MDForge: Agentic Molecular Dynamics Pipeline Design under Sparse Simulator Feedback
Pith reviewed 2026-06-27 07:06 UTC · model grok-4.3
The pith
MDForge uses multi-agent LLM debate to design molecular dynamics pipelines that compete with human experts on binding benchmarks and discover new binders.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
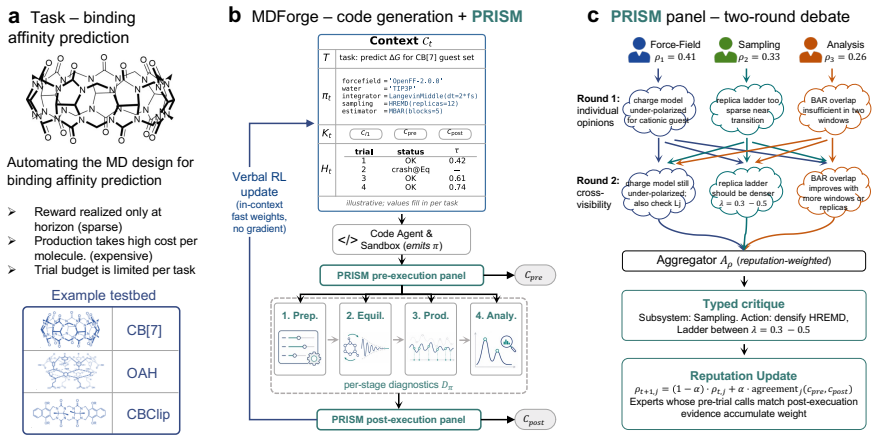
MDForge is an LLM agent for open-ended MD pipeline code generation whose behavior is reshaped online by verbal rewards from multi-agent debate among physics-expert LLMs. On three SAMPL host-guest binding free-energy benchmarks it produces pipelines competitive with human experts. When applied to a library of unseen guests its CB[7] pipeline discovers a novel binder whose high affinity is confirmed by wet-lab competition NMR as picomolar.
What carries the argument
Multi-agent debate among physics-expert LLMs that converts sparse numerical simulator feedback into verbal rewards to guide the primary LLM's code generation.
If this is right
- MD pipeline design for new systems no longer requires substantial expert knowledge or expensive trial-and-error.
- Automatically designed pipelines achieve performance on par with expert-designed ones on standard benchmarks.
- The method enables screening of molecular libraries to find new high-affinity binders.
- Computational discoveries from the agent can be directly validated in wet-lab experiments.
Where Pith is reading between the lines
- The approach may generalize to other areas of computational chemistry where simulator feedback is sparse.
- Verbal rewards from LLM debate could replace traditional reward shaping in code generation tasks.
- Future work could test the agent on more complex molecular systems beyond host-guest binding.
- Integration with experimental feedback loops could further accelerate discovery.
Load-bearing premise
The multi-agent debate among physics-expert LLMs can reliably convert sparse numerical simulator feedback into effective verbal rewards that steer the primary LLM toward correct and efficient MD code without post-hoc human editing or extensive trial-and-error.
What would settle it
Running MDForge on a new host-guest system where the automatically designed pipeline yields binding free energy predictions that differ substantially from both experimental values and those from human-designed pipelines.
Figures


read the original abstract
Molecular dynamics (MD) is the canonical in-silico method for atomistic molecular science, simulating molecular behavior from first-principle physics. Designing an MD pipeline for a new system requires substantial expert knowledge: running it on even one molecule is expensive, ruling out trial-and-error. We automate this expert pipeline-design process with an LLM agent. Unlike existing MD agents that orchestrate a predefined tool set, we treat pipeline design as open-ended code generation in which the agent's behavior is reshaped online by verbal reward. Specifically, we build MDForge, an LLM agent whose in-context update rule densifies the sparse reward via a multi-agent debate among physics experts. On three SAMPL host-guest binding free-energy benchmarks, MDForge automatically designs MD pipelines competitive with human experts. Deployed on a library of unseen candidate guests, its CB[7] pipeline discovers a novel binder that wet-lab competition NMR confirms is a high-affinity, picomolar CB[7] binder. Our data and code are available at https://github.com/Zehong-Wang/MDForge.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces MDForge, an LLM-based agent for open-ended molecular dynamics (MD) pipeline design. Unlike prior agents that orchestrate fixed toolkits, MDForge generates MD code and reshapes its behavior online via verbal rewards obtained by densifying sparse simulator outputs through multi-agent debate among physics-expert LLMs. The central claims are that the resulting pipelines are competitive with human experts on three SAMPL host-guest binding free-energy benchmarks and that, when applied to an unseen library of CB[7] candidate guests, the system identifies a novel binder whose picomolar affinity is subsequently confirmed by wet-lab competition NMR. Code and data are released at a public GitHub repository.
Significance. If the performance and discovery claims hold after quantitative verification, the work would demonstrate a practical route to automating expert MD pipeline construction under the realistic constraint of expensive, sparse simulator feedback. The open release of code and data constitutes a clear strength for reproducibility. The wet-lab confirmation of a novel binder further strengthens the applied contribution to host-guest chemistry.
major comments (2)
- [Abstract] Abstract: the claim that MDForge designs pipelines 'competitive with human experts' on the SAMPL benchmarks is presented without any quantitative metrics, error bars, baseline comparisons, or explicit definition of 'competitive.' This absence is load-bearing for the primary empirical claim.
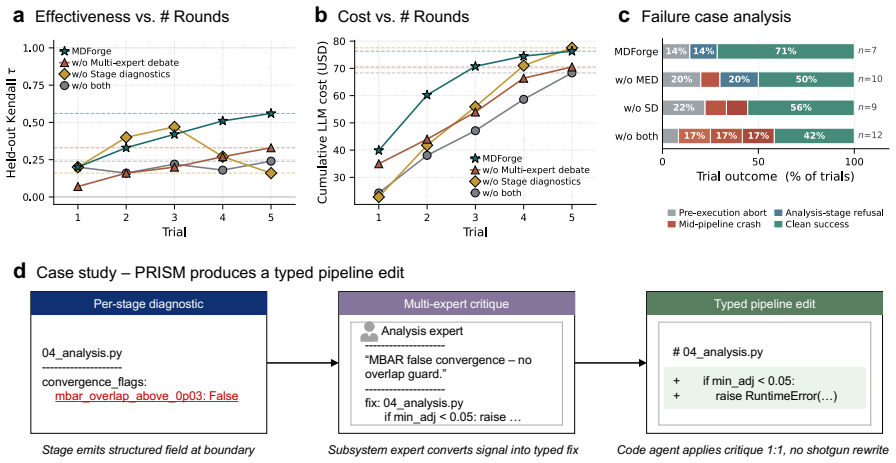
- [Abstract] Abstract: no ablation or isolation experiment is reported that quantifies the contribution of the multi-agent debate step in converting sparse numerical feedback into effective verbal rewards. Without such evidence it remains unclear whether the reported performance is attributable to the debate mechanism or to other factors such as prompt engineering.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on our manuscript. The points raised about the abstract are well-taken and we will revise it to improve clarity and completeness while preserving the core contributions. We address each major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that MDForge designs pipelines 'competitive with human experts' on the SAMPL benchmarks is presented without any quantitative metrics, error bars, baseline comparisons, or explicit definition of 'competitive.' This absence is load-bearing for the primary empirical claim.
Authors: We agree that the abstract as written summarizes the SAMPL results at a high level without embedding the supporting numbers. The main text (Sections 4.1–4.3) reports the quantitative results, including per-system RMSE values with standard deviations from replicate runs, direct numerical comparisons against expert-designed pipelines on the same SAMPL host–guest sets, and an operational definition of “competitive” as performance statistically indistinguishable from the expert baseline within the reported error bars. In the revision we will condense these key figures into the abstract (e.g., “RMSE = 1.2 ± 0.3 kcal mol⁻¹, matching expert pipelines within error”) so that the claim is self-contained. revision: yes
-
Referee: [Abstract] Abstract: no ablation or isolation experiment is reported that quantifies the contribution of the multi-agent debate step in converting sparse numerical feedback into effective verbal rewards. Without such evidence it remains unclear whether the reported performance is attributable to the debate mechanism or to other factors such as prompt engineering.
Authors: The referee correctly notes that the current manuscript does not contain an explicit ablation that isolates the multi-agent debate component. The verbal-reward densification procedure is described in Section 3.2, but its incremental benefit over a single-LLM baseline is not quantified. We will add a targeted ablation study in the revision that compares (i) the full multi-agent debate pipeline, (ii) a single-LLM verbal-reward variant, and (iii) a prompt-engineering-only control, reporting the resulting differences in pipeline success rate and final binding-free-energy accuracy on the SAMPL benchmarks. This will directly address the attribution question. revision: yes
Circularity Check
No circularity: empirical LLM-agent system with external simulator validation
full rationale
The paper presents an LLM-based agent system (MDForge) that uses multi-agent debate to generate verbal rewards from sparse simulator outputs for MD pipeline code generation. No equations, fitted parameters, predictions, or mathematical derivations appear in the provided text. The central claims rest on benchmark performance and wet-lab confirmation rather than any internal re-derivation or self-referential construction. No self-citations are load-bearing for uniqueness or ansatz; the approach is described as an engineering pipeline without reducing to its inputs by definition. This is a standard non-circular empirical result.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption LLM agents can generate syntactically and physically valid MD simulation code when iteratively refined by verbal feedback from other LLM agents simulating physics experts.
Reference graph
Works this paper leans on
-
[1]
Augmenting large language models with chem- istry tools.Nature Machine Intelligence. Tom B. Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, Sandhini Agarwal, Ariel Herbert-V oss, Gretchen Krueger, Tom Henighan, Rewon Child, Aditya Ramesh, Daniel M. Ziegler,...
arXiv 2020
-
[2]
Cucurbit[7]uril ·guest pair with an attomolar dissociation constant.Angewandte Chemie Interna- tional Edition. David A. Case, Hasan Metin Aktulga, Kellon Belfon, David S. Cerutti, G. Andrés Cisneros, Vinicius Wil- ian D. Cruzeiro, Negin Forouzesh, Timothy J. Giese, Andreas W. Goetz, Holger Gohlke, and 1 others
-
[3]
AmberTools.Journal of Chemical Informa- tion and Modeling. Jun Shern Chan, Neil Chowdhury, Oliver Jaffe, James Aung, Dane Sherburn, Evan Mays, Giulio Starace, Kevin Liu, Leon Maksin, Tejal Patwardhan, Lil- ian Weng, and Aleksander M ˛ adry. 2025. MLE- bench: Evaluating machine learning agents on ma- chine learning engineering. InInternational Confer- ence...
arXiv 2025
-
[4]
Zoe Cournia, Bryce Allen, and Woody Sherman
Training verifiers to solve math word prob- lems.arXiv preprint arXiv:2110.14168. Zoe Cournia, Bryce Allen, and Woody Sherman. 2017. Relative binding free energy calculations in drug dis- covery: recent advances and practical considerations. Journal of chemical information and modeling. DeepSeek-AI. 2025. DeepSeek-R1 incentivizes reason- ing in LLMs throu...
Pith/arXiv arXiv 2017
-
[5]
Yilun Du, Shuang Li, Antonio Torralba, Joshua B
ToPolyAgent: AI agents for coarse-grained topological polymer simulations.arXiv preprint arXiv:2510.12091. Yilun Du, Shuang Li, Antonio Torralba, Joshua B. Tenenbaum, and Igor Mordatch. 2024. Improving factuality and reasoning in language models through multiagent debate. InInternational Conference on Machine Learning. Peter Eastman, Jason Swails, John D....
arXiv 2024
-
[6]
Rushil Gupta, Jason Hartford, and Bang Liu
DynaMate: An autonomous agent for protein- ligand molecular dynamics simulations.arXiv preprint arXiv:2512.10034. Rushil Gupta, Jason Hartford, and Bang Liu. 2025. LLMs for Bayesian optimization in scientific do- mains: Are we there yet? InFindings of the As- sociation for Computational Linguistics: EMNLP 2025. Lester Hedges, Antonia S. J. S. Mey, Charles...
arXiv 2025
-
[7]
BioSimSpace: An interoperable Python frame- work for biomolecular simulation.Journal of Open Source Software. Niel M. Henriksen, Andrew T. Fenley, and Michael K. Gilson. 2015. Computational calorimetry: High- precision calculation of host-guest binding thermo- dynamics.Journal of Chemical Theory and Compu- tation. Scott A. Hollingsworth and Ron O. Dror. 2...
arXiv 2015
-
[8]
Language models can learn from verbal feedback without scalar rewards.arXiv preprint arXiv:2509.22638. Tianyi Ma, Yiyue Qian, Zheyuan Zhang, Zehong Wang, Xiaoye Qian, Feifan Bai, Yifan Ding, Xuwei Luo, Shinan Zhang, Keerthiram Murugesan, Chuxu Zhang, and Yanfang Ye. 2025. AutoData: A multi-agent system for open web data collection. InAdvances in Neural In...
arXiv 2025
-
[9]
In International Conference on Machine Learning
Policy invariance under reward transforma- tions: Theory and application to reward shaping. In International Conference on Machine Learning. Frank Noé, Simon Olsson, Jonas Köhler, and Hao Wu
-
[10]
Boltzmann generators: Sampling equilibrium states of many-body systems with deep learning.Sci- ence. Odhran O’Donoghue, Aleksandar Shtedritski, John Gin- ger, Ralph Abboud, Ali Ghareeb, and Samuel Ro- driques. 2023. BioPlanner: Automatic evaluation of 12 LLMs on protocol planning in biology. InProceed- ings of the 2023 Conference on Empirical Methods in N...
arXiv 2023
-
[11]
Journal of Chemical Information and Modeling
Large-scale assessment of binding free en- ergy calculations in active drug discovery projects. Journal of Chemical Information and Modeling. Imanol Schlag, Kazuki Irie, and Jürgen Schmidhuber
-
[12]
InInternational Conference on Ma- chine Learning
Linear transformers are secretly fast weight programmers. InInternational Conference on Ma- chine Learning. Samuel Schmidgall, Yusheng Su, Ze Wang, Ximeng Sun, Jialian Wu, Xiaodong Yu, Jiang Liu, Michael Moor, Zicheng Liu, and Emad Barsoum. 2025. Agent laboratory: Using LLM agents as research assistants. InFindings of the Association for Compu- tational L...
Pith/arXiv arXiv 2025
-
[13]
MDAgent2: Large language model for code generation and knowledge Q&A in molecular dynam- ics.arXiv preprint arXiv:2601.02075. Zhuofan Shi, Chunxiao Xin, Tong Huo, Yuntao Jiang, Bowen Wu, Xingyue Chen, Wei Qin, Xinjian Ma, Gang Huang, Zhenyu Wang, and Xiang Jing. 2025. A fine-tuned large language model based molecular dynamics agent for code generation to ...
arXiv 2025
-
[14]
InAdvances in Neural Informa- tion Processing Systems
Reflexion: Language agents with verbal rein- forcement learning. InAdvances in Neural Informa- tion Processing Systems. Michael R. Shirts and John D. Chodera. 2008. Sta- tistically optimal analysis of samples from multiple equilibrium states.The Journal of Chemical Physics. David R. Slochower, Niel M. Henriksen, Lin-Hsuan Wang, John D. Chodera, David L. M...
2008
-
[15]
InInternational Con- ference on Machine Learning
AutoML-Agent: A multi-agent LLM frame- work for full-pipeline AutoML. InInternational Con- ference on Machine Learning. Jonathan Uesato, Nate Kushman, Ramana Kumar, Fran- cis Song, Noah Siegel, Lisa Wang, Antonia Creswell, Geoffrey Irving, and Irina Higgins. 2022. Solving math word problems with process- and outcome- based feedback.arXiv preprint arXiv:22...
Pith/arXiv arXiv 2022
-
[16]
Derek van Tilborg, Alisa Alenicheva, and Francesca Grisoni
Machine learning force fields.Chemical Re- views. Derek van Tilborg, Alisa Alenicheva, and Francesca Grisoni. 2022. Exposing the limitations of molecu- lar machine learning with activity cliffs.Journal of Chemical Information and Modeling. Alexander Sasha Vezhnevets, Simon Osindero, Tom Schaul, Nicolas Heess, Max Jaderberg, David Silver, and Koray Kavukcu...
2022
-
[17]
Multi-agentic AI framework for end-to-end atomistic simulations.Digital Discovery. Guanzhi Wang, Yuqi Xie, Yunfan Jiang, Ajay Man- dlekar, Chaowei Xiao, Yuke Zhu, Linxi Fan, and An- ima Anandkumar. 2024a. V oyager: An open-ended embodied agent with large language models.Trans- actions on Machine Learning Research. Lingle Wang, Yujie Wu, Yuqing Deng, Byung...
arXiv 2015
-
[18]
AutoGen: Enabling next-gen LLM applica- tions via multi-agent conversation. InConference on Language Modeling (COLM). Rong Wu, Xiaoman Wang, Jianbiao Mei, Pinlong Cai, Daocheng Fu, Cheng Yang, Licheng Wen, Xuemeng Yang, Yufan Shen, Yuxin Wang, and Botian Shi. 2025. EvolveR: Self-evolving LLM agents through an experience-driven lifecycle.arXiv preprint arX...
Pith/arXiv arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.