Lynx: Enabling Efficient MoE Inference through Dynamic Batch-Aware Expert Selection
Pith reviewed 2026-05-23 17:01 UTC · model grok-4.3
The pith
LYNX remaps low-affinity token-to-expert assignments in MoE batches to invoke fewer experts and reach up to 1.30x throughput with under 1% accuracy loss.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
LYNX leverages a key property of MoE training: load-balancing losses introduce batch-level expert activation skews and redundancy, which it exploits by remapping low-affinity token-to-expert assignments within each batch using a novel AffinityBinning technique that reduces the total experts invoked. Our evaluation of LYNX on four state-of-the-art model families across nine benchmarks shows that it achieves up to 1.30x improvement in throughput while maintaining accuracy loss of less than 1% points across tasks. Further, LYNX is complementary to existing techniques where it additionally boosts their performance by up to 1.38x.
What carries the argument
AffinityBinning technique that remaps low-affinity token-to-expert assignments within each batch to exploit activation skews from training
If this is right
- Up to 1.30x throughput improvement across evaluated MoE models
- Accuracy loss stays below 1 percentage point on nine benchmarks
- Adds up to 1.38x extra speedup when layered on existing inference methods
- Works workload-agnostically on four model families without per-task adjustments
Where Pith is reading between the lines
- Serving systems could adopt dynamic remapping as a standard post-training layer to relax memory-bandwidth limits.
- Training objectives might be adjusted to deliberately strengthen batch skews for inference gains.
- Similar remapping logic could transfer to other sparse-activation architectures beyond standard MoE.
- Hardware schedulers might expose batch-level expert affinity data to enable such optimizations at runtime.
Load-bearing premise
Remapping low-affinity assignments inside batches preserves accuracy within 1% and the batch-level skews created by load-balancing losses are consistent enough to exploit across workloads without tuning.
What would settle it
Run LYNX on an MoE model trained without any load-balancing loss and measure whether the reduction in invoked experts and the sub-1% accuracy bound still hold.
Figures





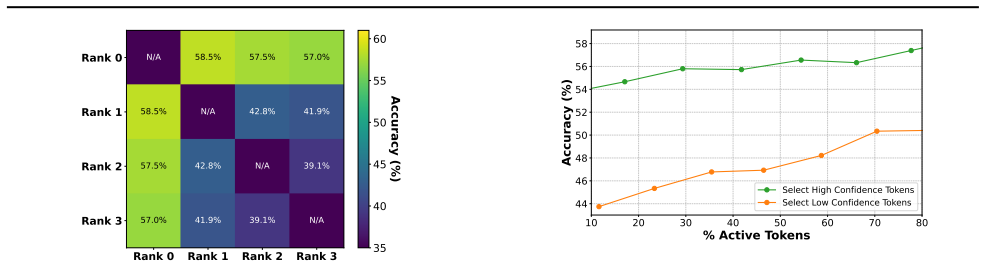



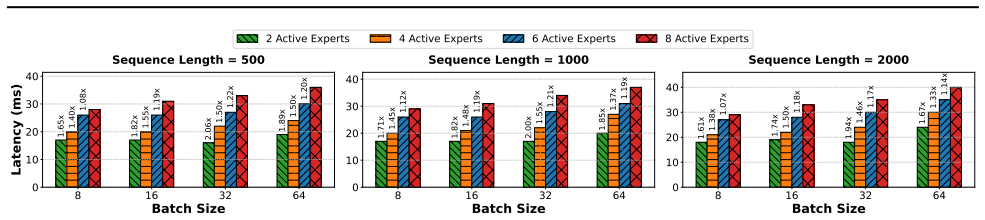

read the original abstract
Selective parameter activation provided by Mixture-of-Expert (MoE) models have made them a popular choice in modern foundational models. However, MoEs face a fundamental tension when employed for serving. Batching, critical for performance in serving, forces the activation of all experts, thereby negating MoEs' benefits and exacerbating memory bandwidth bottlenecks. Existing work on efficient MoE inference are unable to resolve this tension even with extensive workload-specific tuning. We present LYNX, a system that enables efficient MoE inference in a workload-agnostic fashion. LYNX leverages a key property of MoE training: load-balancing losses introduce batch-level expert activation skews and redundancy, which it exploits by remapping low-affinity token-to-expert assignments within each batch using a novel AffinityBinning technique that reduces the total experts invoked. Our evaluation of LYNX on four state-of-the-art model families across nine benchmarks shows that it achieves up to 1.30x improvement in throughput while maintaining accuracy loss of less than 1% points across tasks. Further, LYNX is complementary to existing techniques where it additionally boosts their performance by up to 1.38x.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents LYNX, a system for efficient MoE inference that exploits batch-level expert activation skews and redundancy induced by load-balancing losses during training. It introduces AffinityBinning to remap low-affinity token-to-expert assignments within each batch, reducing the total experts invoked per batch. The central claim is that this yields up to 1.30x throughput improvement while keeping accuracy loss below 1 percentage point across four model families and nine benchmarks, and that it is complementary to prior techniques (up to 1.38x additional boost).
Significance. If the accuracy preservation claim holds under the stated conditions, the result would be significant for MoE serving: it addresses the fundamental batching tension without requiring workload-specific tuning. The evaluation span across multiple model families is a positive aspect of the empirical component.
major comments (2)
- [Abstract, §4] Abstract and §4 (Evaluation): the central performance claim (1.30x throughput, <1% accuracy loss) is reported without details on experimental setup, statistical significance testing, exact per-task accuracy metrics, or controls for post-hoc benchmark selection. This leaves the soundness of the accuracy bound difficult to assess.
- [§3] §3 (AffinityBinning description): the remapping operator is presented as preserving output distribution up to <1% drop, but no derivation, correlation analysis, or forward-pass commutativity argument is given showing why low-affinity experts (identified via the training-induced skew) carry only redundant signal for arbitrary inference inputs. The assumption that batch-level redundancy is stable and safely exploitable across workloads is load-bearing for the accuracy claim yet remains heuristic.
minor comments (2)
- [§3] Notation for affinity scores and binning thresholds should be defined with explicit equations rather than prose descriptions to improve reproducibility.
- [§4] Figure captions and axis labels in the throughput/accuracy plots would benefit from explicit mention of batch sizes and model scales used.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major point below and indicate where revisions will be made to improve clarity and rigor.
read point-by-point responses
-
Referee: [Abstract, §4] Abstract and §4 (Evaluation): the central performance claim (1.30x throughput, <1% accuracy loss) is reported without details on experimental setup, statistical significance testing, exact per-task accuracy metrics, or controls for post-hoc benchmark selection. This leaves the soundness of the accuracy bound difficult to assess.
Authors: Section 4 already specifies the four model families, nine benchmarks, hardware platform, and throughput measurement methodology. We agree that the presentation would be strengthened by adding (i) per-task accuracy tables with exact deltas, (ii) standard deviations over three runs to support the <1% claim, and (iii) an explicit statement that the benchmark suite was chosen a priori from prior MoE literature rather than post-hoc. These additions will be incorporated in the revised §4 and an expanded abstract footnote. revision_made = yes. revision: yes
-
Referee: [§3] §3 (AffinityBinning description): the remapping operator is presented as preserving output distribution up to <1% drop, but no derivation, correlation analysis, or forward-pass commutativity argument is given showing why low-affinity experts (identified via the training-induced skew) carry only redundant signal for arbitrary inference inputs. The assumption that batch-level redundancy is stable and safely exploitable across workloads is load-bearing for the accuracy claim yet remains heuristic.
Authors: Section 3 motivates AffinityBinning from the empirical observation that load-balancing losses create stable batch-level skews; the accuracy results in §4 serve as the primary validation. We acknowledge that a formal derivation or commutativity proof is absent because the method is fundamentally empirical. In revision we will add a short correlation analysis (token affinity vs. expert output magnitude) in an appendix to quantify the redundancy assumption. The core claim will remain that the technique is workload-agnostic and empirically robust across the evaluated models, not that it is theoretically guaranteed for all inputs. revision_made = partial. revision: partial
Circularity Check
No circularity; empirical system with external validation
full rationale
The paper describes an inference optimization technique (AffinityBinning) that exploits an observed training-time property of load-balancing losses in MoE models. The central claim of <1% accuracy loss is supported by empirical evaluation across four model families and nine benchmarks rather than any derivation. No equations, self-definitional mappings, fitted parameters renamed as predictions, or load-bearing self-citations appear in the abstract or described approach. The method is workload-agnostic by design and complementary to prior techniques, with no reduction of outputs to inputs by construction.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 2 Pith papers
-
Patterns behind Chaos: Forecasting Data Movement for Efficient Large-Scale MoE LLM Inference
Comprehensive profiling of expert selection in frontier MoE models reveals temporal and spatial patterns that enable 6.6x speedup on wafer-scale GPUs and 1.25x on existing systems via targeted optimizations.
-
LayerScope: Predictive Cross-Layer Scheduling for Efficient Multi-Batch MoE Inference on Legacy Servers
PreScope combines a layer-aware activation predictor, cross-layer prefetch scheduling, and asynchronous I/O to deliver 141% higher throughput and 74.6% lower latency for MoE inference on legacy hardware.
Reference graph
Works this paper leans on
-
[1]
URL https://api.semanticscholar. org/CorpusID:268249103. Anthropic. Claude, 2024. URL https://claude.ai/. Accessed: 2024-10-31. Bojar, O., Chatterjee, R., Federmann, C., Graham, Y ., Had- dow, B., Huck, M., Jimeno-Yepes, A., Koehn, P., Lo- gacheva, V ., Monz, C., Negri, M., N ´ev´eol, A., Neves, M., Popel, M., Post, M., Rubino, R., Scarton, C., Spe- cia, ...
work page 2024
-
[2]
Evaluating Large Language Models Trained on Code
URL https://api.semanticscholar. org/CorpusID:14421595. Chen, M., Tworek, J., Jun, H., Yuan, Q., Pond´e, H., Kaplan, J., Edwards, H., Burda, Y ., Joseph, N., Brockman, G., Ray, A., Puri, R., Krueger, G., Petrov, M., Khlaaf, H., Sastry, G., Mishkin, P., Chan, B., Gray, S., Ryder, N., Pavlov, M., Power, A., Kaiser, L., Bavarian, M., Winter, C., Tillet, P., ...
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
URL https://api.semanticscholar. org/CorpusID:235755472. Chen, T., Huang, S., Xie, Y ., Jiao, B., Jiang, D., Zhou, H., Li, J., and Wei, F. Task-specific expert pruning for sparse mixture-of-experts. ArXiv, abs/2206.00277,
-
[4]
URL https://api.semanticscholar. org/CorpusID:249240535. Chen, T., Zhang, Z. A., Jaiswal, A., Liu, S., and Wang, Z. Sparse moe as the new dropout: Scaling dense and self-slimmable transformers. ArXiv, abs/2303.01610,
-
[5]
Training Verifiers to Solve Math Word Problems
URL https://api.semanticscholar. org/CorpusID:257353502. Cobbe, K., Kosaraju, V ., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., Hesse, C., and Schulman, J. Training verifiers to solve math word problems. ArXiv, abs/2110.14168,
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
URL https://api.semanticscholar. org/CorpusID:239998651. Do, G., Khiem, L., Pham, Q. H., Nguyen, T., Doan, T.-N., Nguyen, B., Liu, C., Ramasamy, S., Li, X., and Hoi, S. C. H. Hyperrouter: Towards efficient training and infer- ence of sparse mixture of experts. ArXiv, abs/2312.07035,
-
[7]
URL https://api.semanticscholar. org/CorpusID:266163896. Eliseev, A. and Mazur, D. Fast inference of mixture-of-experts language models with offload- ing. ArXiv, abs/2312.17238, 2023. URL https: //api.semanticscholar.org/CorpusID: 266573098. Fedus, W., Zoph, B., and Shazeer, N. Switch transformers: scaling to trillion parameter models with simple and ef- ...
-
[8]
URL https://api.semanticscholar. org/CorpusID:270869609. He, S., Dong, D., Ding, L., and Li, A. Demystifying the compression of mixture-of-experts through a unified framework, 2024. URL https://arxiv.org/abs/ 2406.02500. Huang, H., Ardalani, N., Sun, A., Ke, L., Lee, H.-H. S., Sridhar, A., Bhosale, S., Wu, C.-J., and Lee, B. Towards moe deployment: Mitiga...
-
[9]
URL https://api.semanticscholar. org/CorpusID:257496628. Jiang, A. Q., Sablayrolles, A., Roux, A., Mensch, A., Savary, B., Bamford, C., Chaplot, D. S., de Las Casas, D., Hanna, E. B., Bressand, F., Lengyel, G., Bour, G., Lample, G., Lavaud, L. R., Saulnier, L., Lachaux, M.-A., Stock, P., Subramanian, S., Yang, S., Antoniak, S., Scao, T. L., Gervet, T., La...
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
URL https://api.semanticscholar. org/CorpusID:266844877. Kamahori, K., Gu, Y ., Zhu, K., and Kasikci, B. Fid- dler: Cpu-gpu orchestration for fast inference of mixture-of-experts models. ArXiv, abs/2402.07033,
-
[11]
Scaling Laws for Neural Language Models
URL https://api.semanticscholar. org/CorpusID:267627732. Kaplan, J., McCandlish, S., Henighan, T., Brown, T. B., Chess, B., Child, R., Gray, S., Radford, A., Wu, J., and Amodei, D. Scaling laws for neural language models. ArXiv, abs/2001.08361,
work page internal anchor Pith review Pith/arXiv arXiv 2001
-
[12]
GShard: Scaling Giant Models with Conditional Computation and Automatic Sharding
URL https://api.semanticscholar. org/CorpusID:210861095. Kwon, W., Li, Z., Zhuang, S., Sheng, Y ., Zheng, L., Yu, C. H., Gonzalez, J. E., Zhang, H., and Stoica, I. Efficient memory management for large language model serving with pagedattention. In Proceedings of the ACM SIGOPS 29th Symposium on Operating Systems Principles, 2023. Lepikhin, D., Lee, H., X...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[13]
URL https://api.semanticscholar. org/CorpusID:220265858. Li, P., Zhang, Z. A., Yadav, P., Sung, Y .-L., Cheng, Y ., Bansal, M., and Chen, T. Merge, then compress: Demystify efficient smoe with hints from its routing policy. ArXiv, abs/2310.01334,
-
[14]
URL https://api.semanticscholar. org/CorpusID:263605809. Lin, J., Tang, J., Tang, H., Yang, S., Chen, W.-M., Wang, W.-C., Xiao, G., Dang, X., Gan, C., and Han, S. Awq: Activation-aware weight quantization for llm compres- sion and acceleration. In MLSys, 2024. Lin, S. C., Hilton, J., and Evans, O. Truthfulqa: Measur- ing how models mimic human falsehoods....
work page 2024
-
[15]
URL https://api.semanticscholar. org/CorpusID:237532606. Lu, X., Liu, Q., Xu, Y ., Zhou, A., Huang, S., Zhang, B., Yan, J., and Li, H. Not all experts are equal: Efficient expert pruning and skipping for mixture-of- experts large language models. ArXiv, abs/2402.14800,
-
[16]
URL https://api.semanticscholar. org/CorpusID:267782440. Luo, X., Rechardt, A., Sun, G., Nejad, K. K., Y ´a˜nez, F., Yilmaz, B., Lee, K., Cohen, A. O., Borghesani, V ., Pashkov, A., Marinazzo, D., Nicholas, J., Salatiello, A., Sucholutsky, I., Minervini, P., Razavi, S., Rocca, R., Yusifov, E., Okalova, T., Gu, N., Ferianc, M., Khona, M., Patil, K. R., Lee...
-
[17]
URL https://api.semanticscholar. org/CorpusID:268253470. Mosaic. Introducing dbrx: A new state- of-the-art open llm, March 2024. URL https://www.databricks.com/blog/ introducing-dbrx-new-state-art-open-llm . Accessed: 2024-10-30. Muzio, A., Sun, A., and He, C. Seer-moe: Sparse expert efficiency through regularization for mixture-of- experts. ArXiv, abs/24...
-
[18]
URL https://api.semanticscholar. org/CorpusID:267211688. Yin, Z., Sun, Q., Guo, Q., Zeng, Z., Li, X., Sun, T., Chang, C., Cheng, Q., Wang, D., Mou, X., Qiu, X., and Huang, X. Aggregation of reasoning: A hierarchical framework for enhancing answer se- lection in large language models. In International Conference on Language Resources and Evaluation ,
-
[19]
URL https://api.semanticscholar. org/CorpusID:269804400. Yu, G.-I. and Jeong, J. S. Orca: A distributed serving system for transformer-based generative models. In USENIX Symposium on Operating Systems De- sign and Implementation , 2022. URL https: //api.semanticscholar.org/CorpusID: 251734964. Yun, L., Zhuang, Y ., Fu, Y ., Xing, E. P., and Zhang, H. Towa...
- [20]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.