SLIM-RL: Risk-Budgeted Random-Masking RL for Diffusion LLMs Without Trajectory Slicing
Pith reviewed 2026-07-02 19:03 UTC · model grok-4.3
The pith
SLIM-RL bounds commit risk with a tau-budget decoder to enable trace-free random-masking RL for diffusion LLMs, matching trajectory methods with fewer samples.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
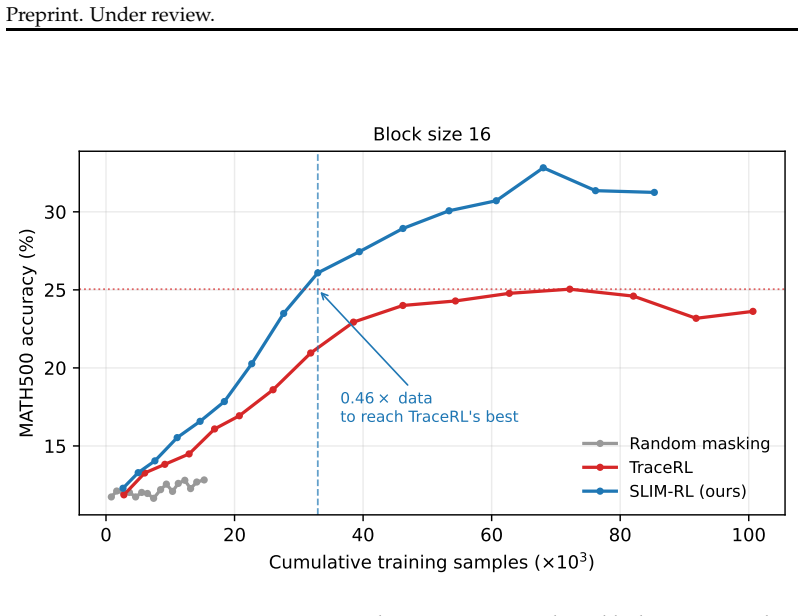
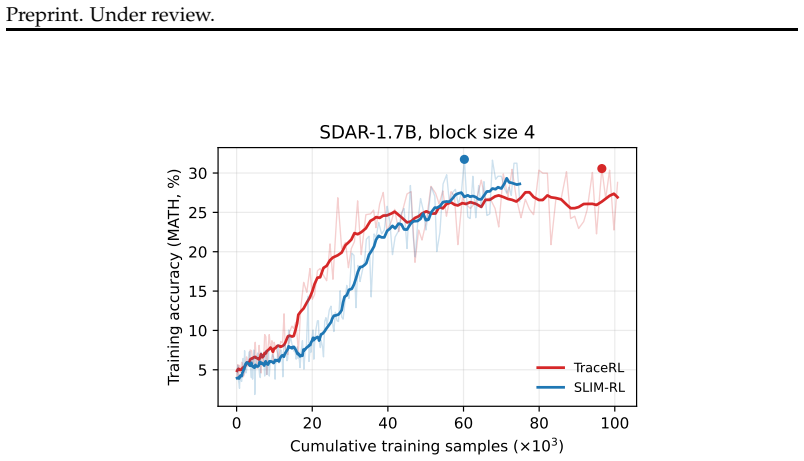
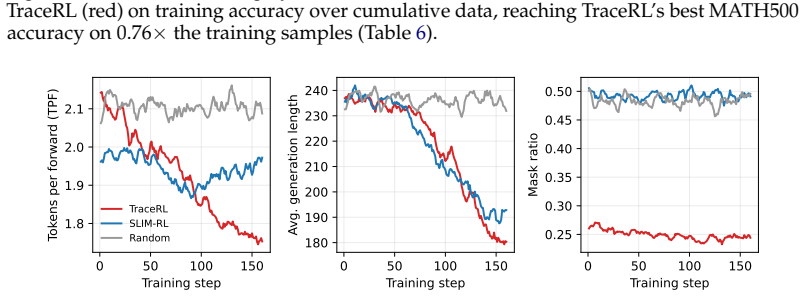
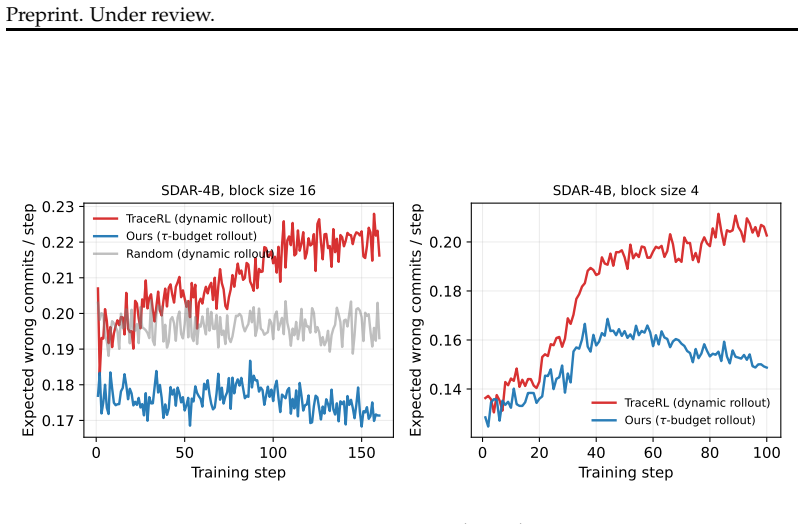
SLIM-RL introduces a tau-budget decoder that bounds the commit risk of rollout steps, thereby reducing aggregate commit risk in the training data. Optimization then proceeds with a trace-free random-masking objective that incorporates sequence-level importance sampling, deterministic quadrature over masking levels, and a mean-preserving monotonically decreasing per-block mask schedule. This yields equivalent MATH500 accuracy to TraceRL using 0.46 times the training samples at block size 16 on SDAR-4B, along with accuracy gains of 6.32% on MATH500 and 11.05% on GSM8K.
What carries the argument
The tau-budget decoder that bounds aggregate commit risk to support a trace-free random-masking objective instead of trajectory slicing.
If this is right
- Matches TraceRL best MATH500 accuracy on 0.46x training samples at block size 16
- Gains 6.32% on MATH500 and 11.05% on GSM8K over TraceRL under matched sampling
- At block size 4, 4B SLIM-RL exceeds LLaDA-8B by 10.76% on MATH500
- Gains 4.20% on MBPP and 3.65% on HumanEval over TraceRL
- Tau-budget decoder works training-free on LLaDA, Dream, and SDAR
Where Pith is reading between the lines
- The risk-budget approach could support larger block sizes in diffusion models without proportional growth in RL training cost.
- Similar risk control might simplify RL objectives for other non-autoregressive or diffusion-based generators.
- Improved sample efficiency may enable RL fine-tuning of even larger diffusion LLMs where full trajectory reconstruction would be too costly.
Load-bearing premise
The tau-budget decoder successfully bounds aggregate commit risk in the training data so that a trace-free random-masking objective can replace trajectory slicing without loss of optimization quality.
What would settle it
Running the random-masking objective on the same rollouts but without applying the tau-budget decoder and checking if the resulting model underperforms TraceRL on MATH500 at the same number of samples.
Figures

read the original abstract
Reinforcement learning for diffusion large language models (dLLMs) has largely moved to trajectory-aware methods. The current state of the art, TraceRL, holds that random masking is mismatched with the model's inference trajectory, and it reconstructs that trajectory during training by slicing each rollout into up to K/s trajectory-aligned training samples, a cost that grows with the block size K. We show that this mismatch can be mitigated without reconstructing the trajectory. Our method, SLIM-RL, bounds the commit risk of each rollout step with a tau-budget decoder, reducing aggregate commit risk in the training data. During optimization, SLIM-RL trains on these risk-controlled rollouts with a trace-free random-masking objective that adapts variance-reduction tools, combining sequence-level importance sampling, deterministic quadrature over masking levels under a mean-preserving, monotonically decreasing per-block mask schedule that we introduce. On SDAR-4B, SLIM-RL matches TraceRL's best MATH500 accuracy on only 0.46x its training samples at block size 16, improving over TraceRL by 6.32% on MATH500 and 11.05% on GSM8K under matched dynamic sampling. At block size 4, the 4B SLIM-RL surpasses the larger LLaDA-8B and Dream-7B dLLMs on math, exceeding LLaDA-8B by 10.76% on MATH500 while staying below the autoregressive Qwen2.5-7B. On code, it improves over TraceRL by 4.20% on MBPP and 3.65% on HumanEval. The tau-budget decoder transfers training-free across LLaDA, Dream, and SDAR. The source code is available at https://github.com/laolaorkkkkk/SLIM-RL .
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces SLIM-RL for risk-budgeted random-masking reinforcement learning in diffusion large language models. It proposes using a tau-budget decoder to bound commit risk in rollouts, allowing a trace-free random-masking objective that incorporates sequence-level importance sampling, deterministic quadrature over masking levels, and a newly introduced mean-preserving monotonically decreasing per-block mask schedule. This avoids the trajectory slicing required by TraceRL. Empirical results on SDAR-4B demonstrate that SLIM-RL matches TraceRL's best MATH500 accuracy using only 0.46x the training samples at block size 16, with improvements of 6.32% on MATH500 and 11.05% on GSM8K under matched dynamic sampling. Additional gains are reported on code generation tasks, and the approach transfers across base models including LLaDA and Dream.
Significance. If the results hold, the work is significant as it provides an empirical demonstration that trajectory reconstruction is not necessary for effective RL in dLLMs when commit risk is controlled, leading to substantial sample efficiency gains. The open sourcing of the code supports reproducibility. The transfer of the tau-budget decoder training-free across models is a notable strength. This could influence future work on efficient training methods for non-autoregressive LLMs.
minor comments (2)
- The method section should provide pseudocode or a detailed algorithm for the tau-budget decoder to allow independent verification of how aggregate commit risk is bounded.
- An ablation table isolating the contribution of the mean-preserving mask schedule versus standard schedules would strengthen the presentation of the variance-reduction components.
Simulated Author's Rebuttal
We thank the referee for the positive summary, significance assessment, and recommendation of minor revision. No major comments appear in the report, so we provide no point-by-point responses below.
Circularity Check
No significant circularity identified
full rationale
The paper's central claims consist of empirical performance comparisons (e.g., 0.46× samples to match TraceRL MATH500 accuracy, +6.32% MATH500 and +11.05% GSM8K gains under matched dynamic sampling) on held-out benchmarks across multiple base models. No equations, derivations, or self-citations are presented that reduce any reported result to a fitted quantity or input defined from the same data by construction. The tau-budget decoder and trace-free random-masking objective are introduced as methodological components whose effectiveness is demonstrated experimentally rather than assumed via internal redefinition or prior self-work.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Block diffusion: Interpolating between autoregres- sive and diffusion language models
Marianne Arriola, Aaron Gokaslan, Justin Chiu, Zhihan Yang, Zhixuan Qi, Jiaqi Han, Sub- ham Sahoo, and Volodymyr Kuleshov. Block diffusion: Interpolating between autoregres- sive and diffusion language models. InInternational Conference on Learning Representations, volume 2025, pp. 50726–50753,
2025
-
[2]
Program Synthesis with Large Language Models
Jacob Austin, Daniel D Johnson, Jonathan Ho, Daniel Tarlow, and Rianne Van Den Berg. Structured denoising diffusion models in discrete state-spaces.Advances in neural informa- tion processing systems, 34:17981–17993, 2021a. Jacob Austin, Augustus Odena, Maxwell Nye, Maarten Bosma, Henryk Michalewski, David Dohan, Ellen Jiang, Carrie Cai, Michael Terry, Qu...
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
LLaDA2.0: Scaling Up Diffusion Language Models to 100B
URLhttps://arxiv.org/abs/2512.15745. Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde De Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, et al. Evalu- ating large language models trained on code.arXiv preprint arXiv:2107.03374,
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Sdar: A synergistic diffusion- autoregression paradigm for scalable sequence generation
Shuang Cheng, Yihan Bian, Dawei Liu, Yuhua Jiang, Yihao Liu, Linfeng Zhang, Qian Yao, Zhongbo Tian, Wenhai Wang, Qipeng Guo, et al. Sdar: A synergistic diffusion- autoregression paradigm for scalable sequence generation. InFindings of the Association for Computational Linguistics: ACL 2026, pp. 22058–22075,
2026
-
[5]
Training Verifiers to Solve Math Word Problems
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, et al. Training verifiers to solve math word problems.arXiv preprint arXiv:2110.14168,
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
DiffuSeq: Sequence to Sequence Text Generation with Diffusion Models
Shansan Gong, Mukai Li, Jiangtao Feng, Zhiyong Wu, and LingPeng Kong. Diffuseq: Se- quence to sequence text generation with diffusion models.arXiv preprint arXiv:2210.08933,
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
9 Preprint. Under review. Shansan Gong, Ruixiang Zhang, Huangjie Zheng, Jiatao Gu, Navdeep Jaitly, Lingpeng Kong, and Yizhe Zhang. Diffucoder: Understanding and improving masked diffusion models for code generation.arXiv preprint arXiv:2506.20639,
-
[8]
S2D2: Fast Decoding for Diffusion LLMs via Training-Free Self-Speculation
Ligong Han, Hao Wang, Han Gao, Kai Xu, and Akash Srivastava. S2d2: Fast decoding for diffusion llms via training-free self-speculation.arXiv preprint arXiv:2603.25702,
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
Haoyu He, Katrin Renz, Yong Cao, and Andreas Geiger. Mdpo: Overcoming the training- inference divide of masked diffusion language models.arXiv preprint arXiv:2508.13148,
-
[10]
Measuring Mathematical Problem Solving With the MATH Dataset
Dan Hendrycks, Collin Burns, Saurav Kadavath, Akul Arora, Steven Basart, Eric Tang, Dawn Song, and Jacob Steinhardt. Measuring mathematical problem solving with the math dataset.arXiv preprint arXiv:2103.03874,
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
Yanzhe Hu, Yijie Jin, Pengfei Liu, Kai Yu, and Zhijie Deng. Lightningrl: Breaking the accuracy-parallelism trade-off of block-wise dllms via reinforcement learning.arXiv preprint arXiv:2603.13319,
-
[12]
arXiv preprint arXiv:2412.01152 , year=
URL https://arxiv.org/abs/ 2412.01152. Xiang Li, John Thickstun, Ishaan Gulrajani, Percy S Liang, and Tatsunori B Hashimoto. Diffusion-lm improves controllable text generation.Advances in neural information process- ing systems, 35:4328–4343,
-
[13]
Jiawei Liu, Xiting Wang, Yuanyuan Zhong, Defu Lian, and Yu Yang. Efficient and stable reinforcement learning for diffusion language models.arXiv preprint arXiv:2602.08905,
-
[14]
Understanding R1-Zero-Like Training: A Critical Perspective
Zichen Liu, Changyu Chen, Wenjun Li, Penghui Qi, Tianyu Pang, Chao Du, Wee Sun Lee, and Min Lin. Understanding r1-zero-like training: A critical perspective.arXiv preprint arXiv:2503.20783,
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
Jingyang Ou, Jiaqi Han, Minkai Xu, Shaoxuan Xu, Jianwen Xie, Stefano Ermon, Yi Wu, and Chongxuan Li. Principled rl for diffusion llms emerges from a sequence-level perspective. arXiv preprint arXiv:2512.03759,
-
[16]
URLhttps://arxiv.org/abs/2412.15115. Kevin Rojas, Jiahe Lin, Kashif Rasul, Anderson Schneider, Yuriy Nevmyvaka, Molei Tao, and Wei Deng. Improving reasoning for diffusion language models via group diffusion policy optimization.arXiv preprint arXiv:2510.08554,
work page internal anchor Pith review Pith/arXiv arXiv
-
[17]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
10 Preprint. Under review. Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Yang Wu, et al. Deepseekmath: Pushing the limits of mathe- matical reasoning in open language models.arXiv preprint arXiv:2402.03300,
work page internal anchor Pith review Pith/arXiv arXiv
-
[18]
URL https://arxiv.org/ abs/2507.08838. Guanghan Wang, Gilad Turok, Yair Schiff, Marianne Arriola, and Volodymyr Kuleshov. d2: Improving reasoning in diffusion language models via trajectory likelihood estimation,
-
[19]
d2: Improving Reasoning in Diffusion Language Models via Trajectory Likelihood Estimation
URLhttps://arxiv.org/abs/2509.21474. Xu Wang, Chenkai Xu, Yijie Jin, Jiachun Jin, Hao Zhang, and Zhijie Deng. Diffusion llms can do faster-than-ar inference via discrete diffusion forcing.arXiv preprint arXiv:2508.09192, 2025a. Yinjie Wang, Ling Yang, Bowen Li, Ye Tian, Ke Shen, and Mengdi Wang. Revolutionizing reinforcement learning framework for diffusi...
work page internal anchor Pith review Pith/arXiv arXiv
-
[20]
Dream 7B: Diffusion Large Language Models
Jiacheng Ye, Zhihui Xie, Lin Zheng, Jiahui Gao, Zirui Wu, Xin Jiang, Zhenguo Li, and Ling- peng Kong. Dream 7b: Diffusion large language models.arXiv preprint arXiv:2508.15487,
work page internal anchor Pith review Pith/arXiv arXiv
-
[21]
Runpeng Yu, Xinyin Ma, and Xinchao Wang. Dimple: Discrete diffusion multimodal large language model with parallel decoding.arXiv preprint arXiv:2505.16990,
-
[22]
Group Sequence Policy Optimization
Chujie Zheng, Shixuan Liu, Mingze Li, Xiong-Hui Chen, Bowen Yu, Chang Gao, Kai Dang, Yuqiong Liu, Rui Men, An Yang, et al. Group sequence policy optimization.arXiv preprint arXiv:2507.18071,
work page internal anchor Pith review Pith/arXiv arXiv
-
[23]
LLaDA 1.5: Variance-Reduced Preference Optimization for Large Language Diffusion Models
Fengqi Zhu, Rongzhen Wang, Shen Nie, Xiaolu Zhang, Chunwei Wu, Jun Hu, Jun Zhou, Jianfei Chen, Yankai Lin, Ji-Rong Wen, and Chongxuan Li. Llada 1.5: Variance-reduced preference optimization for large language diffusion models, 2025a. URL https://arxiv. org/abs/2505.19223. Ying Zhu, Jiaxin Wan, Xiaoran Liu, Siyang He, Qiqi Wang, Xu Guo, Tianyi Liang, Zengf...
work page internal anchor Pith review Pith/arXiv arXiv
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.