PIU: Proximity-guided Identity Unlearning in ID-Conditioned Diffusion Models
Pith reviewed 2026-05-22 06:56 UTC · model grok-4.3
The pith
Reassigning a target identity to a nearby anchor in the embedding space and fine-tuning only cross-attention layers removes that identity from an ID-conditioned face diffusion model.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
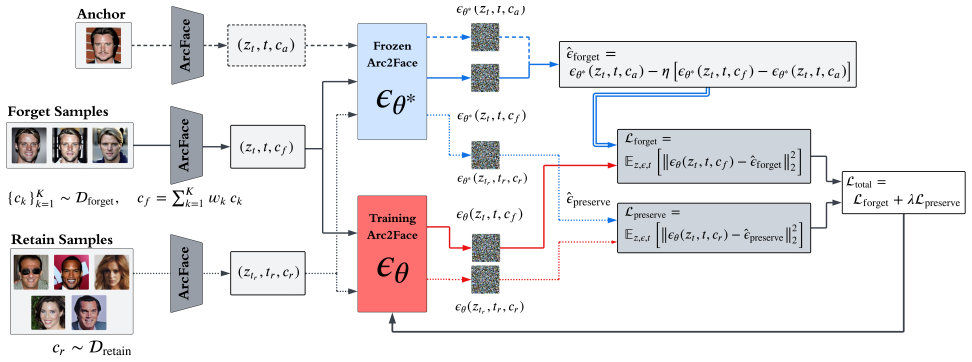
Identity removal is formulated as an identity replacement objective that reassigns the source identity to a proximity-selected anchor identity in the learned identity space, with effective unlearning achieved through localized fine-tuning of a small subset of identity-sensitive cross-attention layers in models such as Arc2Face.
What carries the argument
Proximity-based anchor selection in the ArcFace identity space that guides an identity replacement objective, implemented via targeted updates to cross-attention layers.
If this is right
- The target identity generation is suppressed across tested cases
- Realism and identity consistency remain intact for retained identities
- Unlearning and image-quality metrics show improvement
- Qualitative results confirm suppression without visible new artifacts
Where Pith is reading between the lines
- The same proximity replacement idea could be tested in other embedding-conditioned generators outside face synthesis
- Geometric structure in identity embeddings may enable selective forgetting in additional privacy-sensitive generation tasks
Load-bearing premise
Reassigning the source identity to a proximity-selected anchor identity in the learned identity space, combined with localized fine-tuning of cross-attention layers, removes the original identity's influence without degrading overall model performance or introducing new artifacts.
What would settle it
A test in which the fine-tuned model still generates recognizable images of the target identity at rates comparable to the original model when conditioned on its embedding, or in which image quality and consistency metrics drop for retained identities.
Figures















read the original abstract
Identity-conditioned diffusion models enable high-quality and identity-consistent face generation, but they also raise severe privacy concerns, as models may continue to synthesize individuals despite their right to be forgotten. While machine unlearning has been extensively studied for concept and data removal, identity unlearning remains largely unexplored, particularly in models conditioned directly on identity embeddings rather than text prompts. In this work, we study identity unlearning in Arc2Face, a state-of-the-art identity-conditioned latent diffusion model for face generation, and introduce Proximity-guided Identity Unlearning (PIU), an anchor-guided framework for identity unlearning. Specifically, we formulate identity removal as an identity replacement objective that reassigns the source identity to a selected anchor identity in the learned identity space, and we complement it with a proximity-based anchor selection strategy motivated by the geometry of ArcFace representations. We further show that effective unlearning can be achieved through localized fine-tuning of a small subset of identity-sensitive cross-attention layers. Experiments across many target identities show that our framework effectively suppresses generation of the target identity while preserving realism and identity consistency for retained identities, as validated by improved performance on unlearning and image-quality metrics, together with qualitative evaluation. The source code for the PIU framework is publicly available at https://github.com/edgarcancinoe/piu_unlearning .
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Proximity-guided Identity Unlearning (PIU) for removing specific identities from identity-conditioned diffusion models such as Arc2Face. The method reassigns the source identity embedding to a proximity-selected anchor identity in ArcFace space and performs localized fine-tuning on a small subset of identity-sensitive cross-attention layers. The central claim is that this suppresses generation of the target identity while preserving realism and identity consistency for retained identities, as shown by improved unlearning and image-quality metrics plus qualitative results across many target identities. Code is released publicly.
Significance. If the effectiveness claims hold under rigorous controls, the work would be significant for privacy in generative face models by providing a practical, geometry-motivated approach to identity unlearning that avoids full retraining. The use of ArcFace proximity for anchor selection and targeted layer updates is a targeted contribution; public code release aids reproducibility.
major comments (2)
- [§4 Experiments] §4 Experiments: the claim that the framework 'effectively suppresses generation of the target identity' is supported only by assertions of 'improved performance on unlearning and image-quality metrics' without reported numerical values, standard deviations, exact number of identities, or explicit baselines/controls, rendering the quantitative evidence for the central claim unverifiable from the given description.
- [§3.2] §3.2 (localized fine-tuning description): the premise that reassigning to a proximity anchor plus updates confined to cross-attention layers removes the original identity's generative influence lacks a direct test for residual leakage (e.g., whether the unmodified source embedding can still elicit the target face under post-unlearning sampling or adversarial optimization); this is load-bearing for the removal claim.
minor comments (1)
- [Abstract] Abstract: the phrase 'across many target identities' would be strengthened by stating the exact count and selection criteria used.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed feedback. We address each major comment below and will revise the manuscript to improve clarity and strengthen the supporting evidence for our claims.
read point-by-point responses
-
Referee: [§4 Experiments] §4 Experiments: the claim that the framework 'effectively suppresses generation of the target identity' is supported only by assertions of 'improved performance on unlearning and image-quality metrics' without reported numerical values, standard deviations, exact number of identities, or explicit baselines/controls, rendering the quantitative evidence for the central claim unverifiable from the given description.
Authors: We thank the referee for this observation on the presentation of results. The submitted manuscript reports quantitative improvements via figures and tables in §4 (and supplementary material) that include specific metric values for unlearning effectiveness (e.g., identity similarity) and image quality (e.g., FID), along with comparisons to baselines. However, to enhance verifiability in the main text, we will revise §4 to explicitly tabulate the numerical values with standard deviations, state the exact number of target identities evaluated (50), and include additional explicit baseline comparisons such as full-model fine-tuning and random-anchor selection. These revisions will be made in the next version. revision: yes
-
Referee: [§3.2] §3.2 (localized fine-tuning description): the premise that reassigning to a proximity anchor plus updates confined to cross-attention layers removes the original identity's generative influence lacks a direct test for residual leakage (e.g., whether the unmodified source embedding can still elicit the target face under post-unlearning sampling or adversarial optimization); this is load-bearing for the removal claim.
Authors: We agree that a direct test for residual leakage would strengthen the central removal claim. Our current evaluation in §3.2 and §4 demonstrates suppression via post-unlearning identity similarity scores (near-zero cosine similarity to the target) and qualitative results showing no recognizable target faces. To directly address residual leakage, we will add experiments in the revised manuscript: (1) sampling with the unmodified source embedding after PIU to measure retained identity similarity, and (2) an adversarial optimization attempt to recover the target identity from the post-unlearning model, reporting failure to reconstruct the original face. This will provide explicit evidence against residual generative influence. revision: yes
Circularity Check
No circularity: new unlearning objective and localized fine-tuning are independent of fitted inputs
full rationale
The paper proposes PIU as a novel anchor-guided replacement objective in ArcFace embedding space plus targeted cross-attention fine-tuning. These steps are explicitly motivated by external ArcFace geometry and presented as new components rather than redefinitions of prior fitted parameters. No equations reduce the unlearning metric or identity reassignment back to the source embedding by construction, and no self-citation chain is invoked to justify uniqueness or force the method. Experimental claims rest on independent unlearning and quality metrics across multiple identities, making the derivation self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (2)
- proximity threshold or number of candidate anchors
- identity-sensitive cross-attention layers subset
axioms (1)
- domain assumption The geometry of ArcFace representations provides a reliable basis for selecting anchor identities that enable effective unlearning.
Reference graph
Works this paper leans on
-
[1]
S. Alberti, K. Hasanaliyev, M. Shah, and S. Ermon. Data unlearning in diffusion models. InInternational Conference on Learning Representations (ICLR), pages 1–17, 2025
work page 2025
- [2]
-
[3]
L. Bourtoule, V . Chandrasekaran, C. A. Choquette-Choo, H. Jia, A. Travers, B. Zhang, D. Lie, and N. Papernot. Ma- chine unlearning. InIEEE Symposium on Security and Pri- vacy (SP), pages 141–159, 2021
work page 2021
-
[4]
F. Boutros, V . Struc, J. Fierrez, and N. Damer. Synthetic data for face recognition: Current state and future prospects. Image and Vision Computing, 135:104688, 2023
work page 2023
-
[5]
N. Carlini, J. Hayes, M. Nasr, M. Jagielski, V . Sehwag, F. Tramer, B. Balle, D. Ippolito, and E. Wallace. Extract- ing training data from diffusion models. InUSENIX Security Symposium, pages 5253–5270, 2023
work page 2023
-
[6]
Q. Chen, C.-W. Cheng, X. Su, H. Xu, X. Lin, S. You, A. I. Aviles-Rivero, and Y . Chen. Legato: Good identity unlearn- ing is continuous.arXiv preprint arXiv:2601.04282, 2026
-
[7]
J. Deng, J. Guo, N. Xue, and S. Zafeiriou. Arcface: Additive angular margin loss for deep face recognition. InIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 4690–4699, 2019
work page 2019
-
[8]
M. Ester, H.-P. Kriegel, J. Sander, X. Xu, et al. A density- based algorithm for discovering clusters in large spatial databases with noise. InInternational Conference on Knowl- edge Discovery and Data Mining (KDD), volume 96, pages 226–231, 1996
work page 1996
-
[9]
C. Fan, J. Liu, Y . Zhang, E. Wong, D. Wei, and S. Liu. Salun: Empowering machine unlearning via gradient-based weight saliency in both image classification and generation.arXiv preprint arXiv:2310.12508, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[10]
R. Gal, Y . Alaluf, Y . Atzmon, O. Patashnik, A. H. Bermano, G. Chechik, and D. Cohen-Or. An image is worth one word: Personalizing text-to-image generation using textual inver- sion.arXiv preprint arXiv:2208.01618, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[11]
R. Gandikota, J. Materzynska, J. Fiotto-Kaufman, and D. Bau. Erasing concepts from diffusion models. In IEEE/CVF International Conference on Computer Vision (ICCV), pages 2426–2436, 2023
work page 2023
-
[12]
R. Gandikota, H. Orgad, Y . Belinkov, J. Materzy ´nska, and D. Bau. Unified concept editing in diffusion models. In IEEE/CVF Winter conference on Applications of Computer Vision (WACV), pages 5111–5120, 2024
work page 2024
-
[13]
E. Goldman. An introduction to the california consumer pri- vacy act (CCPA).Santa Clara Univ. Legal Studies Research Paper, 2020
work page 2020
-
[14]
I. J. Goodfellow, J. Pouget-Abadie, M. Mirza, B. Xu, D. Warde-Farley, S. Ozair, A. Courville, and Y . Bengio. Gen- erative adversarial nets.Advances in Neural Information Processing Systems (NeurIPS), 27, 2014
work page 2014
-
[15]
A. Gretton, K. Borgwardt, M. Rasch, B. Sch ¨olkopf, and A. Smola. A kernel method for the two-sample-problem.Ad- vances in Neural Information Processing Systems (NeurIPS), 19, 2006
work page 2006
-
[16]
A. Heng and H. Soh. Selective amnesia: A continual learn- ing approach to forgetting in deep generative models.Ad- vances in Neural Information Processing Systems (NeurIPS), 36:17170–17194, 2023
work page 2023
- [17]
-
[18]
J. Ho, A. Jain, and P. Abbeel. Denoising diffusion probabilis- tic models. InAdvances in Neural Information Processing Systems (NeurIPS), volume 33, pages 6840–6851, 2020
work page 2020
-
[19]
Classifier-Free Diffusion Guidance
J. Ho and T. Salimans. Classifier-free diffusion guidance. arXiv preprint arXiv:2207.12598, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
- [20]
- [21]
- [22]
- [23]
-
[24]
Z. Li, M. Cao, X. Wang, Z. Qi, M.-M. Cheng, and Y . Shan. Photomaker: Customizing realistic human pho- tos via stacked id embedding. InIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 8640–8650, 2024
work page 2024
-
[25]
Z. Liu, K. Chen, Y . Zhang, J. Han, L. Hong, H. Xu, Z. Li, D.- Y . Yeung, and J. T. Kwok. Implicit concept removal of diffu- sion models. InSpringer European Conference on Computer Vision (ECCV), pages 457–473, 2024
work page 2024
-
[26]
C. Lu, Y . Zhou, F. Bao, J. Chen, C. Li, and J. Zhu. DPM- Solver++: Fast solver for guided sampling of diffusion prob- abilistic models.Machine Intelligence Research (MIR), 22(4):730–751, 2025
work page 2025
- [27]
-
[28]
F. P. Papantoniou, A. Lattas, S. Moschoglou, J. Deng, B. Kainz, and S. Zafeiriou. Arc2face: A foundation model for id-consistent human faces. InSpringer European Con- ference on Computer Vision (ECCV), pages 241–261, 2024
work page 2024
-
[29]
D. Protection. General data protection regulation.Intersoft Consulting, Accessed in October, 24(1), 2018
work page 2018
-
[30]
F. Qi, A. Liu, Z. Zhang, and C. Xu. Forget me: Feder- ated unlearning for face generation models. InACM In- ternational Conference on Multimedia (ICK), pages 11288– 11297, 2025
work page 2025
-
[31]
A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agarwal, G. Sastry, A. Askell, P. Mishkin, J. Clark, et al. Learning transferable visual models from natural language supervision. InPMLR International Conference on Machine Learning (ICML), pages 8748–8763, 2021
work page 2021
-
[32]
R. Rombach, A. Blattmann, D. Lorenz, P. Esser, and B. Om- mer. High-resolution image synthesis with latent diffusion models. InIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 10684–10695, 2022
work page 2022
-
[33]
O. Ronneberger, P. Fischer, and T. Brox. U-net: Convo- lutional networks for biomedical image segmentation. In Springer International Conference on Medical Image Com- puting and Computer-Assisted Intervention (MICCAI), pages 234–241, 2015
work page 2015
-
[34]
N. Ruiz, Y . Li, V . Jampani, Y . Pritch, M. Rubinstein, and K. Aberman. Dreambooth: Fine tuning text-to-image dif- fusion models for subject-driven generation. InIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 22500–22510, 2023
work page 2023
-
[35]
F. Schroff, D. Kalenichenko, and J. Philbin. Facenet: A unified embedding for face recognition and clustering. In IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 815–823, 2015
work page 2015
- [36]
-
[37]
M. Shaheryar, J. T. Lee, and S. K. Jung. Black hole-driven identity absorbing in diffusion models. InIEEE/CVF Com- puter Vision and Pattern Recognition Conference (CVPR), pages 28544–28554, 2025
work page 2025
-
[38]
M. Shaheryar, J. T. Lee, and S. K. Jung. Unlearn and pro- tect: Selective identity removal in diffusion models for pri- vacy preservation. InACM/SIGAPP Symposium on Applied Computing, pages 1172–1179, 2025
work page 2025
-
[39]
G. Somepalli, V . Singla, M. Goldblum, J. Geiping, and T. Goldstein. Diffusion art or digital forgery? investigating data replication in diffusion models. InIEEE/CVF Confer- ence on Computer Vision and Pattern Recognition (CVPR), pages 6048–6058, 2023
work page 2023
-
[40]
G. Somepalli, V . Singla, M. Goldblum, J. Geiping, and T. Goldstein. Understanding and mitigating copying in dif- fusion models.Advances in Neural Information Processing Systems (NeurIPS), 36:47783–47803, 2023
work page 2023
-
[41]
G. Stein, J. Cresswell, R. Hosseinzadeh, Y . Sui, B. Ross, V . Villecroze, Z. Liu, A. L. Caterini, E. Taylor, and G. Loaiza-Ganem. Exposing flaws of generative model eval- uation metrics and their unfair treatment of diffusion mod- els.Advances in Neural Information Processing Systems (NeurIPS), 36:3732–3784, 2023
work page 2023
-
[42]
D. Toma ˇsevi´c, F. Boutros, C. Lin, N. Damer, V . ˇStruc, and P. Peer. Id-booth: Identity-consistent face generation with diffusion models. InIEEE International Conference on Au- tomatic Face and Gesture Recognition (FG), pages 1–10, 2025
work page 2025
- [43]
-
[44]
J. Wu, T. Le, M. Hayat, and M. Harandi. Erasing undesir- able influence in diffusion models. InIEEE/CVF Computer Vision and Pattern Recognition Conference (CVPR), pages 28263–28273, 2025
work page 2025
-
[45]
G. Xiao, T. Yin, W. T. Freeman, F. Durand, and S. Han. Fast- composer: Tuning-free multi-subject image generation with localized attention.Springer International Journal of Com- puter Vision (IJCV), 133(3):1175–1194, 2025
work page 2025
-
[46]
Z. Yan, Y . Zhang, Y . Fan, and B. Wu. Ucf: Uncover- ing common features for generalizable deepfake detection. InIEEE/CVF International Conference on Computer Vision (ICCV), pages 22412–22423, 2023
work page 2023
-
[47]
H. Ye, J. Zhang, S. Liu, X. Han, and W. Yang. IP-adapter: Text compatible image prompt adapter for text-to-image dif- fusion models.arXiv preprint arXiv:2308.06721, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[48]
xt −γ tx σt −ϵ θ(xt, t) 2 2 # ,(14) and La(θ) :=E a∼pA at∼q(·|a)
Y . Zhang, E. Jin, Y . Dong, Y . Wu, P. Torr, A. Khakzar, J. Stegmaier, and K. Kawaguchi. Minimalist concept era- sure in generative models.arXiv preprint arXiv:2507.13386, 2025. PIU: Proximity-Guided Identity Unlearning in ID-Conditioned Diffusion Models Supplementary Material A. Additional Experimentation Details Dataset Details.As explained in Section ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.