Self-Evolving Scientific Agent Discovers Generalizable Physically-Reasoned Fluid Control
Pith reviewed 2026-06-27 19:04 UTC · model grok-4.3
The pith
A self-evolving LLM agent autonomously refines code to produce a unified control policy for an underactuated fluid swimmer that generalizes to unseen targets without retraining.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
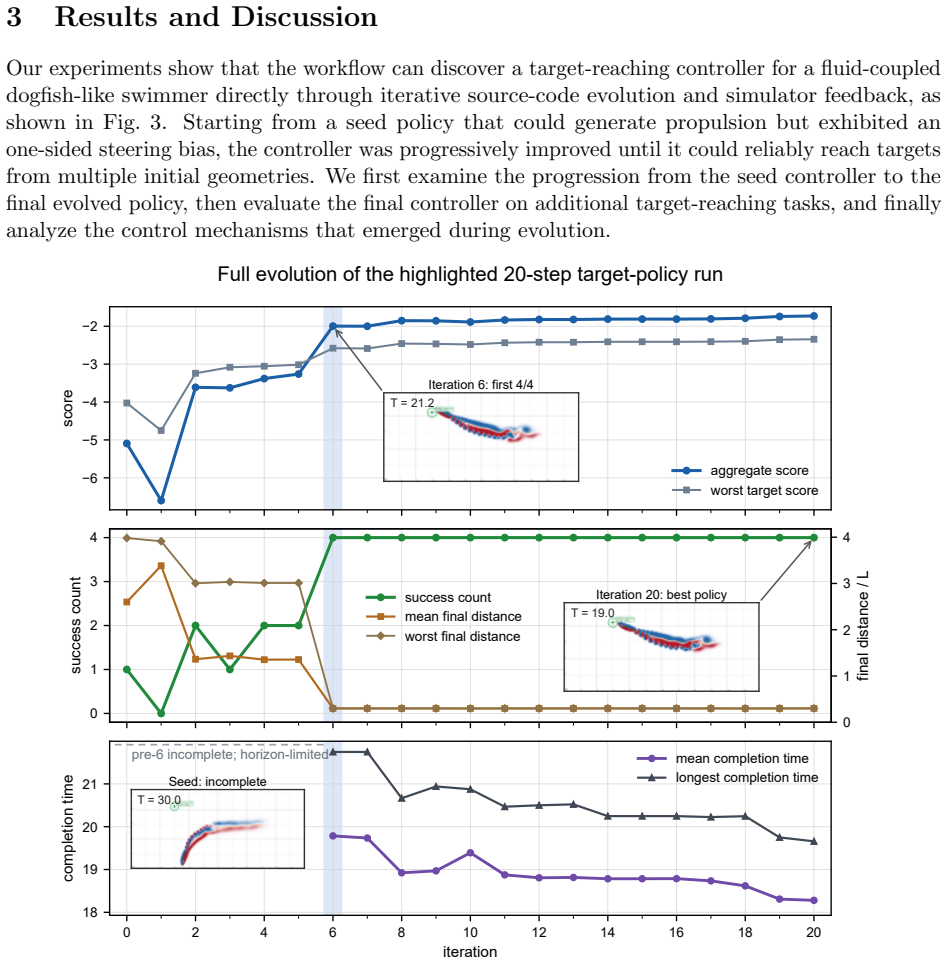
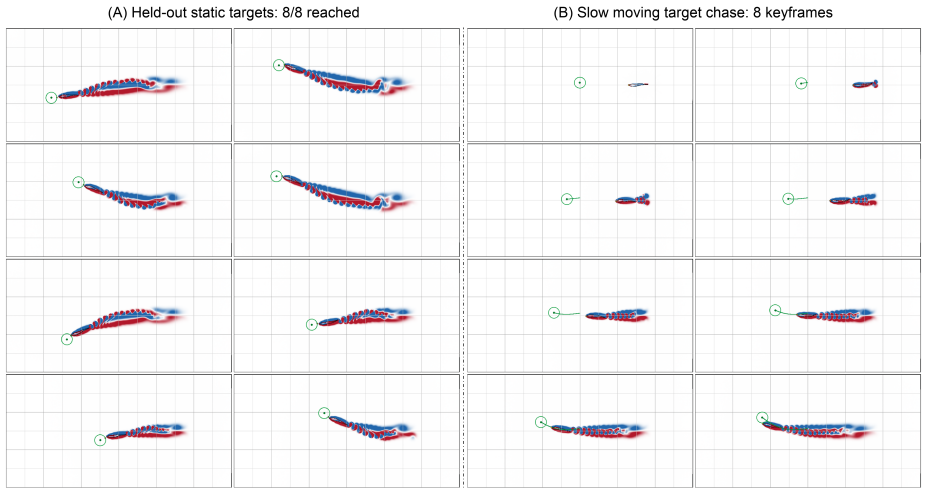
The agent, through iterative simulation and diagnosis of multimodal evidence, synthesizes a single control policy for the two-joint dogfish swimmer that robustly reaches all canonical targets and, without retraining or target-specific branching, also succeeds on unseen static targets and dynamically curved pursuit trajectories.
What carries the argument
The self-evolving scientific-agent workflow that deploys candidate strategies into physical simulations, diagnoses dynamic behaviors from multimodal evidence, and translates observations into progressive source-code refinements.
If this is right
- The final policy reaches all canonical targets and generalizes to unseen static targets and curved trajectories without retraining or branching.
- The evolve log supplies an explicit, traceable record of how physical observations led to each code change.
- The resulting architecture combines traveling-wave propulsion, body-frame target guidance, yaw-rate feedback, signed mean-tail curvature, and adaptive cadence relief.
- The method preserves strict interpretability while still achieving robust performance on a highly nonlinear fluid-structure interaction task.
Where Pith is reading between the lines
- The same iterative diagnosis-and-rewrite loop could be applied to other underactuated physical systems where simulation is cheap but analytical design is hard.
- If the LLM occasionally proposes plausible but ineffective code edits, the workflow would still require an external performance filter to reject regressions.
- Extending the agent to propose and evaluate entirely new sensor inputs or actuator limits would test whether the method scales beyond the current joint-acceleration formulation.
Load-bearing premise
The large language model can correctly diagnose dynamic behaviors from the multimodal simulation evidence and translate those diagnoses into code changes that actually improve physical performance.
What would settle it
Run the final synthesized policy on a previously unseen curved pursuit trajectory in the same fluid simulation environment and measure whether target-reaching success rate remains high without any additional code changes or retraining.
Figures

read the original abstract
While data-intensive deep reinforcement learning can optimize complex control policies, scientific discovery in physical systems fundamentally requires an interpretable chain of reasoning that connects physical evidence to structured control architectures. Here, we present a self-evolving scientific-agent workflow, driven by large language models and iterative code generation, that automates controller construction while preserving strict interpretability and rigorous physical reasoning. Instead of adjusting weights, the agent deploys candidate strategies into physical simulations, actively diagnoses dynamic behaviors from multimodal evidence, and translates these observations into progressive source-code refinements. We demonstrate this framework on a highly non-linear fluid-structure interaction problem: an underactuated, two-joint dogfish swimmer tasked with spatial target reaching using only joint angular accelerations. Starting from a propulsive seed policy that exhibits a one-sided steering bias, the agent autonomously discovers and refines a unified controller that robustly captures all canonical targets. Remarkably, without any retraining or target-specific branching, the synthesized control policy generalizes to unseen static targets and dynamically curved pursuit trajectories. The auditable evolve log reveals an emergent control architecture built upon traveling-wave propulsion, body-frame target guidance, yaw-rate feedback, signed mean-tail curvature, and adaptive cadence relief. Our results show that an autonomous scientific agent can successfully transform accumulated physical evidence into robust, mathematically readable control policy, while maintaining a fully traceable process of scientific discovery.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
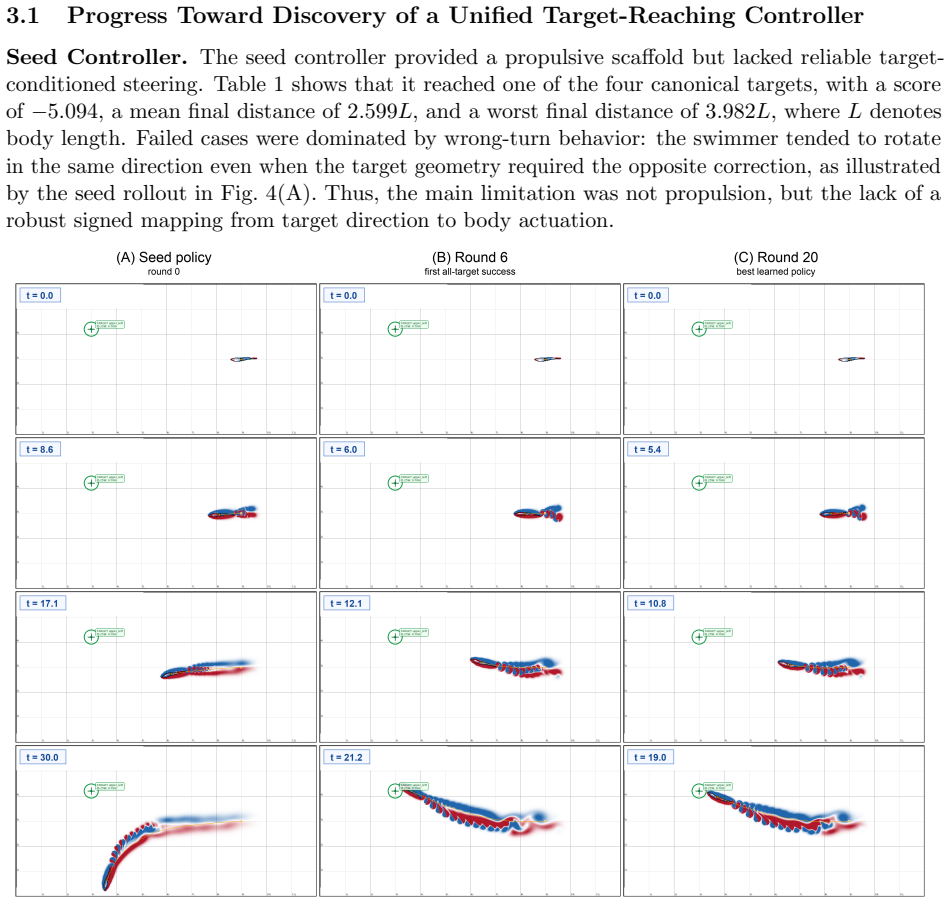
Summary. The manuscript presents a self-evolving scientific-agent workflow driven by large language models that iteratively generates, simulates, diagnoses, and refines source code for an underactuated two-joint dogfish swimmer in a nonlinear fluid-structure interaction problem. Starting from a one-sided steering bias in a propulsive seed policy, the agent produces a unified controller using components such as traveling-wave propulsion, body-frame target guidance, yaw-rate feedback, signed mean-tail curvature, and adaptive cadence relief. The central claim is that this policy reaches all canonical targets and, without retraining or target-specific branching, generalizes to unseen static targets and dynamically curved pursuit trajectories, with the entire process remaining fully auditable and interpretable.
Significance. If the generalization and physical-reasoning claims are substantiated with quantitative evidence, the work would be significant for automated scientific discovery in control and robotics. It offers a traceable alternative to black-box deep RL by coupling multimodal simulation evidence with LLM-driven code edits, potentially enabling interpretable policy synthesis in complex physical domains. The emphasis on an auditable evolve log and emergent physically grounded architecture is a notable strength.
major comments (3)
- [Abstract / Results] Abstract and results section: the central generalization claim (no retraining, performance on unseen static targets and curved trajectories) is load-bearing but unsupported by any reported success rates, trajectory errors, or statistical comparisons between training and test conditions; without these metrics it is impossible to confirm that LLM-driven refinements causally improve dynamics rather than produce policies that merely match observed training targets.
- [Methods / Workflow] Agent workflow description: the assertion that the LLM correctly diagnoses dynamic behaviors from multimodal simulation evidence and translates them into performance-improving code changes lacks concrete examples of the evidence traces, the exact diagnoses, and the resulting code diffs; this leaves open the possibility that refinements arise from pattern-matching to prior LLM knowledge rather than new physical reasoning.
- [Results / Emergent architecture] Control architecture section: the listed components (traveling-wave propulsion, yaw-rate feedback, signed mean-tail curvature, etc.) are presented as emergent and necessary, yet no ablation, sensitivity analysis, or removal experiments are described to show that each contributes measurably to generalization performance on held-out targets.
minor comments (2)
- [Introduction] The term 'dogfish swimmer' and the precise actuation model (joint angular accelerations only) would benefit from a short reference or diagram in the introduction for readers outside fluid dynamics.
- [Control architecture] Notation for quantities such as 'signed mean-tail curvature' and 'adaptive cadence relief' should be defined mathematically at first use to ensure reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed review. We address each major comment below and commit to revisions that strengthen the quantitative and evidentiary support for the claims.
read point-by-point responses
-
Referee: [Abstract / Results] Abstract and results section: the central generalization claim (no retraining, performance on unseen static targets and curved trajectories) is load-bearing but unsupported by any reported success rates, trajectory errors, or statistical comparisons between training and test conditions; without these metrics it is impossible to confirm that LLM-driven refinements causally improve dynamics rather than produce policies that merely match observed training targets.
Authors: We agree that the generalization claim requires explicit quantitative metrics. The revised manuscript will add a results subsection reporting success rates (fraction of targets reached within a defined tolerance), mean trajectory errors with standard deviations for training versus unseen static and curved targets, and statistical comparisons (e.g., paired t-tests) across multiple independent runs to demonstrate that the refinements produce genuine generalization rather than target-specific matching. revision: yes
-
Referee: [Methods / Workflow] Agent workflow description: the assertion that the LLM correctly diagnoses dynamic behaviors from multimodal simulation evidence and translates them into performance-improving code changes lacks concrete examples of the evidence traces, the exact diagnoses, and the resulting code diffs; this leaves open the possibility that refinements arise from pattern-matching to prior LLM knowledge rather than new physical reasoning.
Authors: We concur that concrete traces are needed to establish the reasoning chain. The revision will expand the methods and supplementary material with specific examples drawn from the evolve log: selected multimodal simulation outputs (e.g., trajectory plots, curvature time series, flow visualizations), the LLM's verbatim diagnostic statements linking those outputs to control deficiencies, and the exact unified-diff code changes that followed, thereby documenting the evidence-to-edit pathway. revision: yes
-
Referee: [Results / Emergent architecture] Control architecture section: the listed components (traveling-wave propulsion, yaw-rate feedback, signed mean-tail curvature, etc.) are presented as emergent and necessary, yet no ablation, sensitivity analysis, or removal experiments are described to show that each contributes measurably to generalization performance on held-out targets.
Authors: The components were introduced sequentially in the documented evolve log to correct diagnosed shortfalls in prior policies. To quantify their individual contributions, the revised manuscript will include sensitivity analyses in which each component is disabled in turn; we will report the resulting changes in success rate and trajectory error on the held-out target set, thereby providing measurable evidence of necessity. revision: yes
Circularity Check
No significant circularity: generalization demonstrated via external simulation feedback on unseen targets
full rationale
The paper describes an iterative LLM-driven code refinement workflow that uses multimodal simulation evidence to diagnose and update controller source code. The central claim of generalization to unseen static targets and curved trajectories is evaluated by direct deployment on held-out cases after evolution, not by fitting parameters to those cases or redefining the target metric in terms of the evolved policy. No equations, fitted inputs, or self-citation chains reduce the reported performance to the training targets by construction. The process is self-contained against external benchmarks (physical simulation runs) and does not rely on any of the enumerated circular patterns.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 1 Pith paper
-
Agentic Symbolic Search: Characterizing PDEs Beyond Hand-crafted Expressions, Meshes, and Neural Networks
ASYS recovers known analytical PDE forms and generates new interpretable symbolic approximations, such as a geometric interface formula for 2D Allen-Cahn and a nine-parameter contraction law for Keller-Segel blow-up, ...
Reference graph
Works this paper leans on
-
[1]
Jean Rabault, Miroslav Kuchta, Atle Jensen, Ulysse R´ eglade, and Nicolas Cerardi. Artificial neural networks trained through deep reinforcement learning discover control strategies for active flow control.Journal of Fluid Mechanics, 865:281–302, February 2019. ISSN 1469-7645. doi: 10.1017/jfm.2019.62. URLhttp://dx.doi.org/10.1017/jfm.2019.62
-
[2]
Siddhartha Verma, Guido Novati, and Petros Koumoutsakos. Efficient collective swimming by harnessing vortices through deep reinforcement learning.Proceedings of the National Academy of Sciences, 115(23):5849–5854, May 2018. ISSN 1091-6490. doi: 10.1073/pnas.1800923115. URLhttp://dx.doi.org/10.1073/pnas.1800923115
-
[3]
Triantafyllou, and George Em Karniadakis
Dixia Fan, Liu Yang, Zhicheng Wang, Michael S. Triantafyllou, and George Em Karniadakis. Reinforcement learning for bluff body active flow control in experiments and simulations. Proceedings of the National Academy of Sciences, 117(42):26091–26098, October 2020. ISSN 13 1091-6490. doi: 10.1073/pnas.2004939117. URL http://dx.doi.org/10.1073/pnas.200493 9117
-
[4]
C. Vignon, J. Rabault, and R. Vinuesa. Recent advances in applying deep reinforcement learning for flow control: Perspectives and future directions.Physics of Fluids, 35(3), March 2023. ISSN 1089-7666. doi: 10.1063/5.0143913. URLhttp://dx.doi.org/10.1063/5.0143913
-
[5]
Guido Novati, Hugues Lascombes de Laroussilhe, and Petros Koumoutsakos. Automating turbulence modelling by multi-agent reinforcement learning.Nature Machine Intelligence, 3(1):87–96, January 2021. ISSN 2522-5839. doi: 10.1038/s42256-020-00272-0. URL http://dx.doi.org/10.1038/s42256-020-00272-0
-
[6]
Steven L. Brunton, Bernd R. Noack, and Petros Koumoutsakos. Machine learning for fluid mechanics.Annual Review of Fluid Mechanics, 52:477–508, 2020. doi: 10.1146/annurev-fluid-0 10719-060214
-
[7]
Mankowitz, Jerry Li, Cosmin Paduraru, Sven Gowal, and Todd Hester
Gabriel Dulac-Arnold, Nir Levine, Daniel J. Mankowitz, Jerry Li, Cosmin Paduraru, Sven Gowal, and Todd Hester. Challenges of real-world reinforcement learning: definitions, benchmarks and analysis.Machine Learning, 110(9):2419–2468, April 2021. ISSN 1573-0565. doi: 10.1007/s109 94-021-05961-4. URLhttp://dx.doi.org/10.1007/s10994-021-05961-4
-
[8]
A survey on physics informed reinforcement learning: Review and open problems, 2023
Chayan Banerjee, Kien Nguyen, Clinton Fookes, and Maziar Raissi. A survey on physics informed reinforcement learning: Review and open problems, 2023. URL https://arxiv.or g/abs/2309.01909
arXiv 2023
-
[9]
M. Raissi, P. Perdikaris, and G.E. Karniadakis. Physics-informed neural networks: A deep learning framework for solving forward and inverse problems involving nonlinear partial differen- tial equations.Journal of Computational Physics, 378:686–707, February 2019. ISSN 0021-9991. doi: 10.1016/j.jcp.2018.10.045. URLhttp://dx.doi.org/10.1016/j.jcp.2018.10.045
-
[10]
Physics-informed machine learning,
George Em Karniadakis, Ioannis G. Kevrekidis, Lu Lu, Paris Perdikaris, Sifan Wang, and Liu Yang. Physics-informed machine learning.Nature Reviews Physics, 3(6):422–440, May 2021. ISSN 2522-5820. doi: 10.1038/s42254-021-00314-5. URL http://dx.doi.org/10.1038/s42 254-021-00314-5
-
[11]
Steven L. Brunton, Joshua L. Proctor, and J. Nathan Kutz. Discovering governing equations from data by sparse identification of nonlinear dynamical systems.Proceedings of the National Academy of Sciences, 113(15):3932–3937, March 2016. ISSN 1091-6490. doi: 10.1073/pnas.151 7384113. URLhttp://dx.doi.org/10.1073/pnas.1517384113
-
[12]
Peter Henderson, Riashat Islam, Philip Bachman, Joelle Pineau, Doina Precup, and David Meger. Deep reinforcement learning that matters.Proceedings of the AAAI Conference on Artificial Intelligence, 32(1), April 2018. ISSN 2159-5399. doi: 10.1609/aaai.v32i1.11694. URL http://dx.doi.org/10.1609/aaai.v32i1.11694
-
[13]
Pawan Kumar, Emilien Dupont, Francisco J
Bernardino Romera-Paredes, Mohammadamin Barekatain, Alexander Novikov, Matej Balog, M. Pawan Kumar, Emilien Dupont, Francisco J. R. Ruiz, Jordan S. Ellenberg, Pengming Wang, Omar Fawzi, Pushmeet Kohli, and Alhussein Fawzi. Mathematical discoveries from program search with large language models.Nature, 625(7995):468–475, December 2023. ISSN 1476-4687. doi:...
-
[14]
Le, Denny Zhou, and Xinyun Chen
Chengrun Yang, Xuezhi Wang, Yifeng Lu, Hanxiao Liu, Quoc V. Le, Denny Zhou, and Xinyun Chen. Large language models as optimizers, 2023. URL https://arxiv.org/abs/2309.03409
Pith/arXiv arXiv 2023
-
[15]
Eureka: Human-level reward design via coding large language models, 2023
Yecheng Jason Ma, William Liang, Guanzhi Wang, De-An Huang, Osbert Bastani, Dinesh Jayaraman, Yuke Zhu, Linxi Fan, and Anima Anandkumar. Eureka: Human-level reward design via coding large language models, 2023. URLhttps://arxiv.org/abs/2310.12931
Pith/arXiv arXiv 2023
-
[16]
Alexander Novikov, Ngˆ an V˜ u, Marvin Eisenberger, Emilien Dupont, Po-Sen Huang, Adam Zsolt Wagner, Sergey Shirobokov, Borislav Kozlovskii, Francisco J. R. Ruiz, Abbas Mehrabian, M. Pawan Kumar, Abigail See, Swarat Chaudhuri, George Holland, Alex Davies, Sebastian Nowozin, Pushmeet Kohli, and Matej Balog. Alphaevolve: A coding agent for scientific and al...
Pith/arXiv arXiv 2025
-
[17]
Boiko, Robert MacKnight, Ben Kline, and Gabe Gomes
Daniil A. Boiko, Robert MacKnight, Ben Kline, and Gabe Gomes. Autonomous chemical research with large language models.Nature, 624(7992):570–578, December 2023. ISSN 1476-
2023
-
[18]
A., MacKnight, R., Kline, B., and Gomes, G
doi: 10.1038/s41586-023-06792-0. URL http://dx.doi.org/10.1038/s41586-023-067 92-0
-
[19]
ImmFusion: Robust mmWave-RGB Fusion for 3D Human Body Reconstruction in All Weather Conditions,
Jacky Liang, Wenlong Huang, Fei Xia, Peng Xu, Karol Hausman, Brian Ichter, Pete Florence, and Andy Zeng. Code as policies: Language model programs for embodied control. In2023 IEEE International Conference on Robotics and Automation (ICRA), page 9493–9500. IEEE, May 2023. doi: 10.1109/icra48891.2023.10160591. URL http://dx.doi.org/10.1109/ICRA4 8891.2023.10160591
-
[20]
React: Synergizing reasoning and acting in language models, 2022
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, and Yuan Cao. React: Synergizing reasoning and acting in language models, 2022. URL https: //arxiv.org/abs/2210.03629
Pith/arXiv arXiv 2022
-
[21]
Xingang Guo, Darioush Keivan, Usman Syed, Lianhui Qin, Huan Zhang, Geir Dullerud, Peter Seiler, and Bin Hu. Controlagent: Automating control system design via novel integration of llm agents and domain expertise, 2024. URLhttps://arxiv.org/abs/2410.19811
arXiv 2024
-
[22]
Pde-controller: Llms for autoformalization and reasoning of pdes
Mauricio Soroco, Jialin Song, Mengzhou Xia, Kye Emond, Weiran Sun, and Wuyang Chen. Pde-controller: Llms for autoformalization and reasoning of pdes. InProceedings of the 42nd International Conference on Machine Learning (ICML), 2025. URL https://arxiv.org/abs/ 2502.00963
arXiv 2025
-
[23]
Learning beyond gradients
Jiayi Weng. Learning beyond gradients. https://trinkle23897.github.io/learning-bey ond-gradients/, May 2026. Blog post. Accessed: 2026-06-06
2026
-
[24]
Fossen.Handbook of Marine Craft Hydrodynamics and Motion Control
Thor I. Fossen.Handbook of Marine Craft Hydrodynamics and Motion Control. Wiley, April
-
[25]
ISBN 9781119994138. doi: 10.1002/9781119994138. URL http://dx.doi.org/10.1002 /9781119994138
-
[26]
Large-amplitude elongated-body theory of fish locomotion.Proceedings of the Royal Society of London
Michael James Lighthill. Large-amplitude elongated-body theory of fish locomotion.Proceedings of the Royal Society of London. Series B. Biological Sciences, 179(1055):125–138, November
-
[27]
ISSN 2053-9193. doi: 10.1098/rspb.1971.0085. URL http://dx.doi.org/10.1098/rsp b.1971.0085
-
[28]
M. J. Lighthill. Aquatic animal propulsion of high hydromechanical efficiency.Journal of Fluid Mechanics, 44(2):265–301, November 1970. ISSN 1469-7645. doi: 10.1017/s0022112070001830. URLhttp://dx.doi.org/10.1017/S0022112070001830. 15
-
[29]
M. S. Triantafyllou, G. S. Triantafyllou, and D. K. P. Yue. Hydrodynamics of fishlike swimming. Annual Review of Fluid Mechanics, 32(1):33–53, January 2000. ISSN 1545-4479. doi: 10.1146/ annurev.fluid.32.1.33. URLhttp://dx.doi.org/10.1146/annurev.fluid.32.1.33
-
[30]
Taylor, Robert L
Graham K. Taylor, Robert L. Nudds, and Adrian L. R. Thomas. Flying and swimming animals cruise at a strouhal number tuned for high power efficiency.Nature, 425(6959):707–711, October
-
[31]
ISSN 1476-4687. doi: 10.1038/nature02000. URL http://dx.doi.org/10.1038/natur e02000
-
[32]
U. K. Muller. Riding the waves: the role of the body wave in undulatory fish swimming. Integrative and Comparative Biology, 42(5):981–987, November 2002. ISSN 1557-7023. doi: 10.1093/icb/42.5.981. URLhttp://dx.doi.org/10.1093/icb/42.5.981
-
[33]
I. Borazjani and F. Sotiropoulos. On the role of form and kinematics on the hydrodynamics of self-propelled body/caudal fin swimming.Journal of Experimental Biology, 213(1):89–107, January 2010. ISSN 0022-0949. doi: 10.1242/jeb.030932. URL http://dx.doi.org/10.1242 /jeb.030932
-
[34]
Mattia Gazzola, Mederic Argentina, and L. Mahadevan. Scaling macroscopic aquatic locomotion. Nature Physics, 10(10):758–761, 2014. doi: 10.1038/nphys3078
-
[35]
Evolutionary ensemble of agents, 2026
Zongmin Yu and Liu Yang. Evolutionary ensemble of agents, 2026. URL https://arxiv.or g/abs/2605.09018
Pith/arXiv arXiv 2026
-
[36]
M. J. Lighthill. Note on the swimming of slender fish.Journal of Fluid Mechanics, 9(2): 305–317, October 1960. ISSN 1469-7645. doi: 10.1017/s0022112060001110. URL http: //dx.doi.org/10.1017/S0022112060001110
-
[37]
Analysis of the swimming of long and narrow animals.Proceedings of the Royal Society of London
Geoffrey Ingram Taylor. Analysis of the swimming of long and narrow animals.Proceedings of the Royal Society of London. Series A. Mathematical and Physical Sciences, 214(1117):158–183, August 1952. ISSN 2053-9169. doi: 10.1098/rspa.1952.0159. URL http://dx.doi.org/10.10 98/rspa.1952.0159
-
[38]
M. Sfakiotakis, D.M. Lane, and J.B.C. Davies. Review of fish swimming modes for aquatic locomotion.IEEE Journal of Oceanic Engineering, 24(2):237–252, April 1999. ISSN 0364-9059. doi: 10.1109/48.757275. URLhttp://dx.doi.org/10.1109/48.757275
-
[39]
J. M. ANDERSON, K. STREITLIEN, D. S. BARRETT, and M. S. TRIANTAFYLLOU. Oscillating foils of high propulsive efficiency.Journal of Fluid Mechanics, 360:41–72, April
-
[40]
doi: 10.1017/s0022112097008392
ISSN 1469-7645. doi: 10.1017/s0022112097008392. URL http://dx.doi.org/10.1017 /S0022112097008392
-
[41]
Daniel Floryan, Tyler Van Buren, and Alexander J. Smits. Efficient cruising for swimming and flying animals is dictated by fluid drag.Proceedings of the National Academy of Sciences, 115(32):8116–8118, June 2018. ISSN 1091-6490. doi: 10.1073/pnas.1805941115. URL http://dx.doi.org/10.1073/pnas.1805941115
-
[42]
Paolo Domenici and Robert W. Blake. The kinematics and performance of fish fast-start swimming.Journal of Experimental Biology, 200(8):1165–1178, April 1997. ISSN 1477-9145. doi: 10.1242/jeb.200.8.1165. URLhttp://dx.doi.org/10.1242/jeb.200.8.1165. 16
-
[43]
Auke Jan Ijspeert. Central pattern generators for locomotion control in animals and robots: A review.Neural Networks, 21(4):642–653, May 2008. ISSN 0893-6080. doi: 10.1016/j.neunet.200 8.03.014. URLhttp://dx.doi.org/10.1016/j.neunet.2008.03.014
-
[44]
Katzschmann, Joseph DelPreto, Robert MacCurdy, and Daniela Rus
Robert K. Katzschmann, Joseph DelPreto, Robert MacCurdy, and Daniela Rus. Exploration of underwater life with an acoustically controlled soft robotic fish.Science Robotics, 3(16), March 2018. ISSN 2470-9476. doi: 10.1126/scirobotics.aar3449. URL http://dx.doi.org/10. 1126/scirobotics.aar3449
-
[45]
Gabriel D. Weymouth and Bernat Font. Waterlily.jl: A differentiable and backend-agnostic julia solver for incompressible viscous flow around dynamic bodies.Computer Physics Commu- nications, 315:109748, 2025. ISSN 0010-4655. doi: https://doi.org/10.1016/j.cpc.2025.109748. URLhttps://www.sciencedirect.com/science/article/pii/S0010465525002504
-
[46]
Maertens, Amy Gao, and Michael S
Audrey P. Maertens, Amy Gao, and Michael S. Triantafyllou. Optimal undulatory swimming for a single fish-like body and for a pair of interacting swimmers.Journal of Fluid Mechanics, 813:301–345, January 2017. ISSN 1469-7645. doi: 10.1017/jfm.2016.845. URL http: //dx.doi.org/10.1017/jfm.2016.845
-
[47]
On the best design for undulatory swimming.Journal of Fluid Mechanics, 717:48–89, February 2013
Christophe Eloy. On the best design for undulatory swimming.Journal of Fluid Mechanics, 717:48–89, February 2013. ISSN 1469-7645. doi: 10.1017/jfm.2012.561. URL http://dx.doi .org/10.1017/jfm.2012.561. 17
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.