Beyond Perplexity: A Geometric and Spectral Study of Low-Rank Pre-Training
Pith reviewed 2026-05-20 20:19 UTC · model grok-4.3
The pith
Low-rank pre-training methods converge to geometrically distinct loss basins compared to full-rank training, even when validation perplexity matches closely.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
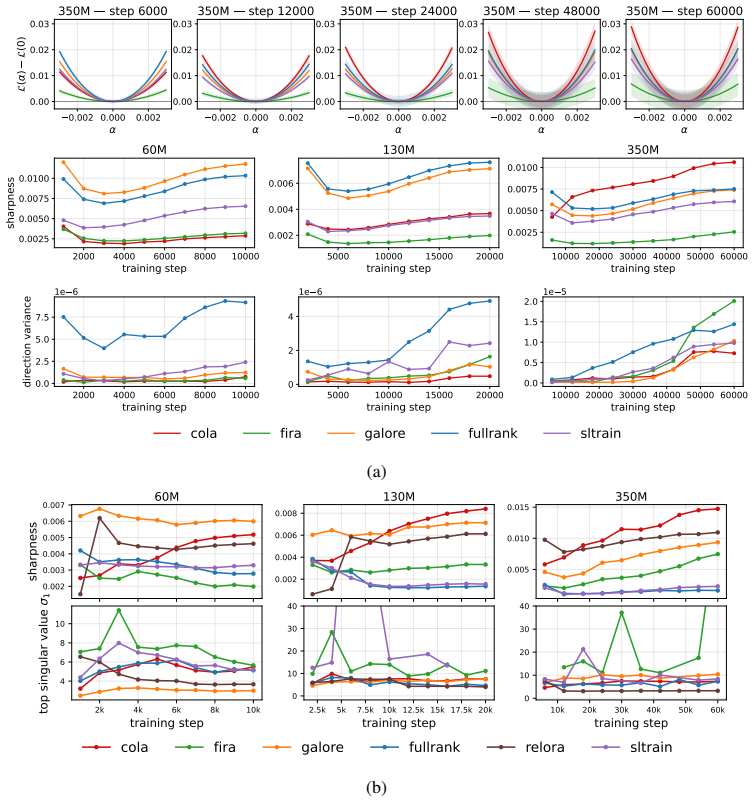
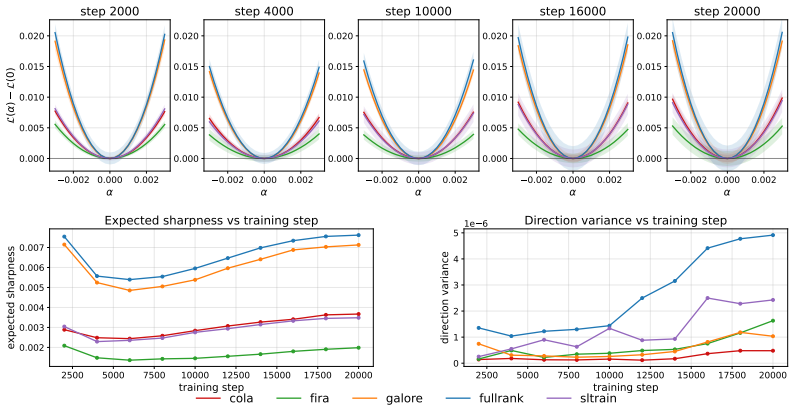
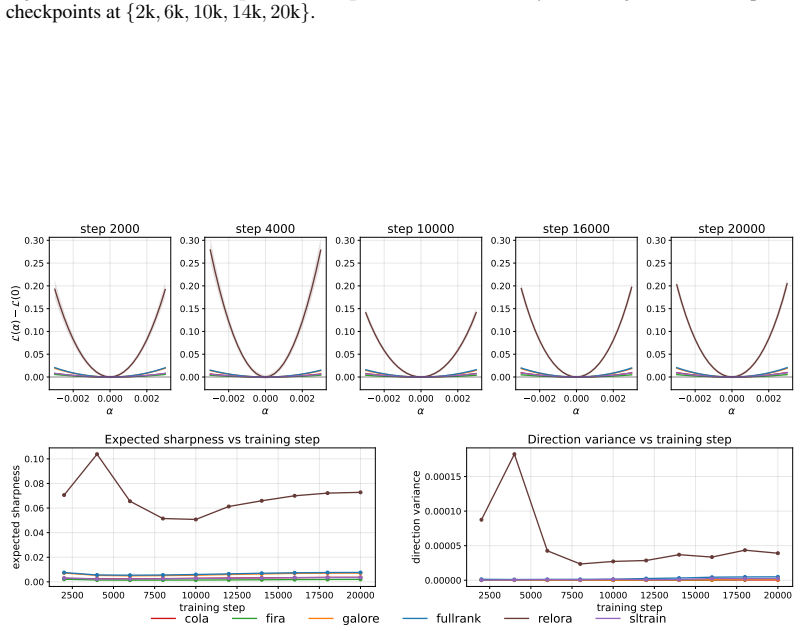
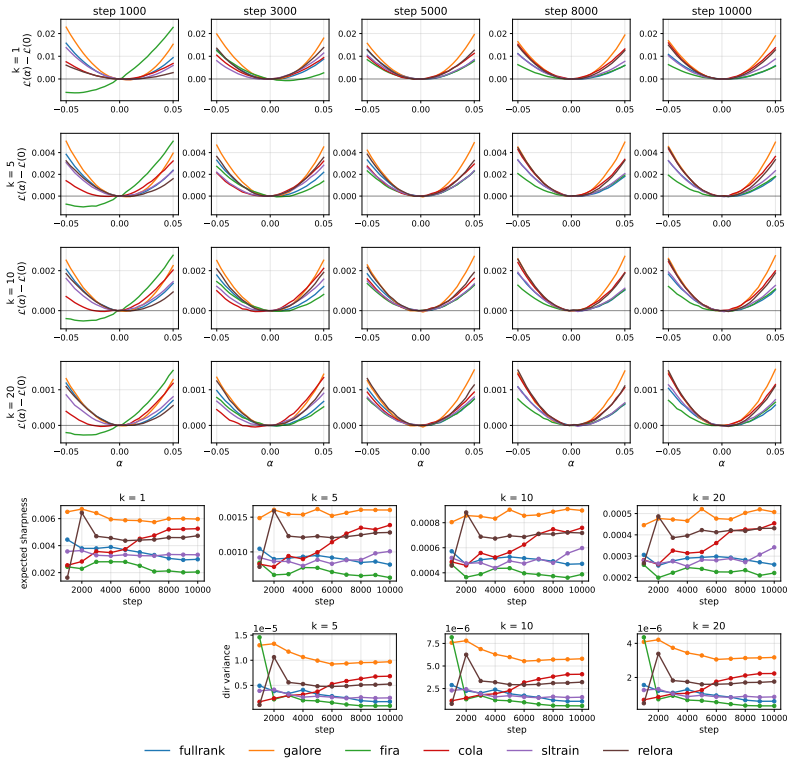
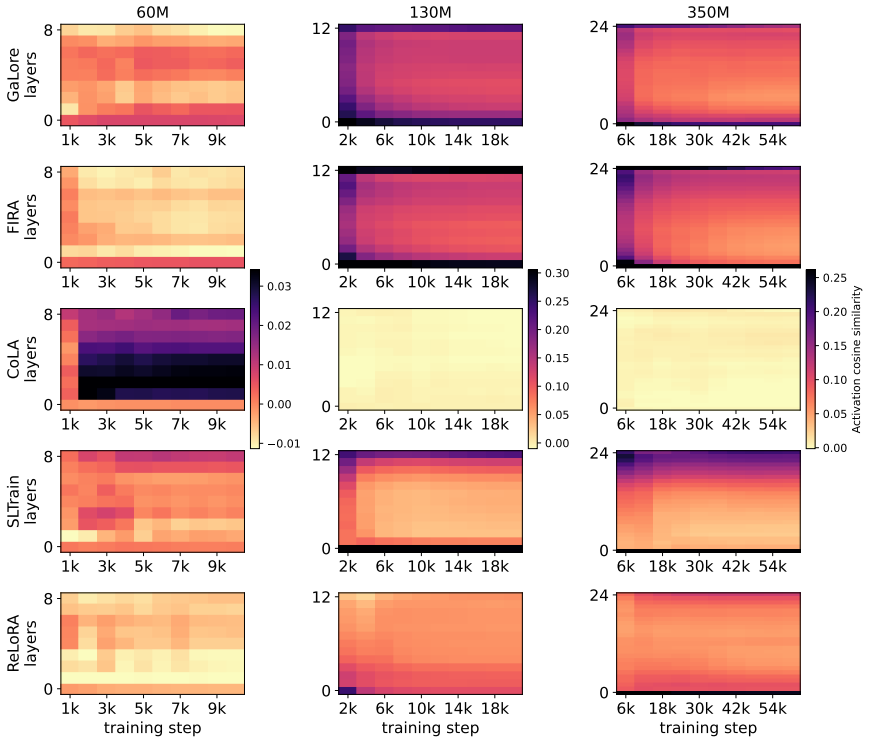
Low-rank pre-training methods including GaLore, Fira, CoLA, SLTrain, and ReLoRA are not equivalent to full-rank training or to each other. Full-rank training settles into a sharper basin along random directions while low-rank methods show the reverse along the top-1 PCA direction, with each method converging to a geometrically distinct basin. Low-rank activations diverge from full-rank in later layers as training progresses, with GaLore tracking full-rank most closely. Validation perplexity does not always translate to downstream performance, and adding geometric and spectral metrics improves prediction of such performance.
What carries the argument
1-D loss landscape analysis along random and top-K PCA directions together with spectral structure of weights and updates and activation similarity to full-rank training. These metrics expose geometric and spectral distinctions between the solutions found by different methods.
If this is right
- Perplexity alone cannot be used to claim that low-rank methods produce models comparable to full-rank training.
- Each low-rank technique reaches a unique basin geometry, so method choice affects the final solution properties.
- Activation divergence in later layers suggests internal representations differ even when surface metrics look similar.
- Geometric and spectral metrics can supplement perplexity to better forecast downstream performance.
- Low-rank methods are not interchangeable with each other for the same reason they differ from full-rank training.
Where Pith is reading between the lines
- At larger model scales the geometric distinctions might become more or less pronounced, affecting which method is preferable for specific tasks.
- The distinct basins could influence model robustness or transfer to new domains in ways not captured by the current metrics.
- Practitioners might select a low-rank method based on desired spectral characteristics rather than assuming all low-rank approaches behave alike.
- Future experiments could test whether these geometric differences persist or change when models are fine-tuned on downstream data.
Load-bearing premise
That observed differences in loss landscape geometry, spectral properties, and activations reliably indicate non-equivalent generalization and internal representations across methods.
What would settle it
A demonstration that low-rank and full-rank models achieve identical downstream task performance and identical layer-wise activation distributions at multiple scales despite the reported geometric and spectral differences.
Figures














read the original abstract
Pre-training large language models is dominated by the memory cost of storing full-rank weights, gradients, and optimizer states. Low-rank pre-training has emerged to address this, and the space of methods has grown rapidly. A central question remains open: do low-rank methods produce models that generalize comparably to full-rank training, or does the rank constraint fundamentally alter the solutions reached? Existing comparisons rely almost entirely on validation perplexity from single-seed runs, often carried forward from prior literature. Yet perplexity is a poor proxy for solution quality; two methods can match on perplexity while converging to different loss landscape regions and internal representations. We close this gap by characterizing the solutions found by five low-rank pre-training methods, GaLore and Fira (memory-efficient optimizers), CoLA and SLTrain (architecture reparameterizations), and ReLoRA (adapter-style updates with periodic resets), against full-rank training at three model scales (60M, 130M, 350M). We evaluate each along 16 metrics across four dimensions: 1-D loss landscape along random/top-K PCA directions, 1-D interpolation between checkpoints, spectral structure of the weights and learned updates, and activation similarity to full-rank training. We show that low-rank methods are not equivalent to full-rank training, nor to one another, even when validation perplexity is close. Full-rank training settles into a sharper basin than low-rank methods along random directions, while the reverse holds for the top-1 PCA direction. Each method converges to a geometrically distinct basin. Low-rank activations diverge from full-rank in later layers as training progresses, with GaLore tracking full-rank most closely. Further, validation perplexity does not translate to downstream performance at every scale. Adding geometric and spectral metrics improves the prediction.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper empirically compares five low-rank pre-training methods (GaLore, Fira, CoLA, SLTrain, ReLoRA) against full-rank training on language models at 60M, 130M, and 350M scales. It uses 16 metrics spanning 1-D loss-landscape slices (random and top-K PCA directions), checkpoint interpolation, spectral properties of weights/updates, and activation similarities to argue that low-rank methods reach geometrically distinct basins from full-rank and from each other, even at matched validation perplexity, and that perplexity alone is a poor predictor of downstream performance.
Significance. If the geometric and spectral distinctions hold under replication, the work provides a useful demonstration that perplexity matching does not imply solution equivalence in low-rank LLM training. The multi-scale design and breadth of metrics (loss curvature, spectral structure, activation divergence) offer a concrete template for more informative method comparisons beyond scalar performance numbers.
major comments (2)
- [Experimental results and evaluation protocol] The central non-equivalence claim rests on observed differences in 1-D loss-landscape curvature (random vs. top-1 PCA directions) and layer-wise activation divergence. However, the experiments appear to follow the single-seed protocol critiqued in the abstract for prior work; no variance across independent runs, standard errors, or statistical tests are reported. This is load-bearing because stochastic effects from initialization, data ordering, or optimizer state could produce the reported basin differences without any systematic effect of the rank constraint.
- [Downstream evaluation and metric utility] The statement that 'adding geometric and spectral metrics improves the prediction' of downstream performance is presented without quantitative details on the regression or classification setup, the specific downstream tasks, or the improvement magnitude at each scale. This weakens the practical takeaway that the 16-metric suite is superior to perplexity alone.
minor comments (2)
- [Metric definitions] Notation for the 16 metrics is introduced in the abstract but would benefit from an explicit table or appendix listing each metric, its mathematical definition, and the exact directions or layers used.
- [Figures] Figure captions for the loss-landscape slices should state the number of points sampled along each direction and the step size to allow direct reproduction.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below and indicate the revisions we will incorporate.
read point-by-point responses
-
Referee: [Experimental results and evaluation protocol] The central non-equivalence claim rests on observed differences in 1-D loss-landscape curvature (random vs. top-1 PCA directions) and layer-wise activation divergence. However, the experiments appear to follow the single-seed protocol critiqued in the abstract for prior work; no variance across independent runs, standard errors, or statistical tests are reported. This is load-bearing because stochastic effects from initialization, data ordering, or optimizer state could produce the reported basin differences without any systematic effect of the rank constraint.
Authors: We agree that reliance on single-seed runs is a limitation, especially since the manuscript itself critiques this practice in prior work. Training at these scales is computationally intensive, which constrained our initial experimental design. In the revised manuscript we will add results from at least three independent random seeds for the 60M and 130M models, reporting means and standard deviations for the primary geometric and spectral metrics. For the 350M scale we will explicitly acknowledge the single-seed constraint and discuss its implications for the strength of the claims. These additions will help demonstrate that the observed basin differences are not attributable solely to stochastic variation. revision: yes
-
Referee: [Downstream evaluation and metric utility] The statement that 'adding geometric and spectral metrics improves the prediction' of downstream performance is presented without quantitative details on the regression or classification setup, the specific downstream tasks, or the improvement magnitude at each scale. This weakens the practical takeaway that the 16-metric suite is superior to perplexity alone.
Authors: We thank the referee for highlighting this gap. The current manuscript states the predictive improvement at a high level without the supporting experimental details. In the revision we will expand the relevant section to specify the downstream tasks, the regression setup (including the model type and feature sets), the quantitative gains (e.g., changes in R² or prediction error) when geometric and spectral metrics are added versus perplexity alone, and results disaggregated by model scale. This will make the claim concrete and reproducible. revision: yes
Circularity Check
Empirical comparison of low-rank methods uses independent metrics with no definitional or fitted circularity
full rationale
The paper reports direct empirical measurements on trained models: 1-D loss landscape slices along random and PCA directions, spectral analysis of weights/updates, activation similarities, and downstream performance. These are applied as separate evaluation procedures to full-rank and low-rank runs at matched perplexity. No step defines a quantity in terms of another that is then re-used as a prediction, no fitted parameters are renamed as forecasts, and no uniqueness theorems or ansatzes are imported via self-citation. The non-equivalence conclusion follows from the observed differences across the 16 metrics rather than from any reduction to the input training configurations by construction. The work is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Gradient-based optimization on the chosen loss landscape produces representative solutions for the model scales tested.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We show that low-rank methods ... converge to a geometrically distinct basin. ... spectral structure of the weights and learned updates
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Maksym Andriushchenko, Francesco Croce, Maximilian Müller, Matthias Hein, and Nicolas Flammarion. A modern look at the relationship between sharpness and generalization.arXiv preprint arXiv:2302.07011, 2023
-
[2]
Understanding pre-training and fine-tuning from loss landscape perspectives,
Huanran Chen, Yinpeng Dong, Zeming Wei, Yao Huang, Yichi Zhang, Hang Su, and Jun Zhu. Unveiling the basin-like loss landscape in large language models.arXiv preprint arXiv:2505.17646, 2025
-
[3]
Xi Chen, Kaituo Feng, Changsheng Li, Xunhao Lai, Xiangyu Yue, Ye Yuan, and Guoren Wang. Fira: Can we achieve full-rank training of llms under low-rank constraint?ArXiv, abs/2410.01623, 2024
-
[4]
Linear mode connectivity and the lottery ticket hypothesis
Jonathan Frankle, Gintare Karolina Dziugaite, Daniel Roy, and Michael Carbin. Linear mode connectivity and the lottery ticket hypothesis. InInternational conference on machine learning, pages 3259–3269. PMLR, 2020
work page 2020
-
[5]
The language model evaluation harness, 07 2024
Leo Gao, Jonathan Tow, Baber Abbasi, Stella Biderman, Sid Black, Anthony DiPofi, Charles Foster, Laurence Golding, Jeffrey Hsu, Alain Le Noac’h, Haonan Li, Kyle McDonell, Niklas Muennighoff, Chris Ociepa, Jason Phang, Laria Reynolds, Hailey Schoelkopf, Aviya Skowron, Lintang Sutawika, Eric Tang, Anish Thite, Ben Wang, Kevin Wang, and Andy Zou. The languag...
work page 2024
-
[6]
Andi Han, Jiaxiang Li, Wei Huang, Mingyi Hong, Akiko Takeda, Pratik Jawanpuria, and Bamdev Mishra. SLTrain: a sparse plus low-rank approach for parameter and memory efficient pretraining.arXiv preprint arXiv:2406.02214, 2024
-
[7]
Flora: Low-rank adapters are secretly gradient compressors,
Yongchang Hao, Yanshuai Cao, and Lili Mou. Flora: Low-rank adapters are secretly gradient compressors.arXiv preprint arXiv:2402.03293, 2024
-
[8]
Galore-mini: Low rank gradient learning with fewer learning rates
Weihao Huang, Zhenyu Zhang, Yushun Zhang, Zhi-Quan Luo, Ruoyu Sun, and Zhangyang Wang. Galore-mini: Low rank gradient learning with fewer learning rates. InNeurIPS 2024 Workshop on Fine-Tuning in Modern Machine Learning: Principles and Scalability, 2024
work page 2024
-
[9]
From galore to welore: How low-rank weights non-uniformly emerge from low-rank gradients
AJAY KUMAR JAISW AL, Lu Yin, Zhenyu Zhang, Shiwei Liu, Jiawei Zhao, Yuandong Tian, and Zhangyang Wang. From galore to welore: How low-rank weights non-uniformly emerge from low-rank gradients
-
[10]
I Can’t Believe It’s Not Better! - Understanding Deep Learning Through Empirical Falsification
Simran Kaur, Jeremy Cohen, and Zachary Chase Lipton. On the maximum hessian eigenvalue and generalization. In Javier Antorán, Arno Blaas, Fan Feng, Sahra Ghalebikesabi, Ian Mason, Melanie F. Pradier, David Rohde, Francisco J. R. Ruiz, and Aaron Schein, editors,Proceedings on "I Can’t Believe It’s Not Better! - Understanding Deep Learning Through Empirical...
work page 2022
-
[11]
Similarity of neural network representations revisited
Simon Kornblith, Mohammad Norouzi, Honglak Lee, and Geoffrey Hinton. Similarity of neural network representations revisited. InInternational Conference on Machine Learning (ICML), 2019
work page 2019
-
[12]
Visualizing the loss landscape of neural nets
Hao Li, Zheng Xu, Gavin Taylor, Christoph Studer, and Tom Goldstein. Visualizing the loss landscape of neural nets. InAdvances in Neural Information Processing Systems (NeurIPS), 2018
work page 2018
-
[13]
Jiaxi Li, Lu Yin, Li Shen, Jinjin Xu, Liwu Xu, Tianjin Huang, Wenwu Wang, Shiwei Liu, and Xilu Wang. Lost: Low-rank and sparse pre-training for large language models.arXiv preprint arXiv:2508.02668, 2025
-
[14]
Flat-lora: Low-rank adaptation over a flat loss landscape.arXiv preprint arXiv:2409.14396, 2024
Tao Li, Zhengbao He, Yujun Li, Yasheng Wang, Lifeng Shang, and Xiaolin Huang. Flat-lora: Low-rank adaptation over a flat loss landscape.arXiv preprint arXiv:2409.14396, 2024
-
[15]
ReLoRA: High-Rank Training Through Low-Rank Updates
Vladislav Lialin, Sherin Muckatira, Namrata Shivagunde, and Anna Rumshisky. ReLoRA: High-Rank Training Through Low-Rank Updates. InThe Twelfth International Conference on Learning Representations, ICLR 2024, Vienna, Austria, May 7-11, 2024. OpenReview.net, 2024. 10
work page 2024
-
[16]
Same pre-training loss, better downstream: Implicit bias matters for language models
Hong Liu, Sang Michael Xie, Zhiyuan Li, and Tengyu Ma. Same pre-training loss, better downstream: Implicit bias matters for language models. InInternational Conference on Machine Learning, 2022
work page 2022
-
[17]
On the optimization landscape of low rank adaptation methods for large language models
Xu-Hui Liu, Yali Du, Jun Wang, and Yang Yu. On the optimization landscape of low rank adaptation methods for large language models. InThe Thirteenth International Conference on Learning Representations, 2025
work page 2025
-
[18]
Cola: Compute-efficient pre-training of llms via low-rank activation
Ziyue Liu, Ruijie Zhang, Zhengyang Wang, Mingsong Yan, Zi Yang, Paul D Hovland, Bogdan Nicolae, Franck Cappello, Sui Tang, and Zheng Zhang. Cola: Compute-efficient pre-training of llms via low-rank activation. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 4627–4645, 2025
work page 2025
-
[19]
LoQT: Low Rank Adapters for Quantized Training.arXiv preprint arXiv:2405.16528, 2024
Sebastian Loeschcke, Mads Toftrup, Michael J Kastoryano, Serge Belongie, and Vésteinn Snæb- jarnarson. LoQT: Low Rank Adapters for Quantized Training.arXiv preprint arXiv:2405.16528, 2024
-
[20]
Roy Miles, Pradyumna Reddy, Ismail Elezi, and Jiankang Deng. Velora: Memory efficient training using rank-1 sub-token projections.Advances in Neural Information Processing Systems, 37:42292–42310, 2024
work page 2024
-
[21]
Aashiq Muhamed, Oscar Li, David Woodruff, Mona Diab, and Virginia Smith. Grass: Com- pute efficient low-memory llm training with structured sparse gradients.arXiv preprint arXiv:2406.17660, 2024
-
[22]
Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, and Peter J Liu. Exploring the limits of transfer learning with a unified text-to-text transformer.Journal of machine learning research, 21(140):1–67, 2020
work page 2020
-
[23]
Namrata Shivagunde, Mayank Kulkarni, Giannis Karamanolakis, Jack G. M. FitzGerald, Yan- nick Versley, Saleh Soltan, V olkan Cevher, Jianhua Lu, and Anna Rumshisky. Approximations may be all you need: Towards pre-training llms with low-rank decomposition and optimizers. 2024
work page 2024
-
[24]
Galore 2: Large-scale llm pre-training by gradient low-rank projection.ArXiv, abs/2504.20437, 2025
DiJia Su, Andrew Gu, Jane Xu, Yuan Tian, and Jiawei Zhao. Galore 2: Large-scale llm pre-training by gradient low-rank projection.ArXiv, abs/2504.20437, 2025
-
[25]
Kaiyue Wen, Zhiyuan Li, Jason Wang, David Hall, Percy Liang, and Tengyu Ma. Understanding warmup-stable-decay learning rates: A river valley loss landscape perspective.arXiv preprint arXiv:2410.05192, 2024
-
[26]
Coap: Memory-efficient training with correlation-aware gradient projection
Jinqi Xiao, Shen Sang, Tiancheng Zhi, Jing Liu, Qing Yan, Linjie Luo, and Bo Yuan. Coap: Memory-efficient training with correlation-aware gradient projection. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 30116–30126, 2025
work page 2025
-
[27]
Q-galore: Quantized galore with int4 projection and layer-adaptive low-rank gradients
Zhenyu Zhang, Ajay Jaiswal, Lu Yin, Shiwei Liu, Jiawei Zhao, Yuandong Tian, and Zhangyang Wang. Q-galore: Quantized galore with int4 projection and layer-adaptive low-rank gradients. arXiv preprint arXiv:2407.08296, 2024
-
[28]
GaLore: Memory-Efficient LLM Training by Gradient Low-Rank Projection
Jiawei Zhao, Zhenyu Zhang, Beidi Chen, Zhangyang Wang, Anima Anandkumar, and Yuandong Tian. GaLore: Memory-Efficient LLM Training by Gradient Low-Rank Projection. InForty-first International Conference on Machine Learning, ICML 2024, Vienna, Austria, July 21-27, 2024. OpenReview.net, 2024
work page 2024
-
[29]
Kaiye Zhou, Shucheng Wang, and Jun Xu. Switchlora: Switched low-rank adaptation can learn full-rank information.arXiv preprint arXiv:2406.06564, 2024
-
[30]
Demystifying Mergeability: Interpretable Properties to Predict Model Merging Success
Luca Zhou, Bo Zhao, Rose Yu, and Emanuele Rodolà. Demystifying mergeability: Interpretable properties to predict model merging success.arXiv preprint arXiv:2601.22285, 2026. A More details on metrics We provide more details on the metrics in this section. 11 A.1 Loss landscape related metrics Direction variance equation is given below DV= 1 2N PN j=1 h σ2...
work page internal anchor Pith review Pith/arXiv arXiv 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.