MONA: Muon Optimizer with Nesterov Acceleration for Scalable Language Model Training
Pith reviewed 2026-06-29 19:12 UTC · model grok-4.3
The pith
MONA adds an acceleration term from the exponential moving average of gradient differences into Muon's gradient processing pipeline to escape sharp minima while keeping spectral-norm regularization.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
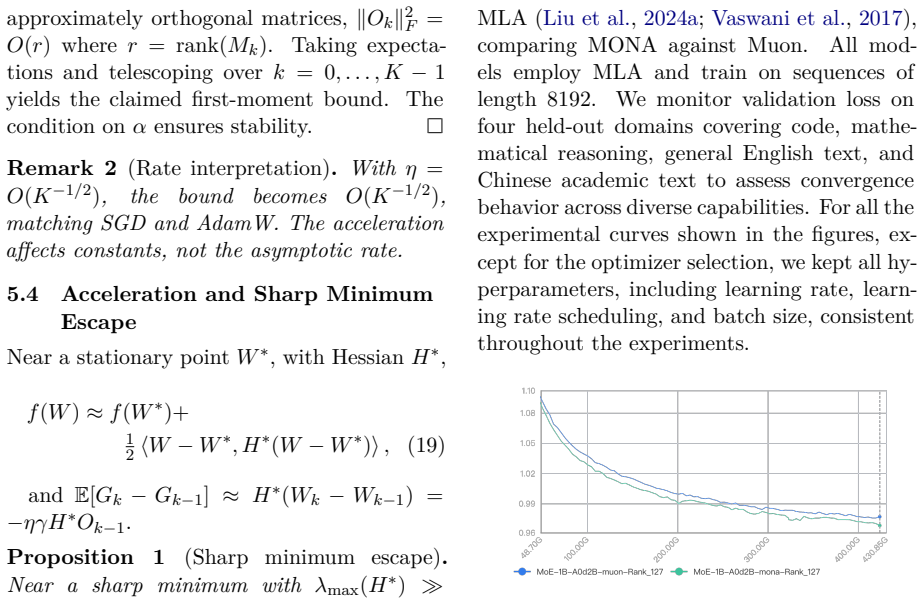
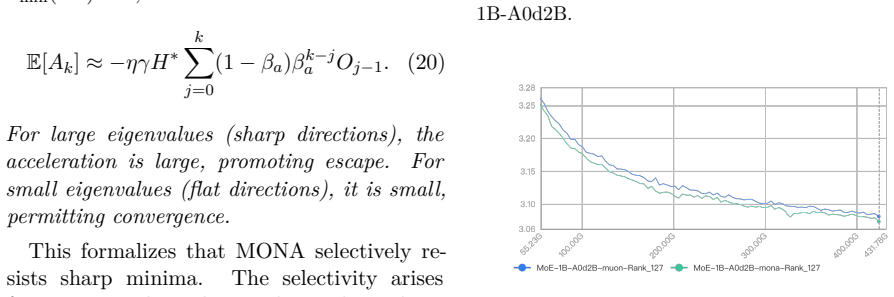
MONA adds an acceleration term, calculated from the exponential moving average of gradient differences, directly into Muon's gradient processing pipeline. Convergence analysis shows that the acceleration term enables escape from sharp minima while preserving Muon's spectral-norm regularization. Empirically, MONA achieves better convergence and downstream task performance compared to both Muon and AdamW across three scales of Mixture-of-Experts pretraining, spanning from 1B to 68B parameters, with the largest model trained on 1 trillion tokens. Furthermore, supervised fine-tuning on the MOE-68B-A3B model yields SOTA performance on general capability, mathematical reasoning, and code generatio
What carries the argument
The acceleration term added directly into Muon's gradient processing pipeline and computed from the exponential moving average of gradient differences.
If this is right
- MONA reaches lower training loss than Muon or AdamW on MoE models from 1B to 68B parameters.
- It produces higher downstream task performance after pretraining on up to one trillion tokens.
- The spectral-norm regularization property of Muon remains intact.
- SOTA results appear on general, math, and code benchmarks after fine-tuning the 68B model.
- The same gains hold across three different model scales.
Where Pith is reading between the lines
- The acceleration mechanism might be added to other orthogonalization-based optimizers with similar effect.
- Training runs on dense transformer models could test whether the gains are specific to MoE architectures.
- The convergence analysis could be extended to derive explicit rates that quantify the escape speed from sharp minima.
- Longer training horizons beyond one trillion tokens might reveal whether the advantage persists or saturates.
Load-bearing premise
The acceleration term enables escape from sharp minima while preserving Muon's spectral-norm regularization.
What would settle it
A side-by-side pretraining run of the 68B MoE model in which MONA produces neither faster loss reduction nor higher final downstream scores than Muon would falsify the empirical superiority claim.
Figures














read the original abstract
The Muon optimizer has recently offered a promising alternative to AdamW for large language model training, leveraging matrix orthogonalization to produce geometry-aware updates. However, like all first-order methods, Muon can become trapped in sharp local minima. In this work, we present MONA, an optimizer that bridges Muon's orthogonalization framework with curvature-aware acceleration. MONA adds an acceleration term directly into Muon's gradient processing pipeline. This term is calculated from the exponential moving average of gradient differences. We provide a detailed convergence analysis for MONA, showing that the acceleration term enables escape from sharp minima while preserving Muon's spectral-norm regularization. Empirically, MONA achieves better convergence and downstream task performance compared to both Muon and AdamW across three scales of Mixture-of-Experts pretraining, spanning from 1B to 68B parameters, with the largest model trained on 1 trillion tokens. Furthermore, we conduct supervised fine-tuning on the MOE-68B-A3B model and evaluate it on general capability, mathematical reasoning, and code generation benchmarks, where MONA achieves SOTA performance.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces MONA, which augments the Muon optimizer by inserting an acceleration term—computed as the exponential moving average of gradient differences—directly into Muon's gradient processing pipeline. It supplies a convergence analysis asserting that this term enables escape from sharp minima while preserving Muon's spectral-norm regularization property. Empirically, MONA is shown to yield better convergence and downstream performance than both Muon and AdamW on Mixture-of-Experts pretraining at three scales (1B to 68B parameters), with the largest model trained on 1 trillion tokens; after supervised fine-tuning of the 68B model, MONA attains SOTA results on general capability, mathematical reasoning, and code generation benchmarks.
Significance. If the convergence analysis holds under the step-size regimes and model architectures used in the experiments, and if the scaling results prove reproducible, MONA would represent a meaningful advance in optimizer design for large-scale language model training by combining geometry-aware orthogonalization with curvature-aware acceleration. The multi-scale empirical evaluation (1B–68B) together with the SFT benchmark results constitutes a substantial practical contribution; the explicit preservation of spectral-norm regularization is a noteworthy theoretical strength.
minor comments (3)
- [Convergence analysis] The convergence analysis section would benefit from an explicit statement of the Lipschitz or smoothness assumptions required for the escape-from-sharp-minima guarantee, together with a brief discussion of how these assumptions align with the MoE routing dynamics observed in the 68B experiments.
- [Experiments] Table 2 (or equivalent results table): the reported downstream metrics after SFT should include the number of independent runs or standard deviations to allow assessment of statistical reliability of the SOTA claim.
- [Method] The description of the acceleration term insertion (around Eq. (X) in the method section) could be accompanied by a short pseudocode snippet showing the exact placement relative to Muon's orthogonalization step for immediate reproducibility.
Simulated Author's Rebuttal
We thank the referee for the positive summary of our work on MONA and the recommendation for minor revision. The referee's description of the method, convergence analysis, and empirical results on MoE models up to 68B parameters is accurate.
Circularity Check
No significant circularity; derivation is self-contained
full rationale
The paper's central theoretical contribution is a convergence analysis showing that the added acceleration term (EMA of gradient differences) enables escape from sharp minima while preserving Muon's spectral-norm regularization. No load-bearing step reduces by construction to a fitted input, self-definition, or self-citation chain; the analysis is presented as a direct derivation from the modified update rule using standard optimization techniques. Empirical results consist of direct head-to-head comparisons on independent pretraining and SFT benchmarks across scales, without renaming known patterns or smuggling ansatzes via citation. The derivation chain therefore stands on its own stated assumptions and does not collapse to its inputs.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
- [1]
-
[2]
Alon Albalak, Duy Phung, Nathan Lile, Rafael Rafailov, Kanishk Gandhi, Louis Castricato, Anikait Singh, Chase Blagden, Violet Xiang, Dakota Mahan, and 1 others. 2025. Big-math: A large-scale, high-quality math dataset for reinforcement learning in language models. arXiv preprint arXiv:2502.17387
-
[3]
Loubna Ben Allal, Niklas Muennighoff, Logesh Kumar Umapathi, Ben Lipkin, and Leandro Von Werra. 2022. A framework for the evaluation of code generation models
2022
-
[4]
Yonatan Bisk, Rowan Zellers, Ronan Le Bras, Jianfeng Gao, and Yejin Choi. 2020. Piqa: Reasoning about physical commonsense in natural language. In Thirty-Fourth AAAI Conference on Artificial Intelligence
2020
-
[5]
Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, and 1 others. 2020. Language models are few-shot learners. Advances in neural information processing systems, 33:1877--1901
2020
- [6]
-
[7]
Multipl-e: A scalable and extensible approach to benchmarking neural code generation, 2022
Federico Cassano, John Gouwar, Daniel Nguyen, Sydney Nguyen, Luna Phipps-Costin, Donald Pinckney, Ming-Ho Yee, Yangtian Zi, Carolyn Jane Anderson, Molly Q Feldman, and 1 others. Multipl-e: A scalable and extensible approach to benchmarking neural code generation, 2022. URL https://arxiv. org/abs/2208.08227
-
[8]
Xiangning Chen, Chen Liang, Da Huang, Esteban Real, Kaiyuan Wang, Hieu Pham, Xuanyi Dong, Thang Luong, Cho-Jui Hsieh, Yifeng Lu, and 1 others. 2023. Symbolic discovery of optimization algorithms. Advances in neural information processing systems, 36:49205--49233
2023
- [9]
-
[10]
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, and 1 others. 2021. Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[11]
DeepSeek-AI. 2026. Deepseek-v4: Towards highly efficient million-token context intelligence
2026
-
[12]
Dheeru Dua, Yizhong Wang, Pradeep Dasigi, Gabriel Stanovsky, Sameer Singh, and Matt Gardner. 2019. Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short ...
2019
- [13]
-
[14]
Alex Gu, Baptiste Rozi \`e re, Hugh Leather, Armando Solar-Lezama, Gabriel Synnaeve, and Sida I Wang. 2024. Cruxeval: A benchmark for code reasoning, understanding and execution. arXiv preprint arXiv:2401.03065
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[15]
Vineet Gupta, Tomer Koren, and Yoram Singer. 2018. Shampoo: Preconditioned stochastic tensor optimization. In International Conference on Machine Learning, pages 1842--1850. PMLR
2018
- [16]
-
[17]
Dan Hendrycks, Collin Burns, Steven Basart, Andy Zou, Mantas Mazeika, Dawn Song, and Jacob Steinhardt. 2020. Measuring massive multitask language understanding. arXiv preprint arXiv:2009.03300
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[18]
Dan Hendrycks, Collin Burns, Saurav Kadavath, Akul Arora, Steven Basart, Eric Tang, Dawn Song, and Jacob Steinhardt. 2021. Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[19]
Yuzhen Huang, Yuzhuo Bai, Zhihao Zhu, Junlei Zhang, Jinghan Zhang, Tangjun Su, Junteng Liu, Chuancheng Lv, Yikai Zhang, Yao Fu, and 1 others. 2023. C-eval: A multi-level multi-discipline chinese evaluation suite for foundation models. Advances in neural information processing systems, 36:62991--63010
2023
-
[20]
Robert A Jacobs, Michael I Jordan, Steven J Nowlan, and Geoffrey E Hinton. 1991. Adaptive mixtures of local experts. Neural computation, 3(1):79--87
1991
-
[21]
Naman Jain, Alex Gu, Wen-Ding Li, Fanjia Yan, Tianjun Zhang, Sida Wang, Armando Solar-Lezama, Koushik Sen, and Ion Stoica. 2025. Livecodebench: Holistic and contamination free evaluation of large language models for code. In International Conference on Learning Representations, volume 2025, pages 58791--58831
2025
-
[22]
Keller Jordan, Yuchen Jin, Vlado Boza, You Jiacheng, Franz Cesista, Laker Newhouse, and Jeremy Bernstein. 2024. Muon: An optimizer for hidden layers in neural networks, 2024. URL https://kellerjordan. github. io/posts/muon, 6(3):4
2024
-
[23]
Nitish Shirish Keskar, Dheevatsa Mudigere, Jorge Nocedal, Mikhail Smelyanskiy, and Ping Tak Peter Tang. 2016. On large-batch training for deep learning: Generalization gap and sharp minima. arXiv preprint arXiv:1609.04836
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[24]
Ahmed Khaled, Kaan Ozkara, Tao Yu, Mingyi Hong, and Youngsuk Park. 2025. https://doi.org/10.48550/arXiv.2510.16981 Muonbp: Faster muon via block-periodic orthogonalization . arXiv preprint arXiv:2510.16981
-
[25]
Diederik P Kingma and Jimmy Ba. 2014. Adam: A method for stochastic optimization. arXiv preprint arXiv:1412.6980
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[26]
Yuhang Lai, Chengxi Li, Yiming Wang, Tianyi Zhang, Ruiqi Zhong, Luke Zettlemoyer, Wen-tau Yih, Daniel Fried, Sida Wang, and Tao Yu. 2023. Ds-1000: A natural and reliable benchmark for data science code generation. In International Conference on Machine Learning, pages 18319--18345. PMLR
2023
-
[27]
CMMLU: Measuring massive multitask language understanding in Chinese
Haonan Li, Yixuan Zhang, Fajri Koto, Yifei Yang, Hai Zhao, Yeyun Gong, Nan Duan, and Timothy Baldwin. Cmmlu: Measuring massive multitask language understanding in chinese, 2024. URL https://arxiv. org/abs/2306.09212
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[29]
Aixin Liu, Bei Feng, Bin Wang, Bingxuan Wang, Bo Liu, Chenggang Zhao, Chengqi Dengr, Chong Ruan, Damai Dai, Daya Guo, and 1 others. 2024 a . Deepseek-v2: A strong, economical, and efficient mixture-of-experts language model. arXiv preprint arXiv:2405.04434
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[30]
Aixin Liu, Bei Feng, Bing Xue, Bingxuan Wang, Bochao Wu, Chengda Lu, Chenggang Zhao, Chengqi Deng, Chenyu Zhang, Chong Ruan, and 1 others. 2024 b . Deepseek-v3 technical report. arXiv preprint arXiv:2412.19437
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[31]
Hong Liu, Jiaqi Zhang, Chao Wang, Xing Hu, Linkun Lyu, Jiaqi Sun, Xurui Yang, Bo Wang, Fengcun Li, Yulei Qian, Lingtong Si, Yerui Sun, Rumei Li, Peng Pei, Yuchen Xie, and Xunliang Cai. 2026. https://arxiv.org/abs/2601.21204 Scaling embeddings outperforms scaling experts in language models . Preprint, arXiv:2601.21204
- [32]
-
[33]
Jingyuan Liu, Jianlin Su, Xingcheng Yao, Zhejun Jiang, Guokun Lai, Yulun Du, Yidao Qin, Weixin Xu, Enzhe Lu, Junjie Yan, and 1 others. 2025. Muon is scalable for llm training. arXiv preprint arXiv:2502.16982
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[34]
Ilya Loshchilov and Frank Hutter. 2017. Decoupled weight decay regularization. arXiv preprint arXiv:1711.05101
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[35]
James Martens and Roger Grosse. 2015. Optimizing neural networks with kronecker-factored approximate curvature. In International conference on machine learning, pages 2408--2417. PMLR
2015
-
[36]
Paulius Micikevicius, Sharan Narang, Jonah Alben, Gregory Diamos, Erich Elsen, David Garcia, Boris Ginsburg, Michael Houston, Oleksii Kuchaiev, Ganesh Venkatesh, and 1 others. 2017. Mixed precision training. arXiv preprint arXiv:1710.03740
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[37]
Todor Mihaylov, Peter Clark, Tushar Khot, and Ashish Sabharwal. 2018. Can a suit of armor conduct electricity? a new dataset for open book question answering. In EMNLP
2018
-
[38]
David Rein, Betty Li Hou, Asa Cooper Stickland, Jackson Petty, Richard Yuanzhe Pang, Julien Dirani, Julian Michael, and Samuel R Bowman. 2023. Gpqa: A graduate-level google-proof q&a benchmark. arXiv preprint arXiv:2311.12022
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[39]
Herbert Robbins and Sutton Monro. 1951. A stochastic approximation method. The annals of mathematical statistics, pages 400--407
1951
-
[40]
Keisuke Sakaguchi, Ronan Le Bras, Chandra Bhagavatula, and Yejin Choi. 2019. Winogrande: An adversarial winograd schema challenge at scale. arXiv preprint arXiv:1907.10641
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[41]
Maarten Sap, Hannah Rashkin, Derek Chen, Ronan LeBras, and Yejin Choi. 2019. https://www.aclweb.org/anthology/D19-1454 Social iqa: Commonsense reasoning about social interactions . In EMNLP
2019
- [42]
-
[43]
Ilya Sutskever, James Martens, George Dahl, and Geoffrey Hinton. 2013. On the importance of initialization and momentum in deep learning. In International conference on machine learning, pages 1139--1147. pmlr
2013
-
[44]
Mirac Suzgun, Nathan Scales, Nathanael Sch \"a rli, Sebastian Gehrmann, Yi Tay, Hyung Won Chung, Aakanksha Chowdhery, Quoc Le, Ed Chi, Denny Zhou, and 1 others. 2023. Challenging big-bench tasks and whether chain-of-thought can solve them. In Findings of the Association for Computational Linguistics: ACL 2023, pages 13003--13051
2023
-
[45]
Oyvind Tafjord, Bhavana Dalvi, and Peter Clark. 2021. Proofwriter: Generating implications, proofs, and abductive statements over natural language. In Findings of the Association for Computational Linguistics: ACL-IJCNLP 2021, pages 3621--3634
2021
-
[46]
Alon Talmor, Jonathan Herzig, Nicholas Lourie, and Jonathan Berant. 2019. https://doi.org/10.18653/v1/N19-1421 C ommonsense QA : A question answering challenge targeting commonsense knowledge . In Proceedings of the 2019 Conference of the North A merican Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long ...
-
[47]
Kimi Team, Yifan Bai, Yiping Bao, Guanduo Chen, Jiahao Chen, Ningxin Chen, Ruijue Chen, Yanru Chen, Yuankun Chen, Yutian Chen, Zhuofu Chen, Jialei Cui, Hao Ding, Mengnan Dong, Angang Du, Chenzhuang Du, Dikang Du, Yulun Du, Yu Fan, and 150 others. 2025 a . https://arxiv.org/abs/2507.20534 Kimi k2: Open agentic intelligence . Preprint, arXiv:2507.20534
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [48]
-
[49]
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, ukasz Kaiser, and Illia Polosukhin. 2017. Attention is all you need. Advances in neural information processing systems, 30
2017
-
[50]
Yubo Wang, Xueguang Ma, Ge Zhang, Yuansheng Ni, Abhranil Chandra, Shiguang Guo, Weiming Ren, Aaran Arulraj, Xuan He, Ziyan Jiang, and 1 others. 2024. Mmlu-pro: A more robust and challenging multi-task language understanding benchmark. Advances in Neural Information Processing Systems, 37:95266--95290
2024
- [51]
-
[52]
Xingyu Xie, Pan Zhou, Huan Li, Zhouchen Lin, and Shuicheng Yan. 2024. Adan: Adaptive nesterov momentum algorithm for faster optimizing deep models. IEEE Transactions on Pattern Analysis and Machine Intelligence, 46(12):9508--9520
2024
-
[53]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, and 1 others. 2025. Qwen3 technical report. arXiv preprint arXiv:2505.09388
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[54]
Yang You, Igor Gitman, and Boris Ginsburg. 2017. Large batch training of convolutional networks. arXiv preprint arXiv:1708.03888
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[55]
Yang You, Jing Li, Sashank Reddi, Jonathan Hseu, Sanjiv Kumar, Srinadh Bhojanapalli, Xiaodan Song, James Demmel, Kurt Keutzer, and Cho-Jui Hsieh. 2019. Large batch optimization for deep learning: Training bert in 76 minutes. arXiv preprint arXiv:1904.00962
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[56]
Daoguang Zan, Bei Chen, Zeqi Lin, Bei Guan, Yongji Wang, and Jian-Guang Lou. 2022. When language model meets private library. In Findings of the Association for Computational Linguistics: EMNLP 2022, pages 277--288
2022
-
[57]
Rowan Zellers, Ari Holtzman, Yonatan Bisk, Ali Farhadi, and Yejin Choi. 2019. Hellaswag: Can a machine really finish your sentence? In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics
2019
-
[58]
Tong Zhao, Jiacheng Li, Yuanchang Zhou, Guangming Tan, and Weile Jia. 2026. Exploring landscapes for better minima along valleys. Advances in Neural Information Processing Systems, 38:171496--171547
2026
-
[59]
Terry Yue Zhuo, Minh Chien Vu, Jenny Chim, Han Hu, Wenhao Yu, Ratnadira Widyasari, Imam Nur Bani Yusuf, Haolan Zhan, Junda He, Indraneil Paul, and 1 others. 2025. Bigcodebench: Benchmarking code generation with diverse function calls and complex instructions. In International Conference on Learning Representations, volume 2025, pages 66602--66656
2025
-
[60]
online" 'onlinestring :=
ENTRY address archivePrefix author booktitle chapter edition editor eid eprint eprinttype howpublished institution journal key month note number organization pages publisher school series title type volume year doi pubmed url lastchecked label extra.label sort.label short.list INTEGERS output.state before.all mid.sentence after.sentence after.block STRING...
-
[61]
write newline
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION word.in bbl.in capitalize " " * FUNCT...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.