Philosophical Dispositions as Behavioral Constraints for AI-Assisted Code Review: An Empirical Study
Pith reviewed 2026-05-25 05:05 UTC · model grok-4.3
The pith
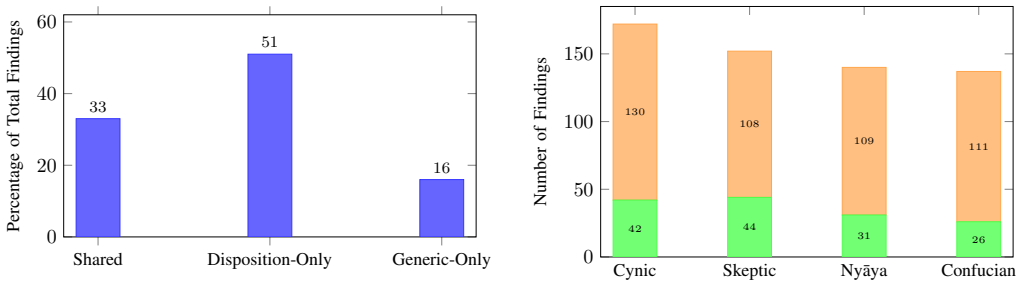
Philosophical dispositions constrain AI code reviewers to produce 51% more unique findings than generic prompting.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Constraining an AI reviewer through apophatically defined philosophical dispositions produces behavioral differences that yield structurally distinct findings at rates substantially higher than those obtained from generic expert-reviewer prompting, while still converging with human judgments at 46%.
What carries the argument
Philosophical dispositions defined apophatically by what they refuse to examine, each equipped with a self-monitoring hamartia and orchestrated by role protocols.
If this is right
- AI code review outputs can be diversified by selecting different epistemological lenses rather than varying prompt wording alone.
- 51% of the disposition-derived findings target structural, operational, and logical concerns instead of standard code-level issues.
- The framework maintains 100% structural adherence across two models while allowing model-specific analytical differences at the finding level.
Where Pith is reading between the lines
- The same disposition structure could be tested on other software-engineering tasks such as test generation or architecture review.
- If the dispositions prove stable across languages and organizations, organizations could maintain a small set of reusable reviewer personas instead of writing new prompts for each review type.
Load-bearing premise
The author's sole judgment is sufficient to establish that none of the 601 findings are false positives.
What would settle it
Independent multi-rater assessment of the 601 findings for false-positive rates.
Figures

read the original abstract
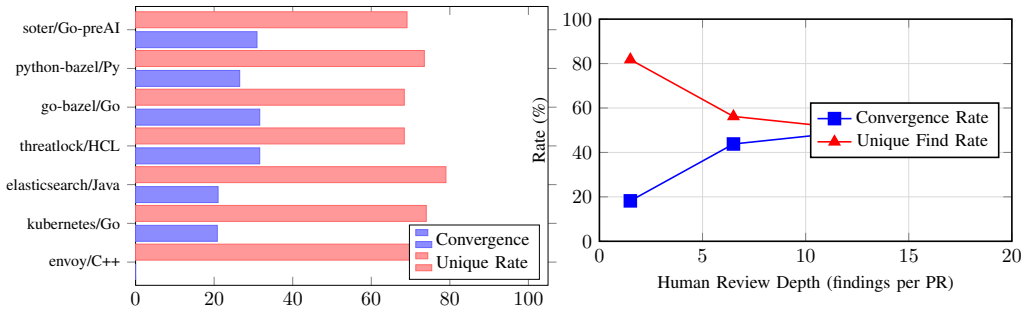
AI-assisted code review tools typically operate as generic "expert reviewer" agents, producing homogeneous findings regardless of the analysis type needed. We present a system that constrains AI reviewer behavior through philosophical dispositions -- coherent personality lenses grounded in specific epistemological traditions (Pyrrhonist Skepticism, Navya-Ny=aya logic, Diogenes' Cynicism, Confucian relational ethics) that direct attention to structurally different types of issues. Each disposition is defined apophatically (by what it refuses to do), equipped with a self-monitoring failure mode (hamartia), and orchestrated in sequence by role protocols. We evaluate this system on 50 merged pull requests across 7 repositories spanning 5 programming languages (Python, Go, C++, Java, Terraform), 5 organizations (2 enterprise, 3 open-source), and 2 temporal eras (pre-AI 2020, post-AI 2024--2026). The disposition system achieves 46% convergence with human reviewers (validating signal quality), identifies unique findings at a 75% rate, and produces no findings judged false-positive by the author across 601 total findings (inter-rater agreement was not assessed and remains a limitation). A controlled baseline comparison demonstrates that 51% of disposition findings are not produced by the same model using generic "expert reviewer" prompting, and these unique findings target structural, operational, and logical concerns rather than standard code-level issues. Preliminary cross-model validation (Claude Opus vs.\ GPT Codex 5.3-xhigh) on 3 PRs shows 100% framework-structure adherence with 39% finding-level agreement, suggesting the framework provides real behavioral constraint while preserving model-specific analytical perspective.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes constraining AI code review agents via four philosophical dispositions (Pyrrhonist Skepticism, Navya-Nyaya logic, Diogenes' Cynicism, Confucian relational ethics), each defined apophatically with a hamartia self-monitoring failure mode and orchestrated by role protocols. It evaluates the system on 50 merged PRs across 7 repositories, 5 languages, 5 organizations, and 2 eras, reporting 46% convergence with human reviewers, 75% unique findings, zero author-judged false positives across 601 findings, and 51% of findings not reproduced by the same model under generic expert-reviewer prompting. A preliminary cross-model check (Claude Opus vs. GPT Codex 5.3-xhigh) on 3 PRs shows 100% framework adherence but 39% finding-level agreement.
Significance. If the empirical claims survive stronger validation, the work supplies a concrete, reproducible method for injecting behavioral diversity into LLM-based code review that goes beyond prompt engineering. The multi-language, multi-organization, pre-/post-AI dataset and the controlled baseline comparison constitute a useful empirical anchor for future studies of constrained AI reviewers. The explicit acknowledgment of the inter-rater limitation is a point of intellectual honesty.
major comments (2)
- [Abstract / Evaluation section] Abstract and the evaluation description: the headline claim of zero false positives across 601 findings rests exclusively on single-author judgment. The manuscript itself states that inter-rater agreement was not assessed; because relevance, severity, and actionability of code-review findings are inherently subjective, this single-rater metric is load-bearing for the quality and uniqueness assertions yet lacks the reliability check the paper acknowledges as missing.
- [Baseline comparison] Baseline comparison paragraph: the claim that 51% of disposition findings are not produced by generic expert prompting requires explicit confirmation that the baseline prompt was matched for length, iteration count, temperature, and output format. Without those controls, the uniqueness result could be an artifact of prompt engineering differences rather than the philosophical dispositions themselves.
minor comments (2)
- [Abstract] Abstract contains an apparent typographical error: 'Navya-Ny=aya' should read 'Navya-Nyaya'.
- [Cross-model validation] The cross-model validation is reported only on 3 PRs; expanding or clarifying the selection criteria for those PRs would strengthen the preliminary result.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and for recognizing the empirical contributions of the work. We address each major comment below with clarifications and planned revisions.
read point-by-point responses
-
Referee: [Abstract / Evaluation section] Abstract and the evaluation description: the headline claim of zero false positives across 601 findings rests exclusively on single-author judgment. The manuscript itself states that inter-rater agreement was not assessed; because relevance, severity, and actionability of code-review findings are inherently subjective, this single-rater metric is load-bearing for the quality and uniqueness assertions yet lacks the reliability check the paper acknowledges as missing.
Authors: We agree that single-author judgment for false-positive assessment constitutes a genuine limitation, as the manuscript already states. The lead author performed the judgments drawing on direct familiarity with the repositories and PR context, but we recognize the inherent subjectivity of relevance and actionability. In revision we will expand the abstract and evaluation section to foreground this limitation more explicitly, add a brief rationale for the single-rater design (resource constraints of the multi-repository study), and strengthen the discussion of implications for the uniqueness and quality claims. This constitutes a partial revision because the core acknowledgment is already present. revision: partial
-
Referee: [Baseline comparison] Baseline comparison paragraph: the claim that 51% of disposition findings are not produced by generic expert prompting requires explicit confirmation that the baseline prompt was matched for length, iteration count, temperature, and output format. Without those controls, the uniqueness result could be an artifact of prompt engineering differences rather than the philosophical dispositions themselves.
Authors: The baseline prompt was constructed using the identical model, temperature setting, single-pass iteration count, and output format as the disposition runs; prompt length was kept comparable by substituting a concise generic expert-reviewer instruction for the disposition-specific text. To eliminate any ambiguity we will revise the methods and baseline-comparison sections to include the exact baseline prompt and an explicit statement confirming the matched parameters. This change directly addresses the concern and strengthens the attribution of uniqueness to the philosophical constraints. revision: yes
Circularity Check
No circularity: empirical metrics derived from direct evaluation against external baselines
full rationale
The paper reports an empirical study evaluating the disposition system on 50 pull requests, with results (46% human convergence, 75% unique findings, 51% not reproduced by generic prompting, zero author-judged false positives) obtained by direct comparison to human reviewers and a controlled generic-prompt baseline. These quantities are measured outputs of the evaluation protocol rather than quantities fitted to data and then re-predicted, self-defined, or justified via self-citation chains. No equations, ansatzes, uniqueness theorems, or renamings appear; the central claims rest on observable differences between the disposition framework and the external baseline.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Philosophical traditions can be coherently mapped to distinct behavioral constraints and failure modes for AI code review.
invented entities (1)
-
Philosophical dispositions (Pyrrhonist Skepticism, Navya-Nyaya logic, Diogenes' Cynicism, Confucian relational ethics) with hamartia
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Constitutional AI: Harmlessness from AI Feedback
Y . Bai et al., “Constitutional AI: Harmlessness from AI Feedback,” arXiv:2212.08073, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[2]
CodeReviewer: Pre-Training for Automating Code Review Activities,
L. Li, Z. Li, et al., “CodeReviewer: Pre-Training for Automating Code Review Activities,” inProc. ACM ESEC/FSE, 2022, pp. 38–50
work page 2022
-
[3]
Vallor,Technology and the Virtues: A Philosophical Guide to a Future Worth Wanting
S. Vallor,Technology and the Virtues: A Philosophical Guide to a Future Worth Wanting. Oxford University Press, 2016
work page 2016
-
[4]
Pramana: Fine-Tuning Large Language Models for Epistemic Reasoning through Navya-Nyaya
S. Sathish, “Pramana: Fine-Tuning Large Language Models for Epis- temic Reasoning through Navya-Ny ¯aya,”arXiv:2604.04937, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
- [5]
-
[6]
AutoGen: Enabling Next-Gen LLM Applications via Multi-Agent Conversation
Q. Wu et al., “AutoGen: Enabling Next-Gen LLM Applications via Multi-Agent Conversation,”arXiv:2308.08155, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[7]
MetaGPT: Meta Programming for A Multi-Agent Collaborative Framework
S. Hong et al., “MetaGPT: Meta Programming for a Multi-Agent Collaborative Framework,”arXiv:2308.00352, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[8]
T. Hagendorff, “The Ethics of AI Ethics,”Minds and Machines, vol. 32, pp. 681–706, 2022
work page 2022
-
[9]
GitHub, “GitHub Copilot Code Review,”GitHub Blog, 2024. [On- line]. Available: https://github.blog/changelog/2024-10-29-copilot-code- review-in-github-com-public-preview/
work page 2024
-
[10]
MacIntyre,After Virtue: A Study in Moral Theory
A. MacIntyre,After Virtue: A Study in Moral Theory. University of Notre Dame Press, 1981
work page 1981
-
[11]
Hadot,Philosophy as a Way of Life
P. Hadot,Philosophy as a Way of Life. Blackwell, 1995
work page 1995
-
[12]
Turner,Faith, Reason and the Existence of God
D. Turner,Faith, Reason and the Existence of God. Cambridge Univer- sity Press, 2004
work page 2004
-
[13]
Discovering Language Model Behaviors with Model-Written Evaluations
E. Perez et al., “Discovering Language Model Behaviors with Model- Written Evaluations,”arXiv:2212.09251, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[14]
LLM Critics Help Catch LLM Bugs,
N. McAleese et al., “LLM Critics Help Catch LLM Bugs,” arXiv:2407.00215, 2024
-
[15]
Inter-Coder Agreement for Computational Linguistics,
R. Artstein and M. Poesio, “Inter-Coder Agreement for Computational Linguistics,”Computational Linguistics, vol. 34, no. 4, pp. 555–596, 2008
work page 2008
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.