Expanding Spatial and Temporal Context for Robotic Imitation Learning With Scene Graphs
Pith reviewed 2026-06-28 17:22 UTC · model grok-4.3
The pith
Dynamic scene graphs serve as explicit memory so imitation-learned robot policies can track object relations across long sequences and partial views.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By maintaining a dynamic scene graph that captures object-centric relationships and their evolution over time, the method supplies the agent with an explicit structured memory that retains relevant historical context, enabling efficient reasoning over incrementally accrued scene information during task execution.
What carries the argument
Dynamic scene graph serving as explicit structured memory that records object-centric relationships and their temporal changes.
If this is right
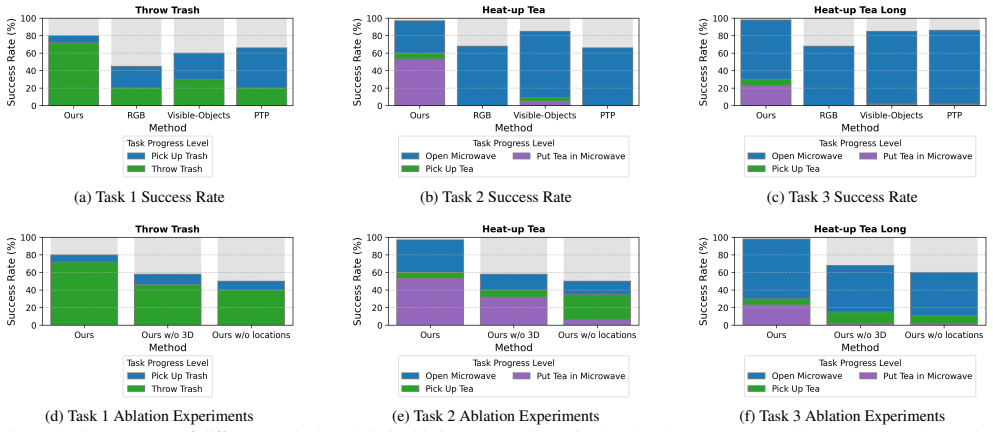
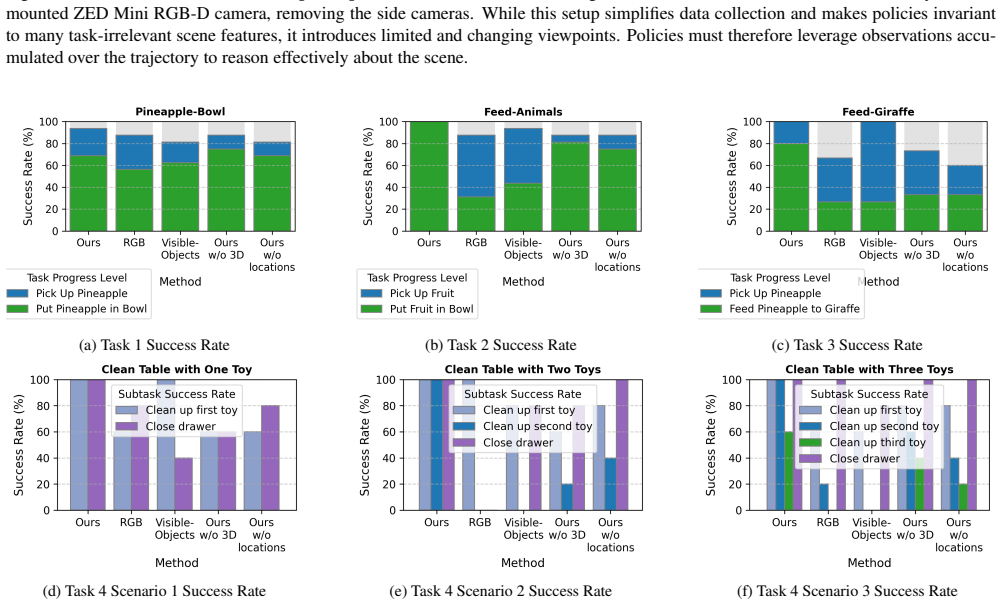
- Policy success rates rise substantially on mobile manipulation tasks that span large spaces.
- Real-world tabletop policies generalize better when observations are incomplete.
- Reasoning over extended time horizons improves because the graph preserves subtask history.
- Incremental scene information becomes usable without retraining the entire policy from scratch.
Where Pith is reading between the lines
- The same graph structure could be tested as a memory layer inside other robot learning pipelines that currently rely on recurrent networks or attention over raw images.
- If graph construction remains reliable, the approach may reduce the need for full environment resets between trials in long-horizon experiments.
- Combining the graph with additional geometric features such as contact points could be examined in follow-up work to handle finer manipulation details.
Load-bearing premise
Scene graphs can be built and kept accurate enough from incomplete sensor data to supply useful historical context.
What would settle it
A test in which the constructed scene graph repeatedly misrepresents object relations or locations from partial observations, causing the learned policy to fail on any task that depends on recalling earlier states.
Figures





read the original abstract
Imitation learning enables robots to learn how to execute tasks via observation. However, real-world environments like homes and offices are often severely partially observed due to their large spatial scales. In addition, many tasks involve executing a series of subtasks requiring autonomous robots to reason over extended time horizons. To address these challenges, we propose using scene graphs as an explicit and structured memory mechanism in imitation learning. By maintaining a dynamic scene graph that captures object-centric relationships and their evolution over time, our method allows the agent to retain relevant historical context during task execution to efficiently reason over incrementally accrued scene information. Our experiments on simulated mobile manipulation and real-world tabletop manipulation demonstrate that our approach substantially improves policy performance, particularly in settings that demand long-term reasoning and robust generalization under partial observability.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes using dynamic scene graphs as an explicit structured memory mechanism within imitation learning policies for robots. By capturing object-centric relationships and their evolution over time, the method aims to retain historical context and enable reasoning over incrementally accrued scene information, addressing partial observability in large environments and long time horizons in sequential tasks. Experiments are claimed to demonstrate substantial policy performance improvements in simulated mobile manipulation and real-world tabletop manipulation, particularly for long-term reasoning and generalization under partial observability.
Significance. If the performance claims hold with appropriate evidence, the work could offer a useful structured alternative to implicit memory mechanisms (e.g., RNNs or transformers) for scaling imitation learning to real-world settings with large spatial scales and extended task horizons.
major comments (1)
- [Abstract] Abstract: the claim that the approach 'substantially improves policy performance' in simulated and real experiments supplies no quantitative results, baselines, or method details. This prevents verification that the data support the central claim of improved reasoning over long horizons and partial observability.
Simulated Author's Rebuttal
We thank the referee for their review and the opportunity to clarify our work. We respond to the major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that the approach 'substantially improves policy performance' in simulated and real experiments supplies no quantitative results, baselines, or method details. This prevents verification that the data support the central claim of improved reasoning over long horizons and partial observability.
Authors: We agree that the abstract would be improved by including quantitative highlights to support the performance claims. The full manuscript reports specific success rates, baseline comparisons, and ablation results demonstrating gains in long-horizon tasks under partial observability (see Experiments section). In the revision we will update the abstract to reference key metrics, such as relative improvements over baselines in simulated mobile manipulation and real tabletop tasks, while keeping the abstract concise. revision: yes
Circularity Check
No significant circularity
full rationale
The paper proposes a methodological approach of using dynamic scene graphs as explicit memory for imitation learning to address partial observability and long time horizons. The provided abstract and text contain no equations, parameter fits, predictions, or self-citations that form a derivation chain. The central claim is a design proposal evaluated via experiments on simulated and real tasks, with no load-bearing step that reduces by construction to its own inputs. This is self-contained against external benchmarks as a standard engineering contribution.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
3d scene graph: A structure for unified semantics, 3d space, and cam- era.2019 IEEE/CVF International Conference on Computer Vision (ICCV), pages 5663–5672, 2019
Iro Armeni, Zhi-Yang He, JunYoung Gwak, Amir Zamir, Martin Fischer, Jitendra Malik, and Silvio Savarese. 3d scene graph: A structure for unified semantics, 3d space, and cam- era.2019 IEEE/CVF International Conference on Computer Vision (ICCV), pages 5663–5672, 2019
2019
-
[2]
Katrina Ashton, Chahyon Ku, Shrey Shah, Wen Jiang, Kostas Daniilidis, and Bernadette Bucher. HELIOS: Hier- archical Exploration for Language-grounded Interaction in Open Scenes.ArXiv, abs/2509.22498, 2025
arXiv 2025
-
[3]
Rokas Bendikas, Daniel Dijkman, Markus Peschl, Sanjay Haresh, and Pietro Mazzaglia. Focusing on what matters: Object-agent-centric tokenization for vision language action models.ArXiv, abs/2509.23655, 2025
arXiv 2025
-
[4]
Emerg- ing properties in self-supervised vision transformers
Mathilde Caron, Hugo Touvron, Ishan Misra, Herv ´e J´egou, Julien Mairal, Piotr Bojanowski, and Armand Joulin. Emerg- ing properties in self-supervised vision transformers. InPro- ceedings of the International Conference on Computer Vi- sion (ICCV), 2021
2021
-
[5]
Bekris, and Abdeslam Boularias
Haonan Chang, Kowndinya Boyalakuntla, Shiyang Lu, Si- wei Cai, Eric Pu Jing, Shreesh Keskar, Shijie Geng, Adeeb Abbas, Lifeng Zhou, Kostas E. Bekris, and Abdeslam Boularias. Context-aware entity grounding with open- vocabulary 3d scene graphs.ArXiv, abs/2309.15940, 2023
arXiv 2023
-
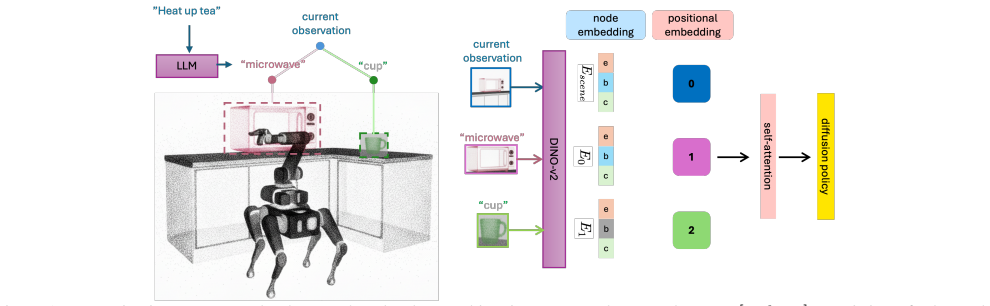
[6]
ASHiTA: Automatic Scene-grounded HIerarchical Task Analysis.Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2025
Yun Chang, Leonor Fermoselle, Duy Ta, Bernadette Bucher, Luca Carlone, and Jiuguang Wang. ASHiTA: Automatic Scene-grounded HIerarchical Task Analysis.Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2025
2025
-
[7]
Decoding dynamic visual scenes across the brain hierarchy.PLOS Computational Biology, 20 (8):e1012297, 2024
Ye Chen, Peter Beech, Ziwei Yin, Shanshan Jia, Jiayi Zhang, Zhaofei Yu, and Jian K Liu. Decoding dynamic visual scenes across the brain hierarchy.PLOS Computational Biology, 20 (8):e1012297, 2024
2024
-
[8]
Ho Kei Cheng and Alexander G. Schwing. Xmem: Long- term video object segmentation with an atkinson-shiffrin memory model. InEuropean Conference on Computer Vi- sion, 2022
2022
-
[9]
Scenegraphfusion: Incre- mental 3d scene graph prediction from rgb-d sequences
Shun cheng Wu, Johanna Wald, Keisuke Tateno, Nassir Navab, and Federico Tombari. Scenegraphfusion: Incre- mental 3d scene graph prediction from rgb-d sequences. 2021 IEEE/CVF Conference on Computer Vision and Pat- tern Recognition (CVPR), pages 7511–7521, 2021
2021
-
[10]
Diffusion policy: Visuomotor policy learning via action dif- fusion.The International Journal of Robotics Research, page 02783649241273668, 2023
Cheng Chi, Zhenjia Xu, Siyuan Feng, Eric Cousineau, Yilun Du, Benjamin Burchfiel, Russ Tedrake, and Shuran Song. Diffusion policy: Visuomotor policy learning via action dif- fusion.The International Journal of Robotics Research, page 02783649241273668, 2023
2023
-
[11]
Cheng Chi, Zhenjia Xu, Chuer Pan, Eric Cousineau, Ben- jamin Burchfiel, Siyuan Feng, Russ Tedrake, and Shuran Song. Universal manipulation interface: In-the-wild robot teaching without in-the-wild robots.ArXiv, abs/2402.10329, 2024
Pith/arXiv arXiv 2024
-
[12]
Transformers for one-shot imitation learning
Sudeep Dasari and et al. Transformers for one-shot imitation learning. InCoRL, 2020
2020
-
[13]
Venkata Naren Devarakonda, Raktim Gautam Goswami, Ali Umut Kaypak, Naman Patel, Rooholla Khorrambakht, Prashanth Krishnamurthy, and Farshad Khorrami. Orion- nav: Online planning for robot autonomy with context-aware llm and open-vocabulary semantic scene graphs.ArXiv, abs/2410.06239, 2024
Pith/arXiv arXiv 2024
-
[14]
Visual representations in the human brain are aligned with large lan- guage models, 2024
Adrien Doerig, Tim C Kietzmann, Emily Allen, Yihan Wu, Thomas Naselaris, Kendrick Kay, and Ian Charest. Visual representations in the human brain are aligned with large lan- guage models, 2024
2024
-
[15]
Simple agent, complex environment: Efficient reinforcement learn- ing with agent states.Journal of Machine Learning Re- search, 23(255):1–54, 2022
Shi Dong, Benjamin Van Roy, and Zhengyuan Zhou. Simple agent, complex environment: Efficient reinforcement learn- ing with agent states.Journal of Machine Learning Re- search, 23(255):1–54, 2022
2022
-
[16]
Robot utility models: General policies for zero-shot deploy- ment in new environments.2025 IEEE International Confer- ence on Robotics and Automation (ICRA), pages 8275–8283, 2024
Haritheja Etukuru, Norihito Naka, Zijin Hu, Seungjae Lee, Julian Mehu, Aaron Edsinger, Chris Paxton, Soumith Chin- tala, Lerrel Pinto, and Nur Muhammad Mahi Shafiullah. Robot utility models: General policies for zero-shot deploy- ment in new environments.2025 IEEE International Confer- ence on Robotics and Automation (ICRA), pages 8275–8283, 2024
2025
-
[17]
Implicit behavioral cloning.RSS, 2022
Pete Florence, Lucas Manuelli, and Russ Tedrake. Implicit behavioral cloning.RSS, 2022
2022
-
[18]
Visual graphs from motion (vgfm): Scene understanding with object ge- ometry reasoning
Paul Gay, Stuart James, and Alessio Del Bue. Visual graphs from motion (vgfm): Scene understanding with object ge- ometry reasoning. InAsian Conference on Computer Vision, 2018
2018
-
[19]
Rvt-2: Learning precise manipulation from few demonstrations.arXiv preprint arXiv:2406.08545, 2024
Ankit Goyal, Valts Blukis, Jie Xu, Yijie Guo, Yu-Wei Chao, and Dieter Fox. Rvt-2: Learning precise manipulation from few demonstrations.arXiv preprint arXiv:2406.08545, 2024
arXiv 2024
-
[20]
Qiao Gu, Ali Kuwajerwala, Sacha Morin, Krishna Murthy Jatavallabhula, Bipasha Sen, Aditya Agarwal, Corban Rivera, William Paul, Kirsty Ellis, Ramalingam Chellappa, Chuang Gan, Celso Miguel de Melo, Joshua B Tenenbaum, Antonio Torralba, Florian Shkurti, and Liam Paull. Concept- graphs: Open-vocabulary 3d scene graphs for perception and planning.ArXiv, abs/...
arXiv 2023
-
[21]
Human-inspired perspec- tives: A survey on ai long-term memory.arXiv preprint arXiv:2411.00489, 2024
Zihong He, Weizhe Lin, Hao Zheng, Fan Zhang, Matt W Jones, Laurence Aitchison, Xuhai Xu, Miao Liu, Per Ola Kristensson, and Junxiao Shen. Human-inspired perspec- tives: A survey on ai long-term memory.arXiv preprint arXiv:2411.00489, 2024
arXiv 2024
-
[22]
Nathan Hughes, Yun Chang, Siyi Hu, Rajat Talak, Rumaisa Abdulhai, Jared Strader, and Luca Carlone. Foundations of spatial perception for robotics: Hierarchical representations and real-time systems.ArXiv, abs/2305.07154, 2023
arXiv 2023
-
[23]
Physical Intelligence, Kevin Black, Noah Brown, James Darpinian, Karan Dhabalia, Danny Driess, Adnan Esmail, Michael Equi, Chelsea Finn, Niccolo Fusai, et al.π 0.5: a vision-language-action model with open-world generaliza- tion.arXiv preprint arXiv:2504.16054, 2025
Pith/arXiv arXiv 2025
-
[24]
Bc-z: Zero-shot task generalization with robotic imitation learning.CoRL, 2022
Eric Jang and et al. Bc-z: Zero-shot task generalization with robotic imitation learning.CoRL, 2022
2022
-
[25]
Krishna Murthy Jatavallabhula, Ali Kuwajerwala, Qiao Gu, Mohd. Omama, Tao Chen, Shuang Li, Ganesh Iyer, Soroush Saryazdi, Nikhil Varma Keetha, Ayush Kumar Tewari, Joshua B. Tenenbaum, Celso M. de Melo, M. Krishna, Liam Paull, Florian Shkurti, and Antonio Torralba. Conceptfusion: Open-set multimodal 3d mapping.ArXiv, abs/2302.07241, 2023
arXiv 2023
-
[26]
Hanxiao Jiang, Binghao Huang, Ruihai Wu, Zhuoran Li, Shubham Garg, Hooshang Nayyeri, Shenlong Wang, and Yunzhu Li. Roboexp: Action-conditioned scene graph via interactive exploration for robotic manipulation.ArXiv, abs/2402.15487, 2024
arXiv 2024
-
[27]
On value functions and the agent–environment boundary.arXiv preprint arXiv:1905.13341, 2019
Nan Jiang. On value functions and the agent–environment boundary.arXiv preprint arXiv:1905.13341, 2019
arXiv 1905
-
[28]
A survey of neurosymbolic visual reasoning with scene graphs and common sense knowledge.Neurosymbolic Artificial Intelligence, 1:NAI–240719, 2025
M Jaleed Khan, Filip Ilievski, John G Breslin, and Edward Curry. A survey of neurosymbolic visual reasoning with scene graphs and common sense knowledge.Neurosymbolic Artificial Intelligence, 1:NAI–240719, 2025
2025
-
[29]
Berg, Wan-Yen Lo, Piotr Doll ´ar, and Ross B
Alexander Kirillov, Eric Mintun, Nikhila Ravi, Hanzi Mao, Chloe Rolland, Laura Gustafson, Tete Xiao, Spencer White- head, Alexander C. Berg, Wan-Yen Lo, Piotr Doll ´ar, and Ross B. Girshick. Segment anything.2023 IEEE/CVF In- ternational Conference on Computer Vision (ICCV), pages 3992–4003, 2023
2023
-
[30]
Semantic memory: A review of meth- ods, models, and current challenges.Psychonomic bulletin & review, 28(1):40–80, 2021
Abhilasha A Kumar. Semantic memory: A review of meth- ods, models, and current challenges.Psychonomic bulletin & review, 28(1):40–80, 2021
2021
-
[31]
Scene graph generation from objects, phrases and region captions.2017 IEEE International Conference on Computer Vision (ICCV), pages 1270–1279, 2017
Yikang Li, Wanli Ouyang, Bolei Zhou, Kun Wang, and Xi- aogang Wang. Scene graph generation from objects, phrases and region captions.2017 IEEE International Conference on Computer Vision (ICCV), pages 1270–1279, 2017
2017
-
[32]
Gps-net: Graph property sensing network for scene graph generation.2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 3743–3752, 2020
Xin Lin, Changxing Ding, Jinquan Zeng, and Dacheng Tao. Gps-net: Graph property sensing network for scene graph generation.2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 3743–3752, 2020
2020
-
[33]
Shilong Liu, Zhaoyang Zeng, Tianhe Ren, Feng Li, Hao Zhang, Jie Yang, Chun yue Li, Jianwei Yang, Hang Su, Jun-Juan Zhu, and Lei Zhang. Grounding dino: Marrying dino with grounded pre-training for open-set object detec- tion.ArXiv, abs/2303.05499, 2023
Pith/arXiv arXiv 2023
-
[34]
Xiao Liu, Fabian Weigend, Yifan Zhou, and Heni Ben Amor. Enabling stateful behaviors for diffusion-based policy learn- ing.arXiv preprint arXiv:2404.12539, 2024
arXiv 2024
-
[35]
Reinforce- ment learning, bit by bit.Foundations and Trends in Machine Learning, 16(6):733–865, 2023
Xiuyuan Lu, Benjamin Van Roy, Vikranth Dwaracherla, Morteza Ibrahimi, Ian Osband, Zheng Wen, et al. Reinforce- ment learning, bit by bit.Foundations and Trends in Machine Learning, 16(6):733–865, 2023
2023
-
[36]
Clio: Real-time task- driven open-set 3d scene graphs
Dominic Maggio, Yun Chang, Nathan Hughes, Matthew Trang, Dan Griffith, Carlyn Dougherty, Eric Cristofalo, Lukas Schmid, and Luca Carlone. Clio: Real-time task- driven open-set 3d scene graphs. 2024
2024
-
[37]
What matters in learning from offline human demonstrations for robot manipulation
Ajay Mandlekar and et al. What matters in learning from offline human demonstrations for robot manipulation. In CoRL, 2021
2021
-
[38]
Mayank Mittal, Pascal Roth, James Tigue, Antoine Richard, Octi Zhang, Peter Du, Antonio Serrano-Mu ˜noz, Xinjie Yao, Ren´e Zurbr ¨ugg, Nikita Rudin, et al. Isaac lab: A gpu- accelerated simulation framework for multi-modal robot learning.arXiv preprint arXiv:2511.04831, 2025
Pith/arXiv arXiv 2025
-
[39]
Liu, and Long Zeng
Zhe Ni, Xiao-Xin Deng, Cong Tai, Xin-Yue Zhu, Xiang Wu, Y . Liu, and Long Zeng. Grid: Scene-graph-based instruction-driven robotic task planning.2024 IEEE/RSJ In- ternational Conference on Intelligent Robots and Systems (IROS), pages 13765–13772, 2023
2024
-
[40]
Maxime Oquab, Timoth’ee Darcet, Th ´eo Moutakanni, Huy Q. V o, Marc Szafraniec, Vasil Khalidov, Pierre Fernan- dez, Daniel Haziza, Francisco Massa, Alaaeldin El-Nouby, Mahmoud Assran, Nicolas Ballas, Wojciech Galuba, Russ Howes, Po-Yao (Bernie) Huang, Shang-Wen Li, Ishan Misra, Michael G. Rabbat, Vasu Sharma, Gabriel Synnaeve, Huijiao Xu, Herv ´e J ´egou,...
Pith/arXiv arXiv 2023
-
[41]
Task-oriented hierarchical object decomposition for visuomotor control
Jianing Qian, Yunshuang Li, Bernadette Bucher, and Dinesh Jayaraman. Task-oriented hierarchical object decomposition for visuomotor control. InConference on Robot Learning, 2024
2024
-
[42]
Learning transferable visual models from natural language supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, and Ilya Sutskever. Learning transferable visual models from natural language supervision. InInternational Conference on Machine Learning, 2021
2021
-
[43]
Daniel Griffith, and Luca Carlone
Zachary Ravichandran, Lisa Peng, Nathan Hughes, J. Daniel Griffith, and Luca Carlone. Hierarchical representations and explicit memory: Learning effective navigation policies on 3d scene graphs using graph neural networks.2022 Inter- national Conference on Robotics and Automation (ICRA), pages 9272–9279, 2021
2022
-
[44]
Sonia Raychaudhuri, Duy Ta, Katrina Ashton, Angel X Chang, Jiuguang Wang, and Bernadette Bucher. Zero-shot object-centric instruction following: Integrating foundation models with traditional navigation.ArXiv, abs/2411.07848, 2024
arXiv 2024
-
[45]
Learning to walk in minutes using massively parallel deep reinforcement learning
Nikita Rudin, David Hoeller, Philipp Reist, and Marco Hut- ter. Learning to walk in minutes using massively parallel deep reinforcement learning. InConference on robot learn- ing, pages 91–100. PMLR, 2022
2022
-
[46]
What matters in learning from large-scale datasets for robot manipulation
Vaibhav Saxena, Matthew Bronars, Nadun Ranawaka Arachchige, Kuancheng Wang, Woo Chul Shin, Soroush Nasiriany, Ajay Mandlekar, and Danfei Xu. What matters in learning from large-scale datasets for robot manipulation. arXiv preprint arXiv:2506.13536, 2025
arXiv 2025
-
[47]
Proximal policy optimization algo- rithms.arXiv preprint arXiv:1707.06347, 2017
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Rad- ford, and Oleg Klimov. Proximal policy optimization algo- rithms.arXiv preprint arXiv:1707.06347, 2017
Pith/arXiv arXiv 2017
-
[48]
Junyao Shi, Jianing Qian, Yecheng Jason Ma, and Dinesh Ja- yaraman. Composing pre-trained object-centric representa- tions for robotics from ”what” and ”where” foundation mod- els.2024 IEEE International Conference on Robotics and Automation (ICRA), pages 15424–15432, 2024
2024
-
[49]
Graph-structured visual imi- tation
Maximilian Sieb, Xian Zhou, Audrey Huang, Oliver Kroe- mer, and Katerina Fragkiadaki. Graph-structured visual imi- tation. InConference on Robot Learning, 2019
2019
-
[50]
Agent-state-based poli- cies in pomdps: Beyond belief-state mdps.arXiv preprint arXiv:??, 2023
Amit Sinha and Aditya Mahajan. Agent-state-based poli- cies in pomdps: Beyond belief-state mdps.arXiv preprint arXiv:??, 2023
2023
-
[51]
Mujoco: A physics engine for model-based control
Emanuel Todorov, Tom Erez, and Yuval Tassa. Mujoco: A physics engine for model-based control. In2012 IEEE/RSJ international conference on intelligent robots and systems, pages 5026–5033. IEEE, 2012
2012
-
[52]
Marcel Torne, Andy Tang, Yuejiang Liu, and Chelsea Finn. Learning long-context diffusion policies via past-token pre- diction.arXiv preprint arXiv:2505.09561, 2025
arXiv 2025
-
[53]
Episodic and semantic memory
Endel Tulving. Episodic and semantic memory. InOrgani- zation of Memory, pages 381–403. Academic Press, 1972
1972
-
[54]
Kaijun Wang, Liqin Lu, Mingyu Liu, Jianuo Jiang, Zeju Li, Bolin Zhang, Wancai Zheng, Xinyi Yu, Hao Chen, and Chunhua Shen. Odyssey: Open-world quadrupeds ex- ploration and manipulation for long-horizon tasks.ArXiv, abs/2508.08240, 2025
arXiv 2025
-
[55]
Scene graph generation by iterative message pass- ing.2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 3097–3106, 2017
Danfei Xu, Yuke Zhu, Christopher Bongsoo Choy, and Li Fei-Fei. Scene graph generation by iterative message pass- ing.2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 3097–3106, 2017
2017
-
[56]
Ge Yan, Jiyue Zhu, Yuquan Deng, Shiqi Yang, Ri-Zhao Qiu, Xuxin Cheng, Marius Memmel, Ranjay Krishna, Ankit Goyal, Xiaolong Wang, et al. Maniflow: A general robot manipulation policy via consistency flow training.arXiv preprint arXiv:2509.01819, 2025
arXiv 2025
-
[57]
Dynamic open- vocabulary 3d scene graphs for long-term language-guided mobile manipulation.IEEE Robotics and Automation Let- ters, 10:4252–4259, 2024
Zhijie Yan, Shufei Li, Zuoxu Wang, Lixiu Wu, Han Wang, Jun-Yan Zhu, Lijiang Chen, and Jihong Liu. Dynamic open- vocabulary 3d scene graphs for long-term language-guided mobile manipulation.IEEE Robotics and Automation Let- ters, 10:4252–4259, 2024
2024
-
[58]
Graph r-cnn for scene graph generation
Jianwei Yang, Jiasen Lu, Stefan Lee, Dhruv Batra, and Devi Parikh. Graph r-cnn for scene graph generation. InEuropean Conference on Computer Vision, 2018
2018
-
[59]
Ruochu Yang, Yu Zhou, Fumin Zhang, and Mengxue Hou. Interleaved llm and motion planning for general- ized multi-object collection in large scene graphs.ArXiv, abs/2507.15782, 2025
arXiv 2025
-
[60]
Vlfm: Vision-language frontier maps for zero-shot semantic navigation.2024 IEEE Inter- national Conference on Robotics and Automation (ICRA), pages 42–48, 2023
Naoki Yokoyama, Sehoon Ha, Dhruv Batra, Jiuguang Wang, and Bernadette Bucher. Vlfm: Vision-language frontier maps for zero-shot semantic navigation.2024 IEEE Inter- national Conference on Robotics and Automation (ICRA), pages 42–48, 2023
2024
-
[61]
Yanjie Ze, Gu Zhang, Kangning Zhang, Chenyuan Hu, Muhan Wang, and Huazhe Xu. 3d diffusion policy: Gen- eralizable visuomotor policy learning via simple 3d repre- sentations.arXiv preprint arXiv:2403.03954, 2024
Pith/arXiv arXiv 2024
-
[62]
Knowledge-inspired 3d scene graph prediction in point cloud
Shoulong Zhang, Shuai Li, Aimin Hao, and Hong Qin. Knowledge-inspired 3d scene graph prediction in point cloud. InNeural Information Processing Systems, 2021
2021
-
[63]
Deep imitation learning for complex manipulation tasks from virtual reality teleoperation
Tingfan Zhang, Zoe McCarthy, Eric Jang, and Sergey Levine. Deep imitation learning for complex manipulation tasks from virtual reality teleoperation. InIROS, 2018
2018
-
[64]
Perceiver-actor: A multi-task trans- former for robotic manipulation
Yunzhu Zhang and et al. Perceiver-actor: A multi-task trans- former for robotic manipulation. InCoRL, 2021
2021
-
[65]
Rec- ognize anything: A strong image tagging model.ArXiv, abs/2306.03514, 2023
Youcai Zhang, Xinyu Huang, Jinyu Ma, Zhaoyang Li, Zhaochuan Luo, Yanchun Xie, Yuzhuo Qin, Tong Luo, Yaqian Li, Siyi Liu, Yandong Guo, and Lei Zhang. Rec- ognize anything: A strong image tagging model.ArXiv, abs/2306.03514, 2023
arXiv 2023
-
[66]
Tony Z Zhao, Vikash Kumar, Sergey Levine, and Chelsea Finn. Learning fine-grained bimanual manipulation with low-cost hardware.arXiv preprint arXiv:2304.13705, 2023
Pith/arXiv arXiv 2023
-
[68]
Yifeng Zhu, Zhenyu Jiang, Peter Stone, and Yuke Zhu. Learning generalizable manipulation policies with object- centric 3d representations.arXiv preprint arXiv:2310.14386, 2023. Expanding Spatial and Temporal Context for Robotic Imitation Learning With Scene Graphs Supplementary Material
arXiv 2023
-
[69]
microwave
Additional Information about Our Task- Driven Scene Graph Concretely, our scene graph is implemented as atwo-level treein which the root node is represented by the CLS token extracted from the DINO-v2 encoder applied to the current image observation. The second level of the tree consists of the set of task-relevant object nodes described in Section 3.1. A...
-
[70]
Following the MDP formulation of [45], we employ Proximal Policy Optimization (PPO) [47] within IsaacLab [38] to learn a ro- bust quadruped walking policy
Technical Details for Collecting Demonstra- tions in Simulated Mujoco Environment Low-Level Controller .During demonstration collection, we train a locomotion controller in simulation. Following the MDP formulation of [45], we employ Proximal Policy Optimization (PPO) [47] within IsaacLab [38] to learn a ro- bust quadruped walking policy. The resulting lo...
-
[71]
A ZED Mini camera is mounted on the robot’s wrist, and the captured wrist images are encoded using DINO-v2
Technical Details for Real World Tabletop Manipulation Experiments We utilize a 7-DoF Franka robotic arm operating under a continuous joint-control action space at 15 Hz. A ZED Mini camera is mounted on the robot’s wrist, and the captured wrist images are encoded using DINO-v2. The resulting CLS token is incorporated as an additional input to the pol- icy...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.