Frames2LoRA: Parametric Video Internalization for Vision-Language Models
Pith reviewed 2026-06-28 07:10 UTC · model grok-4.3
The pith
A perceiver hypernetwork predicts LoRA weights from video frames so a frozen VLM can answer queries with no visual tokens.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
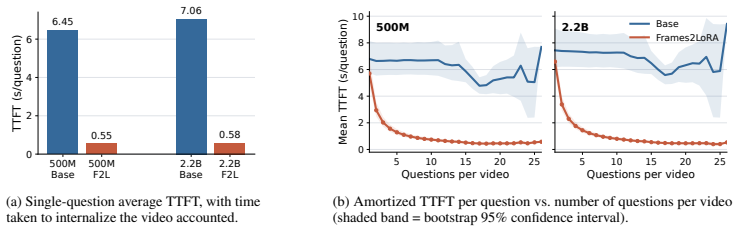
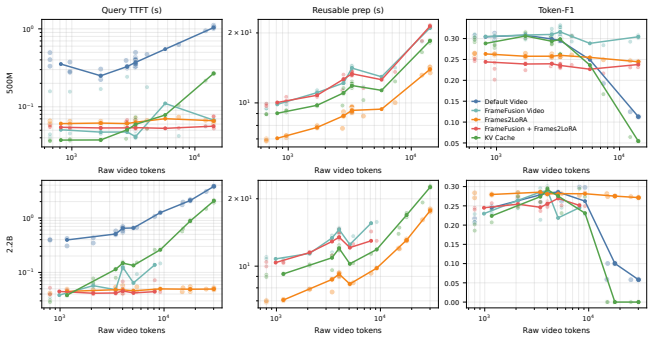
Frames2LoRA trains a perceiver hypernetwork on video summarization and captioning to generate LoRA adapters from the intermediate representations of a frozen VLM encoding a video. Once generated, the adapter lets the same VLM answer any query about the video using only the adapter, with zero visual tokens in the context. It proves statistically equivalent to direct in-context video inference on all five captioning benchmarks and seven of eight QA pairings at both 500M and 2.2B scales, while cutting visual token load by up to 1500x and TTFT by 6-80x, and remains stable up to 1024 frames and 1024px.
What carries the argument
The perceiver hypernetwork that reads layer-by-layer intermediate representations from the frozen VLM's video encoding and generates LoRA adapter weights in a single forward pass.
If this is right
- Performance remains non-inferior to in-context inference on captioning and most QA tasks.
- Answer-time visual token load drops by up to 1500x.
- Query time-to-first-token improves by 6-80x.
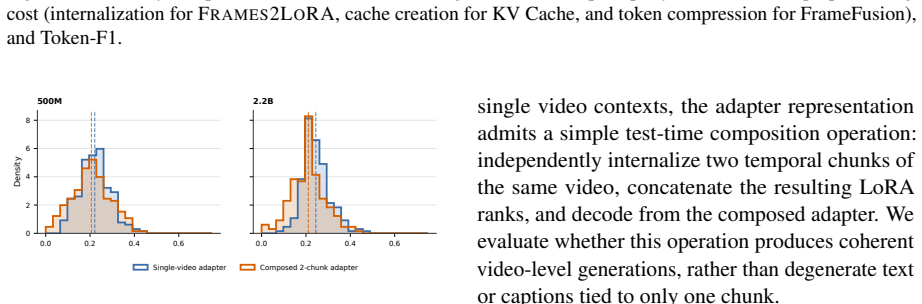
- Independently generated adapters for video segments can compose in rank space for long videos.
- Stability holds when scaling frames and resolution far beyond the 12-frame 384px training regime.
Where Pith is reading between the lines
- Chunking long videos into non-overlapping segments and composing adapters could enable processing of hour-long content without context limits.
- This parametric internalization might extend to other modalities like audio or 3D if similar hypernetworks are trained.
- Reducing visual tokens could allow more complex reasoning chains or multiple queries on the same video at lower cost.
Load-bearing premise
The hypernetwork, trained only on short low-resolution clips, produces usable LoRA weights for videos with many more frames and much higher resolution.
What would settle it
A benchmark run showing that on a 1024-frame high-res video, Frames2LoRA accuracy falls below the direct in-context baseline by a statistically significant margin on a captioning or QA task.
Figures











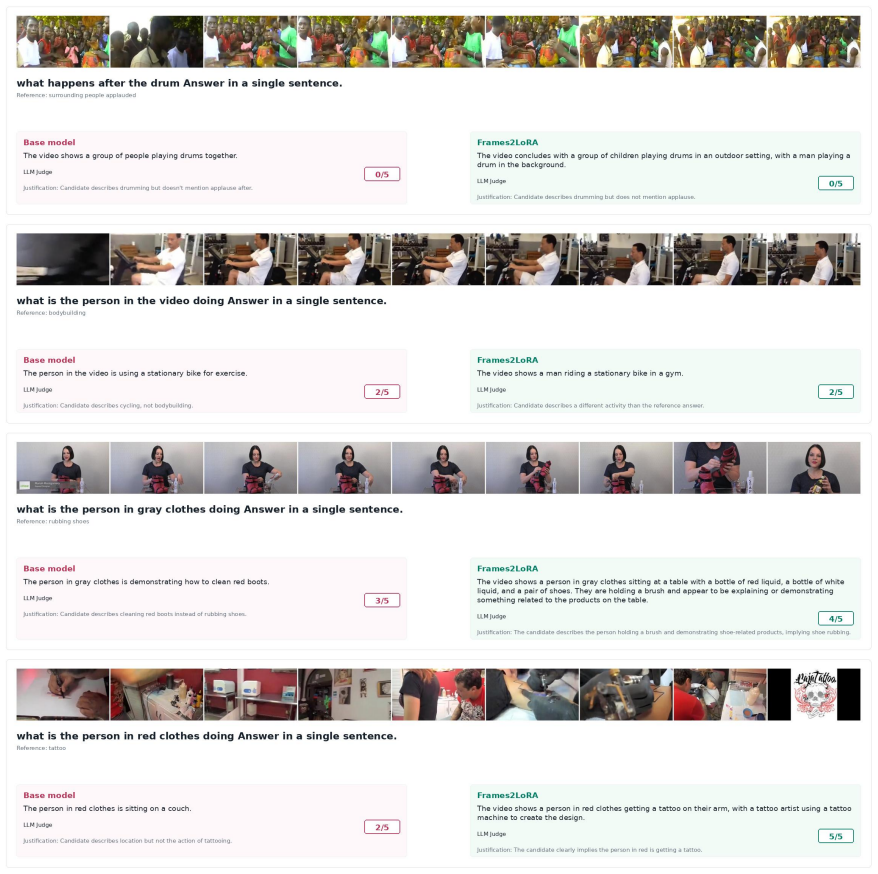





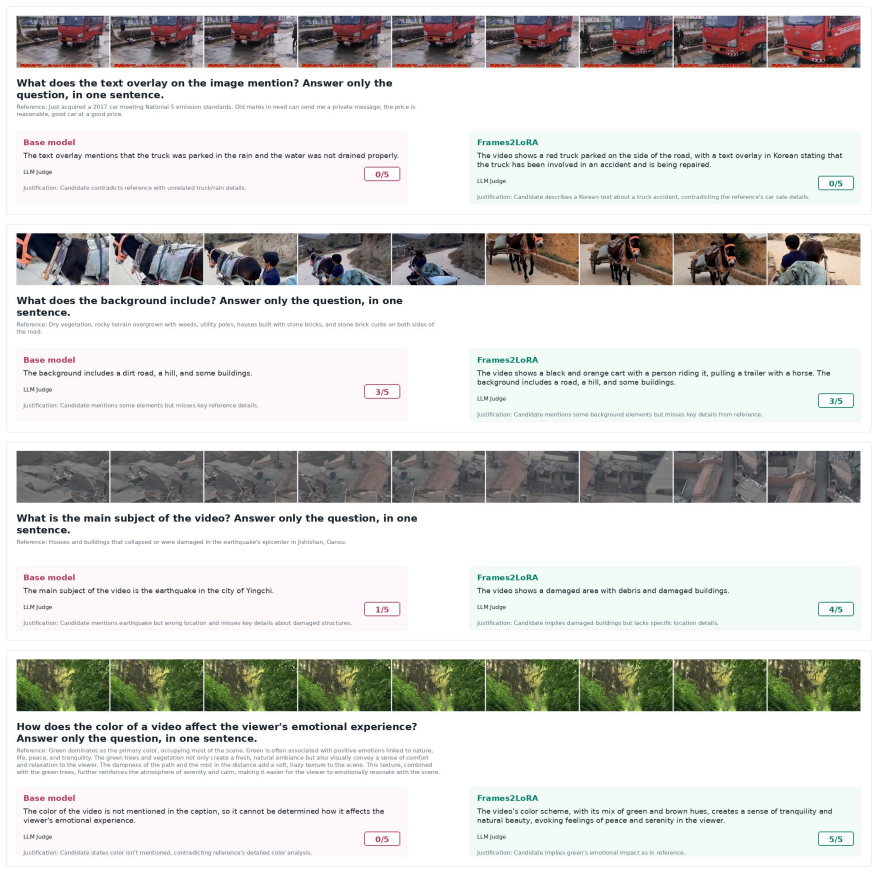
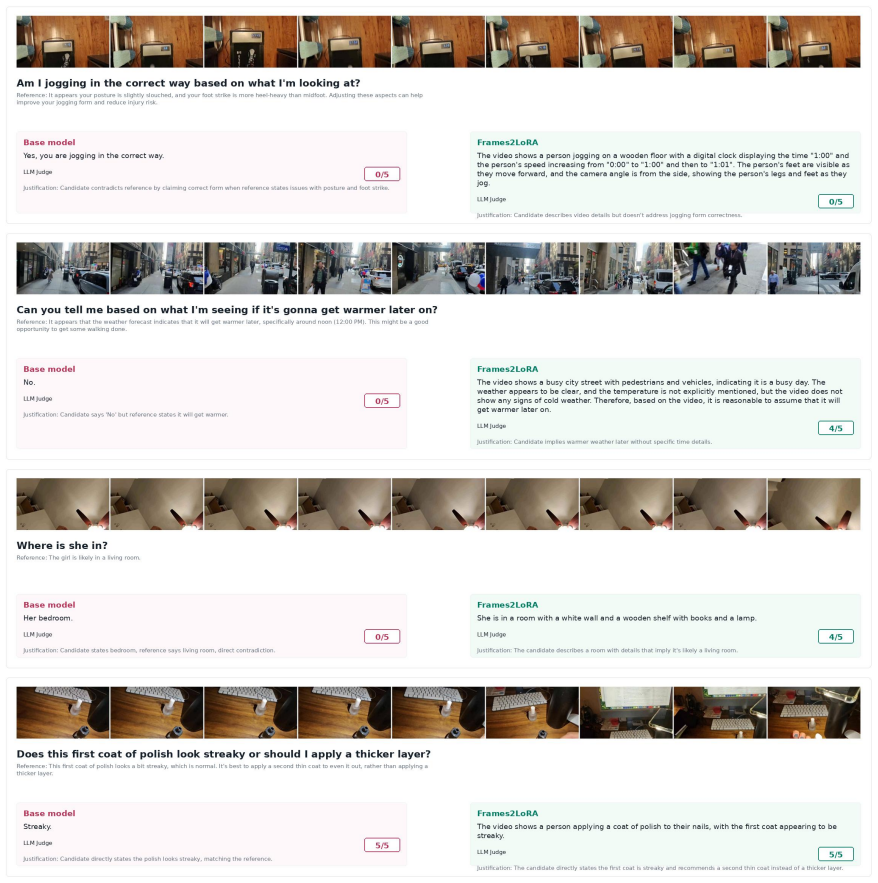
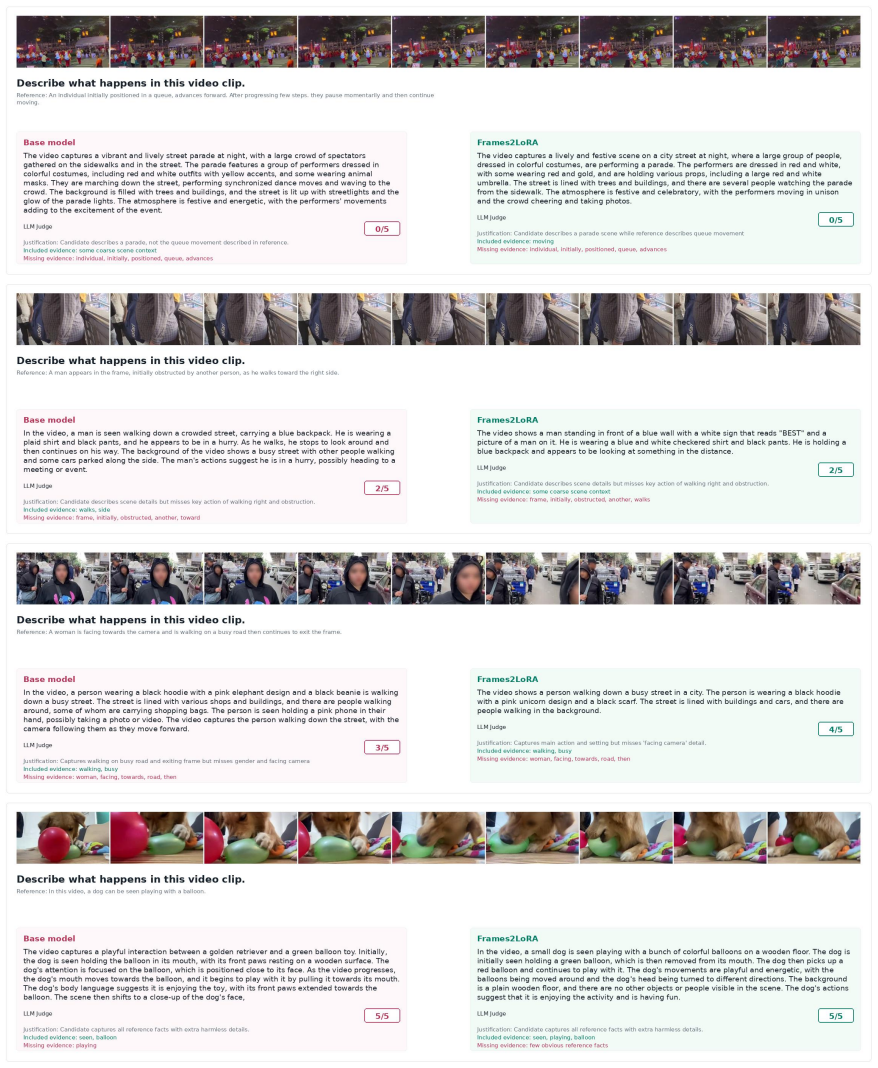






read the original abstract
Processing video in vision-language models is expensive: each frame occupies hundreds of tokens, and inference cost scales with every frame and every repeated query. We introduce Frames2LoRA, a method for parametric video internalization. A perceiver hypernetwork reads the intermediate representations produced layer-by-layer as a frozen VLM encodes a video, and generates a Low-Rank Adaptation (LoRA) adapter in a single forward pass. Unlike standard LoRA fine-tuning, which requires iterative gradient updates, Frames2LoRA predicts these weights directly from the video. Trained for SmolVLM2 500M and 2.2B on video summarization and captioning, Frames2LoRA enables the same frozen VLM to answer queries from the adapter alone, with zero visual tokens in its context at query time. Frames2LoRA is statistically non-inferior and equivalent to direct video-in-context inference across all five captioning benchmarks at both model scales, and across seven of eight video question answering benchmark-scale pairings. Although trained only on 12 frames at 384px, it remains stable up to 1,024 frames and 1024px, where direct video-in-context inference often degenerates. Across this sweep, it reduces answer-time visual-token load by up to 1,500x and query TTFT by 6-80x, while preserving video-faithful outputs. We also find that independently generated adapters for non-overlapping video segments can compose in rank space, suggesting a path toward chunked long-video internalization.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Frames2LoRA, in which a perceiver hypernetwork takes layer-wise intermediate representations from a frozen VLM encoding a video and directly predicts LoRA adapter weights in one forward pass. After training on video summarization and captioning with 12-frame 384 px inputs for SmolVLM2 models at 500M and 2.2B scales, the resulting adapters allow the same frozen VLM to answer queries using only the adapter (zero visual tokens at inference). The central empirical claim is statistical non-inferiority and equivalence to direct video-in-context inference on all five captioning benchmarks at both scales and on seven of eight VQA benchmark-scale pairings, with stability observed up to 1024 frames and 1024 px (where in-context inference often fails), yielding up to 1500× reduction in answer-time visual tokens and 6-80× lower TTFT; adapters for non-overlapping segments are also shown to compose in rank space.
Significance. If the reported generalization and equivalence results hold under rigorous verification, the work provides a concrete mechanism for parametric internalization of video content that decouples inference cost from video length. The composition property of independently generated adapters offers a plausible route to chunked long-video handling. The efficiency numbers, if reproducible, represent a substantial practical advance for video VLMs. The approach is empirically grounded across model scales and multiple task families, though the absence of architectural and statistical detail limits immediate assessment of its reliability.
major comments (4)
- [Perceiver hypernetwork architecture] Perceiver hypernetwork architecture section: the manuscript supplies no description of how the perceiver processes variable-length sequences of layer representations (positional encodings, masking, pooling, or length normalization) when the number of frames increases from the 12-frame training regime to 1024-frame inference. This detail is load-bearing for the stability claim at extrapolated scales.
- [Experimental results] Experimental results and equivalence claims: the abstract asserts that Frames2LoRA is “statistically non-inferior and equivalent” across the reported benchmark-scale pairings, yet no statistical tests, p-values, confidence intervals, or equivalence-testing procedure (e.g., TOST) are described. Without these, the central non-inferiority result cannot be evaluated.
- [Scaling and ablation experiments] Scaling and ablation experiments: no ablation isolates hypernetwork performance as a function of input frame count or resolution. The reported stability at 1024 frames/1024 px (the regime where the 1500× token-reduction claim is measured) therefore rests on an untested generalization assumption rather than controlled evidence.
- [Training procedure] Training procedure: the manuscript provides insufficient detail on the training data mixture, loss formulation, optimizer settings, hypernetwork size, and LoRA rank to allow reproduction or independent verification of the scaling behavior and VQA generalization results.
Simulated Author's Rebuttal
We thank the referee for their detailed and constructive feedback. We address each major comment below, agreeing that several areas require additional detail and clarification. We will incorporate these changes in the revised manuscript.
read point-by-point responses
-
Referee: [Perceiver hypernetwork architecture] Perceiver hypernetwork architecture section: the manuscript supplies no description of how the perceiver processes variable-length sequences of layer representations (positional encodings, masking, pooling, or length normalization) when the number of frames increases from the 12-frame training regime to 1024-frame inference. This detail is load-bearing for the stability claim at extrapolated scales.
Authors: We agree that the manuscript lacks a sufficient description of variable-length handling. In the revision we will add an explicit subsection detailing the perceiver's use of sinusoidal positional encodings, per-frame masking, and mean pooling over the sequence dimension to normalize length. This mechanism is what permits the observed extrapolation from the 12-frame training regime. revision: yes
-
Referee: [Experimental results] Experimental results and equivalence claims: the abstract asserts that Frames2LoRA is “statistically non-inferior and equivalent” across the reported benchmark-scale pairings, yet no statistical tests, p-values, confidence intervals, or equivalence-testing procedure (e.g., TOST) are described. Without these, the central non-inferiority result cannot be evaluated.
Authors: The referee is correct; the statistical methodology is not reported. We will revise the experimental results section to describe the full equivalence-testing procedure (TOST), report p-values, confidence intervals, and the exact decision criteria used for each benchmark-scale pairing. revision: yes
-
Referee: [Scaling and ablation experiments] Scaling and ablation experiments: no ablation isolates hypernetwork performance as a function of input frame count or resolution. The reported stability at 1024 frames/1024 px (the regime where the 1500× token-reduction claim is measured) therefore rests on an untested generalization assumption rather than controlled evidence.
Authors: We acknowledge the lack of isolated ablations. The revised manuscript will include new controlled ablation experiments that vary frame count and resolution independently while measuring adapter quality, thereby supplying direct evidence for the generalization behavior. revision: yes
-
Referee: [Training procedure] Training procedure: the manuscript provides insufficient detail on the training data mixture, loss formulation, optimizer settings, hypernetwork size, and LoRA rank to allow reproduction or independent verification of the scaling behavior and VQA generalization results.
Authors: We agree that the training details are insufficient for reproducibility. The revision will expand the training procedure section with the exact data mixture composition, loss formulation, optimizer hyperparameters, hypernetwork dimensions, and LoRA rank/alpha values. revision: yes
Circularity Check
No circularity; central claims are empirical measurements against external baselines
full rationale
The paper presents Frames2LoRA as an empirical method whose headline claims (statistical non-inferiority on captioning and VQA benchmarks, token reduction up to 1500x, stability from 12-frame training to 1024-frame inference) are measured directly against held-out test sets and direct video-in-context baselines. No equations, uniqueness theorems, or fitted parameters are redefined in terms of the target quantities; the perceiver hypernetwork is trained on summarization/captioning data and its outputs are evaluated on separate VQA tasks and extrapolated regimes without any self-referential reduction. Self-citations, if present, are not load-bearing for any derivation. The result is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (2)
- LoRA rank
- Hypernetwork size
Reference graph
Works this paper leans on
-
[1]
and Shen, Yelong and Wallis, Phillip and Allen-Zhu, Zeyuan and Li, Yuanzhi and Wang, Shean and Wang, Lu and Chen, Weizhu , booktitle =
Hu, Edward J. and Shen, Yelong and Wallis, Phillip and Allen-Zhu, Zeyuan and Li, Yuanzhi and Wang, Shean and Wang, Lu and Chen, Weizhu , booktitle =
-
[2]
Charakorn, Rujikorn and Cetin, Edoardo and Uesaka, Shinnosuke and Lange, Robert , journal =. Doc-to-
-
[3]
Proceedings of the 38th International Conference on Machine Learning , pages =
Perceiver: General Perception with Iterative Attention , author =. Proceedings of the 38th International Conference on Machine Learning , pages =. 2021 , editor =
2021
-
[4]
and Le, Quoc V
Ha, David and Dai, Andrew M. and Le, Quoc V. , booktitle =
-
[5]
SmolVLM: Redefining small and efficient multimodal models
Marafioti, Andr. arXiv preprint arXiv:2504.05299 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
IEEE International Conference on Computer Vision , year =
Dense-Captioning Events in Videos , author =. IEEE International Conference on Computer Vision , year =
-
[7]
, booktitle =
Chai, Wenhao and Song, Enxin and Du, Yilun and Meng, Chenlin and Madhavan, Vashisht and Bar-Tal, Omer and Hwang, Jenq-Neng and Xie, Saining and Manning, Christopher D. , booktitle =
-
[8]
Xiao, Junbin and Shang, Xindi and Yao, Angela and Chua, Tat-Seng , booktitle =
-
[9]
Yu, Zhou and Xu, Dejing and Yu, Jun and Yu, Ting and Zhao, Zhou and Zhuang, Yueting and Tao, Dacheng , booktitle =
-
[10]
2024 , howpublished=
FineVideo , author=. 2024 , howpublished=
2024
-
[11]
Zhang, Hang and Li, Xin and Bing, Lidong , booktitle =
-
[12]
Chen, Yukang and Xue, Fuzhao and Li, Dacheng and Hu, Qinghao and Zhu, Ligeng and Li, Xiuyu and Fang, Yunhao and Tang, Haotian and Yang, Shang and Liu, Zhijian and He, Ethan and Yin, Hongxu and Molchanov, Pavlo and Kautz, Jan and Fan, Linxi and Zhu, Yuke and Lu, Yao and Han, Song , booktitle =
-
[13]
Transactions on Machine Learning Research , year =
Long Context Transfer from Language to Vision , author =. Transactions on Machine Learning Research , year =
-
[14]
Li, Wentong and Yuan, Yuqian and Liu, Jian and Tang, Dongqi and Wang, Song and Qin, Jie and Zhu, Jianke and Zhang, Lei , journal =
-
[15]
Advances in Neural Information Processing Systems , year =
Learning to Compress Prompts with Gist Tokens , author =. Advances in Neural Information Processing Systems , year =
-
[16]
International Conference on Learning Representations , year =
Fast Model Editing at Scale , author =. International Conference on Learning Representations , year =
-
[17]
Annual Meeting of the Association for Computational Linguistics , year =
Prefix-Tuning: Optimizing Continuous Prompts for Generation , author =. Annual Meeting of the Association for Computational Linguistics , year =
-
[18]
Advances in Neural Information Processing Systems , year =
Streaming Long Video Understanding with Large Language Models , author =. Advances in Neural Information Processing Systems , year =
-
[19]
Conference on Empirical Methods in Natural Language Processing , year =
The Power of Scale for Parameter-Efficient Prompt Tuning , author =. Conference on Empirical Methods in Natural Language Processing , year =
-
[20]
arXiv preprint arXiv:2503.08727 , year =
Training Plug-n-Play Knowledge Modules with Deep Context Distillation , author =. arXiv preprint arXiv:2503.08727 , year =
-
[21]
Xu, Yifan and Li, Xinhao and Yang, Yichun and Meng, Desen and Huang, Rui and Wang, Limin , journal =
-
[22]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , year =
Improved Baselines with Visual Instruction Tuning , author =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , year =
-
[23]
Shang, Yuzhang and Cai, Mu and Xu, Bingxin and Lee, Yong Jae and Yan, Yan , booktitle =
-
[24]
arXiv preprint , year =
Cho, Jang Hyun and Madotto, Andrea and Mavroudi, Effrosyni and Afouras, Triantafyllos and Nagarajan, Tushar and Maaz, Muhammad and Song, Yale and Ma, Tengyu and Hu, Shuming and Rasheed, Hanoona and Sun, Peize and Huang, Po-Yao and Bolya, Daniel and Jain, Suyog and Martin, Miguel and Wang, Huiyu and Ravi, Nikhila and Jain, Shashank and Stark, Temmy and Moo...
-
[25]
Chen, Xinlong and Zhang, Yuanxing and Rao, Chongling and Guan, Yushuo and Liu, Jiaheng and Zhang, Fuzheng and Song, Chengru and Liu, Qiang and Zhang, Di and Tan, Tieniu , booktitle =
-
[26]
2025 , eprint=
Qwen3 Technical Report , author=. 2025 , eprint=
2025
-
[27]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
FrameFusion: Combining Similarity and Importance for Video Token Reduction on Large Vision Language Models , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.