VIA-SD: Verification via Intra-Model Routing for Speculative Decoding
Pith reviewed 2026-06-27 09:36 UTC · model grok-4.3
The pith
A slim submodel routed from the full verifier can correctly accept many draft tokens rejected in standard speculative decoding.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
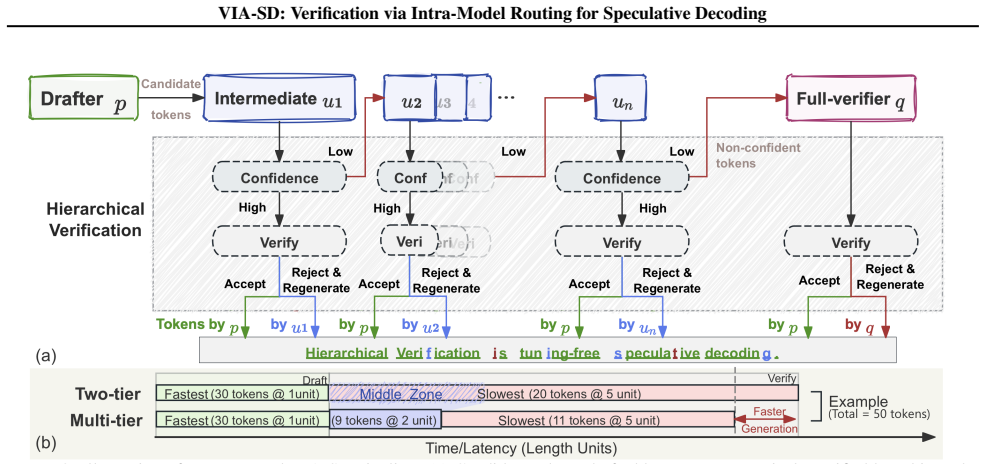
VIA-SD uses intra-model routing to derive a slim-verifier that correctly processes tokens requiring moderate verification resources. Draft tokens are handled hierarchically so that many tokens rejected under binary accept/reject decisions are instead regenerated by the slim verifier, cutting full-model invocations while preserving output quality.
What carries the argument
The routed slim-verifier created via intra-model routing from the full verifier, which serves as the middle tier in a three-level acceptance hierarchy.
If this is right
- Fewer full-model verifications occur because medium-confidence tokens are resolved by the slim verifier.
- Rejection rates drop 0.10-0.22, producing 10-20% speedups over strong speculative decoding baselines.
- Overall inference reaches 2.5-3x acceleration relative to non-drafting decoding.
- The method works with existing speculative decoding frameworks without any retraining step.
- Multi-tier verification emerges as a reusable pattern for scaling LLM inference efficiency.
Where Pith is reading between the lines
- Routing thresholds could be tuned per task or model size to maximize the fraction of tokens routed to the slim verifier.
- The same intra-model routing idea might apply to other verification bottlenecks such as retrieval-augmented generation or tool-use loops.
- Combining the slim verifier with quantization or pruning could produce additive latency reductions beyond the reported figures.
Load-bearing premise
The slim submodel can correctly verify a substantial fraction of the tokens the full verifier would reject without introducing new errors that erase the speed gains.
What would settle it
An experiment that measures the slim-verifier's acceptance rate on tokens the full model rejects and checks whether end-to-end task accuracy falls by more than the reported speedup margin.
Figures




read the original abstract
Speculative decoding (SD) addresses the high inference costs of LLMs by having lightweight drafters generate candidates for large verifiers to validate in parallel. Existing draft-verify methods use binary decisions: accept or fully recompute. Yet we find that many rejected tokens can be verified correctly by a slim submodel derived from the full verifier via intra-model routing, instead of the full verifier. This motivates our slim-verifier to handle tokens requiring moderate verification resources, reducing expensive large-model calls. We propose Verification via Intra-Model Routing for Speculative Decoding (VIA-SD), a multi-tier framework using a routed slim-verifier. Draft tokens are processed hierarchically: direct acceptance for high-confidence cases, slim-verifier regeneration for medium-confidence cases, and full-model verification for uncertain cases. Across four representative tasks and multiple model families, VIA-SD reduces rejection rates by 0.10-0.22 and delivers 10-20% speedups over strong SD baselines, while achieving 2.5-3x acceleration over non-drafting decoding. Moreover, VIA-SD is compatible with existing SD frameworks without modifying their training procedures. Our results suggest multi-tier SD as a general paradigm for scalable and efficient LLM inference. Project page: https://zju-xyc.github.io/VIA-SD-Project-Page/
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes VIA-SD, a multi-tier speculative decoding framework that uses intra-model routing to derive a slim submodel verifier for medium-confidence draft tokens (with direct acceptance for high-confidence and full-model verification for uncertain cases). It claims this reduces rejection rates by 0.10-0.22 and yields 10-20% speedups over strong SD baselines (and 2.5-3x over non-drafting) across four tasks and multiple model families, while remaining compatible with existing SD methods without training changes.
Significance. If the slim verifier maintains exact decision equivalence with the full verifier on its routed subset, the work would usefully extend the SD paradigm by introducing hierarchical verification that reduces full-model calls. The reported compatibility with unmodified SD frameworks and the multi-task empirical evaluation are strengths that would support broader adoption if the core equivalence holds.
major comments (3)
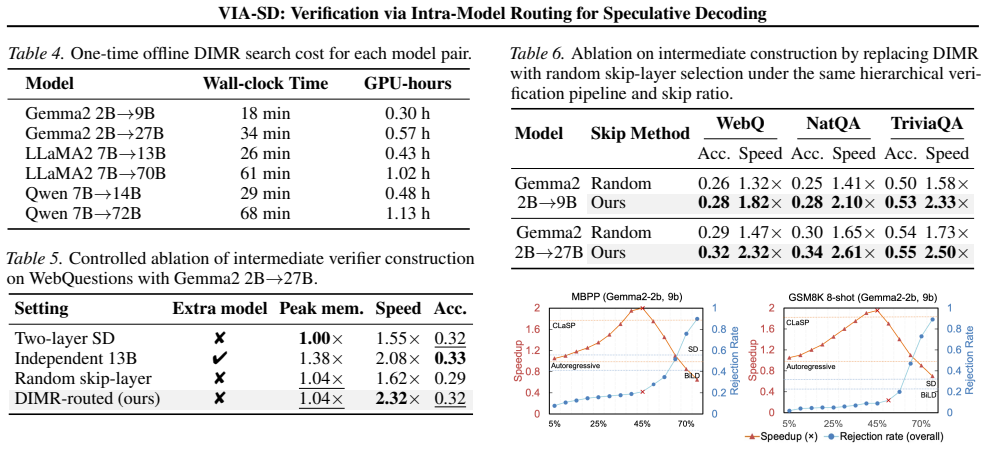
- [§3] §3 (Method): The intra-model routing mechanism for constructing and invoking the slim submodel is described at a high level, but no routing mask, early-exit threshold, consistency loss, or other mechanism is specified that enforces the slim verifier's acceptance decisions to be identical to those of the full verifier on the medium-confidence tokens it handles. This equivalence is load-bearing for the lossless property of SD and for the validity of the reported speedups.
- [§4] §4 (Experiments): No empirical verification is reported that the final output sequences produced by VIA-SD match those of standard SD exactly (e.g., via token-by-token comparison or perplexity equivalence on the evaluated tasks). Without this check, the 10-20% speedup figures cannot be directly compared to baselines.
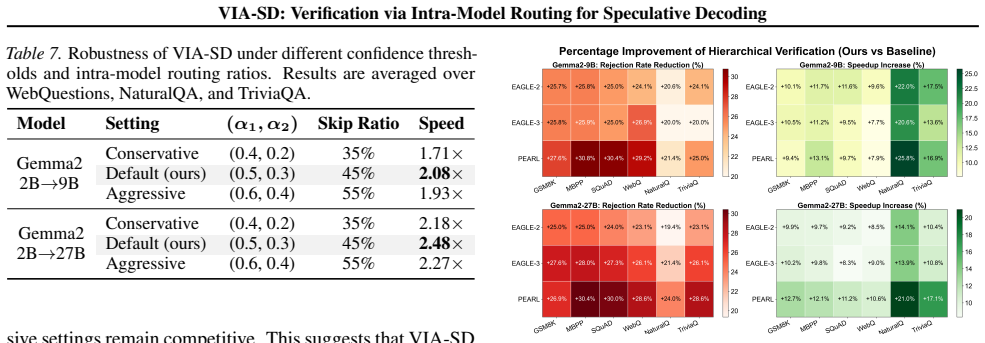
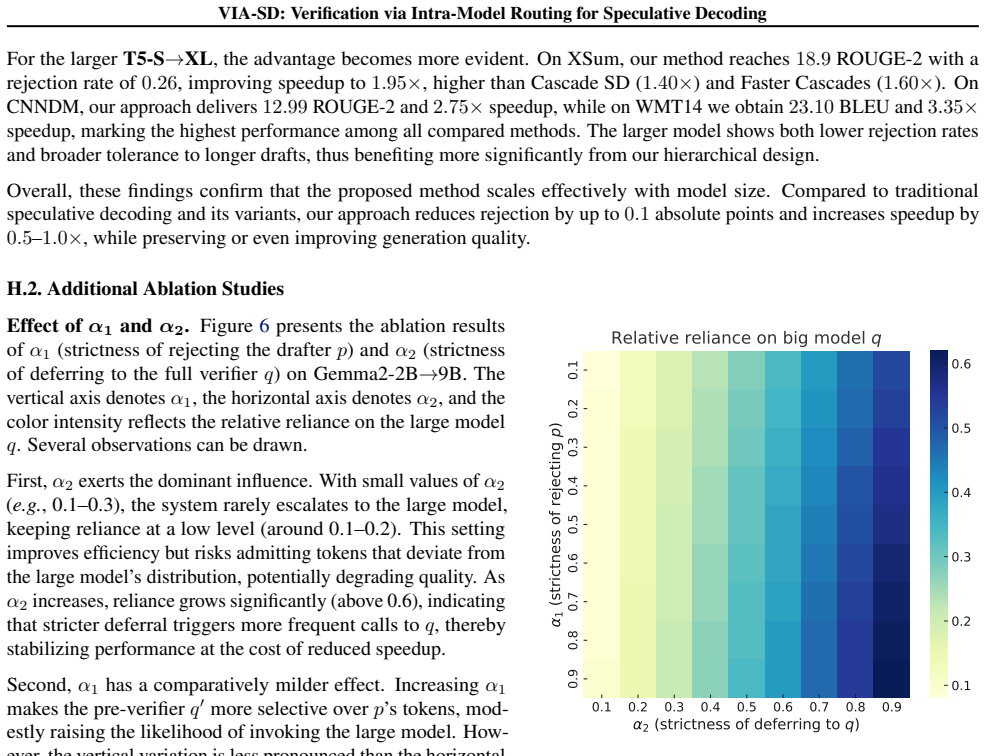
- [Table 2] Table 2 (or equivalent results table): The reported rejection-rate reductions (0.10-0.22) and speedups are presented as point estimates without error bars, variance across runs, or statistical significance tests, making it impossible to assess whether the gains are robust or could be explained by sampling noise.
minor comments (3)
- [Abstract] The abstract and introduction use the phrase 'can be verified correctly' without defining the precise acceptance criterion or error tolerance for the slim verifier.
- [Figure 1] Figure 1 (framework diagram) would benefit from explicit annotation of the routing thresholds or confidence bands that separate the three tiers.
- [§2] A brief discussion of related hierarchical or early-exit verification methods is missing from the related-work section.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the method description, need for output equivalence checks, and statistical reporting. We address each point below and will revise the manuscript to incorporate the requested clarifications and additions.
read point-by-point responses
-
Referee: [§3] §3 (Method): The intra-model routing mechanism for constructing and invoking the slim submodel is described at a high level, but no routing mask, early-exit threshold, consistency loss, or other mechanism is specified that enforces the slim verifier's acceptance decisions to be identical to those of the full verifier on the medium-confidence tokens it handles. This equivalence is load-bearing for the lossless property of SD and for the validity of the reported speedups.
Authors: We agree that §3 currently provides only a high-level description. In the revised manuscript we will expand this section with the precise routing mask definition, early-exit threshold values, and any auxiliary consistency mechanisms employed to guarantee that the slim verifier's acceptance decisions are identical to the full verifier's on the routed medium-confidence tokens. This addition will make explicit how the lossless property is maintained. revision: yes
-
Referee: [§4] §4 (Experiments): No empirical verification is reported that the final output sequences produced by VIA-SD match those of standard SD exactly (e.g., via token-by-token comparison or perplexity equivalence on the evaluated tasks). Without this check, the 10-20% speedup figures cannot be directly compared to baselines.
Authors: We acknowledge that an explicit empirical check would strengthen the presentation. Although the hierarchical routing is designed to preserve exact equivalence, we will add in the revised §4 a direct verification: token-by-token match rates and perplexity comparisons between VIA-SD and standard SD outputs on all evaluated tasks, confirming identical sequences. revision: yes
-
Referee: [Table 2] Table 2 (or equivalent results table): The reported rejection-rate reductions (0.10-0.22) and speedups are presented as point estimates without error bars, variance across runs, or statistical significance tests, making it impossible to assess whether the gains are robust or could be explained by sampling noise.
Authors: We agree that variability measures are needed for robustness assessment. In the revised results tables we will report standard deviations across multiple runs with different random seeds, include error bars, and add statistical significance tests (paired t-tests) for the rejection-rate and speedup improvements. revision: yes
Circularity Check
No circularity: empirical speedups measured directly, no derivation or fitted predictions
full rationale
The paper introduces VIA-SD as an empirical multi-tier speculative decoding method using intra-model routing to create a slim verifier for medium-confidence tokens. All reported outcomes (rejection rate reductions of 0.10-0.22 and 10-20% speedups) are presented as direct experimental measurements across tasks and model families, not as quantities derived from equations or parameters that reduce to the inputs by construction. No self-definitional steps, fitted-input predictions, load-bearing self-citations, uniqueness theorems, or ansatzes appear in the abstract or description. The method is compatible with existing frameworks without training modifications, and results are framed as observations rather than tautological re-expressions of the proposal itself. This is the common case of a self-contained empirical contribution.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Cohen and Mirella Lapata
Shashi Narayan and Shay B. Cohen and Mirella Lapata. Don't Give Me the Details, Just the Summary! T opic-Aware Convolutional Neural Networks for Extreme Summarization. EMNLP. 2018
2018
-
[2]
and Manning, Christopher D
See, Abigail and Liu, Peter J. and Manning, Christopher D. Get To The Point: Summarization with Pointer-Generator Networks. ACL. 2017
2017
-
[3]
Know What You Don ' t Know: Unanswerable Questions for SQ u AD
Rajpurkar, Pranav and Jia, Robin and Liang, Percy. Know What You Don ' t Know: Unanswerable Questions for SQ u AD. ACL. 2018
2018
-
[4]
ACL , year=
Triviaqa: A large scale distantly supervised challenge dataset for reading comprehension , author=. ACL , year=
-
[5]
TACL , year=
Natural questions: a benchmark for question answering research , author=. TACL , year=
-
[6]
Semantic Parsing on F reebase from Question-Answer Pairs
Berant, Jonathan and Chou, Andrew and Frostig, Roy and Liang, Percy. Semantic Parsing on F reebase from Question-Answer Pairs. Proceedings of the 2013 Conference on Empirical Methods in Natural Language Processing. 2013
2013
-
[9]
arXiv preprint arXiv:2108.07732 , year=
Program synthesis with large language models , author=. arXiv preprint arXiv:2108.07732 , year=
-
[10]
ICML , year=
Crafting papers on machine learning , author=. ICML , year=
-
[11]
JMLR , year=
Clustering with Bregman divergences , author=. JMLR , year=
-
[12]
1980 , publisher=
The need for biases in learning generalizations , author=. 1980 , publisher=
1980
-
[13]
1990 , publisher=
The computational complexity of machine learning , author=. 1990 , publisher=
1990
-
[14]
2013 , publisher=
Machine learning: An artificial intelligence approach , author=. 2013 , publisher=
2013
-
[15]
2001 , publisher=
Pattern classification , author=. 2001 , publisher=
2001
-
[16]
Cognitive skills and their acquisition , pages=
Mechanisms of skill acquisition and the law of practice , author=. Cognitive skills and their acquisition , pages=. 2013 , publisher=
2013
-
[17]
IBM Journal of research and development , volume=
Some studies in machine learning using the game of checkers , author=. IBM Journal of research and development , volume=. 1959 , publisher=
1959
-
[18]
Large-scale kernel machines , volume=
Scaling learning algorithms towards AI , author=. Large-scale kernel machines , volume=
-
[19]
Neural computation , volume=
A fast learning algorithm for deep belief nets , author=. Neural computation , volume=. 2006 , publisher=
2006
-
[20]
2016 , publisher=
Deep learning , author=. 2016 , publisher=
2016
-
[21]
arXiv preprint arXiv:2309.16609 , year=
Qwen technical report , author=. arXiv preprint arXiv:2309.16609 , year=
-
[22]
arXiv preprint arXiv:2307.09288 , year=
Llama 2: Open foundation and fine-tuned chat models , author=. arXiv preprint arXiv:2307.09288 , year=
-
[23]
ICML , year=
Fast inference from transformers via speculative decoding , author=. ICML , year=
-
[24]
Advances in Neural Information Processing Systems , volume=
Spectr: Fast speculative decoding via optimal transport , author=. Advances in Neural Information Processing Systems , volume=
-
[25]
IEEE Transactions on information theory , volume=
On optimum recognition error and reject tradeoff , author=. IEEE Transactions on information theory , volume=. 2003 , publisher=
2003
-
[26]
Advances in Neural Information Processing Systems , volume=
When does confidence-based cascade deferral suffice? , author=. Advances in Neural Information Processing Systems , volume=
-
[27]
arXiv preprint arXiv:2404.10136 , year=
Language model cascades: Token-level uncertainty and beyond , author=. arXiv preprint arXiv:2404.10136 , year=
-
[28]
NeurIPS , year=
Blockwise parallel decoding for deep autoregressive models , author=. NeurIPS , year=
-
[29]
CACM , year=
Latency lags bandwith , author=. CACM , year=
-
[30]
2011 , publisher=
Computer architecture: a quantitative approach , author=. 2011 , publisher=
2011
-
[31]
ICML , year=
Online speculative decoding , author=. ICML , year=
-
[32]
NeurIPS , year=
Specexec: Massively parallel speculative decoding for interactive llm inference on consumer devices , author=. NeurIPS , year=
-
[33]
Enhancing LLM Performance: Efficacy, Fine-Tuning, and Inference Techniques , pages=
Speed: Speculative pipelined execution for efficient decoding , author=. Enhancing LLM Performance: Efficacy, Fine-Tuning, and Inference Techniques , pages=. 2025 , publisher=
2025
-
[34]
arXiv preprint arXiv:1911.02150 , year=
Fast transformer decoding: One write-head is all you need , author=. arXiv preprint arXiv:1911.02150 , year=
Pith/arXiv arXiv 1911
-
[35]
IEEE TC , year=
Speculative computation, parallelism, and functional programming , author=. IEEE TC , year=
-
[36]
ICLR , year=
Faster Cascades via Speculative Decoding , author=. ICLR , year=
-
[37]
2016 , publisher=
Information geometry and its applications , author=. 2016 , publisher=
2016
-
[38]
Elements of Information Theory (2nd ed.) , author =
-
[39]
Transactions of the Association for Computational Linguistics , volume=
Opt-tree: Speculative decoding with adaptive draft tree structure , author=. Transactions of the Association for Computational Linguistics , volume=. 2025 , publisher=
2025
-
[40]
ASPLOS , year=
Specinfer: Accelerating large language model serving with tree-based speculative inference and verification , author=. ASPLOS , year=
-
[41]
and Chen, Deming and Dao, Tri , booktitle =
Cai, Tianle and Li, Yuhong and Geng, Zhengyang and Peng, Hongwu and Lee, Jason D. and Chen, Deming and Dao, Tri , booktitle =. Medusa: Simple
-
[42]
Li, Yuhui and Wei, Fangyun and Zhang, Chao and Zhang, Hongyang , booktitle =
-
[43]
ACL , year=
Draft& verify: Lossless large language model acceleration via self-speculative decoding , author=. ACL , year=
-
[44]
Predictive Pipelined Decoding: A Compute-Latency Trade-off for Exact
Yang, Seongjun and Lee, Gibbeum and Cho, Jaewoong and Papailiopoulos, Dimitris and Lee, Kangwook , journal=. Predictive Pipelined Decoding: A Compute-Latency Trade-off for Exact
-
[45]
NeurIPS , year=
Sequoia: Scalable, robust, and hardware-aware speculative decoding , author=. NeurIPS , year=
-
[46]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Dynamic-width speculative beam decoding for llm inference , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[47]
Findings of EMNLP , year=
Speculative decoding: Exploiting speculative execution for accelerating seq2seq generation , author=. Findings of EMNLP , year=
-
[48]
2006 , publisher=
Elements of Information Theory , author=. 2006 , publisher=
2006
-
[49]
Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
Densely connected convolutional networks , author=. Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
-
[50]
ICLR , year=
Distillspec: Improving speculative decoding via knowledge distillation , author=. ICLR , year=
-
[51]
The annals of mathematical statistics , year=
On information and sufficiency , author=. The annals of mathematical statistics , year=
-
[52]
NeurIPS , year=
Cascade speculative drafting for even faster llm inference , author=. NeurIPS , year=
-
[53]
Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
Dovetail: A cpu/gpu heterogeneous speculative decoding for llm inference , author=. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
2025
-
[54]
and Zhou, Z
Li, C. and Zhou, Z. and Zheng, S. and Zhang, J. and Liang, Y. and Sun, G. , booktitle=. 2024 , publisher=
2024
-
[55]
CL a S p: In-Context Layer Skip for Self-Speculative Decoding
Chen, Longze and Shan, Renke and Wang, Huiming and Wang, Lu and Liu, Ziqiang and Luo, Run and Wang, Jiawei and Alinejad-Rokny, Hamid and Yang, Min. CL a S p: In-Context Layer Skip for Self-Speculative Decoding. ACL. 2025
2025
-
[56]
NeurIPS , year =
Speculative Decoding with Big Little Decoder , author =. NeurIPS , year =
-
[57]
arXiv preprint arXiv:2302.01318 , year=
Accelerating large language model decoding with speculative sampling , author=. arXiv preprint arXiv:2302.01318 , year=
-
[58]
Heming Xia and Yongqi Li and Jun Zhang and Cunxiao Du and Wenjie Li , booktitle=
-
[59]
Unsupervised Thoughts (blog) , author=
An optimal lossy variant of speculative decoding , url=. Unsupervised Thoughts (blog) , author=
-
[60]
ICLR , year=
Multisize dataset condensation , author=. ICLR , year=
-
[61]
JMLR , year=
Exploring the limits of transfer learning with a unified text-to-text transformer , author=. JMLR , year=
-
[62]
arXiv preprint arXiv:2408.00118 , year=
Gemma 2: Improving open language models at a practical size , author=. arXiv preprint arXiv:2408.00118 , year=
-
[63]
2017 , publisher=
Markov chains and mixing times , author=. 2017 , publisher=
2017
-
[64]
ACL Workshop , year=
Findings of the 2014 workshop on statistical machine translation , author=. ACL Workshop , year=
2014
-
[65]
Liu, Tianyu and Li, Yun and Lv, Qitan and Liu, Kai and Zhu, Jianchen and Hu, Winston and Sun, Xiao , booktitle=
-
[66]
EAGLE -2: Faster Inference of Language Models with Dynamic Draft Trees
Li, Yuhui and Wei, Fangyun and Zhang, Chao and Zhang, Hongyang. EAGLE -2: Faster Inference of Language Models with Dynamic Draft Trees. EMNLP. 2024
2024
-
[67]
NeurIPS , year =
Yuhui Li and Fangyun Wei and Chao Zhang and Hongyang Zhang , title =. NeurIPS , year =
-
[68]
Advances in neural information processing systems , volume=
Teaching machines to read and comprehend , author=. Advances in neural information processing systems , volume=
-
[69]
EMNLP , year=
Semantic parsing on freebase from question-answer pairs , author=. EMNLP , year=
-
[70]
SQ u AD : 100,000+ Questions for Machine Comprehension of Text
Rajpurkar, Pranav and Zhang, Jian and Lopyrev, Konstantin and Liang, Percy. SQ u AD : 100,000+ Questions for Machine Comprehension of Text. Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing. 2016. doi:10.18653/v1/D16-1264
-
[71]
arXiv preprint arXiv:1811.10959 , year=
Dataset distillation , author=. arXiv preprint arXiv:1811.10959 , year=
-
[72]
2020 , booktitle =
Mirzasoleiman, Baharan and Bilmes, Jeff and Leskovec, Jure , title =. 2020 , booktitle =
2020
-
[73]
ICLR , year=
Outrageously large neural networks: The sparsely-gated mixture-of-experts layer , author=. ICLR , year=
-
[74]
ICLR , year=
Deep compression: Compressing deep neural networks with pruning, trained quantization and huffman coding , author=. ICLR , year=
-
[75]
arXiv preprint arXiv:1503.02531 , year=
Distilling the knowledge in a neural network , author=. arXiv preprint arXiv:1503.02531 , year=
-
[76]
arXiv preprint arXiv:2110.14168 , year=
Training verifiers to solve math word problems , author=. arXiv preprint arXiv:2110.14168 , year=
-
[77]
Proceedings of the 20th SIGNLL conference on computational natural language learning , pages=
Abstractive text summarization using sequence-to-sequence rnns and beyond , author=. Proceedings of the 20th SIGNLL conference on computational natural language learning , pages=
-
[78]
2008 , publisher=
Optimal transport: old and new , author=. 2008 , publisher=
2008
-
[79]
2021 , booktitle =
Narayanan, Deepak and Shoeybi, Mohammad and Casper, Jared and LeGresley, Patrick and Patwary, Mostofa and Korthikanti, Vijay and Vainbrand, Dmitri and Kashinkunti, Prethvi and Bernauer, Julie and Catanzaro, Bryan and Phanishayee, Amar and Zaharia, Matei , title =. 2021 , booktitle =
2021
-
[80]
Advances in Neural Information Processing Systems (NeurIPS) , year=
Fast and memory-efficient exact attention with IO-awareness , author=. Advances in Neural Information Processing Systems (NeurIPS) , year=
-
[81]
Hierarchical Speculative Decoding with Dynamic Window
Syu, Shensian and Lee, Hung-yi. Hierarchical Speculative Decoding with Dynamic Window. Findings of NAACL. 2025
2025
-
[82]
Findings of EMNLP , year=
Dropping Experts, Recombining Neurons: Retraining-Free Pruning for Sparse Mixture-of-Experts LLMs , author=. Findings of EMNLP , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.