FVSpec: Real-World Property-Based Tests as Lean Challenges
Pith reviewed 2026-06-28 17:03 UTC · model grok-4.3
The pith
Real Python property-based tests are translated into Lean specifications to create a benchmark for AI formal verification.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
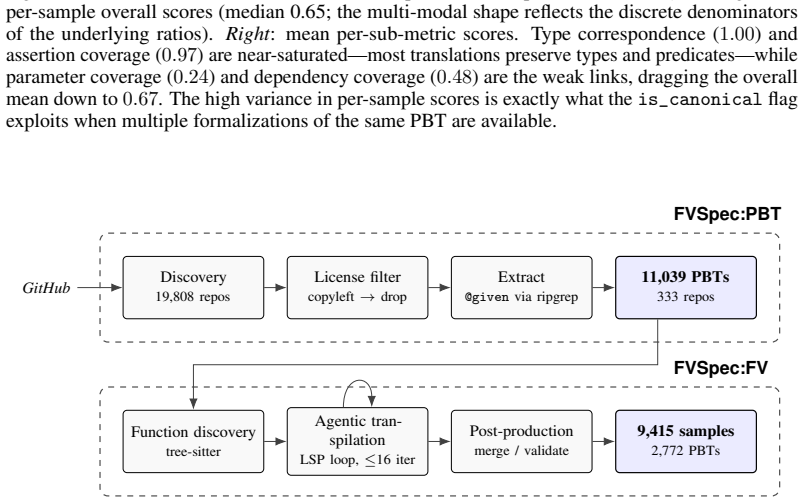
We present a benchmark consisting of 9,415 Lean 4 specifications derived from 2,772 real-world Python property-based tests scraped from 11,039 examples across repositories. A three-agent LLM pipeline performs the transpilation by modeling Python semantics in Lean, inferring the encoded logical property from imperative code, and producing dependently-typed formalizations, with multiple variants retained when quality metrics do not single out one. Coverage and quality metrics are reported for the translations, and baselines are given for proof generation using several automated and model-based approaches.
What carries the argument
Three-agent LLM pipeline that transpiles imperative Python PBTs into Lean specifications by modeling runtime semantics and inferring logical properties.
If this is right
- The benchmark supplies concrete tasks for measuring AI progress on turning informal tests into formal specs.
- Baselines establish current performance levels for both translation quality and subsequent automated proof attempts.
- Open release of scraper, agents, PBTs, and Lean files enables others to extend the dataset or improve the pipeline.
- Success on these tasks would demonstrate AI capability on verification of code drawn from real repositories rather than toy examples.
Where Pith is reading between the lines
- The pipeline's handling of Python-to-Lean semantic gaps may reveal general patterns useful for translating between other testing and verification languages.
- Retaining multiple formalizations per PBT could support ensemble methods or robustness checks in downstream AI verification systems.
- If the benchmark drives measurable gains in proof rates, it could accelerate integration of property-based testing outputs directly into formal toolchains.
- The emphasis on real repositories suggests the dataset distribution mirrors industrial code more closely than synthetic benchmarks, potentially improving transfer to production verification.
Load-bearing premise
The LLM pipeline's translations preserve the original intended properties without introducing semantic mismatches or losing details of Python behavior.
What would settle it
A set of test inputs where the Python PBT passes but a corresponding Lean specification, once proved, fails to hold under an equivalent Lean encoding of the same inputs.
Figures


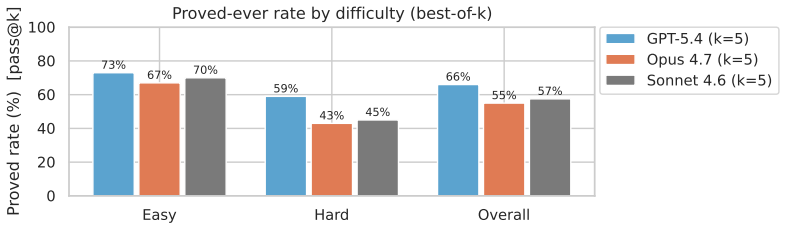
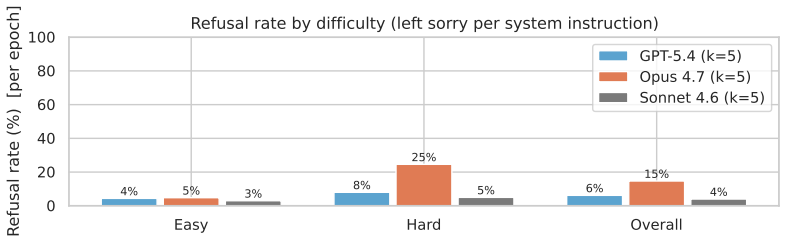
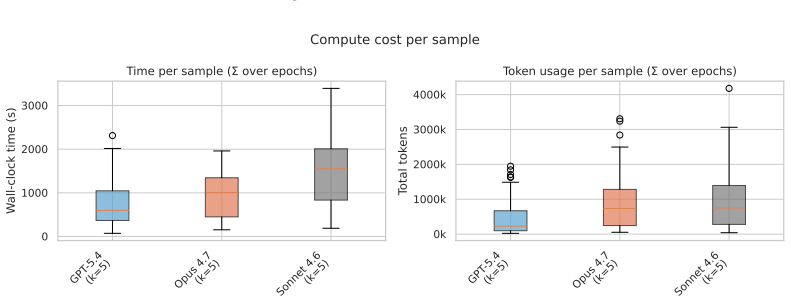
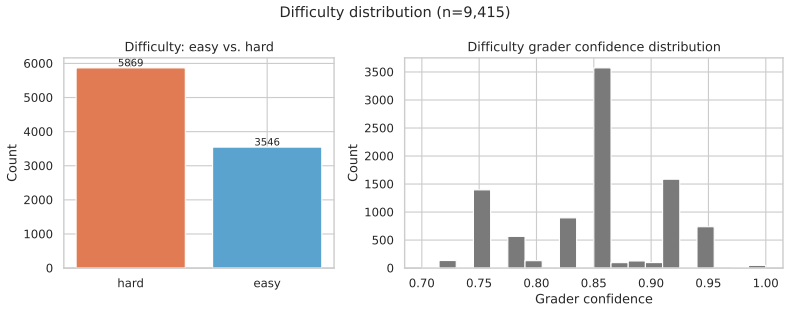



read the original abstract
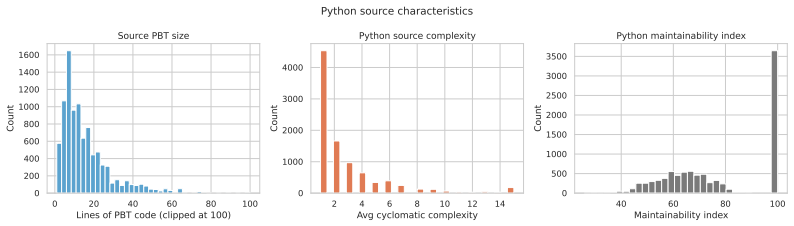
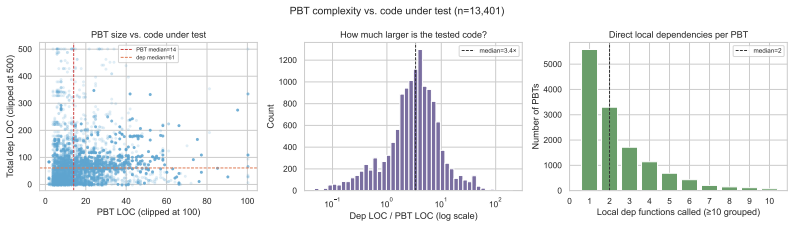
We present a benchmark for evaluating AI models and agents on real-world formal software verification tasks. We first scrape 11,039 property-based tests (PBTs) from real-world Python repositories, then automatically translate 2,772 of them (25%) into 9,415 Lean 4 specifications with sorry placeholders (about 3 formalizations/PBT; we retain multiple attempts when none dominates on quality metrics). Translating PBTs into Lean specifications is challenging: it requires modeling Python semantics in Lean, inferring the logical property encoded in an imperative PBT, and handling the inherent difficulties of dependently-typed programming in a seldom-used language. We describe a three-agent LLM pipeline for transpiling PBTs into Lean specifications, evaluate coverage and quality metrics, and provide baselines for proof generation using several automated and model based approaches. All code (scraper and agents) and data (PBTs and Lean specifications) are open source. Our benchmark aims to drive progress on the underexplored problem of AI-assisted formal verification of real-world software, which is of increasing interest as AI produces more and more of the world's code.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces FVSpec, a benchmark for AI models and agents on real-world formal software verification. It scrapes 11,039 property-based tests (PBTs) from Python repositories, automatically translates 2,772 of them (25%) into 9,415 Lean 4 specifications (with sorry placeholders) via a three-agent LLM pipeline, evaluates coverage and quality metrics on the translations, and reports baselines for proof generation; all code, data, and specifications are released openly.
Significance. If the translations faithfully capture the logical properties and Python semantics, the benchmark would be a valuable contribution to the underexplored area of AI-assisted formal verification of real-world imperative code. The open release of the scraper, agents, PBTs, and Lean specifications is a clear strength that supports reproducibility and community extension.
major comments (2)
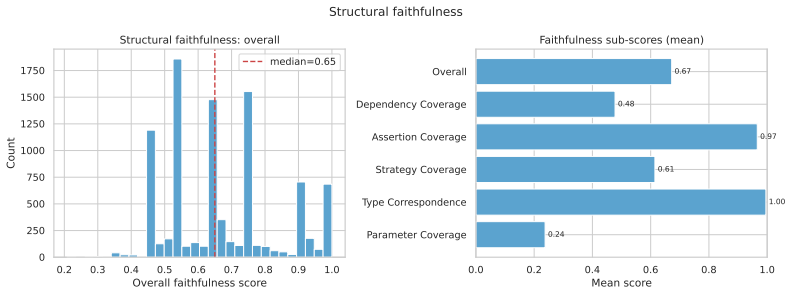
- [Evaluation section] Evaluation section (and abstract): The manuscript states that coverage and quality metrics were evaluated for the three-agent LLM translations, but provides no concrete numbers, error rates, or independent semantic validation (e.g., manual equivalence checks or comparison against human-written Lean specs on a sample). This is load-bearing for the central claim that the 9,415 specifications constitute usable real-world verification tasks, as unvalidated translations risk systematic mismatches in quantifiers, side effects, or Python runtime modeling.
- [Pipeline description] Pipeline description: The three-agent LLM approach is presented as addressing the challenges of modeling Python semantics (mutability, exceptions) and inferring logical properties in dependently-typed Lean, but the manuscript does not detail failure modes, prompt strategies for runtime behaviors, or how multiple formalizations per PBT were selected when none dominated on metrics. This directly affects whether the benchmark tests genuine verification rather than translation artifacts.
minor comments (2)
- [Abstract] Abstract: The claim that 'translating PBTs into Lean specifications is challenging' is stated without accompanying quantitative indicators (e.g., success rate or typical error types), which would strengthen the motivation for the pipeline.
- [Translation process] The retention criterion for multiple Lean formalizations per PBT ('when none dominates on quality metrics') is mentioned but not defined operationally, leaving the exact composition of the 9,415 specifications unclear.
Simulated Author's Rebuttal
We thank the referee for their detailed and constructive report. We address each major comment below and will incorporate the requested clarifications and data into a revised manuscript.
read point-by-point responses
-
Referee: [Evaluation section] Evaluation section (and abstract): The manuscript states that coverage and quality metrics were evaluated for the three-agent LLM translations, but provides no concrete numbers, error rates, or independent semantic validation (e.g., manual equivalence checks or comparison against human-written Lean specs on a sample). This is load-bearing for the central claim that the 9,415 specifications constitute usable real-world verification tasks, as unvalidated translations risk systematic mismatches in quantifiers, side effects, or Python runtime modeling.
Authors: We agree that the current version of the manuscript does not report specific numerical values for coverage and quality metrics, nor does it describe independent semantic validation procedures such as manual equivalence checks. In the revision we will add a new subsection to the Evaluation section that reports the concrete metrics (including error rates), describes the validation protocol used on a sample of translations, and discusses any observed mismatches in quantifiers or runtime modeling. This will directly support the usability claim. revision: yes
-
Referee: [Pipeline description] Pipeline description: The three-agent LLM approach is presented as addressing the challenges of modeling Python semantics (mutability, exceptions) and inferring logical properties in dependently-typed Lean, but the manuscript does not detail failure modes, prompt strategies for runtime behaviors, or how multiple formalizations per PBT were selected when none dominated on metrics. This directly affects whether the benchmark tests genuine verification rather than translation artifacts.
Authors: We acknowledge that the pipeline section currently lacks explicit discussion of observed failure modes, the precise prompt strategies employed for modeling runtime behaviors, and the selection rule for retaining multiple formalizations per PBT. The revised manuscript will expand this section with the requested details, including representative failure cases, prompt templates for exceptions and mutability, and the metric-based retention criterion. revision: yes
Circularity Check
No circularity; benchmark construction is data-driven and externally verifiable
full rationale
The paper presents a scraping and LLM-based translation pipeline to produce Lean specifications from Python PBTs, with all code, data, and artifacts released openly. No mathematical derivations, fitted predictions, self-definitional equations, or load-bearing self-citations are present. The central outputs (9,415 Lean specs) are independently checkable via the released repository, satisfying the criteria for a self-contained, non-circular benchmarking effort.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Attanasio
M. Attanasio. Radon: Python code metrics. https://radon.readthedocs.io/en/latest/. Accessed 2025
2025
-
[2]
Ayers, Dragomir Radev, and Jeremy Avigad
Z. Azerbayev, B. Piotrowski, H. Schoelkopf, E. W. Ayers, D. Radev, and J. Avigad. Proofnet: Autoformalizing and formally proving undergraduate-level mathematics.arXiv preprint arXiv:2302.12433, 2023. 12
-
[3]
Bansal, S
K. Bansal, S. Loos, M. Rabe, C. Szegedy, and S. Wilcox. Holist: An environment for machine learning of higher order logic theorem proving. InInternational conference on machine learning, pages 454–463. PMLR, 2019
2019
-
[4]
Barkallah, S
S. Barkallah, S. Daruru, B. Miranda, L. Aniva, A. Nie, and S. Koyejo. VeriBench-FTP: A formal theorem proving benchmark in Lean 4 for code verification. InThe 5th Workshop on Mathematical Reasoning and AI at NeurIPS 2025, 2025
2025
-
[5]
D. Beyer. State of the art in software verification and witness validation: SV-COMP 2025. In Proceedings of the 31st International Conference on Tools and Algorithms for the Construction and Analysis of Systems (TACAS), 2025
2025
-
[6]
D. Brandfonbrener, L. Beurerkellner, D. Romero, N. Amin, and M. Vechev. miniCodeProps: a minimal benchmark for proving code properties.arXiv preprint arXiv:2406.11915, 2024
arXiv 2024
-
[7]
S. Buro, R. Crole, and I. Mastroeni. Equational logic and categorical semantics for multi- languages.Electronic Notes in Theoretical Computer Science, 352:79–103, 2020
2020
- [8]
-
[9]
Chakraborty, G
S. Chakraborty, G. Ebner, S. Bhat, S. Fakhoury, S. Fatima, S. Lahiri, and N. Swamy. Towards neural synthesis for SMT-assisted proof-oriented programming. InProceedings of the 47th International Conference on Software Engineering (ICSE), 2025
2025
-
[10]
H. Chen et al. VerusBench: A benchmark for automated verification of Rust with Verus.arXiv preprint arXiv:2409.13082, 2024
arXiv 2024
-
[11]
D. Dalrymple, J. Skalse, Y . Bengio, S. Russell, M. Tegmark, S. Seshia, S. Omohundro, C. Szegedy, B. Goldhaber, N. Ammann, A. Abate, J. Halpern, C. Barrett, D. Zhao, T. Zhi-Xuan, J. Wing, and J. Tenenbaum. Towards guaranteed safe AI: A framework for ensuring robust and reliable AI systems.arXiv preprint arXiv:2405.06624, 2024
-
[12]
N. A. David Dalrymple. Safeguarded ai. https://aria.org.uk/opportunity-spaces/ mathematics-for-safe-ai/safeguarded-ai/, 2025. Accessed 25 April 2026
2025
-
[13]
de Almeida Borges, A
A. de Almeida Borges, A. Casanueva Artís, J.-R. Falleri, E. J. Gallego Arias, É. Martin-Dorel, K. Palmskog, A. Serebrenik, and T. Zimmermann. Lessons for interactive theorem proving researchers from a survey of coq users.Journal of Automated Reasoning, 69(1):8, 2025
2025
-
[14]
L. DeV oe. The Hypothesis corpus. https://hypothesis.works/articles/ hypothesis-corpus/, 2026. Accessed April 2026
2026
-
[15]
the acl2 sedan
P. C. Dillinger, P. Manolios, D. Vroon, and J. S. Moore. Acl2s:“the acl2 sedan”.Electronic Notes in Theoretical Computer Science, 174(2):3–18, 2007
2007
-
[16]
M. Dodds. Formally verifying industry cryptography.IEEE Security & Privacy, 20(3):65–70,
-
[17]
doi: 10.1109/MSEC.2022.3153035
-
[18]
Q. Dougherty and R. Mehta. Proving the coding interview: A benchmark for formally verified code generation. InProceedings of the LLM4Code Workshop at the 47th Interna- tional Conference on Software Engineering (ICSE), Ottawa, Ontario, Canada, 2025. doi: 10.48550/arXiv.2502.05714
-
[19]
FrontierMath: A Benchmark for Evaluating Advanced Mathematical Reasoning in AI
E. Glazer, E. Erdil, T. Besiroglu, D. Chicharro, E. Chen, A. Gunning, C. Falkman Olsson, J.-S. Denain, A. Ho, E. de Oliveira Santos, O. Järviniemi, M. Barnett, R. Sandler, M. Vrzala, J. Sevilla, Q. Ren, E. Pratt, L. Levine, G. Barkley, N. Stewart, B. Grechuk, T. Grechuk, S. Varma Enugandla, and M. Wildon. FrontierMath: A benchmark for evaluating advanced ...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[20]
Gopinathan
K. Gopinathan. Lean proved this program was correct; then I found a bug. https:// kirancodes.me/posts/log-who-watches-the-watchers.html , Apr. 2026. Blog post; reports a heap buffer overflow inlean_alloc_sarray in the Lean 4 runtime, found by AFL++ fuzzing of the verifiedlean-ziplibrary. Accessed 26 April 2026. 13
2026
-
[21]
M. H. Halstead.Elements of Software Science (Operating and Programming Systems Series). Elsevier Science Inc., 1977
1977
-
[22]
Hendrycks, S
D. Hendrycks, S. Basart, S. Kadavath, M. Mazeika, A. Arora, E. Guo, C. Burns, S. Puranik, H. He, D. Song, and J. Steinhardt. Measuring coding challenge competence with APPS. In Proceedings of the 35th Conference on Neural Information Processing Systems (NeurIPS), 2021
2021
-
[23]
Hsiang, W
R. Hsiang, W. Adkisson, R. J. George, and A. Anandkumar. LeanDojo-v2: A comprehensive library for AI-assisted theorem proving in Lean. InThe 5th Workshop on Mathematical Reasoning and AI at NeurIPS 2025, 2025
2025
- [24]
- [25]
-
[26]
D. Jackson and J. M. Wing. Lightweight formal methods.IEEE Computer, 29(4):21–22, 1996. doi: 10.1109/2.491459
-
[27]
Jacques, L
V . Jacques, L. Wan, S. Kowalik, and E. Minack. PyGitHub. https://github.com/ PyGithub/PyGithub, 2026. Accessed 26 April 2026
2026
- [28]
-
[29]
C. E. Jimenez, J. Yang, A. Wettig, S. Yao, K. Pei, O. Press, and K. Narasimhan. SWE-bench: Can language models resolve real-world GitHub issues? InProceedings of the 12th International Conference on Learning Representations (ICLR), 2024
2024
-
[30]
Klein, K
G. Klein, K. Elphinstone, G. Heiser, J. Andronick, D. Cock, P. Derrin, D. Elkaduwe, K. Engel- hardt, R. Kolanski, M. Norrish, et al. sel4: Formal verification of an os kernel. InProceedings of the ACM SIGOPS 22nd symposium on Operating systems principles, pages 207–220, 2009
2009
-
[31]
Comparator: A trustworthy judge for Lean proofs
Lean FRO. Comparator: A trustworthy judge for Lean proofs. https://github.com/ leanprover/comparator, 2026. Sandboxes the build and replays proof terms, optionally cross-checking against an independently-implemented Rust kernel (nanoda). Accessed 26 April 2026
2026
-
[32]
Leroy, S
X. Leroy, S. Blazy, D. Kästner, B. Schommer, M. Pister, and C. Ferdinand. Compcert-a formally verified optimizing compiler. InERTS 2016: Embedded Real Time Software and Systems, 8th European Congress, 2016
2016
-
[33]
S. Li, W. Lu, X. Shi, K. Weng, H. Sun, M. Yu, T. Zhang, G. Yu, H. Liu, and L. Du. MSC-180: A benchmark for automated formal theorem proving from mathematical subject classification. arXiv preprint arXiv:2512.18256, 2025
arXiv 2025
- [34]
-
[35]
C. Loughridge, Q. Sun, S. Ahrenbach, F. Cassano, C. Sun, Y . Sheng, A. Mudide, M. R. H. Misu, N. Amin, and M. Tegmark. DafnyBench: A benchmark for formal software verification.arXiv preprint arXiv:2406.08467, 2024
- [36]
-
[37]
P. Lu, J. Sheng, L. Lyu, J. Jin, T. Xia, A. Gu, and J. Zou. Solving inequality proofs with large language models. InThe 39th Conference on Neural Information Processing Systems (NeurIPS), 2025. 14
2025
-
[38]
X. Ma et al. VeriEquivBench: Evaluating verifiable agents on novel data without contamination. arXiv preprint arXiv:2510.06296, 2025
Pith/arXiv arXiv 2025
-
[39]
D. R. MacIver, Z. Hatfield-Dodds, and many other contributors. Hypothesis: A new approach to property-based testing.Journal of Open Source Software, 4(43):1891, 2019. doi: 10.21105/ joss.01891
2019
-
[40]
Q. D. Max von Hippel. Lies, damned lies, and proofs: Formal methods are not slopless. https://www.lesswrong.com/posts/rhAPh3YzhPoBNpgHg/ lies-damned-lies-and-proofs-formal-methods-are-not-slopless , Jan. 2026. Accessed 26 April 2026
2026
-
[41]
T. J. McCabe. A complexity measure.IEEE Transactions on Software Engineering, (4): 308–320, 1976
1976
-
[42]
Miyazono
E. Miyazono. Formally scalable AI oversight through specifications. https://foresight. org/resource/evan-miyazono-formally-scalable-ai-oversight-through-specifications/ ,
-
[43]
Accessed 25 April 2026
2026
-
[44]
J. T. Perconti and A. Ahmed. Verifying an open compiler using multi-language semantics. InEuropean Symposium on Programming Languages and Systems, pages 128–148. Springer, 2014
2014
-
[45]
Poiroux, G
A. Poiroux, G. Weiss, V . Kunˇcak, and A. Bosselut. Reliable evaluation and benchmarks for statement autoformalization. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 17958–17980, 2025
2025
-
[46]
Rasmussen
J. Rasmussen. Risk management in a dynamic society: a modelling problem.Safety science, 27 (2-3):183–213, 1997
1997
-
[47]
Z. Ren, Z. Shao, J. Song, H. Xin, H. Wang, W. Zhao, L. Zhang, Z. Fu, Q. Zhu, D. Yang, et al. Deepseek-prover-v2: Advancing formal mathematical reasoning via reinforcement learning for subgoal decomposition.arXiv preprint arXiv:2504.21801, 2025
Pith/arXiv arXiv 2025
- [48]
-
[49]
Stechly et al
K. Stechly et al. VeriBench: Benchmarking end-to-end formal verification. InAI4Math Workshop at ICML, 2025. URLhttps://openreview.net/forum?id=rWkGFmnSNl
2025
-
[50]
R. S. Team. 2025 state of rust survey results. https://blog.rust-lang.org/2026/03/ 02/2025-State-Of-Rust-Survey-results/, March 2026. Accessed 25 April 2026
2025
- [51]
-
[52]
K. Thompson, N. Saavedra, P. Carrott, K. Fisher, A. Sanchez-Stern, Y . Brun, J. F. Ferreira, S. Lerner, and E. First. Rango: Adaptive retrieval-augmented proving for automated software verification.arXiv preprint arXiv:2412.14063, 2024
-
[53]
Tsoukalas, J
G. Tsoukalas, J. Lee, J. Jennings, J. Xin, M. Ding, M. Jennings, A. Thakur, and S. Chaudhuri. Putnambench: Evaluating neural theorem-provers on the putnam mathematical competition. Advances in Neural Information Processing Systems, 37:11545–11569, 2024
2024
-
[54]
Inspect AI: Framework for large language model evaluations, 2024
UK AI Security Institute. Inspect AI: Framework for large language model evaluations, 2024. URLhttps://github.com/UKGovernmentBEIS/inspect_ai
2024
-
[55]
von Hippel
M. von Hippel. https://www.lesswrong.com/posts/SfhFh9Hfm6JYvzbby/ the-scalable-formal-oversight-research-program , 2026. Accessed 25 April 2026
2026
-
[56]
T.-Y . Wu et al. InvBench: A benchmark for loop invariant synthesis.arXiv preprint arXiv:2509.21629, 2025. 15 Table 2: PBT corpus statistics. Metric Value PBTs (raw scrape) 54,345 PBTs (post-dedup) 11,039 Unique repositories 333 Unique GitHub owners 281 Upstream project names 303 Top-1 / top-10 PBT share 8.7% / 58.5% Per-repo (min / med / max): PBTs per r...
- [57]
- [58]
-
[59]
H. Ying, Z. Wu, Y . Geng, J. Wang, D. Lin, and K. Chen. Lean workbook: A large-scale lean problem set formalized from natural language math problems.Advances in Neural Information Processing Systems, 37:105848–105863, 2024
2024
- [60]
-
[61]
K. Zheng, J. M. Han, and S. Polu. Minif2f: a cross-system benchmark for formal olympiad-level mathematics.arXiv preprint arXiv:2109.00110, 2021. A Comparison with the Hypothesis Corpus While we were finalizing this work, the Hypothesis maintainers released their own scraped corpus [14] (HC-2026). The two corpora target different downstream uses—HC-2026 is...
Pith/arXiv arXiv 2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.