Why LLMs Fail at Causal Discovery and How Interventional Agents Escape
Pith reviewed 2026-06-29 17:25 UTC · model grok-4.3
The pith
Large language models cannot distinguish causal graphs from observational data alone under standard training, requiring unbounded internal representations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Supervised fine-tuning, direct preference optimization, and in-context learning all produce predictors that cannot distinguish between causal graphs generating similar observational data, and any attempt to do so requires the model's internal representations to grow unboundedly, violating the very conditions under which these methods work. This limitation is formalized as a kernel obstruction theorem establishing that the failure is intrinsic to the learning paradigm, not any particular model or dataset. Agentic Causal Bayesian Optimization lets a frozen language model serve as an interventional oracle while an external Bayesian loop concentrates beliefs over candidate graphs, enabling prova
What carries the argument
The kernel obstruction theorem, which proves that standard training paradigms cannot separate observationally equivalent causal graphs without unbounded representations, together with Agentic Causal Bayesian Optimization that routes interventional queries outside the obstructed space.
If this is right
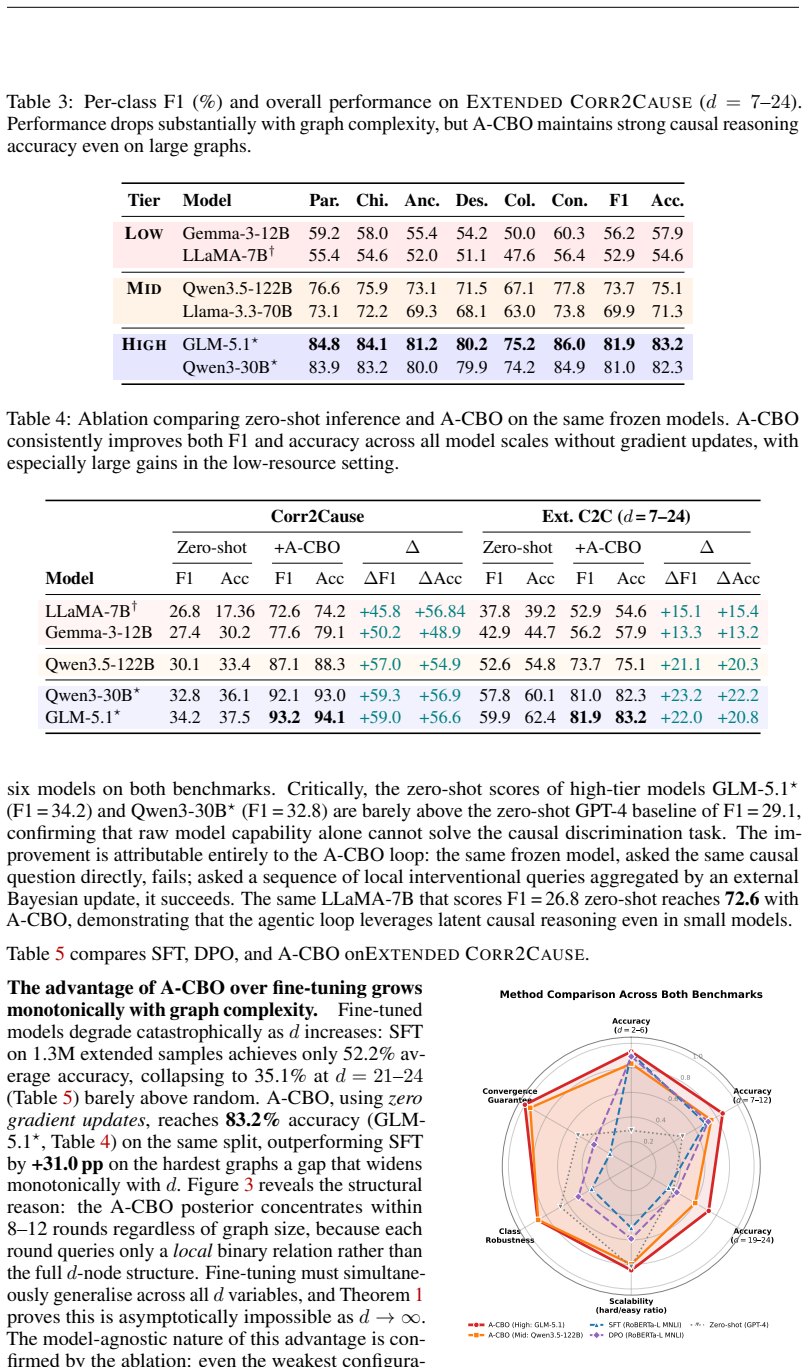
- A-CBO matches the performance of fine-tuned baselines on the Corr2Cause benchmark without any model training.
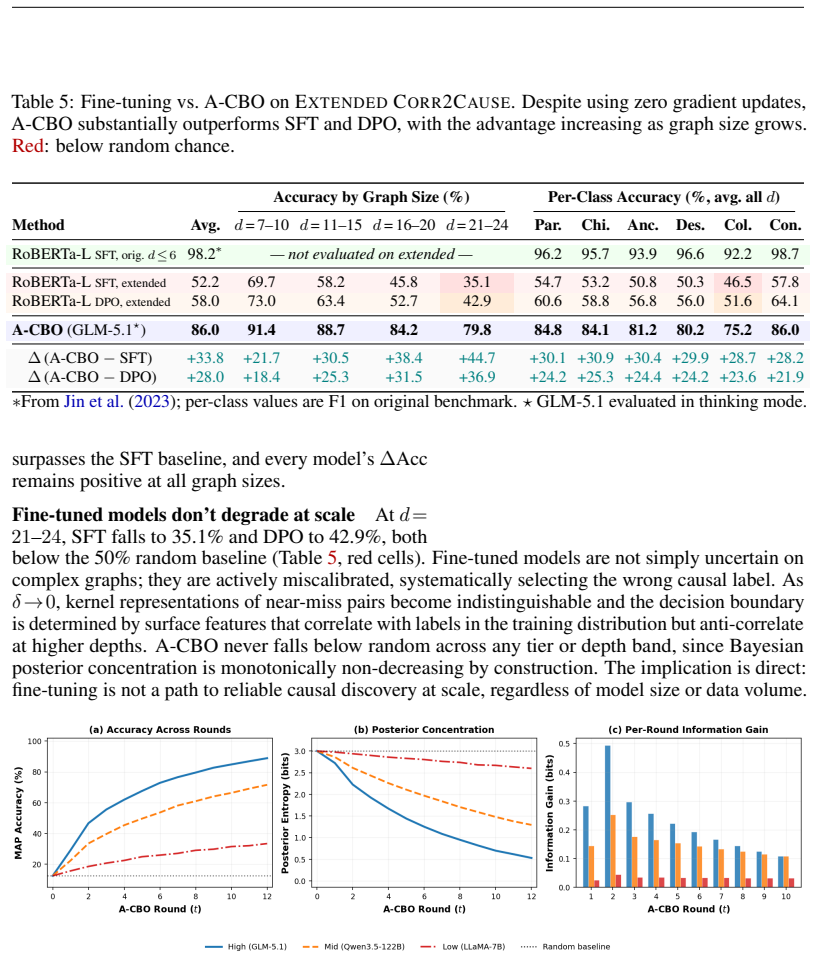
- On the Extended Corr2Cause benchmark with graphs up to 24 variables, A-CBO outperforms both fine-tuning and preference optimization, with the gap increasing as graph size grows.
- The external Bayesian loop requires only logarithmically many intervention queries to concentrate posterior mass on the correct graph.
- Because the language model remains frozen, the method avoids the representation-growth requirement that blocks direct training approaches.
Where Pith is reading between the lines
- The same separation of oracle queries from internal representations could be tested on other tasks that require distinguishing latent structures from surface correlations.
- Hybrid agentic systems might systematically outperform pure end-to-end training on any problem where observational data alone leaves multiple explanations equally likely.
- If the obstruction generalizes, it would predict similar plateaus for LLMs on other scientific reasoning benchmarks that rely on causal rather than correlational patterns.
Load-bearing premise
The kernel obstruction holds for the learning paradigm itself regardless of any particular model architecture or training dataset.
What would settle it
Training an LLM via supervised fine-tuning or preference optimization that correctly distinguishes causal graphs with identical observational distributions while keeping its internal representation dimension bounded would falsify the obstruction claim.
Figures


read the original abstract
Causal discovery is a cornerstone of scientific reasoning, yet whether large language models can perform it reliably remains an open question. Recent benchmarks show that even fine-tuned models plateau on simple causal graphs and degrade as complexity grows, but why they fail has not been established. We prove the failure is fundamental: supervised fine-tuning, direct preference optimization, and in-context learning all produce predictors that cannot distinguish between causal graphs generating similar observational data, and any attempt to do so requires the model's internal representations to grow unboundedly, violating the very conditions under which these methods work. We formalize this as a kernel obstruction theorem, establishing that the limitation is intrinsic to the learning paradigm, \emph{not any particular model or dataset}. We propose Agentic Causal Bayesian Optimization (A-CBO), wherein a frozen language model serves as an interventional oracle answering targeted queries about intervention effects, while an external Bayesian loop concentrates beliefs over candidate graphs in logarithmically many rounds. Because the decision operates outside the space where the obstruction applies, A-CBO provably converges while the underlying model remains unchanged. On Corr2Cause, A-CBO matches fine-tuned baselines without any training. On Extended Corr2Cause, a new benchmark scaling to 24 variables with 18K test samples, A-CBO significantly outperforms both fine-tuning and preference optimization, with the advantage growing
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that supervised fine-tuning, DPO, and in-context learning cannot distinguish causal graphs that produce similar observational distributions, formalized via a kernel obstruction theorem that requires internal representations to grow unboundedly; this limitation is intrinsic to the learning paradigm. It introduces Agentic Causal Bayesian Optimization (A-CBO), which keeps the LLM frozen as an interventional oracle and uses an external Bayesian loop to converge on graphs in logarithmically many rounds. Empirical results are reported on Corr2Cause (matching fine-tuned baselines) and a new Extended Corr2Cause benchmark (24 variables, 18K samples) where A-CBO outperforms fine-tuning and preference optimization, with the gap increasing with complexity.
Significance. If the kernel obstruction theorem holds and the reduction from LLM training to kernel predictors is valid, the result would be significant: it supplies a theoretical account for observed plateaus in causal discovery benchmarks and demonstrates a practical way to escape the limitation without retraining. The agentic separation of the decision process from the model's internal representations is a clean architectural contribution. Reproducible code or machine-checked elements are not mentioned.
major comments (3)
- The kernel obstruction theorem is the load-bearing claim, yet the provided manuscript text asserts a mathematical proof without any derivation, equations, proof sketch, or formal statement of the kernel or the reduction from SFT/DPO/ICL predictors to RKHS methods. This prevents verification of whether the argument applies to adaptive parametric models whose feature maps are updated by gradient descent rather than fixed kernels.
- The central claim that the obstruction is independent of any particular model or dataset rests on the theorem; without the explicit reduction showing why gradient updates on transformer weights cannot induce separating representations within bounded dimension, the conclusion that all three paradigms are affected does not follow.
- Empirical claims on Extended Corr2Cause (outperformance growing with complexity) are stated without methods, baselines, error bars, or statistical tests, so it is impossible to assess whether the results support the claim that A-CBO escapes the obstruction while fine-tuning does not.
minor comments (2)
- The abstract and introduction should explicitly state the section containing the theorem statement and proof.
- Notation for the interventional oracle and the Bayesian update loop in A-CBO should be introduced with a small example before the convergence argument.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on the kernel obstruction theorem and empirical presentation. We address each major point below and will revise the manuscript accordingly to improve clarity and completeness.
read point-by-point responses
-
Referee: The kernel obstruction theorem is the load-bearing claim, yet the provided manuscript text asserts a mathematical proof without any derivation, equations, proof sketch, or formal statement of the kernel or the reduction from SFT/DPO/ICL predictors to RKHS methods. This prevents verification of whether the argument applies to adaptive parametric models whose feature maps are updated by gradient descent rather than fixed kernels.
Authors: We agree that the current version presents the theorem at a high level. In revision we will insert the formal statement of the kernel obstruction theorem, the explicit RKHS reduction from SFT/DPO/ICL predictors, the definition of the relevant kernel, and a complete proof sketch. The expanded argument will directly address adaptive parametric models by showing that any finite-dimensional feature map inducible by gradient descent on transformer weights remains subject to the same separation obstruction. revision: yes
-
Referee: The central claim that the obstruction is independent of any particular model or dataset rests on the theorem; without the explicit reduction showing why gradient updates on transformer weights cannot induce separating representations within bounded dimension, the conclusion that all three paradigms are affected does not follow.
Authors: The independence claim is derived from the reduction itself: any predictor obtained by SFT, DPO, or ICL is shown to be equivalent to a kernel predictor whose feature dimension is bounded by the training regime, precluding the unbounded growth required to separate observationally equivalent graphs. The revised proof will spell out why gradient updates on transformer parameters cannot escape this bound without leaving the paradigm. We will also add a short corollary clarifying applicability to all three methods. revision: yes
-
Referee: Empirical claims on Extended Corr2Cause (outperformance growing with complexity) are stated without methods, baselines, error bars, or statistical tests, so it is impossible to assess whether the results support the claim that A-CBO escapes the obstruction while fine-tuning does not.
Authors: We will expand the experimental section to include the precise construction of Extended Corr2Cause, the full list of baselines with implementation details, error bars computed over multiple random seeds, and the results of statistical significance tests. These elements are present in the supplementary material; the main text will be updated to foreground them so that the performance gap with increasing graph size can be properly evaluated. revision: yes
Circularity Check
No circularity: kernel obstruction theorem and A-CBO are presented as independent formal results
full rationale
The paper introduces a new kernel obstruction theorem to formalize why SFT/DPO/ICL cannot distinguish causal graphs with identical observational distributions, requiring unbounded representations. It then proposes A-CBO as an external Bayesian procedure using the frozen LLM only as an interventional oracle. No load-bearing step reduces by construction to fitted parameters renamed as predictions, self-citations, or ansatzes imported from prior author work. The central claim is framed as a mathematical limitation intrinsic to the paradigm, with convergence of A-CBO shown separately; the derivation chain remains self-contained and does not rely on re-labeling known empirical patterns or self-referential definitions.
Axiom & Free-Parameter Ledger
axioms (1)
- ad hoc to paper Kernel obstruction theorem applies to supervised fine-tuning, DPO, and in-context learning for causal discovery tasks
invented entities (1)
-
A-CBO (Agentic Causal Bayesian Optimization)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Abdulaal, hadjivasiliou, N
A. Abdulaal, hadjivasiliou, N. Montana-Brown, T. He, A. Ijishakin, I. Drobnjak, D. C. Castro, and D. C. Alexander Causal Modelling Agents: Causal Graph Discovery through Synergising Metadata- and Data-driven Reasoning. In The Twelfth International Conference on Learning Representations , 2024. URL https://openreview.net/forum?id=pAoqRlTBtY
2024
-
[2]
Agrawal, C
R. Agrawal, C. Squires, K. Yang, K. Shanmugam, and C. Uhler ABCD -Strategy: Budgeted experimental design for targeted causal structure discovery. In Proceedings of the 22nd International Conference on Artificial Intelligence and Statistics , pages 3400--3409, 2019
2019
-
[3]
H. Chi, H. Li, W. Yang, F. Liu, L. Lan, X. Ren, T. Liu, and B. Han Unveiling causal reasoning in large language models: Reality or mirage?. Advances in Neural Information Processing Systems , 37:96640--96670, 2024
2024
-
[4]
Ghorbani, S
B. Ghorbani, S. Mei, T. Misiakiewicz, and A. Montanari Limitations of lazy training of two-layers neural network. Advances in Neural Information Processing Systems , 32, 2019
2019
-
[5]
T. Gupta, W. Gong, C. Ma, N. Pawlowski, A. Hilmkil, M. Scetbon, M. Rigter, A. Famoti, A. J. Llorens, J. Gao, and others The essential role of causality in foundation world models for embodied AI. arXiv preprint arXiv:2402.06665 , 2024
- [6]
-
[7]
Jacot, F
A. Jacot, F. Gabriel, and C. Hongler Neural tangent kernel: Convergence and generalization in neural networks. Advances in neural information processing systems , 31, 2018
2018
- [8]
-
[9]
Z. Jin, Y. Chen, F. Leber, L. Gresele, O. Kamath, B. Xin, Z. Shi, B. Scholkopf, L. Bottou, and R. Mihalcea Cladder: A benchmark to assess causal reasoning capabilities of language models. In Advances in Neural Information Processing Systems , 2024
2024
-
[10]
K. Kadziolka and S. Salehkaleybar Causal Reasoning in Pieces: Modular In-Context Learning for Causal Discovery. arXiv preprint arXiv:2507.23488 , 2025
-
[11]
Karkada The Lazy ( NTK ) and Rich ( P ) Regimes: A Gentle Tutorial
D. Karkada The Lazy ( NTK ) and Rich ( P ) Regimes: A Gentle Tutorial. arXiv preprint arXiv:2404.19719 , 2024
-
[12]
H. D. Le, X. Xia, and Z. Chen Multi-agent causal discovery using large language models. arXiv preprint arXiv:2407.15073 , 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [13]
- [14]
- [15]
-
[16]
N. Scherrer, O. Bilaniuk, Y. Annadani, A. Goyal, P. Schwab, B. Sch \"o lkopf, M. C. Mozer, Y. Bengio, S. Bauer, and N. R. Ke Learning neural causal models with active interventions. arXiv preprint arXiv:2109.02429 , 2021
-
[17]
B. Sch \"o lkopf, F. Locatello, S. Bauer, N. R. Ke, N. Kalchbrenner, A. Goyal, and Y. Bengio Toward Causal Representation Learning. Proceedings of the IEEE , 109(5):612--634, 2021. doi:10.1109/JPROC.2021.3058954
-
[18]
E. Sgouritsa, V. Aglietti, Y. W. Teh, A. Doucet, A. Gretton, and S. Chiappa Prompting strategies for enabling large language models to infer causation from correlation. arXiv preprint arXiv:2412.13952 , 2024
-
[19]
Sheth, B
I. Sheth, B. Fatemi, and M. Fritz Causalgraph2llm: Evaluating llms for causal queries. In Findings of the Association for Computational Linguistics: NAACL 2025 , pages 2076--2098, 2025
2025
- [20]
- [21]
- [22]
- [23]
- [24]
-
[25]
Ze c evi \'c , M
M. Ze c evi \'c , M. Willig, D. S. Dhami, and K. Kersting Causal Parrots: Large Language Models May Talk Causality But Are Not Causal. Transactions on Machine Learning Research , 2023
2023
- [26]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.