SWE-Future: Forecast-Conditioned Data Synthesis for Future-Oriented Software Engineering Agents
Pith reviewed 2026-06-26 20:22 UTC · model grok-4.3
The pith
Repository forecasts can generate future-oriented coding tasks without replaying historical pull requests.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
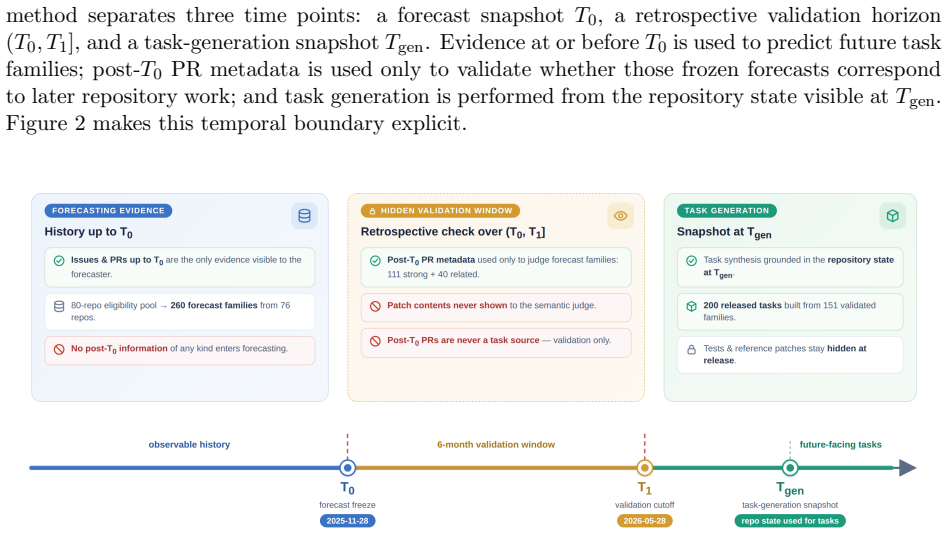
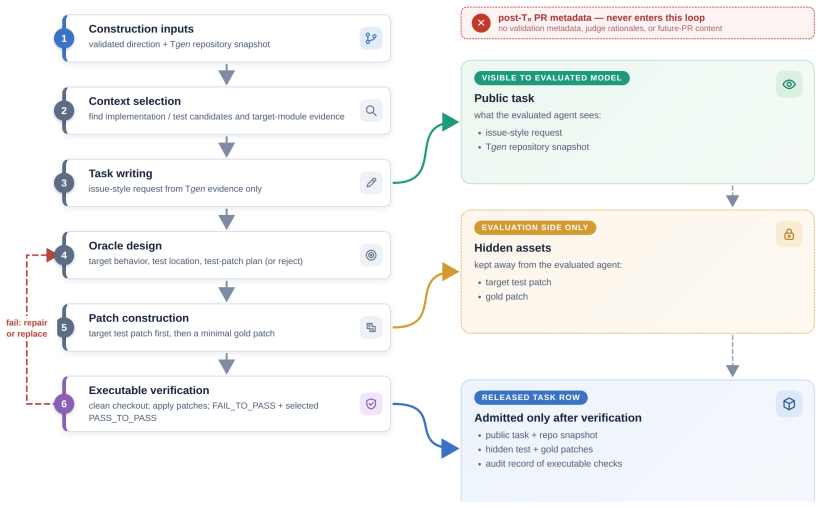
Given a forecast snapshot at time T0, the method forecasts future task families using only pre-T0 evidence and validates them retrospectively against later pull requests, achieving 58.1% relevance. These validated families then serve as conditioning signals to synthesize a 200-task dataset without replaying the validation pull requests, demonstrating that repository-evolution forecasts can guide realistic future-oriented task synthesis.
What carries the argument
Forecast-conditioned data synthesis, which uses predicted task families from pre-T0 repository evidence to direct the generation of coding tasks.
If this is right
- Forecasts derived solely from pre-T0 data can achieve 58.1% relevance to actual future repository work under the main semantic matching metric.
- Validated forecast families can condition task synthesis to create datasets that avoid direct use of the validating pull requests.
- A 200-task coding-agent dataset was produced across 61 repositories using this forecast-conditioned approach.
- The method reduces direct dependence on historical pull-request replay for creating realistic benchmarks.
Where Pith is reading between the lines
- Continuous updates to benchmarks could be generated by periodically refreshing forecasts from evolving repositories.
- The same conditioning approach might apply to other agent domains where historical data risks training overlap.
- Refinements to semantic matching could improve how well forecast families translate into practically useful tasks.
Load-bearing premise
That retrospective matching of predicted task families to later pull requests via semantic metrics reliably indicates the forecasts will produce useful synthetic tasks for future-oriented evaluation.
What would settle it
If coding agents evaluated on forecast-synthesized tasks show substantially lower success rates than on replay-based tasks when both are tested against actual future repository changes in new repositories, the central claim would be falsified.
Figures



read the original abstract
Realistic coding-agent benchmarks often replay public GitHub issues and pull requests, making them vulnerable to overlap with model pretraining, fine-tuning, synthetic-data generation, or benchmark-driven model selection. Fully synthetic tasks avoid direct historical replay, but can drift away from real repository needs. We propose SWE-Future, a forecast-conditioned data synthesis method for future-oriented coding tasks. Given a forecast snapshot at time $T_0$, the method uses only pre-$T_0$ repository evidence to forecast future feature implementation/enhancement, bugfix, and refactor task families. We first validate this forecasting step retrospectively: after forecasts are fixed, later pull requests are used only to measure whether the predicted task families match future repository work. In an 80-repository study, the forecaster achieves 58.1\% future-work relevance under the main semantic matching metric. We then use validated forecast families as conditioning signals to synthesize a 200-task coding-agent dataset across 61 repositories from a task-generation snapshot, rather than replaying the later pull requests used for validation. SWE-Future shows that repository-evolution forecasts can guide realistic, future-oriented coding-task synthesis while reducing direct dependence on historical pull-request replay.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes SWE-Future, a forecast-conditioned data synthesis method for future-oriented coding tasks in software engineering agents. Given a forecast snapshot at T0, it uses only pre-T0 repository evidence to predict future task families (feature implementation/enhancement, bugfix, refactor). These forecasts are validated retrospectively against later pull requests in an 80-repository study, achieving 58.1% future-work relevance under the main semantic matching metric. Validated forecast families then condition synthesis of a 200-task dataset across 61 repositories from a separate task-generation snapshot, avoiding direct replay of the validation PRs.
Significance. If the forecasting validation is robust, the work offers a concrete path toward coding-agent benchmarks with reduced overlap with historical PR replay and pretraining data. The explicit separation of the forecast-validation snapshot from the synthesis snapshot is a methodological strength that directly addresses circularity concerns in benchmark construction and supports falsifiable claims about future-oriented task relevance.
major comments (1)
- [80-repository retrospective study (abstract and validation section)] The 58.1% future-work relevance figure (abstract; 80-repository retrospective study) is load-bearing for the central claim that pre-T0 forecasts predict actual future repository work. The manuscript provides no description of the semantic matching metric, including how task-family embeddings or similarities are computed, the threshold or decision rule applied, inter-annotator agreement if human review is used, or any stratification/matching controls on repository selection. This omission prevents evaluation of whether the metric could be inflated by generic signals or selection bias.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback and for recognizing the methodological value of separating the forecast-validation and synthesis snapshots. We address the single major comment below.
read point-by-point responses
-
Referee: [80-repository retrospective study (abstract and validation section)] The 58.1% future-work relevance figure (abstract; 80-repository retrospective study) is load-bearing for the central claim that pre-T0 forecasts predict actual future repository work. The manuscript provides no description of the semantic matching metric, including how task-family embeddings or similarities are computed, the threshold or decision rule applied, inter-annotator agreement if human review is used, or any stratification/matching controls on repository selection. This omission prevents evaluation of whether the metric could be inflated by generic signals or selection bias.
Authors: We agree that the current manuscript omits necessary details on the semantic matching metric used to obtain the 58.1% figure, which limits evaluation of its robustness. In the revised manuscript we will expand the validation section (and corresponding appendix) to specify: the embedding model and vectorization procedure for task-family representations, the similarity function and exact threshold/decision rule, confirmation that the primary reported metric is fully automated (with no human review or IAA statistics), and the repository sampling procedure including any stratification by language, size, domain, or activity level. These additions will directly address concerns about generic signals or selection bias while leaving the reported 58.1% value unchanged. revision: yes
Circularity Check
No circularity: pre-T0 forecasting, held-out retrospective measurement, and independent synthesis snapshot remain separate
full rationale
The paper's chain fixes forecasts exclusively from pre-T0 evidence, uses later PRs solely as an external measurement set for the 58.1% relevance figure, and generates the 200-task dataset from a distinct task-generation snapshot without replaying the validation PRs. No equation or step equates the forecast output to the validation input by construction, no parameter is fitted to the target future distribution and then relabeled as a prediction, and no load-bearing premise rests on self-citation. The separation of stages keeps the derivation self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
SWE- rebench: An automated pipeline for task collection and decontaminated evaluation of software engineering agents, 2025
Ibragim Badertdinov, Alexander Golubev, Maksim Nekrashevich, Anton Shevtsov, Simon Karasik, Andrei Andriushchenko, Maria Trofimova, Daria Litvintseva, and Boris Yangel. SWE- rebench: An automated pipeline for task collection and decontaminated evaluation of software engineering agents, 2025
2025
-
[2]
daVinci- Env: Open SWE environment synthesis at scale, 2026
Dayuan Fu, Shenyu Wu, Yunze Wu, Zerui Peng, Yaxing Huang, Jie Sun, Ji Zeng, Mohan Jiang, Lin Zhang, Yukun Li, Jiarui Hu, Liming Liu, Jinlong Hou, and Pengfei Liu. daVinci- Env: Open SWE environment synthesis at scale, 2026
2026
-
[3]
Graves, Alan F
Todd L. Graves, Alan F. Karr, J. S. Marron, and Harvey Siy. Predicting fault incidence using software change history.IEEE Transactions on Software Engineering, 26(7):653–661, 2000
2000
-
[4]
SWE-Factory: Your automated factory for issue resolution training data and evaluation benchmarks, 2026
Lianghong Guo, Yanlin Wang, Caihua Li, Wei Tao, Pengyu Yang, Jiachi Chen, Haoyu Song, Duyu Tang, and Zibin Zheng. SWE-Factory: Your automated factory for issue resolution training data and evaluation benchmarks, 2026. To appear at FSE 2026
2026
-
[5]
Ahmed E. Hassan. Predicting faults using the complexity of code changes. InProceedings of the 31st International Conference on Software Engineering, pages 78–88, 2009
2009
-
[6]
Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik Narasimhan
Carlos E. Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik Narasimhan. SWE-bench: Can language models resolve real-world github issues? In International Conference on Learning Representations, 2024
2024
-
[7]
Hassan, Audris Mockus, Anand Sinha, and Naoyasu Ubayashi
Yasutaka Kamei, Emad Shihab, Bram Adams, Ahmed E. Hassan, Audris Mockus, Anand Sinha, and Naoyasu Ubayashi. A large-scale empirical study of just-in-time quality assurance. IEEE Transactions on Software Engineering, 39(6):757–773, 2013
2013
-
[8]
FEA-Bench: A benchmark for evaluating repository-level code generation for feature implementation
Wei Li, Xin Zhang, Zhongxin Guo, Shaoguang Mao, Wen Luo, Guangyue Peng, Yangyu Huang, Houfeng Wang, and Scarlett Li. FEA-Bench: A benchmark for evaluating repository-level code generation for feature implementation. InProceedings of the Annual Meeting of the Association for Computational Linguistics, 2025
2025
-
[9]
On leakage of code generation evaluation datasets
Alexandre Matton, Tom Sherborne, Dennis Aumiller, Elena Tommasone, Milad Alizadeh, Jingyi He, Raymond Ma, Maxime Voisin, Ellen Gilsenan-McMahon, and Matthias Gall´ e. On leakage of code generation evaluation datasets. InFindings of the Association for Computa- tional Linguistics: EMNLP 2024, pages 13215–13223, Miami, Florida, USA, 2024. Association for Co...
2024
-
[10]
Use of relative code churn measures to predict system defect density
Nachiappan Nagappan and Thomas Ball. Use of relative code churn measures to predict system defect density. InProceedings of the 27th International Conference on Software Engineering, pages 284–292, 2005
2005
-
[11]
Quantifying contamination in evaluating code generation capabilities of language models
Martin Riddell, Ansong Ni, and Arman Cohan. Quantifying contamination in evaluating code generation capabilities of language models. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 14116–14137, Bangkok, Thailand, 2024. Association for Computational Linguistics
2024
-
[12]
A time-consistent benchmark for repository-level software engineering evaluation, 2026
Xianpeng Sun, Haonan Sun, Tian Yu, Sheng Ma, Qincheng Zhang, Lifei Rao, and Chen Tian. A time-consistent benchmark for repository-level software engineering evaluation, 2026. 19
2026
-
[13]
SWE-Bench++: A frame- work for the scalable generation of software engineering benchmarks from open-source reposi- tories, 2025
Lilin Wang, Lucas Ramalho, Alan Celestino, Phuc Anthony Pham, Yu Liu, Umang Kumar Sinha, Andres Portillo, Onassis Osunwa, and Gabriel Maduekwe. SWE-Bench++: A frame- work for the scalable generation of software engineering benchmarks from open-source reposi- tories, 2025
2025
-
[14]
SWE-Hub: A unified production system for scalable, executable software engineering tasks, 2026
Yucheng Zeng, Shupeng Li, Daxiang Dong, Ruijie Xu, Zimo Chen, Liwei Zheng, Yuxuan Li, Zhe Zhou, Haotian Zhao, Lun Tian, Heng Xiao, Tianshu Zhu, Longkun Hao, and Jianmin Wu. SWE-Hub: A unified production system for scalable, executable software engineering tasks, 2026
2026
-
[15]
Training versatile coding agents in synthetic environments, 2026
Yiqi Zhu, Apurva Gandhi, and Graham Neubig. Training versatile coding agents in synthetic environments, 2026. SWE-Playground project repository
2026
-
[16]
Mining version histories to guide software changes
Thomas Zimmermann, Peter Weissgerber, Stephan Diehl, and Andreas Zeller. Mining version histories to guide software changes. InProceedings of the 26th International Conference on Software Engineering, pages 563–572, 2004. 20
2004
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.