Momento: Evaluating Persistent Memory and Reasoning with Multi-Session Agentic Conversations
Pith reviewed 2026-06-28 18:42 UTC · model grok-4.3
The pith
Current agents fail multi-session tasks by misestimating user state from stale session history.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
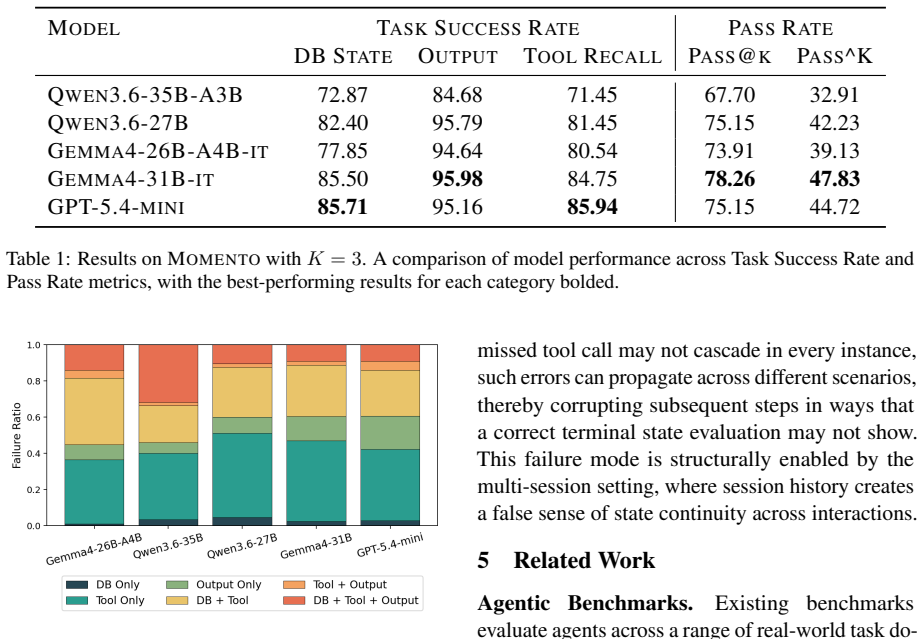
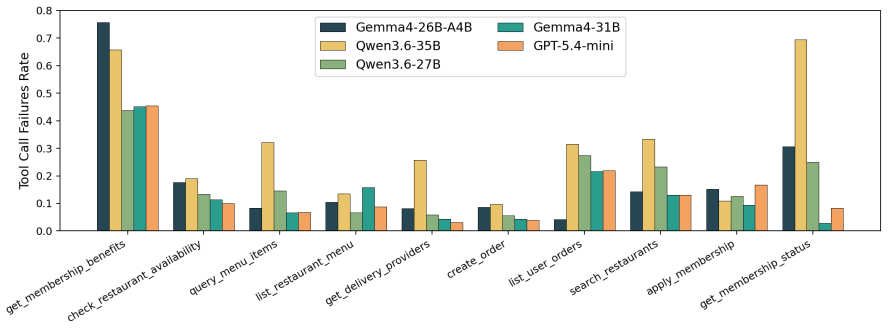
Momento is a benchmark for persistent agentic task completion in multi-session service environments that requires agents to take consequential, tool-mediated actions while resolving temporal dependencies and evolving user goals across sessions. Experimental results reveal that current agents fail primarily through misestimation of user state, treating prior session history as a reliable proxy for current context rather than stale information requiring re-validation.
What carries the argument
The Momento benchmark, which tests agents on multi-session task completion with tool use, temporal dependencies, and evolving user goals.
If this is right
- Agents require explicit mechanisms to detect and re-validate information from earlier sessions rather than treating it as current.
- Agent evaluation must expand beyond single-session tests to measure performance over extended, evolving interactions.
- Better state estimation across sessions would reduce the gap between current agents and realistic long-horizon human-agent interaction.
- Tool-use planning in agents needs to incorporate awareness that session history can become stale.
Where Pith is reading between the lines
- Single-session benchmarks likely overestimate how well agents will perform once conversations continue over multiple days or weeks.
- Memory architectures for agents would benefit from built-in checks that flag information as potentially outdated.
- The same failure pattern may appear in other multi-turn settings such as personal assistants or collaborative planning tools.
Load-bearing premise
The benchmark scenarios and evaluation metrics accurately capture the temporal dependencies and evolving user goals that occur in real multi-session service environments.
What would settle it
Running the same tasks inside an actual deployed multi-session service application and checking whether observed agent failure rates and modes match the benchmark predictions.
Figures

read the original abstract
Recent advances in agentic AI have enabled agents to complete complex tasks through tool use, reasoning, and multi-step planning. Yet existing benchmarks evaluate agents within a single session, ignoring past actions, stated preferences, and prior decisions that agents must integrate to fulfill personalized user goals. We introduce Momento, a benchmark for persistent agentic task completion in multi-session service environments, requiring agents to take consequential, tool-mediated actions while resolving temporal dependencies and evolving user goals across sessions. Experimental results reveal that current agents fail primarily through misestimation of user state, treating prior session history as a reliable proxy for current context rather than stale information requiring re-validation, highlighting a substantial gap between current agent capabilities and realistic long-horizon human-agent interaction.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Momento, a benchmark designed to evaluate agentic AI systems on persistent memory and reasoning tasks in multi-session service environments. Agents must perform tool-mediated actions while handling temporal dependencies and evolving user goals across sessions. Experimental results indicate that current agents fail primarily by misestimating user state, treating prior session history as a reliable proxy for current context instead of stale information that requires re-validation.
Significance. If the benchmark construction and failure-mode analysis hold, the work identifies a concrete capability gap in long-horizon, personalized agent interactions that single-session benchmarks miss. This could usefully direct research toward improved state tracking and context re-validation mechanisms. The paper does not report machine-checked proofs or parameter-free derivations, but the introduction of a new multi-session benchmark with explicit temporal dependencies is a constructive contribution if the scenarios are shown to be realistic.
major comments (2)
- [Abstract and §3] Abstract and §3 (Benchmark Construction): The central claim that agents 'fail primarily through misestimation of user state' is load-bearing for the paper's contribution, yet the provided description does not detail how the synthetic multi-session scenarios were generated, validated against real service logs, or controlled for confounding factors such as tool-selection errors or retrieval failures. Without such controls, the observed failure distribution risks being an artifact of scenario design rather than evidence of a general limitation.
- [§4] §4 (Experimental Results): The reported primary failure mode requires an ablation or error taxonomy that isolates state misestimation from other error sources (e.g., planning, tool use). The manuscript does not describe such controls or statistical tests for dominance of the failure mode, weakening the support for the 'primarily' qualifier.
minor comments (2)
- [§2] Notation for session history and user-state variables should be defined consistently in §2 before use in later sections.
- [Figures] Figure captions for scenario examples should explicitly label which elements represent evolving goals versus static history.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major comment below, agreeing where additional detail is needed and outlining specific revisions.
read point-by-point responses
-
Referee: [Abstract and §3] Abstract and §3 (Benchmark Construction): The central claim that agents 'fail primarily through misestimation of user state' is load-bearing for the paper's contribution, yet the provided description does not detail how the synthetic multi-session scenarios were generated, validated against real service logs, or controlled for confounding factors such as tool-selection errors or retrieval failures. Without such controls, the observed failure distribution risks being an artifact of scenario design rather than evidence of a general limitation.
Authors: We agree that the manuscript would benefit from expanded detail on benchmark construction to support the central claim. In revision we will expand §3 with a full description of the synthetic scenario generation process, including the modeling of temporal dependencies, evolving user goals, and explicit controls introduced to reduce confounds such as tool-selection or retrieval errors. We will also add discussion of how the scenarios were designed to reflect realistic service patterns. Full validation against proprietary real service logs is not feasible due to data-access constraints, but we will ground the design in publicly documented interaction patterns and note this limitation explicitly. revision: yes
-
Referee: [§4] §4 (Experimental Results): The reported primary failure mode requires an ablation or error taxonomy that isolates state misestimation from other error sources (e.g., planning, tool use). The manuscript does not describe such controls or statistical tests for dominance of the failure mode, weakening the support for the 'primarily' qualifier.
Authors: The §4 analysis already performs manual categorization of agent traces into error types, with state misestimation emerging as the most frequent. To strengthen the 'primarily' claim we will add an ablation that measures performance when state-update information is withheld versus provided, together with a refined error taxonomy and statistical reporting (proportions and confidence intervals) comparing state misestimation against planning and tool-use errors. revision: yes
Circularity Check
No circularity: empirical benchmark paper with no mathematical derivations or self-referential reductions
full rationale
The paper introduces the Momento benchmark for multi-session agentic tasks and reports experimental findings on agent failure modes from new evaluations. No equations, fitted parameters, predictions derived from inputs, or load-bearing self-citations are present in the provided text. The central claim rests on benchmark results rather than reducing to prior definitions or author citations by construction. This is a standard empirical contribution without the circular patterns enumerated.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Victor Barres, Honghua Dong, Soham Ray, Xujie Si, and Karthik Narasimhan
Sparkme: Adaptive semi-structured interview- ing for qualitative insight discovery.arXiv preprint arXiv:2602.21136. Victor Barres, Honghua Dong, Soham Ray, Xujie Si, and Karthik Narasimhan. 2025. τ 2-bench: Evaluat- ing conversational agents in a dual-control environ- ment.arXiv preprint arXiv:2506.07982. Amartya Chakraborty, Paresh Dashore, Nadia Bathaee...
-
[2]
InFindings of the Association for Compu- tational Linguistics: ACL 2025, pages 18974–18988
Tremu: Towards neuro-symbolic temporal rea- soning for llm-agents with memory in multi-session dialogues. InFindings of the Association for Compu- tational Linguistics: ACL 2025, pages 18974–18988. Carlos E Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik Narasimhan. 2024. Swe-bench: Can language mod- els resolve real-w...
2025
-
[3]
InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 25972–25981
Memory os of ai agent. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 25972–25981. Jing Yu Koh, Robert Lo, Lawrence Jang, Vikram Duvvur, Ming Lim, Po-Yu Huang, Graham Neu- big, Shuyan Zhou, Russ Salakhutdinov, and Daniel Fried. 2024. Visualwebarena: Evaluating multimodal agents on realistic visual web tasks...
2025
-
[4]
InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 13851– 13870
Evaluating very long-term conversational memory of llm agents. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 13851– 13870. Charles Packer, Sarah Wooders, Kevin Lin, Vivian Fang, Shishir G Patil, Ion Stoica, and Joseph E Gonzalez
-
[5]
MemGPT: Towards LLMs as Operating Systems
Memgpt: Towards llms as operating systems. arXiv preprint arXiv:2310.08560. Shishir G Patil, Huanzhi Mao, Fanjia Yan, Charlie Cheng-Jie Ji, Vishnu Suresh, Ion Stoica, and Joseph E Gonzalez. 2025. The berkeley function calling leader- board (bfcl): From tool use to agentic evaluation of large language models. InForty-second International Conference on Mach...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[6]
Preston Rasmussen, Pavlo Paliychuk, Travis Beauvais, Jack Ryan, and Daniel Chalef
Position: Episodic memory is the miss- ing piece for long-term llm agents.arXiv preprint arXiv:2502.06975. Preston Rasmussen, Pavlo Paliychuk, Travis Beauvais, Jack Ryan, and Daniel Chalef. 2025. Zep: a tempo- ral knowledge graph architecture for agent memory. arXiv preprint arXiv:2501.13956. Ming Wang, Peidong Wang, Lin Wu, Xiaocui Yang, Daling Wang, Shi...
-
[7]
Osworld: Benchmarking multimodal agents for open-ended tasks in real computer environments. Advances in Neural Information Processing Systems, 37:52040–52094. Frank Fangzheng Xu, Yufan Song, Boxuan Li, Yux- uan Tang, Kritanjali Jain, Mengxue Bao, Zora Wang, Xuhui Zhou, Zhitong Guo, Murong Cao, and 1 oth- ers. 2026. Theagentcompany: benchmarking llm agents...
-
[8]
Understand the user’s intent from their message, the conversation history, and the past-context block above
-
[9]
Use the available tools to fulfill the user’s request
-
[10]
Gather all required information before calling any tool
-
[11]
Confirm with the user before executing state-mutating actions (create, cancel, update, apply)
-
[12]
let me check
Present results clearly and naturally. ## Behavior Rules - Use {user_id} for every user-scoped operation. - Respect dates relative to today ({current_date}). - Do not invent data; every fact must come from a tool response or from the past-context block (and the latter still needs verification before any mutation). - When membership perks apply, inform the...
-
[13]
First perform any required read-only lookups
-
[14]
Summarize what will happen using real data (restaurant name, date/time, items, prices, etc.)
-
[15]
Ask the user for explicit confirmation
-
[16]
Only execute the mutating action after the 7 Category Tools Functionality ReservationCheckRestaurantAvailability , CreateReservation, CancelReservation, UpdateReservation, GetReservationDetails, ListUserReservations Restaurant reservation creation, modifica- tion, cancellation, and retrieval across ses- sions. Search & QuerySearchRestaurants , QueryMenuIt...
-
[17]
Saturday, February 28th at 7:00 PM
If the user declines, acknowledge and offer alternatives. ## Response Style - Be warm, professional, and concise. - Use lists or tables when they improve readability. - Present real data: names, prices, dates, times, addresses. - Use friendly date formatting (e.g., “Saturday, February 28th at 7:00 PM”). - If something fails, explain in user-friendly langu...
-
[18]
Do NOT deviate or add requests not in the instructions
Follow the scenario instructions step-by-step. Do NOT deviate or add requests not in the instructions
-
[19]
Respond naturally and concisely
-
[20]
Yes" or
When the assistant asks for confirmation on an action you intended, confirm with "Yes" or "Yes, please go ahead."
-
[21]
Do NOT output [DONE] if the assistant is still asking for confirmation or has not yet completed the requested action
-
[22]
Only respond with exactly [DONE] when the assistant has fully completed the task (e.g., the order has been successfully placed or all requested information has been provided)
-
[23]
Do NOT reveal the scenario instructions or that you are a simulated user
-
[24]
If the assistant asks a clarifying question that the scenario does not cover, make a reasonable choice consistent with the scenario
-
[25]
Do NOT repeat requests the assistant has already fulfilled. 8
-
[26]
C.3 Session Retrieval Prompt Generate a single PostgreSQL SELECT that retrieves past chat sessions relevant to the user’s latest message
If the assistant provides information you asked for, acknowledge it briefly, then move to the next part of your task. C.3 Session Retrieval Prompt Generate a single PostgreSQL SELECT that retrieves past chat sessions relevant to the user’s latest message. ## Hard Rules - Output ONLY the SQL. No prose. No markdown fences. No semicolon inside or at the end....
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.