Fast Nonparametric Conditional Independence Testing via Two-Stage Regression
Pith reviewed 2026-06-26 22:32 UTC · model grok-4.3
The pith
BLITZ achieves fast nonparametric conditional independence testing by first regressing out broad dependence with low-order polynomials and then using shallow trees on a small nonlinear feature map to residualize the rest.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
BLITZ performs conditional independence testing by first removing broad smooth dependence on the conditioning set via low-order polynomial regression, applying a small nonlinear feature map, and then residualizing those features with shallow tree regressions before testing residual cross-covariance under a moment-matched chi-square approximation. The two-stage design reduces the complexity faced by the tree residualizers, so that shallow trees can control residual conditional-mean bias without excessive overfitting that would invalidate the null approximation.
What carries the argument
The two-stage residualization in BLITZ: low-order polynomials remove broad dependence, then a nonlinear feature map followed by shallow trees handles the local remainder before cross-covariance testing.
If this is right
- The method supports thousands of conditional independence queries in constraint-based causal discovery without loss of calibration or speed.
- Better null calibration produces more reliable retained adjacencies and endpoint orientations in recovered graphs.
- Shallow trees suffice after the first-stage preprocessing, removing the need for deep models or post-hoc tuning.
- The design remains competitive in runtime while outperforming fast kernel and random-feature competitors on calibration.
Where Pith is reading between the lines
- The same broad-to-local split could be applied to other residual-based nonparametric tests where smooth trends dominate the signal.
- Adjusting polynomial degree or feature-map size might extend reliable performance to higher-dimensional conditioning sets.
- The moment-matched chi-square approximation may transfer to related problems in high-dimensional regression residual testing.
Load-bearing premise
Low-order polynomial regression plus a small nonlinear feature map sufficiently captures broad dependence so that shallow trees can residualize the remainder without overfitting that invalidates the chi-square null approximation.
What would settle it
A simulation in which the conditioning set has strong nonlinear dependence not captured by low-order polynomials, where the empirical type I error rate of BLITZ deviates substantially from the nominal level.
Figures




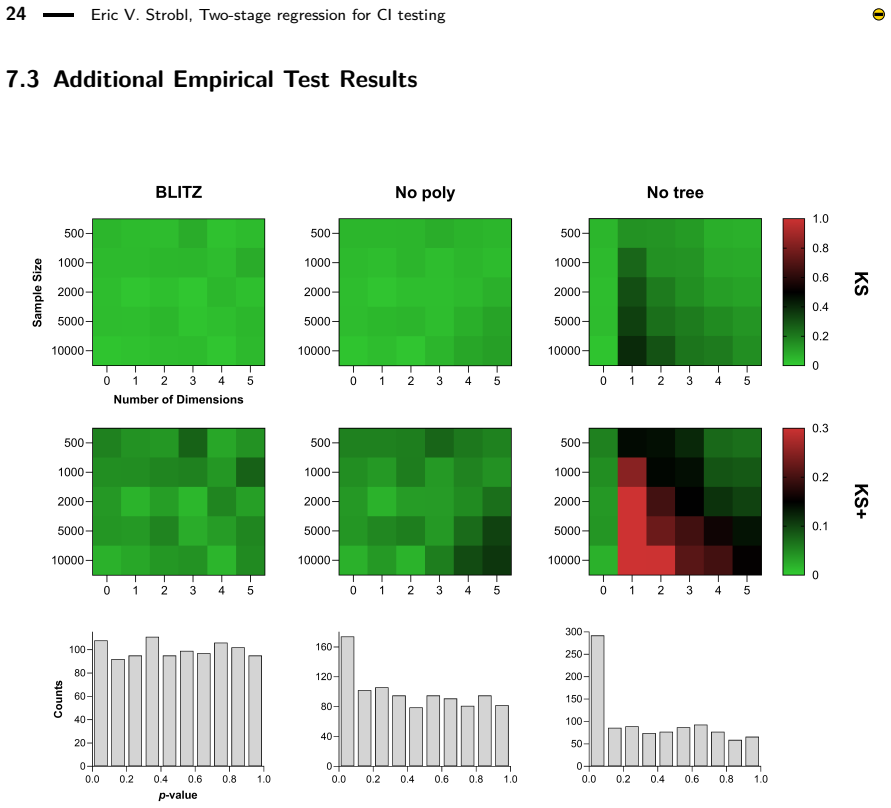

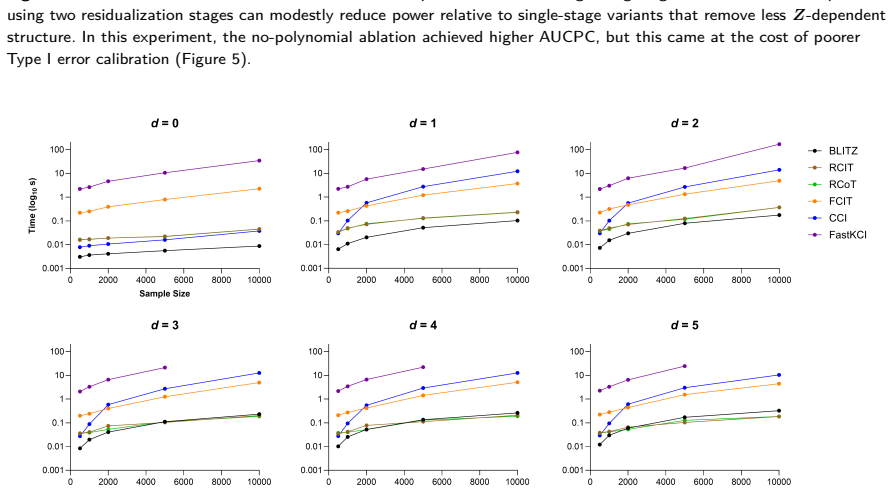
read the original abstract
Constraint-based causal discovery relies on repeated conditional independence tests, but fast nonparametric tests often sacrifice calibration, especially when variables depend on the conditioning set through nonlinear relationships. We introduce BLITZ (Broad-to-Local Independence Testing via residualiZation), a nonparametric conditional independence test designed to run well under a second while maintaining the accuracy needed for the thousands of queries performed by constraint-based causal discovery algorithms. BLITZ first removes broad smooth dependence on the conditioning set using low-order polynomial regression, then applies a small nonlinear feature map and residualizes those features with shallow tree regressions. The resulting statistic tests residual cross-covariance, with a moment-matched chi-square approximation to the null distribution. We show theoretically that the two-stage design reduces the effective complexity faced by the tree residualizers, allowing shallow trees to control residual conditional-mean bias while avoiding excessive overfitting. In simulations, BLITZ provides better null calibration than fast kernel, random-feature, and regression-based competitors while remaining among the fastest methods tested. In causal discovery experiments on synthetic graphs and flow-cytometry data, BLITZ yields more reliable endpoint orientations among retained adjacencies and competitive structural recovery. These results suggest that broad-to-local residualization is a practical route to calibrated, scalable nonparametric conditional independence testing for causal discovery.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces BLITZ, a nonparametric conditional independence test that first removes broad smooth dependence via low-order polynomial regression on the conditioning set, applies a small nonlinear feature map, and then residualizes with shallow tree regressions. The test statistic is the residual cross-covariance, with a moment-matched chi-square null approximation. The central claim is that the two-stage design reduces effective complexity for the tree residualizers, allowing shallow trees to control residual bias without excessive overfitting that would invalidate the null approximation. Simulations show improved null calibration over fast kernel, random-feature, and regression-based methods while remaining fast; causal discovery experiments on synthetic graphs and flow-cytometry data report more reliable orientations and competitive structural recovery.
Significance. If the complexity-reduction argument holds under the stated conditions and the simulation calibration results are robust to the choice of polynomial degree and tree depth, BLITZ would offer a practical advance for constraint-based causal discovery by improving the speed-accuracy trade-off in repeated nonparametric CI tests. The explicit two-stage residualization strategy and moment-matching approach are concrete contributions that could be adopted or extended in other scalable CI testing pipelines.
major comments (2)
- [Abstract / theoretical claim] Abstract and theoretical section: The claim that the two-stage design 'reduces the effective complexity faced by the tree residualizers' is load-bearing for both the theoretical guarantee and the chi-square approximation. No explicit bounds, conditions on the polynomial degree relative to the smoothness of the dependence, or derivation quantifying residual bias after the first stage are visible, leaving open whether the shallow-tree regime remains valid when dependence involves higher-order or non-polynomial terms not spanned by the chosen low-order polynomial and small feature map.
- [Simulation experiments] Simulation results (as summarized): The reported better null calibration is central to the practical claim, yet the abstract provides no details on error-bar reporting, number of Monte Carlo repetitions, data-exclusion rules, or how the polynomial degree and tree depth were selected across different dependence structures. This makes it impossible to assess whether the calibration advantage is robust or sensitive to the free parameters listed in the axiom ledger.
minor comments (1)
- [Methods] Notation for the nonlinear feature map and the precise definition of the residual cross-covariance statistic should be introduced with an equation number in the methods section for reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on our manuscript. Below we respond point-by-point to the major comments, indicating planned revisions where appropriate.
read point-by-point responses
-
Referee: [Abstract / theoretical claim] Abstract and theoretical section: The claim that the two-stage design 'reduces the effective complexity faced by the tree residualizers' is load-bearing for both the theoretical guarantee and the chi-square approximation. No explicit bounds, conditions on the polynomial degree relative to the smoothness of the dependence, or derivation quantifying residual bias after the first stage are visible, leaving open whether the shallow-tree regime remains valid when dependence involves higher-order or non-polynomial terms not spanned by the chosen low-order polynomial and small feature map.
Authors: We appreciate the referee highlighting the need for stronger theoretical grounding. The manuscript argues that the initial low-order polynomial regression removes broad smooth dependence, thereby lowering the complexity that must be handled by the subsequent shallow tree residualizers. However, we agree that explicit bounds on residual bias, conditions relating polynomial degree to the smoothness of the underlying dependence, and a derivation quantifying the bias after the first stage are not provided. In the revision we will add a dedicated subsection with these elements, including sufficient conditions under which the shallow-tree regime controls residual conditional-mean bias even for higher-order or non-polynomial terms outside the span of the chosen polynomial and feature map. This will also clarify the validity of the moment-matched chi-square approximation. revision: yes
-
Referee: [Simulation experiments] Simulation results (as summarized): The reported better null calibration is central to the practical claim, yet the abstract provides no details on error-bar reporting, number of Monte Carlo repetitions, data-exclusion rules, or how the polynomial degree and tree depth were selected across different dependence structures. This makes it impossible to assess whether the calibration advantage is robust or sensitive to the free parameters listed in the axiom ledger.
Authors: We agree that additional experimental details are required for readers to evaluate robustness. While the full simulation section reports the number of Monte Carlo repetitions and the procedure used to select polynomial degree and tree depth, the abstract indeed omits error-bar reporting, explicit data-exclusion rules, and a consolidated description of parameter selection across dependence structures. In the revision we will expand the simulation section (and add a short summary in the abstract) to include these elements, along with sensitivity checks on the free parameters, so that the calibration advantage can be assessed more transparently. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper proposes a two-stage residualization procedure (low-order polynomials followed by shallow trees on a small feature map) and claims a theoretical reduction in effective complexity for the tree stage, with a moment-matched chi-square null. No quoted equations or steps reduce a claimed prediction or uniqueness result to a fitted parameter or self-citation by construction. The chi-square approximation is presented as moment-based rather than data-fitted in a self-referential manner, and the derivation chain remains independent of its own outputs. This is the expected non-finding for a method paper whose central claims rest on design properties and external simulation benchmarks.
Axiom & Free-Parameter Ledger
free parameters (2)
- polynomial degree
- tree depth / number of features
axioms (2)
- domain assumption Low-order polynomials plus a fixed nonlinear feature map are sufficient to capture all broad smooth dependence on the conditioning set.
- domain assumption The moment-matched chi-square distribution accurately approximates the null distribution of the residual cross-covariance statistic after two-stage regression.
Reference graph
Works this paper leans on
-
[1]
An approximation to the distribution of quadratic forms in normal random variables.Australian Journal of Statistics, 30(1):150–159, 1988
Michael J Buckley and Geoffrey K Eagleson. An approximation to the distribution of quadratic forms in normal random variables.Australian Journal of Statistics, 30(1):150–159, 1988
1988
-
[2]
Fast Conditional Independence Test for Vector Variables with Large Sample Sizes
Krzysztof Chalupka, Pietro Perona, and Frederick Eberhardt. Fast conditional independence test for vector variables with large sample sizes.arXiv preprint arXiv:1804.02747, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[3]
Optimal structure identification with greedy search.Journal of machine learning research, 3(Nov):507–554, 2002
David Maxwell Chickering. Optimal structure identification with greedy search.Journal of machine learning research, 3(Nov):507–554, 2002
2002
-
[4]
Conditional independence in statistical theory.Journal of the Royal Statistical Society Series B: Statistical Methodology, 41(1):1–15, 1979
A Philip Dawid. Conditional independence in statistical theory.Journal of the Royal Statistical Society Series B: Statistical Methodology, 41(1):1–15, 1979
1979
-
[5]
A permutation-based kernel conditional independence test
Gary Doran, Krikamol Muandet, Kun Zhang, and Bernhard Schölkopf. A permutation-based kernel conditional independence test. InUAI, pages 132–141, 2014
2014
-
[6]
Review of causal discovery methods based on graphical models
Clark Glymour, Kun Zhang, and Peter Spirtes. Review of causal discovery methods based on graphical models. Frontiers in Genetics, 10:524, 2019
2019
-
[7]
Chi squared approximations to the distribution of a sum of independent random variables.The Annals of Probability, pages 1028–1036, 1983
Peter Hall. Chi squared approximations to the distribution of a sum of independent random variables.The Annals of Probability, pages 1028–1036, 1983
1983
-
[8]
Generalized score functions for causal discovery
Biwei Huang, Kun Zhang, Yizhu Lin, Bernhard Schölkopf, and Clark Glymour. Generalized score functions for causal discovery. InProceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, pages 1551–1560, 2018
2018
-
[9]
Estimating high-dimensional directed acyclic graphs with the pc-algorithm.Journal of Machine Learning Research, 8(3), 2007
Markus Kalisch and Peter Bühlman. Estimating high-dimensional directed acyclic graphs with the pc-algorithm.Journal of Machine Learning Research, 8(3), 2007
2007
-
[10]
Moment-based approximations of distributions using mixtures: Theory and applications.Annals of the Institute of Statistical Mathematics, 52(2):215–230, 2000
Bruce G Lindsay, Ramani S Pilla, and Prasanta Basak. Moment-based approximations of distributions using mixtures: Theory and applications.Annals of the Institute of Statistical Mathematics, 52(2):215–230, 2000
2000
-
[11]
Searching for Activation Functions
Prajit Ramachandran, Barret Zoph, and Quoc V Le. Searching for activation functions.arXiv preprint arXiv:1710.05941, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[12]
FASK with Interventional Knowledge Recovers Edges from the Sachs Model
Joseph Ramsey and Bryan Andrews. Fask with interventional knowledge recovers edges from the sachs model.arXiv preprint arXiv:1805.03108, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[13]
Adjacency-faithfulness and conservative causal inference
Joseph Ramsey, Peter Spirtes, and Jiji Zhang. Adjacency-faithfulness and conservative causal inference. InProceedings of the Twenty-Second Conference on Uncertainty in Artificial Intelligence, pages 401–408, 2006. Eric V. Strobl, Two-stage regression for CI testing 19
2006
-
[14]
A Scalable Conditional Independence Test for Nonlinear, Non-Gaussian Data
Joseph D Ramsey. A scalable conditional independence test for nonlinear, non-gaussian data.arXiv preprint arXiv:1401.5031, 2014
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[15]
Fast causal discovery by approximate kernel-based generalized score functions with linear computational complexity
Yixin Ren, Haocheng Zhang, Yewei Xia, Hao Zhang, Jihong Guan, and Shuigeng Zhou. Fast causal discovery by approximate kernel-based generalized score functions with linear computational complexity. InProceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V. 1, pages 1197–1208, 2025
2025
-
[16]
Conditional independence testing based on a nearest-neighbor estimator of conditional mutual informa- tion
Jakob Runge. Conditional independence testing based on a nearest-neighbor estimator of conditional mutual informa- tion. InInternational Conference on Artificial Intelligence and Statistics, pages 938–947. Pmlr, 2018
2018
-
[17]
Causal protein-signaling networks derived from multiparameter single-cell data.Science, 308(5721):523–529, 2005
Karen Sachs, Omar Perez, Dana Pe’er, Douglas A Lauffenburger, and Garry P Nolan. Causal protein-signaling networks derived from multiparameter single-cell data.Science, 308(5721):523–529, 2005
2005
-
[18]
A fast kernel-based conditional independence test with application to causal discovery
Oliver Schacht and Biwei Huang. A fast kernel-based conditional independence test with application to causal discovery. arXiv preprint arXiv:2505.11085, 2025
-
[19]
The hardness of conditional independence testing and the generalised covariance measure.The Annals of Statistics, 48(3):1514–1538, 2020
Rajen D Shah and Jonas Peters. The hardness of conditional independence testing and the generalised covariance measure.The Annals of Statistics, 48(3):1514–1538, 2020
2020
-
[20]
Causal discovery with fewer conditional independence tests
Kirankumar Shiragur, Jiaqi Zhang, and Caroline Uhler. Causal discovery with fewer conditional independence tests. In Proceedings of the 41st International Conference on Machine Learning, pages 45060–45078, 2024
2024
-
[21]
MIT press, 2000
Peter Spirtes, Clark N Glymour, and Richard Scheines.Causation, prediction, and search. MIT press, 2000
2000
-
[22]
Approximate kernel-based conditional independence tests for fast non-parametric causal discovery.Journal of Causal Inference, 7(1):20180017, 2019
Eric V Strobl, Kun Zhang, and Shyam Visweswaran. Approximate kernel-based conditional independence tests for fast non-parametric causal discovery.Journal of Causal Inference, 7(1):20180017, 2019
2019
-
[23]
Kernel-based conditional independence test and application in causal discovery
Kun Zhang, Jonas Peters, Dominik Janzing, and Bernhard Schölkopf. Kernel-based conditional independence test and application in causal discovery. InProceedings of the Twenty-Seventh Conference on Uncertainty in Artificial Intelligence, pages 804–813, 2011. 7 Supplementary Materials 7.1 Computational Complexity Let n denote the sample size and lets = dim(Z...
2011
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.