-language models for robotics. InProceedings of 16 the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 15768–15780, 2025
2025
-
[12]
D. Qu, H. Song, Q. Chen, Y . Yao, X. Ye, J. Gu, Z. Wang, Y . Ding, B. Zhao, D. Wang, and X. Li. SpatialVLA: Exploring Spatial Representations for Visual-Language-Action Models. InProceedings of Robotics: Science and Systems, LosAngeles, CA, USA, June 2025. doi: 10.15607/RSS.2025.XXI.011
-
[13]
P. W. Battaglia, D. Kersten, and P. R. Schrater. How haptic size sensations improve distance perception.PLoS Computational Biology, 7(6):e1002080, 2011. doi:10.1371/journal.pcbi. 1002080
-
[14]
Y . Xiang, T. Schmidt, V . Narayanan, and D. Fox. PoseCNN: A convolutional neural network for 6D object pose estimation in cluttered scenes. InProceedings of Robotics: Science and Systems, 2018. doi:10.15607/RSS.2018.XIV .019
-
[15]
Tremblay, T
J. Tremblay, T. To, B. Sundaralingam, Y . Xiang, D. Fox, and S. Birchfield. Deep object pose estimation for semantic robotic grasping of household objects. InProceedings of The 2nd Conference on Robot Learning, volume 87 ofProceedings of Machine Learning Research, pages 306–316. PMLR, 2018
2018
-
[16]
Hodan, F
T. Hodan, F. Michel, E. Brachmann, W. Kehl, A. GlentBuch, D. Kraft, B. Drost, J. Vidal, S. Ihrke, X. Zabulis, C. Sahin, F. Manhardt, F. Tombari, T.-K. Kim, J. Matas, and C. Rother. BOP: Benchmark for 6D object pose estimation. InProceedings of the European Conference on Computer Vision, pages 19–34, 2018
2018
-
[17]
S. Hutchinson, G. D. Hager, and P. I. Corke. A tutorial on visual servo control.IEEE Transactions on Robotics and Automation, 12(5):651–670, 1996. doi:10.1109/70.538972
-
[18]
F. Chaumette and S. Hutchinson. Visual servo control. i. basic approaches.IEEE Robotics & Automation Magazine, 13(4):82–90, 2006. doi:10.1109/MRA.2006.250573
-
[19]
Shridhar, L
M. Shridhar, L. Manuelli, and D. Fox. Perceiver-actor: A multi-task transformer for robotic manipulation. InProceedings of The 6th Conference on Robot Learning, volume 205 of Proceedings of Machine Learning Research, pages 785–799. PMLR, 2023
2023
-
[20]
Goyal, J
A. Goyal, J. Xu, Y . Guo, V . Blukis, Y .-W. Chao, and D. Fox. RVT: Robotic view transformer for 3D object manipulation. InProceedings of The 7th Conference on Robot Learning, volume 229 ofProceedings of Machine Learning Research, pages 694–710. PMLR, 2023
2023
-
[21]
X. Li, M. Zhang, Y . Geng, H. Geng, Y . Long, Y . Shen, R. Zhang, J. Liu, and H. Dong. Mani- pLLM: Embodied multimodal large language model for object-centric robotic manipulation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 18061–18070, 2024
2024
-
[22]
H. Li, Q. Feng, Z. Zheng, J. Feng, Z. Chen, and A. Knoll. Language-guided object-centric diffusion policy for generalizable and collision-aware manipulation. In2025 IEEE International Conference on Robotics and Automation (ICRA), pages 12834–12841, 2025. doi:10.1109/ ICRA55743.2025.11127231
-
[23]
C.-C. Hsu, B. Wen, J. Xu, Y . Narang, X. Wang, Y . Zhu, J. Biswas, and S. Birchfield. Spot: Se(3) pose trajectory diffusion for object-centric manipulation. InIEEE International Conference on Robotics and Automation (ICRA), 2025
2025
-
[24]
X. Li, L. Heng, J. Liu, Y . Shen, C. Gu, Z. Liu, H. Chen, N. Han, R. Zhang, H. Tang, S. Zhang, and H. Dong. 3DS-VLA: A 3D spatial-aware vision language action model for robust multi- task manipulation. InProceedings of The 9th Conference on Robot Learning, volume 305 of Proceedings of Machine Learning Research, pages 2344–2359. PMLR, 2025. 17
2025
-
[25]
Krishna, Y
R. Krishna, Y . Zhu, O. Groth, J. Johnson, K. Hata, J. Kravitz, S. Chen, Y . Kalantidis, L.-J. Li, D. A. Shamma, et al. Visual genome: Connecting language and vision using crowdsourced dense image annotations.International Journal of Computer Vision, 123:32–73, 2017
2017
-
[26]
K. Yang, O. Russakovsky, and J. Deng. SpatialSense: An adversarially crowdsourced benchmark for spatial relation recognition. InProceedings of the IEEE/CVF International Conference on Computer Vision, 2019
2019
-
[27]
F. Liu, G. Emerson, and N. Collier. Visual spatial reasoning.Transactions of the Association for Computational Linguistics, 11:635–651, 06 2023. ISSN 2307-387X. doi:10.1162/tacl_a_00566. URLhttps://doi.org/10.1162/tacl_a_00566
-
[28]
T. Thrush, R. Jiang, M. Bartolo, A. Singh, A. Williams, D. Kiela, and C. Ross. Winoground: Probing vision and language models for visio-linguistic compositionality. In2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 5228–5238, 2022. doi:10.1109/CVPR52688.2022.00517
-
[29]
J. Wang, Y . Ming, Z. Shi, V . Vineet, X. Wang, Y . Li, and N. Joshi. Is a pic- ture worth a thousand words? delving into spatial reasoning for vision language mod- els, 2024. URL https://proceedings.neurips.cc/paper_files/paper/2024/file/ 89cc5e613d34f90de90c21e996e60b30-Paper-Conference.pdf
2024
-
[30]
B. Liu, Y . Zhu, C. Gao, Y . Feng, Q. Liu, Y . Zhu, and P. Stone. Libero: Bench- marking knowledge transfer for lifelong robot learning. In A. Oh, T. Naumann, A. Globerson, K. Saenko, M. Hardt, and S. Levine, editors,Advances in Neural Information Processing Systems, volume 36, pages 44776–44791. Curran Associates, Inc., 2023. URL https://proceedings.neur...
2023
-
[31]
A. Zeng, M. Attarian, brian ichter, K. M. Choromanski, A. Wong, S. Welker, F. Tombari, A. Purohit, M. S. Ryoo, V . Sindhwani, J. Lee, V . Vanhoucke, and P. Florence. Socratic models: Composing zero-shot multimodal reasoning with language. InThe Eleventh International Conference on Learning Representations, 2023. URL https://openreview.net/forum? id=G2Q2Mh3avow
2023
-
[32]
Cheng, H
A.-C. Cheng, H. Yin, Y . Fu, Q. Guo, R. Yang, J. Kautz, X. Wang, and S. Liu. SpatialRGPT: Grounded spatial reasoning in vision-language models. InAdvances in Neural Information Processing Systems, 2024
2024
-
[33]
M. Du, B. Wu, Z. Li, X. Huang, and Z. Wei. EmbSpatial-Bench: Benchmarking spatial understanding for embodied tasks with large vision-language models. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics, Volume 2: Short Papers, pages 346–355, 2024
2024
-
[34]
Z. Feng, Z. Kang, Q. Wang, Z. Du, J. Yan, S. Shubin, C. Yuan, H. Liang, Y . Deng, Q. Li, R. Yang, R. An, L. Zheng, W. Wang, S. Chen, S. Xu, Y . Liang, J. Yang, and B. Guo. Seeing across views: Benchmarking spatial reasoning of vision-language models in robotic scenes. In The Fourteenth International Conference on Learning Representations, 2026. URL https:...
2026
-
[35]
S. James, Z. Ma, D. R. Arrojo, and A. J. Davison. RLBench: The robot learning benchmark & learning environment.IEEE Robotics and Automation Letters, 5(2):3019–3026, 2020. doi: 10.1109/LRA.2020.2974707
-
[36]
Reinforcement learning with human feedback for realistic traffic simulation
A. O’Neill, A. Rehman, A. Maddukuri, A. Gupta, A. Padalkar, A. Lee, A. Pooley, A. Gupta, A. Mandlekar, A. Jain, A. Tung, A. Bewley, A. Herzog, A. Irpan, A. Khazatsky, A. Rai, A. Gupta, A. Wang, A. Singh, A. Garg, A. Kembhavi, A. Xie, A. Brohan, A. Raffin, A. Sharma, A. Yavary, A. Jain, A. Balakrishna, A. Wahid, B. Burgess-Limerick, B. Kim, B. Schölkopf, 1...
-
[37]
A. Brohan, N. Brown, J. Carbajal, Y . Chebotar, J. Dabis, C. Finn, K. Gopalakrishnan, K. Haus- man, A. Herzog, J. Hsu, J. Ibarz, B. Ichter, A. Irpan, T. Jackson, S. Jesmonth, N. Joshi, R. Julian, D. Kalashnikov, Y . Kuang, I. Leal, K.-H. Lee, S. Levine, Y . Lu, U. Malla, D. Manjunath, I. Mordatch, O. Nachum, C. Parada, J. Peralta, E. Perez, K. Pertsch, J....
-
[38]
Driess, F
D. Driess, F. Xia, M. S. M. Sajjadi, C. Lynch, A. Chowdhery, B. Ichter, A. Wahid, J. Tompson, Q. Vuong, T. Yu, W. Huang, Y . Chebotar, P. Sermanet, D. Duckworth, S. Levine, V . Vanhoucke, K. Hausman, M. Toussaint, K. Greff, A. Zeng, I. Mordatch, and P. Florence. PaLM-e: An embodied multimodal language model. In A. Krause, E. Brunskill, K. Cho, B. Engelhar...
2023
-
[39]
Q. Zhao, Y . Lu, M. J. Kim, Z. Fu, Z. Zhang, Y . Wu, Z. Li, Q. Ma, S. Han, C. Finn, A. Handa, T.-Y . Lin, G. Wetzstein, M.-Y . Liu, and D. Xiang. Cot-vla: Visual chain-of-thought reasoning for vision-language-action models. In2025 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 1702–1713, 2025. doi:10.1109/CVPR52734.2025.00166
-
[40]
H. Huang, M. Cen, K. Tan, X. Quan, G. Huang, and H. Zhang. GraphCoT-VLA: A 3D spatial-aware reasoning vision-language-action model for robotic manipulation with ambiguous 19 instructions.Proceedings of the AAAI Conference on Artificial Intelligence, 40(22):18324– 18332, 2026. doi:10.1609/aaai.v40i22.38896
-
[41]
X. Zhou, Y . Xu, G. Tie, Y . Chen, G. Zhang, D. Chu, P. Zhou, and L. Sun. Libero-pro: Towards robust and fair evaluation of vision-language-action models beyond memorization, 2026. URL https://arxiv.org/abs/2510.03827
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[42]
S. Fei, S. Wang, J. Shi, Z. Dai, J. Cai, P. Qian, J. Li, X. He, S. Zhang, Z. Fei, et al. LIBERO-Plus: In-depth robustness analysis of vision-language-action models, 2025
2025
-
[43]
SlotVLA: Towards Modeling of Object-Relation Representations in Robotic Manipulation
T. Hanyu, N. Chung, H. Le, T. Nguyen, Y . Ikebe, A. Gunderman, D. N. H. Minh, K. V o, T. Kieu, K. Yamazaki, C. Rainwater, A. Nguyen, and N. Le. SlotVLA: Towards Modeling of Object- Relation Representations in Robotic Manipulation.arXiv e-prints, art. arXiv:2511.06754, Nov
work page internal anchor Pith review Pith/arXiv arXiv
-
[44]
doi:10.48550/arXiv.2511.06754
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2511.06754
-
[45]
Liang, G
W. Liang, G. Sun, Y . He, J. Dong, S. Dai, I. Laptev, S. Khan, and Y . Cong. PixelVLA: Advancing pixel-level understanding in vision-language-action model. InThe Fourteenth International Conference on Learning Representations, 2026. URL https://openreview.net/forum? id=7M6ryCABIc
2026
-
[46]
Cadene, S
R. Cadene, S. Alibert, F. Capuano, M. Aractingi, A. Zouitine, P. Kooijmans, J. Choghari, M. Russi, C. Pascal, S. Palma, D. Aubakirova, M. Shukor, J. Moss, A. Soare, Q. Lhoest, Q. Gallouédec, and T. Wolf. Lerobot: An open-source library for end-to-end robot learning. InThe Fourteenth International Conference on Learning Representations, 2026. URLhttps: //o...
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.