LETT-NeXt: A Lightweight RECIST-Guided Model for 3D CT Lesion Segmentation
Pith reviewed 2026-06-30 06:48 UTC · model grok-4.3
The pith
LETT-NeXt predicts 3D lesion masks from CT by adding RECIST line and endpoints as two prompt channels to a centered crop.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
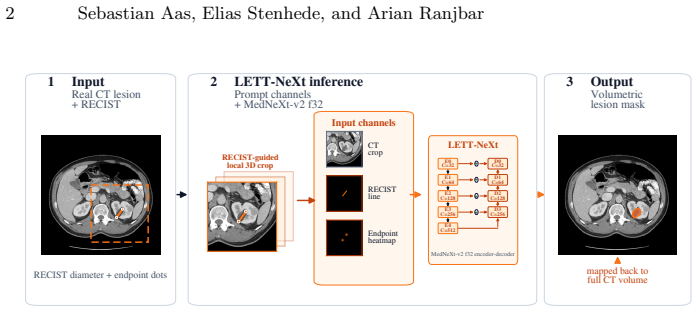
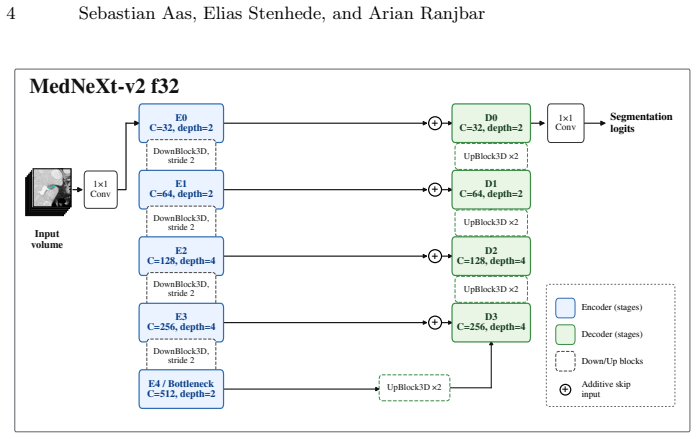
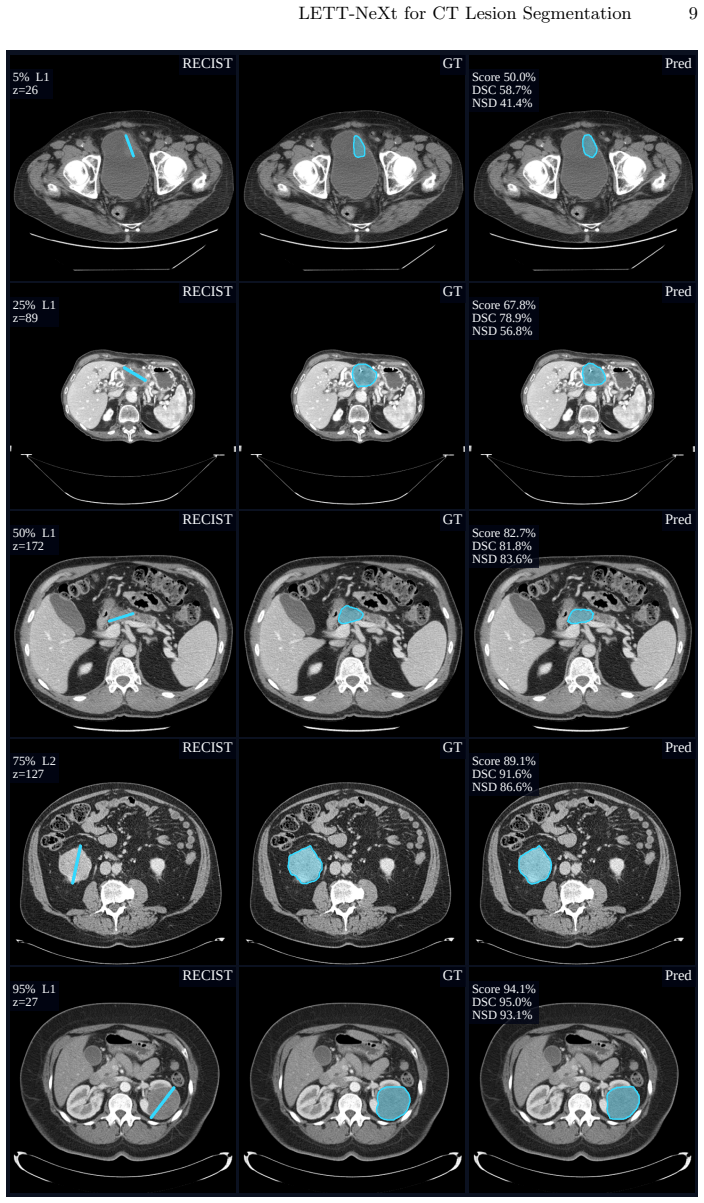
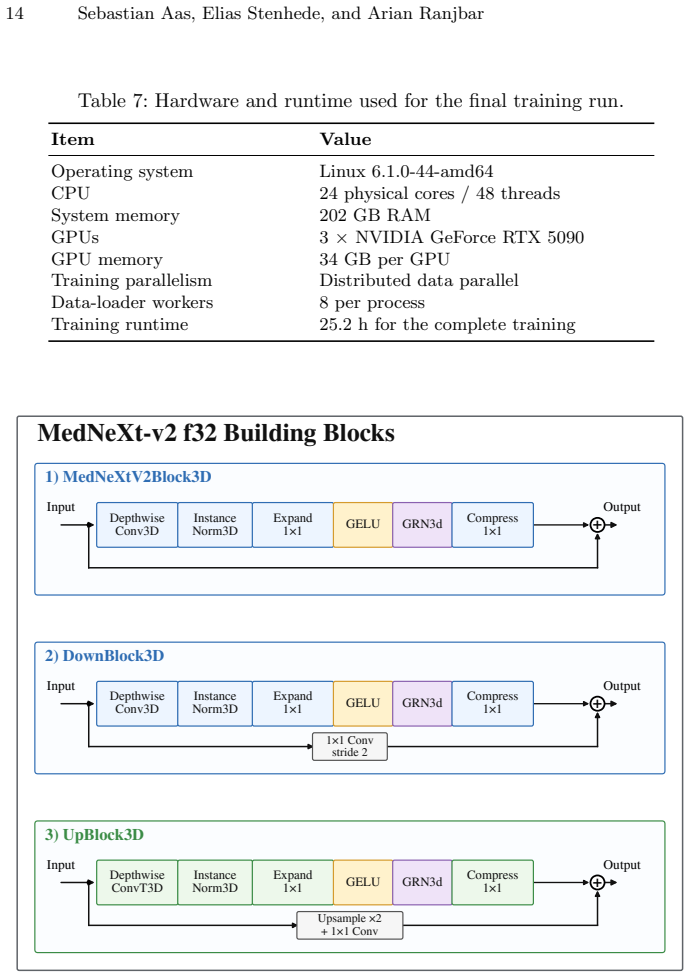
LETT-NeXt extracts a RECIST-centered regional crop from the CT volume, encodes the RECIST line and endpoints as two additional prompt channels, concatenates them with the CT input, and passes the result through a compact MedNeXt-v2 encoder-decoder to output the 3D lesion mask; prompt-aware component selection and adaptive AutoZoom inference then refine the output, yielding DSC 79.4 ± 10.1 and NSD 72.3 ± 16.2 on public validation and DSC 73.9, NSD 67.3 on the hidden test set.
What carries the argument
RECIST prompt channels: two extra input channels that encode the RECIST line and endpoints, concatenated with the CT volume inside a RECIST-centered crop to steer the lightweight segmentation network.
If this is right
- 3D lesion volumes become available from existing routine RECIST annotations without new manual contouring.
- Inference runs on standard CPU hardware in 6.9 seconds per case with peak memory of 3.6 GB.
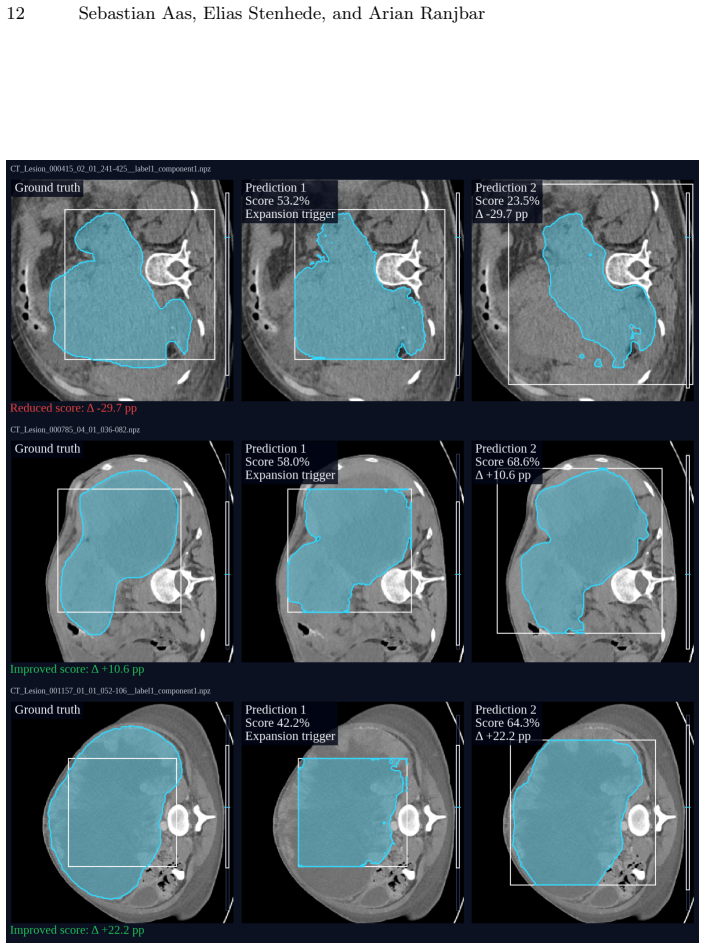
- Prompt-aware component selection removes extraneous regions that the network might otherwise include.
- Adaptive AutoZoom inference adjusts to lesions of different sizes within the same model.
Where Pith is reading between the lines
- The same prompt-channel idea could be tested on other 2D clinical measurements such as caliper distances or long-axis lengths.
- Removing the RECIST prompts entirely and retraining might reveal how much the network relies on image texture versus explicit location cues.
- The lightweight footprint suggests the architecture could serve as a starting point for on-device or edge deployment in clinical workflows.
Load-bearing premise
Marking the RECIST line and endpoints as two prompt channels inside a centered crop supplies enough guidance for the network to recover accurate 3D lesion masks from the CT volume alone.
What would settle it
Measure Dice and NSD on the hidden test set after removing the two RECIST prompt channels while keeping every other part of the pipeline unchanged; a drop below 70 would indicate the prompts are required for the reported performance.
Figures
read the original abstract
RECIST diameter measurements are widely used for tumor response assessment, but they provide only a limited 2D description of lesion extent. We present LETT-NeXt, a lightweight RECIST-guided model that predicts 3D lesion masks from CT volumes and RECIST markers for the CVPR 2026 Foundation Models for Pan-cancer Segmentation in CT Images competition. LETT-NeXt extracts a RECIST-centered regional crop, encodes the RECIST line and endpoints as two prompt channels, and concatenates them with the CT input. A compact MedNeXt-v2 encoder--decoder predicts the lesion mask, followed by prompt-aware component selection and adaptive AutoZoom inference. On the public validation set, LETT-NeXt achieved a Dice Similarity Coefficient (DSC) of 79.4 $\pm$ 10.1 and a Normalized Surface Dice (NSD) of 72.3 $\pm$ 16.2. On the hidden test set, it achieved a DSC of 73.9 and an NSD of 67.3, corresponding to a challenge score of 70.6\%. On the public validation mirror, LETT-NeXt completed CPU inference in 6.9 $\pm$ 3.0 s per case with a peak memory use of 3.6 GB. Code is available at github.com/Ahus-AIM/lett-next.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces LETT-NeXt, a lightweight RECIST-guided model for 3D CT lesion segmentation in the CVPR 2026 competition. It extracts a RECIST-centered regional crop from the CT volume, encodes the RECIST line and endpoints as two additional prompt channels, concatenates them with the CT input, and feeds the result to a compact MedNeXt-v2 encoder-decoder. This is followed by prompt-aware component selection and adaptive AutoZoom inference. The paper reports DSC of 79.4 ± 10.1 and NSD of 72.3 ± 16.2 on the public validation set, DSC of 73.9 and NSD of 67.3 on the hidden test set (challenge score 70.6%), plus CPU inference time of 6.9 ± 3.0 s per case and peak memory of 3.6 GB. Code is released at github.com/Ahus-AIM/lett-next.
Significance. If the reported performance holds under scrutiny, the work supplies a practical, memory-efficient pipeline that converts 2D RECIST annotations into 3D lesion masks for pan-cancer CT segmentation. The explicit release of code and the inclusion of standardized efficiency metrics on CPU constitute concrete strengths that enhance reproducibility and deployment value.
major comments (1)
- [Model description and experimental results] The central claim that encoding the RECIST line and endpoints as two prompt channels guides accurate 3D mask prediction rests on an untested assumption. No ablation is provided that removes or zeros these prompt channels while retaining the RECIST-centered crop, MedNeXt-v2 backbone, component selection, and AutoZoom (see the model description in the abstract and the implied methods). Without this isolation, it remains possible that the regional crop and base architecture alone account for the reported DSC/NSD values.
minor comments (2)
- [Abstract] Training procedure, loss functions, optimizer settings, and data augmentation details are absent, limiting assessment of the experimental protocol.
- [Results] The reported standard deviations (±10.1 DSC, ±16.2 NSD) are large; a brief discussion of failure cases or case-level variability would strengthen the results section.
Simulated Author's Rebuttal
We thank the referee for highlighting the need for an ablation to isolate the contribution of the RECIST prompt channels. We address the comment below and will revise the manuscript to include the requested experiment.
read point-by-point responses
-
Referee: The central claim that encoding the RECIST line and endpoints as two prompt channels guides accurate 3D mask prediction rests on an untested assumption. No ablation is provided that removes or zeros these prompt channels while retaining the RECIST-centered crop, MedNeXt-v2 backbone, component selection, and AutoZoom (see the model description in the abstract and the implied methods). Without this isolation, it remains possible that the regional crop and base architecture alone account for the reported DSC/NSD values.
Authors: We agree that the current manuscript lacks an ablation that removes or zeros the prompt channels while retaining the RECIST-centered crop, MedNeXt-v2 backbone, component selection, and AutoZoom. This is a valid observation. In the revised manuscript we will add this ablation study, reporting the resulting DSC and NSD on the public validation set to quantify the incremental contribution of the prompt channels. revision: yes
Circularity Check
No circularity detected; empirical results on held-out partitions
full rationale
The paper reports DSC and NSD metrics on distinct public validation and hidden test sets after describing a RECIST-prompt architecture. No equations, fitted parameters, or self-citations are present that would reduce the performance numbers to a definitional identity or construction from the inputs. The method description (crop + prompt channels + MedNeXt-v2 + post-processing) stands as an independent design choice whose outputs are evaluated externally.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
FLARE-MedFM/FLARE-Task1-PancancerRECIST-to-3D·Datasets at Hugging Face
-
[2]
Lite ENSAM: a lightweight cancer segmentation model for 3D Computed Tomography, November
Agnar Martin Bjornstad, Elias Stenhede, and Arian Ranjbar. Lite ENSAM: a lightweight cancer segmentation model for 3D Computed Tomography, November
- [3]
-
[4]
SAM 3: Segment Anything with Concepts, March
Nicolas Carion, Laura Gustafson, Yuan-Ting Hu, Shoubhik Debnath, Ronghang Hu, Didac Suris, Chaitanya Ryali, Kalyan Vasudev Alwala, Haitham Khedr, An- drew Huang, Jie Lei, Tengyu Ma, Baishan Guo, Arpit Kalla, Markus Marks, Joseph Greer, Meng Wang, Peize Sun, Roman R¨ adle, Triantafyllos Afouras, Effrosyni Mavroudi, Katherine Xu, Tsung-Han Wu, Yu Zhou, Lili...
-
[5]
SAM 3: Segment Anything with Concepts
arXiv:2511.16719 [cs.CV]. LETT-NeXt for CT Lesion Segmentation 17
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
SegVol: Universal and Inter- active Volumetric Medical Image Segmentation, February 2025
Yuxin Du, Fan Bai, Tiejun Huang, and Bo Zhao. SegVol: Universal and Inter- active Volumetric Medical Image Segmentation, February 2025. arXiv:2311.13385 [cs.CV]
-
[7]
E. A. Eisenhauer, P. Therasse, J. Bogaerts, L. H. Schwartz, D. Sargent, R. Ford, J. Dancey, S. Arbuck, S. Gwyther, M. Mooney, L. Rubinstein, L. Shankar, L. Dodd, R. Kaplan, D. Lacombe, and J. Verweij. New response evaluation criteria in solid tumours: Revised RECIST guideline (version 1.1).European Journal of Cancer, 45(2):228–247, January 2009
2009
-
[8]
Hayes, M.C
S.A. Hayes, M.C. Pietanza, D. O’Driscoll, J. Zheng, C.S. Moskowitz, M.G. Kris, and M.S. Ginsberg. Comparison of CT volumetric measurement with RECIST response in patients with lung cancer.European Journal of Radiology, 85(3):524– 533, March 2016
2016
-
[9]
VISTA3D: A Unified Segmentation Foundation Model For 3D Medical Imaging, November 2024
Yufan He, Pengfei Guo, Yucheng Tang, Andriy Myronenko, Vishwesh Nath, Ziyue Xu, Dong Yang, Can Zhao, Benjamin Simon, Mason Belue, Stephanie Harmon, Baris Turkbey, Daguang Xu, and Wenqi Li. VISTA3D: A Unified Segmentation Foundation Model For 3D Medical Imaging, November 2024. arXiv:2406.05285 [cs]
-
[10]
Ziyan Huang, Haoyu Wang, Zhongying Deng, Jin Ye, Yanzhou Su, Hui Sun, Jun- jun He, Yun Gu, Lixu Gu, Shaoting Zhang, and Yu Qiao. STU-Net: Scalable and Transferable Medical Image Segmentation Models Empowered by Large-Scale Supervised Pre-training, April 2023. arXiv:2304.06716 [cs]
-
[11]
Mertens, Felix J
Hartmut H¨ antze, Lina Xu, Christian J. Mertens, Felix J. Dorfner, Leonhard Donle, Felix Busch, Avan Kader, Sebastian Ziegelmayer, Nadine Bayerl, Nas- sir Navab, Daniel Rueckert, Julia Schnabel, Hugo JWL Aerts, Daniel Truhn, Fabian Bamberg, Jakob Weiß, Christopher L. Schlett, Steffen Ringhof, Thoralf Niendorf, Tobias Pischon, Hans-Ulrich Kauczor, Tobias N...
- [12]
-
[13]
nnU-Net: Self-adapting Framework for U-Net-Based Medical Image Segmentation
Fabian Isensee, Jens Petersen, Andre Klein, David Zimmerer, Paul F. Jaeger, Si- mon Kohl, Jakob Wasserthal, Gregor Koehler, Tobias Norajitra, Sebastian Wirk- ert, and Klaus H. Maier-Hein. nnU-Net: Self-adapting Framework for U-Net-Based Medical Image Segmentation, September 2018. arXiv:1809.10486 [cs]
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[14]
nnInteractive: Redefining 3D Promptable Segmentation, March 2025
Fabian Isensee, Maximilian Rokuss, Lars Kr¨ amer, Stefan Dinkelacker, Ashis Ravin- dran, Florian Stritzke, Benjamin Hamm, Tassilo Wald, Moritz Langenberg, Con- stantin Ulrich, Jonathan Deissler, Ralf Floca, and Klaus Maier-Hein. nnInteractive: Redefining 3D Promptable Segmentation, March 2025
2025
-
[15]
Alexander Kirillov, Eric Mintun, Nikhila Ravi, Hanzi Mao, Chloe Rolland, Laura Gustafson, Tete Xiao, Spencer Whitehead, Alexander C. Berg, Wan-Yen Lo, Pi- otr Doll´ ar, and Ross Girshick. Segment Anything, April 2023. arXiv:2304.02643 [cs.CV]
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[16]
Wenxuan Li, Xinze Zhou, Qi Chen, Tianyu Lin, Pedro R. A. S. Bassi, Szymon Plotka, Jaroslaw B. Cwikla, Xiaoxi Chen, Chen Ye, Zheren Zhu, Kai Ding, Heng Li, Kang Wang, Yang Yang, Yucheng Tang, Daguang Xu, Alan L. Yuille, and Zong- wei Zhou. PanTS: The Pancreatic Tumor Segmentation Dataset, 2025. Version Number: 1
2025
-
[17]
Zhuang Liu, Hanzi Mao, Chao-Yuan Wu, Christoph Feichtenhofer, Trevor Darrell, and Saining Xie. A ConvNet for the 2020s, March 2022. arXiv:2201.03545 [cs]. 18 Sebastian Aas, Elias Stenhede, and Arian Ranjbar
-
[18]
Segment Anything in Medical Images.Nature Communications, 15(1):654, January 2024
Jun Ma, Yuting He, Feifei Li, Lin Han, Chenyu You, and Bo Wang. Segment Anything in Medical Images.Nature Communications, 15(1):654, January 2024. arXiv:2304.12306 [eess.IV]
-
[19]
Springer Nature Switzerland, Cham, 2026
Jun Ma and Bo Wang, editors.Fast, Low-Resource, Accurate Robust Organ and Pan-cancer Segmentation: MICCAI Challenge, FLARE 2024, Held in Conjunction with MICCAI 2024, Marrakesh, Morocco, October 6, 2024, Proceedings, volume 15717 ofLecture Notes in Computer Science. Springer Nature Switzerland, Cham, 2026
2024
-
[20]
A promptable CT foundation model for solid tumor evaluation.npj Precision Oncology, 9(1):121, April 2025
L´ eo Machado, L´ eo Alberge, H´ el` ene Philippe, Elodie Ferreres, Julien Khlaut, Julie Dupuis, Korentin Le Floch, Denis Habip Gatenyo, Pascal Roux, Jules Gr´ egory, Maxime Ronot, Corentin Dancette, Tom Boeken, Daniel Tordjman, Pierre Manceron, and Paul H´ erent. A promptable CT foundation model for solid tumor evaluation.npj Precision Oncology, 9(1):121...
2025
-
[21]
3D MRI brain tumor segmentation using autoencoder regularization
Andriy Myronenko. 3D MRI brain tumor segmentation using autoencoder regu- larization, November 2018. arXiv:1810.11654 [cs]
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[22]
SAM 2: Segment Anything in Images and Videos
Nikhila Ravi, Valentin Gabeur, Yuan-Ting Hu, Ronghang Hu, Chaitanya Ryali, Tengyu Ma, Haitham Khedr, Roman R¨ adle, Chloe Rolland, Laura Gustafson, Eric Mintun, Junting Pan, Kalyan Vasudev Alwala, Nicolas Carion, Chao-Yuan Wu, Ross Girshick, Piotr Doll´ ar, and Christoph Feichtenhofer. SAM 2: Segment Any- thing in Images and Videos, October 2024. arXiv:24...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[23]
U-Net: Convolutional Networks for Biomedical Image Segmentation
Olaf Ronneberger, Philipp Fischer, and Thomas Brox. U-Net: Convolutional Net- works for Biomedical Image Segmentation, May 2015. arXiv:1505.04597 [cs]
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[24]
Saikat Roy, Yannick Kirchhoff, Constantin Ulrich, Maximillian Rokuss, Tassilo Wald, Fabian Isensee, and Klaus Maier-Hein. MedNeXt-v2: Scaling 3D ConvNeXts for Large-Scale Supervised Representation Learning in Medical Image Segmenta- tion, December 2025. arXiv:2512.17774 [eess]
-
[25]
J¨ ager, and Klaus H
Saikat Roy, Gregor Koehler, Constantin Ulrich, Michael Baumgartner, Jens Pe- tersen, Fabian Isensee, Paul F. J¨ ager, and Klaus H. Maier-Hein. MedNeXt: Transformer-Driven Scaling of ConvNets for Medical Image Segmentation. In Hayit Greenspan, Anant Madabhushi, Parvin Mousavi, Septimiu Salcudean, James Dun- can, Tanveer Syeda-Mahmood, and Russell Taylor, e...
2023
-
[26]
Springer Nature Switzerland
-
[27]
ENSAM: an efficient foundation model for interactive segmentation of 3D medical images, September
Elias Stenhede, Agnar Martin Bjørnstad, and Arian Ranjbar. ENSAM: an efficient foundation model for interactive segmentation of 3D medical images, September
-
[28]
arXiv:2509.15874 [cs]
work page internal anchor Pith review arXiv
-
[29]
SAM-Med3D: Towards General-purpose Segmentation Models for Volumetric Medical Images, September 2024
Haoyu Wang, Sizheng Guo, Jin Ye, Zhongying Deng, Junlong Cheng, Tianbin Li, Jianpin Chen, Yanzhou Su, Ziyan Huang, Yiqing Shen, Bin Fu, Shaoting Zhang, Junjun He, and Yu Qiao. SAM-Med3D: Towards General-purpose Segmentation Models for Volumetric Medical Images, September 2024. arXiv:2310.15161 [cs.CV]
-
[30]
Meyer, Maurice Pradella, Daniel Hinck, Alexander W
Jakob Wasserthal, Hanns-Christian Breit, Manfred T. Meyer, Maurice Pradella, Daniel Hinck, Alexander W. Sauter, Tobias Heye, Daniel Boll, Joshy Cyriac, Shan Yang, Michael Bach, and Martin Segeroth. TotalSegmentator: robust segmenta- tion of 104 anatomical structures in CT images.Radiology: Artificial Intelligence, 5(5):e230024, September 2023. arXiv:2208....
-
[31]
Codabench: Flexible, Easy-to-Use and Reproducible Benchmarking Platform, February 2022
Zhen Xu, Sergio Escalera, Isabelle Guyon, Adrien Pav˜ ao, Magali Richard, Wei- Wei Tu, Quanming Yao, and Huan Zhao. Codabench: Flexible, Easy-to-Use and Reproducible Benchmarking Platform, February 2022. arXiv:2110.05802 [cs.LG]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.