Patterns behind Chaos: Forecasting Data Movement for Efficient Large-Scale MoE LLM Inference
Pith reviewed 2026-05-18 09:49 UTC · model grok-4.3
The pith
Profiling data movement in large MoE models uncovers six patterns that reduce serving bottlenecks and deliver substantial speedups.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
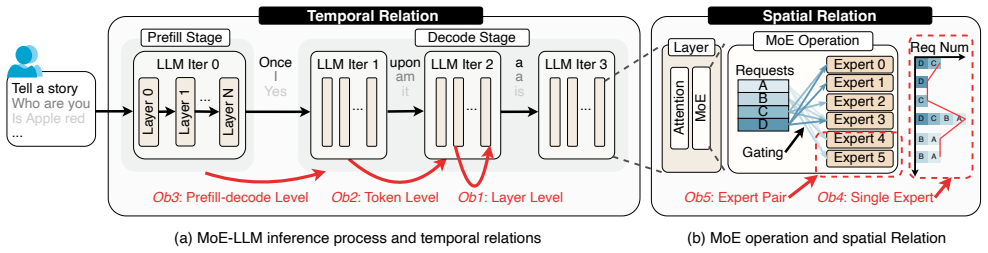
Comprehensive data-movement-centric profiling of state-of-the-art large-scale MoE models reveals consistent patterns in expert activation. From temporal and spatial perspectives the authors distill six key insights. These insights guide lightweight architectural changes on wafer-scale GPUs and a prefill-aware expert placement algorithm on existing GPUs, producing measured speedups of 6.6 times on average and up to 1.25 times respectively.
What carries the argument
Six distilled insights from temporal and spatial analysis of expert selection traces that identify repeatable patterns in data movement and guide placement and architectural decisions.
If this is right
- Lightweight architectural modifications on wafer-scale GPUs produce a 6.6 times average speedup across the four tested 200B-1000B models.
- A prefill-aware expert placement algorithm derived from the insights achieves up to 1.25 times speedup on MoE computation on existing GPU systems.
- The insights apply across diverse workloads spanning the 24,000 profiled requests.
- The same analysis framework can be reused on future model releases to generate new placement or hardware designs.
Where Pith is reading between the lines
- The patterns could be used to build predictive prefetching logic that anticipates expert needs before the current token batch.
- Combining the placement algorithm with existing expert parallelism techniques might further reduce inter-node traffic in multi-rack deployments.
- If the temporal patterns prove stable, online monitoring of recent expert choices could dynamically adjust placement without full re-profiling.
Load-bearing premise
The six patterns observed on the profiled workloads and current model scales will continue to hold and produce similar speedups on other workloads, larger future models, and real production serving conditions.
What would settle it
Run the same profiling on a new 500B+ MoE model with a different routing scheme or workload distribution and measure whether the reported speedups from the derived placement algorithm or modifications drop below 1.1 times.
Figures












read the original abstract
Large-scale Mixture of Experts (MoE) Large Language Models (LLMs) have recently become the frontier open-weight models, achieving remarkable model capability similar to proprietary ones. But their random expert selection mechanism introduces significant data movement overhead that becomes the dominant bottleneck in multi-unit LLM serving systems. To understand the patterns underlying this data movement, we conduct comprehensive data-movement-centric profiling across four state-of-the-art large-scale MoE models released in 2025 (200B-1000B) using over 24,000 requests spanning diverse workloads. We perform systematic analysis from both temporal and spatial perspectives and distill six key insights to guide the design of diverse serving systems. We verify these insights on both future wafer-scale GPU architectures and existing GPU systems. On wafer-scale GPUs, lightweight architectural modifications guided by our insights yield a 6.6$\times$ average speedup across four 200B--1000B models. On existing GPU systems, our insights drive the design of a prefill-aware expert placement algorithm that achieves up to 1.25$\times$ speedup on MoE computation. Our work presents the first comprehensive data-centric analysis of large-scale MoE models together with a concrete design study applying the learned lessons. Our profiling traces are publicly available at \href{https://huggingface.co/datasets/core12345/MoE_expert_selection_trace}{\textcolor{blue}{https://huggingface.co/datasets/core12345/MoE\_expert\_selection\_trace}}.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper conducts comprehensive profiling of data movement in four large-scale MoE LLMs (200B-1000B) using 24,000 requests. It distills six key insights from temporal and spatial analysis to guide serving system design. These insights lead to lightweight modifications yielding 6.6× speedup on wafer-scale GPUs and a prefill-aware placement algorithm with 1.25× speedup on existing systems. Profiling traces are publicly released.
Significance. This work addresses a critical bottleneck in large MoE LLM inference by providing data-centric insights. The reported speedups demonstrate practical impact if the insights hold. Public traces enhance reproducibility. The significance hinges on whether the patterns generalize beyond the studied models and workloads.
major comments (2)
- §4: The six distilled insights are derived from the profiled 2025 models and workloads without reported cross-validation on alternate request distributions, routing strategies (e.g., top-k variants), or model scales; this is load-bearing for the claim that the insights guide design for diverse serving systems.
- §6.1, wafer-scale results: The 6.6× average speedup is obtained via simulated architectural modifications; the manuscript does not detail how the simulation captures realistic interconnect and memory hierarchy costs or whether the modifications introduce unaccounted overheads.
minor comments (2)
- The methods section should explicitly state the workload selection criteria and the exact composition (e.g., request length distributions, batch sizes) of the 24k requests to allow assessment of representativeness.
- Figure captions and axis labels in the spatial/temporal analysis sections would benefit from additional detail on the units and normalization used for data-movement volume.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below and describe the revisions we will make to strengthen the manuscript.
read point-by-point responses
-
Referee: §4: The six distilled insights are derived from the profiled 2025 models and workloads without reported cross-validation on alternate request distributions, routing strategies (e.g., top-k variants), or model scales; this is load-bearing for the claim that the insights guide design for diverse serving systems.
Authors: We acknowledge that the primary analysis is performed on the four 2025 models (200B–1000B) and the 24,000-request workloads described in the manuscript. These models already span a substantial range of scales and exhibit different expert-selection behaviors. The six insights are presented as observations from this data rather than universal claims. To address the concern directly, we will revise §4 to add an explicit discussion of the studied models’ diversity, note the absence of exhaustive cross-validation on alternate top-k variants or request distributions, and include a short analysis applying the insights to a small set of additional traces with varied request patterns drawn from the public dataset. We will also qualify the guidance for serving-system design accordingly. revision: partial
-
Referee: §6.1, wafer-scale results: The 6.6× average speedup is obtained via simulated architectural modifications; the manuscript does not detail how the simulation captures realistic interconnect and memory hierarchy costs or whether the modifications introduce unaccounted overheads.
Authors: We appreciate the referee highlighting the need for greater transparency in the simulation. The results in §6.1 are produced by a cycle-level simulator that incorporates published wafer-scale interconnect bandwidth figures and memory-access latencies. In the revised manuscript we will expand the methodology subsection to describe (1) how the interconnect topology and bandwidth are modeled, (2) how memory-hierarchy costs are accounted for, and (3) an overhead analysis of the proposed lightweight modifications together with sensitivity results showing that the reported speedups remain robust under reasonable variations in these parameters. revision: yes
Circularity Check
Empirical profiling study; speedups are direct measurements, not derived quantities
full rationale
The paper conducts data-movement profiling on four 2025 MoE models using 24k requests, distills six insights from observed temporal/spatial patterns, and reports measured speedups from architectural modifications and a placement algorithm. No equations, fitted parameters, or first-principles derivations are presented; claims rest on empirical observation and verification rather than any reduction to inputs by construction. No self-citation chains or ansatzes are load-bearing for the central results.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We perform systematic analysis from both temporal and spatial perspectives and distill six key insights... prefill-aware expert placement algorithm that achieves up to 1.25× speedup
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanembed_strictMono_of_one_lt unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
layer-level temporal correlation heatmaps... token-level... prefill-decode-level
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 1 Pith paper
-
Replication in Graph Partitioning and Scheduling Problems
Replication reduces costs by 17-65% on average in hypergraph partitioning and 11-23% in DAG scheduling, sometimes eliminating communication needs entirely.
Reference graph
Works this paper leans on
-
[1]
J. Achiam, S. Adler, S. Agarwal, L. Ahmad, I. Akkaya, F. L. Aleman, D. Almeida, J. Altenschmidt, S. Altman, S. Anadkatet al., “Gpt-4 technical report,”arXiv, 2023
work page 2023
-
[2]
Analyzing cuda workloads using a detailed gpu simulator,
A. Bakhoda, G. L. Yuan, W. W. Fung, H. Wong, and T. M. Aamodt, “Analyzing cuda workloads using a detailed gpu simulator,” in2009 IEEE international symposium on performance analysis of systems and software, 2009
work page 2009
-
[3]
N. Binkert, B. Beckmann, G. Black, S. K. Reinhardt, A. Saidi, A. Basu, J. Hestness, D. R. Hower, T. Krishna, S. Sardashtiet al., “The gem5 simulator,”ACM SIGARCH computer architecture news, 2011
work page 2011
-
[4]
Moe-lightning: High-throughput moe inference on memory-constrained gpus,
S. Cao, S. Liu, T. Griggs, P. Schafhalter, X. Liu, Y . Sheng, J. E. Gon- zalez, M. Zaharia, and I. Stoica, “Moe-lightning: High-throughput moe inference on memory-constrained gpus,” inProceedings of the 30th ACM International Conference on Architectural Support for Programming Languages and Operating Systems, 2025
work page 2025
-
[5]
S. Chen, S. Pal, and R. Kumar, “Waferscale network switches,” in 2024 ACM/IEEE 51st Annual International Symposium on Computer Architecture (ISCA). IEEE, 2024, pp. 215–229
work page 2024
-
[6]
Chatbot arena: An open platform for evaluating llms by human preference,
W.-L. Chiang, L. Zheng, Y . Sheng, A. N. Angelopoulos, T. Li, D. Li, B. Zhu, H. Zhang, M. Jordan, J. E. Gonzalezet al., “Chatbot arena: An open platform for evaluating llms by human preference,” inForty-first International Conference on Machine Learning, 2024
work page 2024
-
[7]
Lexi: Layer-adaptive active experts for efficient moe model inference,
K. T. Chitty-Venkata, S. Madireddy, M. Emani, and V . Vishwanath, “Lexi: Layer-adaptive active experts for efficient moe model inference,” arXiv preprint arXiv:2509.02753, 2025
-
[8]
DeepSeekMoE: Towards Ultimate Expert Specialization in Mixture-of-Experts Language Models
D. Dai, C. Deng, C. Zhao, R. Xu, H. Gao, D. Chen, J. Li, W. Zeng, X. Yu, Y . Wuet al., “Deepseekmoe: Towards ultimate expert spe- cialization in mixture-of-experts language models,”arXiv preprint arXiv:2401.06066, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[9]
Cpelide: Efficient multi- chiplet gpu implicit synchronization,
P. Dalmia, R. S. Kumar, and M. D. Sinclair, “Cpelide: Efficient multi- chiplet gpu implicit synchronization,” in2024 57th IEEE/ACM Interna- tional Symposium on Microarchitecture (MICRO), 2024
work page 2024
-
[10]
A complete survey on llm-based ai chatbots,
S. K. Dam, C. S. Hong, Y . Qiao, and C. Zhang, “A complete survey on llm-based ai chatbots,”arXiv, 2024
work page 2024
-
[11]
Z. Du, S. Li, Y . Wu, X. Jiang, J. Sun, Q. Zheng, Y . Wu, A. Li, H. Li, and Y . Chen, “Sida: Sparsity-inspired data-aware serving for efficient and scalable large mixture-of-experts models,”Proceedings of Machine Learning and Systems, vol. 6, pp. 224–238, 2024
work page 2024
-
[12]
Fast inference of mixture-of-experts language models with offloading,
A. Eliseev and D. Mazur, “Fast inference of mixture-of-experts language models with offloading,”arXiv preprint arXiv:2312.17238, 2023
-
[13]
Klotski: Efficient mixture-of-expert inference via expert- aware multi-batch pipeline,
Z. Fang, Y . Huang, Z. Hong, Y . Lyu, W. Chen, Y . Yu, F. Yu, and Z. Zheng, “Klotski: Efficient mixture-of-expert inference via expert- aware multi-batch pipeline,” inProceedings of the 30th ACM Interna- tional Conference on Architectural Support for Programming Languages and Operating Systems, Volume 2, 2025
work page 2025
-
[14]
Heterogeneous die-to-die interfaces: Enabling more flexible chiplet interconnection systems,
Y . Feng, D. Xiang, and K. Ma, “Heterogeneous die-to-die interfaces: Enabling more flexible chiplet interconnection systems,” inProceedings of the 56th Annual IEEE/ACM International Symposium on Microarchi- tecture, 2023, pp. 930–943
work page 2023
-
[15]
A scalable methodology for designing efficient interconnection network of chiplets,
——, “A scalable methodology for designing efficient interconnection network of chiplets,” in2023 IEEE International Symposium on High- Performance Computer Architecture (HPCA). IEEE, 2023, pp. 1059– 1071
work page 2023
-
[16]
S. T. from LMSYS Org. (2025) Deploying deepseek with pd disaggregation and large-scale expert parallelism on 96 h100 gpus. [Online]. Available: https://lmsys.org/blog/2025-05-05-large-scale-ep/
work page 2025
-
[17]
(2025) Together with sglang: Best practices for serving deepseek- r1 on h20-96g
——. (2025) Together with sglang: Best practices for serving deepseek- r1 on h20-96g. [Online]. Available: https://lmsys.org/blog/2025-09-26- sglang-ant-group/
work page 2025
-
[18]
S. Go and D. Mahajan, “Moetuner: Optimized mixture of expert serving with balanced expert placement and token routing,”arXiv preprint arXiv:2502.06643, 2025
-
[19]
Lynx: Enabling efficient moe inference through dynamic batch-aware expert selection,
V . Gupta, K. Sinha, A. Gavrilovska, and A. P. Iyer, “Lynx: Enabling efficient moe inference through dynamic batch-aware expert selection,” arXiv preprint arXiv:2411.08982, 2024
-
[20]
Lost in abstraction: Pitfalls of analyzing gpus at the intermediate language level,
A. Gutierrez, B. M. Beckmann, A. Dutu, J. Gross, M. LeBeane, J. Kala- matianos, O. Kayiran, M. Poremba, B. Potter, S. Puthooret al., “Lost in abstraction: Pitfalls of analyzing gpus at the intermediate language level,” in2018 IEEE International Symposium on High Performance Computer Architecture (HPCA), 2018
work page 2018
-
[21]
Waferllm: Large language model inference at wafer scale,
C. He, Y . Huang, P. Mu, Z. Miao, J. Xue, L. Ma, F. Yang, and L. Mai, “Waferllm: Large language model inference at wafer scale,” in19th USENIX Symposium on Operating Systems Design and Implementation (OSDI 25). USENIX Association, 2025
work page 2025
-
[22]
Chinese simpleqa: A chinese factuality evaluation for large language models,
Y . He, S. Li, J. Liu, Y . Tan, W. Wang, H. Huang, X. Bu, H. Guo, C. Hu, B. Zhenget al., “Chinese simpleqa: A chinese factuality evaluation for large language models,”arXiv preprint arXiv:2411.07140, 2024
-
[23]
Measuring Massive Multitask Language Understanding
D. Hendrycks, C. Burns, S. Basart, A. Zou, M. Mazeika, D. Song, and J. Steinhardt, “Measuring massive multitask language understanding,” arXiv preprint arXiv:2009.03300, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2009
-
[24]
S. Hou, W. C. Chen, C. Hu, C. Chiu, K. Ting, T. Lin, W. Wei, W. Chiou, V . J. Lin, V . C. Changet al., “Wafer-level integration of an advanced logic-memory system through the second-generation cowos technology,” IEEE Transactions on Electron Devices, 2017
work page 2017
-
[25]
Integrated deep trench capacitor in si inter- poser for cowos heterogeneous integration,
S. Hou, H. Hsia, C. Tsai, K. Ting, T. Yu, Y . Lee, F. Chen, W. Chiou, C. Wang, C. Wuet al., “Integrated deep trench capacitor in si inter- poser for cowos heterogeneous integration,” in2019 IEEE International Electron Devices Meeting (IEDM). IEEE, 2019, pp. 19–5
work page 2019
-
[26]
Cowos architecture evolution for next generation hpc on 2.5 d system in package,
Y .-C. Hu, Y .-M. Liang, H.-P. Hu, C.-Y . Tan, C.-T. Shen, C.-H. Lee, and S. Hou, “Cowos architecture evolution for next generation hpc on 2.5 d system in package,” in2023 IEEE 73rd Electronic Components and Technology Conference (ECTC), 2023
work page 2023
-
[27]
Tutel: Adaptive mixture-of-experts at scale,
C. Hwang, W. Cui, Y . Xiong, Z. Yang, Z. Liu, H. Hu, Z. Wang, R. Salas, J. Jose, P. Ramet al., “Tutel: Adaptive mixture-of-experts at scale,” Proceedings of Machine Learning and Systems, vol. 5, pp. 269–287, 2023
work page 2023
-
[28]
Pre-gated moe: An algorithm-system co-design for fast and scalable mixture-of-expert inference,
R. Hwang, J. Wei, S. Cao, C. Hwang, X. Tang, T. Cao, and M. Yang, “Pre-gated moe: An algorithm-system co-design for fast and scalable mixture-of-expert inference,” in2024 ACM/IEEE 51st Annual Interna- tional Symposium on Computer Architecture (ISCA). IEEE, 2024, pp. 1018–1031
work page 2024
-
[29]
LiveCodeBench: Holistic and Contamination Free Evaluation of Large Language Models for Code
N. Jain, K. Han, A. Gu, W.-D. Li, F. Yan, T. Zhang, S. Wang, A. Solar-Lezama, K. Sen, and I. Stoica, “Livecodebench: Holistic and contamination free evaluation of large language models for code,”arXiv preprint arXiv:2403.07974, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[30]
A. Q. Jiang, A. Sablayrolles, A. Roux, A. Mensch, B. Savary, C. Bam- ford, D. S. Chaplot, D. d. l. Casas, E. B. Hanna, F. Bressandet al., “Mixtral of experts,”arXiv preprint arXiv:2401.04088, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[31]
Fiddler: CPU-GPU orchestration for fast inference of mixture-of-experts models,
K. Kamahori, T. Tang, Y . Gu, K. Zhu, and B. Kasikci, “Fiddler: CPU-GPU orchestration for fast inference of mixture-of-experts models,” inThe Thirteenth International Conference on Learning Representations, 2025. [Online]. Available: https://openreview.net/ forum?id=N5fVv6PZGz
work page 2025
-
[32]
Comp-net: Command processor networking for efficient intra-kernel communications on gpus,
M. LeBeane, K. Hamidouche, B. Benton, M. Breternitz, S. K. Reinhardt, and L. K. John, “Comp-net: Command processor networking for efficient intra-kernel communications on gpus,” inProceedings of the 27th International Conference on Parallel Architectures and Compilation Techniques, 2018
work page 2018
-
[33]
J. Li, S. Tripathi, L. Rastogi, Y . Lei, R. Pan, and Y . Xia, “Optimizing mixture-of-experts inference time combining model deployment and communication scheduling,”arXiv preprint arXiv:2410.17043, 2024. 12
-
[34]
Accelerating distributed moe training and inference with lina,
J. Li, Y . Jiang, Y . Zhu, C. Wang, and H. Xu, “Accelerating distributed moe training and inference with lina,” in2023 USENIX Annual Technical Conference (USENIX ATC 23), 2023, pp. 945–959
work page 2023
-
[35]
Lucie: A universal chiplet-interposer design framework for plug-and-play integration,
Z. Li and D. Wentzlaff, “Lucie: A universal chiplet-interposer design framework for plug-and-play integration,” in2024 57th IEEE/ACM International Symposium on Microarchitecture (MICRO). IEEE, 2024, pp. 423–436
work page 2024
-
[36]
A. Liu, B. Feng, B. Xue, B. Wang, B. Wu, C. Lu, C. Zhao, C. Deng, C. Zhang, C. Ruanet al., “Deepseek-v3 technical report,”arXiv preprint arXiv:2412.19437, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[37]
Y . Lu, W. Zhu, L. Li, Y . Qiao, and F. Yuan, “Llamax: Scaling linguis- tic horizons of llm by enhancing translation capabilities beyond 100 languages,”arXiv, 2024
work page 2024
- [38]
-
[39]
Embedded multi-die interconnect bridge (emib)–a high density, high bandwidth packaging interconnect,
R. Mahajan, R. Sankman, N. Patel, D.-W. Kim, K. Aygun, Z. Qian, Y . Mekonnen, I. Salama, S. Sharan, D. Iyengaret al., “Embedded multi-die interconnect bridge (emib)–a high density, high bandwidth packaging interconnect,” in2016 IEEE 66th Electronic Components and Technology Conference (ECTC), 2016
work page 2016
-
[40]
Mixture of experts: a literature survey,
S. Masoudnia and R. Ebrahimpour, “Mixture of experts: a literature survey,”Artificial Intelligence Review, pp. 275–293, 2014
work page 2014
-
[41]
(2025) Llama4 technical report
Meta. (2025) Llama4 technical report. [Online]. Available: https: //ai.meta.com/blog/llama-4-multimodal-intelligence/
work page 2025
-
[42]
OLMoE: Open Mixture-of-Experts Language Models
N. Muennighoff, L. Soldaini, D. Groeneveld, K. Lo, J. Morrison, S. Min, W. Shi, P. Walsh, O. Tafjord, N. Lambertet al., “Olmoe: Open mixture- of-experts language models,”arXiv preprint arXiv:2409.02060, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[43]
Using an llm to help with code understanding,
D. Nam, A. Macvean, V . Hellendoorn, B. Vasilescu, and B. Myers, “Using an llm to help with code understanding,” inProceedings of the IEEE/ACM 46th International Conference on Software Engineering, ser. ICSE ’24, 2024
work page 2024
-
[44]
Nvidia blackwell architecture overview,
NVIDIA, “Nvidia blackwell architecture overview,” https://resources. nvidia.com/en-us-blackwell-architecture, 2025
work page 2025
- [45]
-
[46]
Scar: Schedul- ing multi-model ai workloads on heterogeneous multi-chiplet module accelerators,
M. Odema, L. Chen, H. Kwon, and M. A. Al Faruque, “Scar: Schedul- ing multi-model ai workloads on heterogeneous multi-chiplet module accelerators,” in2024 57th IEEE/ACM International Symposium on Microarchitecture (MICRO). IEEE, 2024, pp. 565–579
work page 2024
-
[47]
R. Qin, Z. Li, W. He, J. Cui, F. Ren, M. Zhang, Y . Wu, W. Zheng, and X. Xu, “Mooncake: Trading more storage for less computation—a {KVCache-centric}architecture for serving{LLM}chatbot,” in23rd USENIX Conference on File and Storage Technologies (FAST 25), 2025
work page 2025
-
[48]
Fred: A wafer-scale fabric for 3d parallel dnn training,
S. Rashidi, W. Won, S. Srinivasan, P. Gupta, and T. Krishna, “Fred: A wafer-scale fabric for 3d parallel dnn training,” inProceedings of the 52nd Annual International Symposium on Computer Architecture, 2025, pp. 34–48
work page 2025
-
[49]
Correlation coefficients: appropriate use and interpretation,
P. Schober, C. Boer, and L. A. Schwarte, “Correlation coefficients: appropriate use and interpretation,”Anesthesia & analgesia, 2018
work page 2018
-
[50]
Simba: Scaling deep-learning inference with multi-chip-module-based architecture,
Y . S. Shao, J. Clemons, R. Venkatesan, B. Zimmer, M. Fojtik, N. Jiang, B. Keller, A. Klinefelter, N. Pinckney, P. Rainaet al., “Simba: Scaling deep-learning inference with multi-chip-module-based architecture,” in Proceedings of the 52nd annual IEEE/ACM international symposium on microarchitecture, 2019, pp. 14–27
work page 2019
-
[51]
Flexgen: High-throughput generative inference of large language models with a single gpu,
Y . Sheng, L. Zheng, B. Yuan, Z. Li, M. Ryabinin, B. Chen, P. Liang, C. R ´e, I. Stoica, and C. Zhang, “Flexgen: High-throughput generative inference of large language models with a single gpu,” inInternational Conference on Machine Learning, 2023
work page 2023
-
[52]
Sow-x: A novel system-on-wafer technology for next generation ai server application,
P.-C. Shih, A.-J. Su, K.-H. Tam, T.-C. Huang, K. Chuang, and J. Yeh, “Sow-x: A novel system-on-wafer technology for next generation ai server application,” in2025 IEEE 75th Electronic Components and Technology Conference (ECTC). IEEE, 2025
work page 2025
-
[53]
Signal integrity of die-to-die interface with advanced packages for co-packaged optics,
J. Shin, H. Eslampour, S. Jeong, W. Kim, S. Yong, S.-O. Ahn, E. Park, and S. Song, “Signal integrity of die-to-die interface with advanced packages for co-packaged optics,” in2024 IEEE 33rd Conference on Electrical Performance of Electronic Packaging and Systems (EPEPS), 2024
work page 2024
-
[54]
Mixture of cache- conditional experts for efficient mobile device inference,
A. Skliar, T. van Rozendaal, R. Lepert, T. Boinovski, M. Van Baalen, M. Nagel, P. Whatmough, and B. E. Bejnordi, “Mixture of cache- conditional experts for efficient mobile device inference,”arXiv preprint arXiv:2412.00099, 2024
-
[55]
Amd instinct™ mi300x accelerator: Packaging and architecture co-optimization,
A. Smith, G. H. Loh, J. Wuu, S. Naffziger, T. Huang, H. McIntyre, R. Mangaser, W. Jung, and R. Swaminathan, “Amd instinct™ mi300x accelerator: Packaging and architecture co-optimization,” in2024 IEEE Symposium on VLSI Technology and Circuits (VLSI Technology and Circuits). IEEE, 2024
work page 2024
-
[56]
Hunyuan-large: An open-source moe model with 52 billion activated parameters by tencent,
X. Sun, Y . Chen, Y . Huang, R. Xie, J. Zhu, K. Zhang, S. Li, Z. Yang, J. Han, X. Shuet al., “Hunyuan-large: An open-source moe model with 52 billion activated parameters by tencent,”arXiv preprint arXiv:2411.02265, 2024
-
[57]
Mgpusim: Enabling multi-gpu performance modeling and optimization,
Y . Sun, T. Baruah, S. A. Mojumder, S. Dong, X. Gong, S. Treadway, Y . Bao, S. Hance, C. McCardwell, V . Zhaoet al., “Mgpusim: Enabling multi-gpu performance modeling and optimization,” inProceedings of the 46th International Symposium on Computer Architecture, 2019
work page 2019
-
[58]
Coserve: Efficient collaboration-of-experts (coe) model inference with limited memory,
J. Suo, X. Liao, L. Xiao, L. Ruan, J. Wang, X. Su, and Z. Huo, “Coserve: Efficient collaboration-of-experts (coe) model inference with limited memory,” inProceedings of the 30th ACM International Conference on Architectural Support for Programming Languages and Operating Systems, 2025
work page 2025
-
[59]
emoe: Task-aware mem- ory efficient mixture-of-experts-based (moe) model inference,
S. Tairin, S. Mahmud, H. Shen, and A. Iyer, “emoe: Task-aware mem- ory efficient mixture-of-experts-based (moe) model inference,”arXiv preprint arXiv:2503.06823, 2025
-
[60]
The microarchitecture of dojo, tesla’s exa-scale computer,
E. Talpes, D. D. Sarma, D. Williams, S. Arora, T. Kunjan, B. Floering, A. Jalote, C. Hsiong, C. Poorna, V . Samantet al., “The microarchitecture of dojo, tesla’s exa-scale computer,”IEEE Micro, 2023
work page 2023
-
[61]
Dojo: The microarchitecture of tesla’s exa-scale computer,
E. Talpes, D. Williams, and D. D. Sarma, “Dojo: The microarchitecture of tesla’s exa-scale computer,” in2022 IEEE Hot Chips 34 Symposium (HCS), 2022
work page 2022
-
[62]
Z. Tan, H. Cai, R. Dong, and K. Ma, “Nn-baton: Dnn workload orches- tration and chiplet granularity exploration for multichip accelerators,” in2021 ACM/IEEE 48th Annual International Symposium on Computer Architecture (ISCA). IEEE, 2021, pp. 1013–1026
work page 2021
-
[63]
Kimi K2: Open Agentic Intelligence
K. Team, Y . Bai, Y . Bao, G. Chen, J. Chen, N. Chen, R. Chen, Y . Chen, Y . Chen, Y . Chenet al., “Kimi k2: Open agentic intelligence,”arXiv preprint arXiv:2507.20534, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[64]
TSMC. (2025) Tsmc’s next generation of system-on- wafer package will make today’s cpus and gpus look pathetically feeble in comparison. [Online]. Available: https://www.pcgamer.com/hardware/processors/tsmcs-next-generation- of-system-on-wafer-packaging-will-make-todays-cpus-and-gpus-look- pathetically-feeble-in-comparison/
work page 2025
-
[65]
Rag-based llm chatbot using llama-2,
S. Vakayil, D. S. Juliet, S. Vakayilet al., “Rag-based llm chatbot using llama-2,” in2024 7th International Conference on Devices, Circuits and Systems (ICDCS), 2024
work page 2024
-
[66]
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, Ł. Kaiser, and I. Polosukhin, “Attention is all you need,”Advances in neural information processing systems, 2017
work page 2017
-
[67]
Mmlu-pro: A more robust and challenging multi-task language understanding benchmark,
Y . Wang, X. Ma, G. Zhang, Y . Ni, A. Chandra, S. Guo, W. Ren, A. Arulraj, X. He, Z. Jianget al., “Mmlu-pro: A more robust and challenging multi-task language understanding benchmark,”Advances in Neural Information Processing Systems, 2024
work page 2024
-
[68]
Y . Wang, W. Wang, S. Joty, and S. C. H. Hoi, “Codet5: Identifier-aware unified pre-trained encoder-decoder models for code understanding and generation,”arXiv, 2021
work page 2021
-
[69]
W. Won, T. Heo, S. Rashidi, S. Sridharan, S. Srinivasan, and T. Kr- ishna, “Astra-sim2. 0: Modeling hierarchical networks and disaggregated systems for large-model training at scale,” in2023 IEEE International Symposium on Performance Analysis of Systems and Software (ISPASS), 2023
work page 2023
-
[70]
B. Wu, S. Liu, Y . Zhong, P. Sun, X. Liu, and X. Jin, “Loongserve: Effi- ciently serving long-context large language models with elastic sequence parallelism,” inProceedings of the ACM SIGOPS 30th Symposium on Operating Systems Principles, 2024, pp. 640–654
work page 2024
-
[71]
Wsc-llm: Efficient llm service and architecture co-exploration for wafer-scale chips,
Z. Xu, D. Kong, J. Liu, J. Li, J. Hou, X. Dai, C. Li, S. Wei, Y . Hu, and S. Yin, “Wsc-llm: Efficient llm service and architecture co-exploration for wafer-scale chips,” inProceedings of the 52nd Annual International Symposium on Computer Architecture, 2025, pp. 1–17
work page 2025
-
[72]
A. Yang, A. Li, B. Yang, B. Zhang, B. Hui, B. Zheng, B. Yu, C. Gao, C. Huang, C. Lvet al., “Qwen3 technical report,”arXiv preprint arXiv:2505.09388, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[73]
Pd constraint-aware physical/logical topology co-design for network on wafer,
Q. Yang, T. Wei, S. Guan, C. Li, H. Shang, J. Deng, H. Wang, C. Li, L. Wang, Y . Zhanget al., “Pd constraint-aware physical/logical topology co-design for network on wafer,” inProceedings of the 52nd Annual International Symposium on Computer Architecture, 2025, pp. 49–64
work page 2025
-
[74]
Exploiting inter-layer expert affinity for accelerating mixture-of-experts model inference,
J. Yao, Q. Anthony, A. Shafi, H. Subramoni, and D. K. D. Panda, “Exploiting inter-layer expert affinity for accelerating mixture-of-experts model inference,” in2024 IEEE International Parallel and Distributed Processing Symposium (IPDPS). IEEE, 2024
work page 2024
-
[75]
X. Yu, D. Jiang, J. Deng, J. Liu, C. Li, S. Yin, and Y . Hu, “Cramming a data center into one cabinet, a co-exploration of computing and hardware 13 architecture of waferscale chip,” inProceedings of the 52nd Annual International Symposium on Computer Architecture, 2025, pp. 631–645
work page 2025
-
[76]
Cambricon-llm: A chiplet-based hybrid archi- tecture for on-device inference of 70b llm,
Z. Yu, S. Liang, T. Ma, Y . Cai, Z. Nan, D. Huang, X. Song, Y . Hao, J. Zhang, T. Zhiet al., “Cambricon-llm: A chiplet-based hybrid archi- tecture for on-device inference of 70b llm,” in2024 57th IEEE/ACM International Symposium on Microarchitecture (MICRO), 2024
work page 2024
-
[77]
S. Yun, K. Kyung, J. Cho, J. Choi, J. Kim, B. Kim, S. Lee, K. Sohn, and J. H. Ahn, “Duplex: A device for large language models with mixture of experts, grouped query attention, and continuous batching,” in2024 57th IEEE/ACM International Symposium on Microarchitecture (MICRO), 2024
work page 2024
-
[78]
M. Zhai, J. He, Z. Ma, Z. Zong, R. Zhang, and J. Zhai, “{SmartMoE}: Efficiently training sparsely-activated models through combining offline and online parallelization,” in2023 USENIX Annual Technical Confer- ence (USENIX ATC 23), 2023, pp. 961–975
work page 2023
-
[79]
COMET: Fine-grained computation-communication overlapping for mixture-of-experts,
S. Zhang, N. Zheng, H. Lin, Z. Jiang, W. Bao, C. Jiang, Q. Hou, W. Cui, S. Zheng, L.-W. Chang, Q. Chen, and X. Liu, “COMET: Fine-grained computation-communication overlapping for mixture-of-experts,” in Eighth Conference on Machine Learning and Systems, 2025. [Online]. Available: https://openreview.net/forum?id=fGgQS5VW09
work page 2025
-
[80]
Sglang: Efficient execution of structured language model programs,
L. Zheng, L. Yin, Z. Xie, C. L. Sun, J. Huang, C. H. Yu, S. Cao, C. Kozyrakis, I. Stoica, J. E. Gonzalezet al., “Sglang: Efficient execution of structured language model programs,”Advances in neural information processing systems, 2024
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.