IFMTBench: A Comprehensive Benchmark for Multilingual Translation Instruction Following
Pith reviewed 2026-06-29 12:29 UTC · model grok-4.3
The pith
A new benchmark for multilingual translation instruction following reveals that constraint adherence scales more sharply with model size than semantic quality does and correlates only weakly with general instruction-following rankings.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
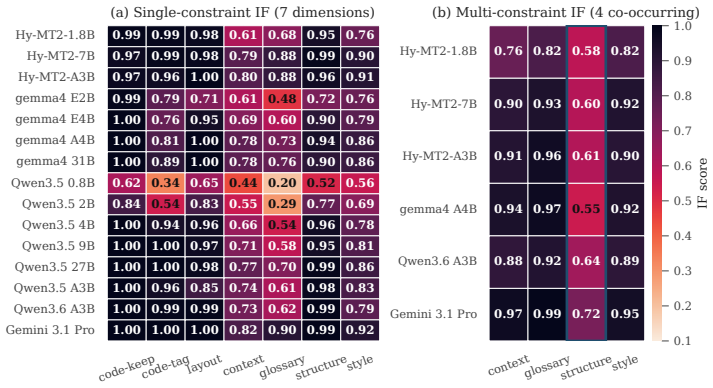
The benchmark reveals systematic gaps missed by prior protocols: instruction following scales with size more sharply than translation quality, glossary and structured-format constraints dominate the difficulty gradient, and general instruction following rankings correlate only weakly with translation behavior.
What carries the argument
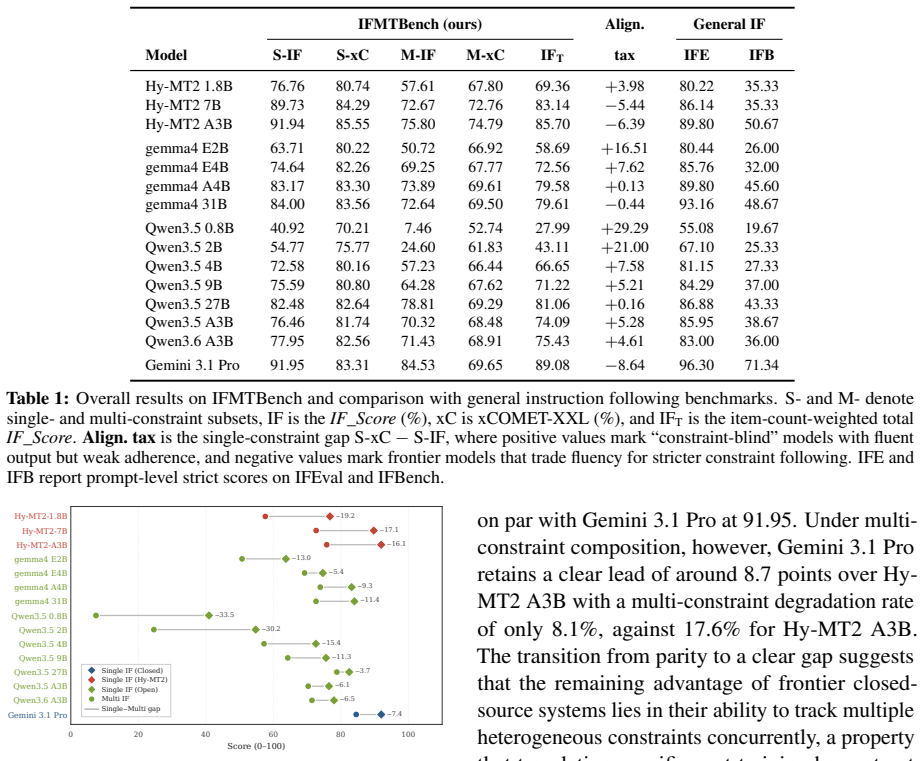
IFMTBench, a collection of 4,506 single-constraint and 2,838 multi-constraint items spanning six constraint dimensions and five compositional patterns, with instructions in all seven languages, scored by deterministic checkers on a gating subset and rubric-based LLM judge on a continuous subset under a multiplicative rule.
If this is right
- Larger models will continue to show outsized gains on multi-constraint translation tasks relative to smaller models.
- Glossary and structured-format constraints will remain the primary bottlenecks even as overall capability increases.
- General instruction-following benchmarks will continue to give misleading signals about performance on translation-specific constraints.
- Multi-constraint items will expose failures that single-constraint items miss.
- Performance will vary with the language in which the instruction is given relative to the translation target.
Where Pith is reading between the lines
- Training objectives that explicitly optimize for simultaneous satisfaction of glossary and format rules may close the observed gaps faster than scale alone.
- The multiplicative scoring rule will penalize any single violation more harshly than additive alternatives, potentially changing which models appear strongest.
- Extending the same constraint dimensions to additional language pairs could test whether the difficulty gradient generalizes beyond the seven languages tested.
Load-bearing premise
The assumption that deterministic checkers combined with a rubric-based LLM judge under a multiplicative scoring rule accurately and unbiasedly measure constraint adherence across the described constraint dimensions.
What would settle it
Human raters scoring the same model outputs on the identical constraints produce a different model ranking or difficulty ordering than the automated scores.
Figures



read the original abstract
Modern translation workflows demand more than semantic equivalence. Users routinely require models to preserve JSON or HTML schemas, honor curated glossaries, disambiguate with provided context, and match prescribed registers, often several at once. Conventional metrics such as BLEU and xCOMET capture semantic fidelity but provide little signal on constraint adherence, while general instruction following benchmarks ignore the cross-lingual nature of translation. We introduce \bench, a benchmark for multilingual translation instruction following covering seven languages, with 4,506 single-constraint and 2,838 multi-constraint items spanning six constraint dimensions and five compositional patterns with instructions issued in all seven languages. Constraints are split into a gating subset verified by deterministic checkers and a continuous subset scored by a rubric-based LLM judge, combined under a multiplicative rule that resists reward hacking. Evaluating 15 models reveals systematic gaps that prior protocols miss: Instruction following scales with size more sharply than translation quality, glossary and structured-format constraints dominate the difficulty gradient, and general instruction following rankings correlate only weakly with translation behavior. Our benchmark are available at https://github.com/Tencent-Hunyuan/Hy-MT2/tree/main/IFMTBench.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces IFMTBench, a benchmark for multilingual translation instruction following across seven languages. It comprises 4,506 single-constraint and 2,838 multi-constraint items spanning six constraint dimensions and five compositional patterns, with instructions in all seven languages. Constraints are partitioned into a gating subset verified by deterministic checkers and a continuous subset scored by a rubric-based LLM judge; scores are combined multiplicatively. Evaluation of 15 models is reported to reveal that instruction following scales more sharply with model size than translation quality, that glossary and structured-format constraints dominate difficulty, and that general instruction-following rankings correlate only weakly with translation-specific behavior.
Significance. If the LLM-judge component is shown to be reliable, the benchmark would address a genuine gap between conventional MT metrics (BLEU, xCOMET) and real-world translation workflows that impose simultaneous schema, glossary, context, and register constraints. The reported weak correlation between general IF rankings and translation behavior would be a useful empirical observation for the field.
major comments (2)
- [Evaluation / Methods] The central claims about sharper size scaling for instruction following, glossary/structured-format dominance, and weak correlation with general IF benchmarks all rest on the composite scores produced by the multiplicative rule. No inter-annotator agreement, human-LLM correlation, or judge-model details are reported for the rubric-based LLM judge across the seven languages (Evaluation / Methods section). Without such validation, systematic bias in the continuous subset could artifactually produce the reported difficulty gradients and model orderings.
- [Experiments] The manuscript states that 15 models were evaluated but supplies no information on model selection criteria, exact prompting templates, decoding parameters, or whether the same prompt format was used for all constraint types and languages. These details are required to interpret the scaling and correlation results.
minor comments (1)
- [Abstract] Abstract contains a subject-verb agreement error: "Our benchmark are available" should read "Our benchmark is available" (or "benchmarks are").
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major point below and indicate the revisions that will be made to the manuscript.
read point-by-point responses
-
Referee: [Evaluation / Methods] The central claims about sharper size scaling for instruction following, glossary/structured-format dominance, and weak correlation with general IF benchmarks all rest on the composite scores produced by the multiplicative rule. No inter-annotator agreement, human-LLM correlation, or judge-model details are reported for the rubric-based LLM judge across the seven languages (Evaluation / Methods section). Without such validation, systematic bias in the continuous subset could artifactually produce the reported difficulty gradients and model orderings.
Authors: We agree that the LLM judge requires more documentation. The revised manuscript will specify the exact judge model, provide the full rubric, and include the prompting template used for scoring the continuous subset. We will also add a brief discussion of the multiplicative combination rule and its intended robustness against isolated judge errors. A comprehensive human-LLM correlation study across all languages and items was not conducted in the original work; we will note this as a limitation and indicate that the deterministic gating subset provides an independent check on a substantial portion of the data. revision: partial
-
Referee: [Experiments] The manuscript states that 15 models were evaluated but supplies no information on model selection criteria, exact prompting templates, decoding parameters, or whether the same prompt format was used for all constraint types and languages. These details are required to interpret the scaling and correlation results.
Authors: We acknowledge that these implementation details were omitted. The revised manuscript will add a dedicated subsection (or appendix) listing the 15 models and the criteria used for their selection, the exact prompt templates applied to single-constraint and multi-constraint items, the decoding parameters (temperature, top-p, etc.), and explicit confirmation that the same prompt structure was used across all languages and constraint types. revision: yes
Circularity Check
No significant circularity in benchmark construction or evaluation
full rationale
The paper introduces IFMTBench as an independent evaluation resource with explicitly defined constraint dimensions, deterministic gating checkers, and a separate rubric-based LLM judge under a multiplicative rule. Model evaluations and reported gradients (size scaling, constraint difficulty, weak correlation with general IF) are direct empirical outputs from applying these fixed procedures to 15 external models across 7 languages. No parameter is fitted to the evaluation results and then re-used as a 'prediction'; no uniqueness theorem or ansatz is imported via self-citation; no renaming of known results occurs. The derivation chain consists solely of benchmark definition followed by independent measurement, making the findings self-contained against external model outputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Rubric-based LLM judge provides consistent and accurate scores for continuous constraint adherence
Reference graph
Works this paper leans on
-
[1]
Gemini: A Family of Highly Capable Multimodal Models
Gemini: A family of highly capable multimodal models.arXiv preprint arXiv:2312.11805. Nuno M Guerreiro, Ricardo Rei, Daan van Stigt, Luísa Coheur, Pierre Colombo, and André F T Mar- tins
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
MultiIF: Benchmarking LLMs on multi- turn and multilingual instructions following.arXiv preprint arXiv:2410.15553. Yuxin Jiang, Yufei Wang, Xingshan Zeng, Wanjun Zhong, Liangyou Li, Fei Mi, Lifeng Shang, Xin Jiang, Qun Liu, and Wei Wang
-
[3]
InProceedings of the Eighth Conference on Machine Translation (WMT)
Findings of the 2023 conference on machine translation (WMT23): LLMs are here but not quite there yet. InProceedings of the Eighth Conference on Machine Translation (WMT). Tom Kocmi and Christian Federmann
2023
-
[4]
The Llama 3 herd of models.arXiv preprint arXiv:2407.21783. Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, and 1 others
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
Generalizing Verifiable Instruction Following
Generalizing verifiable instruction following.arXiv preprint arXiv:2507.02833. Yiwei Qin, Kaiqiang Song, Yebowen Hu, Wenlin Yao, Sangwoo Cho, Xiaoyang Wang, Xuansheng Wu, Fei Liu, Pengfei Liu, and Dong Yu
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
InFoBench: Evaluating instruction following ability in large lan- guage models.arXiv preprint arXiv:2401.03601. Rafael Rafailov, Archit Sharma, Eric Mitchell, Stefano Ermon, Christopher D Manning, and Chelsea Finn
-
[7]
InProceedings of the 2020 Conference on Empirical Methods in Natural Language Process- ing (EMNLP), pages 2685–2702
COMET: A neural framework for MT evaluation. InProceedings of the 2020 Conference on Empirical Methods in Natural Language Process- ing (EMNLP), pages 2685–2702. Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, Y K Li, Y Wu, and Daya Guo
2020
-
[8]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
DeepSeekMath: Pushing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300. An Yang and 1 others
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
Qwen3 technical report. arXiv preprint arXiv:2505.09388. Mao Zheng, Zheng Li, Tao Chen, Bo Lv, Mingrui Sun, Mingyang Song, Jinlong Song, Hong Huang, Decheng Wu, Hai Wang, Yifan Song, Yanfeng Chen, and Guanwei Zhang
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
Hy-MT2: A Family of Fast, Efficient and Powerful Multilingual Translation Models in the Wild
Hy-mt2: A family of fast, efficient and powerful multilingual translation models in the wild.Preprint, arXiv:2605.22064. Jeffrey Zhou, Tianjian Lu, Swaroop Mishra, Sid- dhartha Brahma, Sujoy Basu, Yi Luan, Denny Zhou, and Le Hou
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
Instruction-Following Evaluation for Large Language Models
Instruction-following evalu- ation for large language models.arXiv preprint arXiv:2311.07911. A LLM Judge Prompt Templates This appendix provides the full prompt templates used in our hybrid evaluation framework (Sec- tion 5). We include both the glossary fallback judge prompt (Section A.1) and the style/background rubric judge prompt (Section A.2). A.1 G...
work page internal anchor Pith review Pith/arXiv arXiv
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.