Beyond the Reranker: Do RAG Retrieval Enhancements Help Once a Strong Reranker Is Present?
Pith reviewed 2026-06-30 10:57 UTC · model grok-4.3
The pith
A strong cross-encoder reranker accounts for most RAG pipeline quality, with only query expansion and SSCC adding reliable gains.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
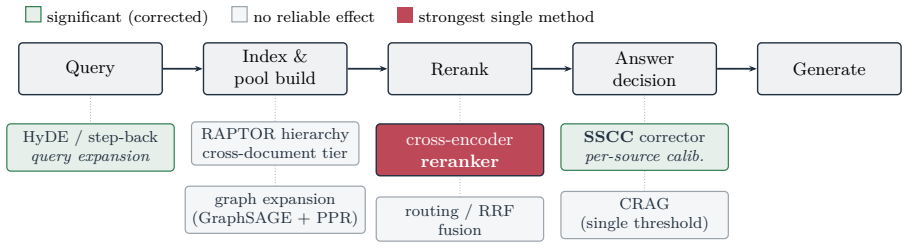
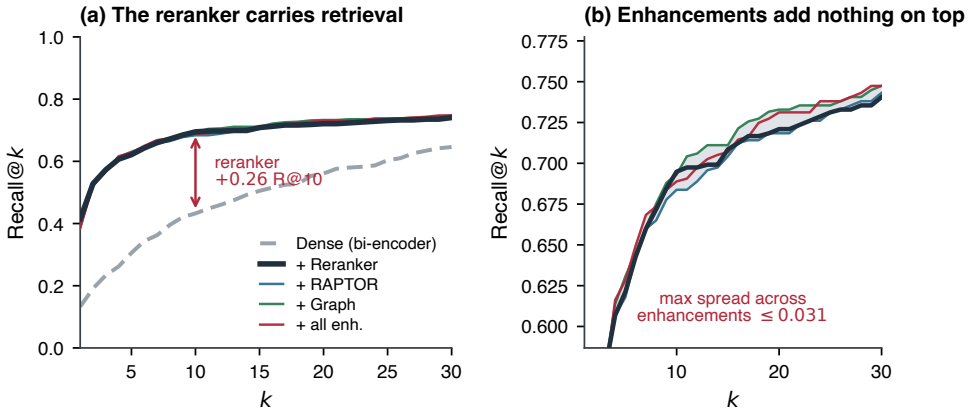
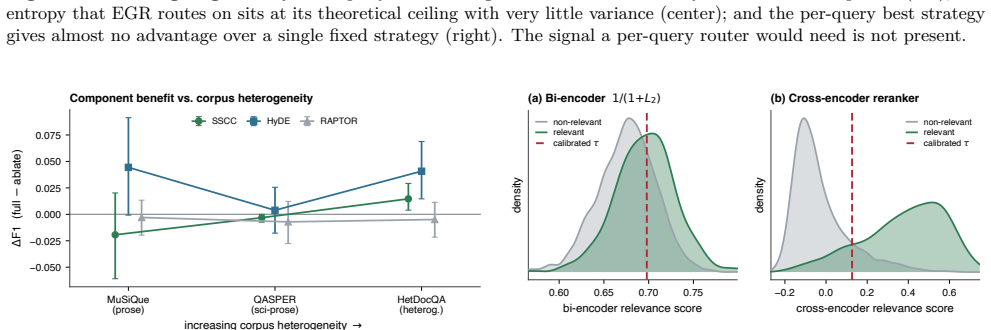
A strong cross-encoder reranker accounts for most of the pipeline's quality; beyond it, only two methods yield reliable gains: query expansion and SSCC. SSCC, a per-source calibrated corrector introduced here, sets a separate acceptance threshold for each score source and helps only on heterogeneous data. The remaining reranking and pool-expansion methods in common use, among them hierarchical summarization, graph expansion, routing, and rank fusion, give no reliable gain once that reranker is present.
What carries the argument
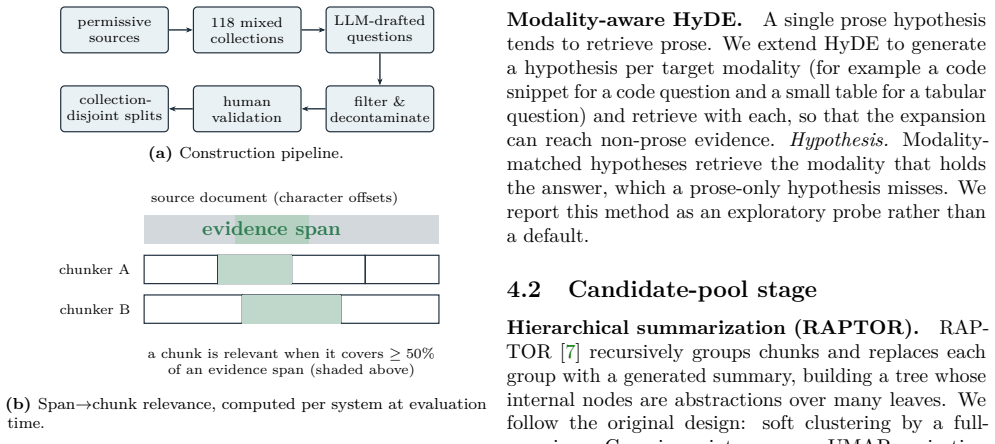
HetDocQA benchmark with chunker-agnostic span-overlap relevance labels, evaluated on a shared backbone with cross-encoder reranker and multiple-comparison-corrected bootstrap intervals across heterogeneous and homogeneous collections.
If this is right
- Query expansion produces reliable gains even after a strong reranker is applied.
- SSCC improves performance only when the collection contains heterogeneous document formats.
- Hierarchical summarization, graph expansion, per-query routing, and rank fusion add no reliable improvement once the reranker is present.
- Benefits observed for retrieval methods on homogeneous corpora do not appear on the mixed-format collections typical in practice.
Where Pith is reading between the lines
- RAG systems could simplify by focusing compute on the reranker stage rather than adding multiple retrieval layers.
- Future RAG benchmarks should include heterogeneous document mixes to avoid overstating method gains.
- SSCC may generalize to any retrieval setup that combines multiple score sources with differing calibration.
Load-bearing premise
Span-overlap relevance labels in HetDocQA accurately reflect downstream question-answering utility on mixed-format documents.
What would settle it
An end-to-end QA accuracy measurement on a real mixed-format corpus showing that graph expansion or rank fusion improves answers when paired with the same strong reranker and a different relevance labeling scheme.
Figures
read the original abstract
Retrieval-augmented generation (RAG) is routinely extended with methods meant to improve retrieval: query expansion, hierarchical and cross-document summarization, graph-based expansion, per-query routing, rank fusion, and corrective re-retrieval. The benefits reported for these methods come almost exclusively from homogeneous corpora, predominantly Wikipedia prose. Whether they hold on the mixed-format collections common in practice, where code, markdown, tables, scientific PDFs, and prose are interleaved within one corpus, has not been measured. To study this directly, we build \textbf{HetDocQA}, a heterogeneous benchmark with \emph{chunker-agnostic} span-overlap relevance labels and collection-disjoint splits, and pair it with MuSiQue and QASPER as homogeneous controls. We evaluate eight methods on a shared backbone, with bootstrap confidence intervals and multiple-comparison correction. A strong cross-encoder reranker accounts for most of the pipeline's quality; beyond it, only two methods yield reliable gains: query expansion and SSCC. SSCC, a per-source calibrated corrector introduced here, sets a separate acceptance threshold for each score source and helps only on heterogeneous data. The remaining reranking and pool-expansion methods in common use, among them hierarchical summarization, graph expansion, routing, and rank fusion, give no reliable gain once that reranker is present.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper constructs HetDocQA, a heterogeneous document QA benchmark using chunker-agnostic span-overlap relevance labels and collection-disjoint splits, and evaluates eight RAG retrieval enhancement methods (including query expansion, hierarchical summarization, graph expansion, routing, rank fusion, and the new SSCC) against homogeneous controls (MuSiQue, QASPER). Using a shared backbone and strong cross-encoder reranker, with bootstrap confidence intervals and multiple-comparison correction, it concludes that the reranker accounts for most pipeline quality and that only query expansion and SSCC yield reliable additional gains on heterogeneous data; the other methods show no reliable gains once the reranker is present.
Significance. If the results hold, the work indicates that many standard RAG retrieval enhancements add little value beyond a strong reranker on mixed-format corpora, which could simplify production pipelines and redirect research effort. Strengths include the new benchmark addressing a gap in heterogeneous evaluation, explicit use of bootstrap CIs with multiple-comparison correction for reliable empirical claims, collection-disjoint splits, and the introduction of SSCC which shows targeted gains on heterogeneous data.
major comments (2)
- [§3] §3 (HetDocQA construction): The central claim that only query expansion and SSCC yield reliable gains (while hierarchical summarization, graph expansion, routing, and rank fusion do not) depends on span-overlap labels being faithful proxies for downstream QA utility. On mixed-format collections (code, tables, PDFs), these labels risk missing paraphrases, cross-format synthesis, and partial matches that matter for actual utility, which could make the 'no reliable gain' results metric artifacts rather than pipeline behavior.
- [§4] §4 (experimental results): The no-gain conclusions for reranking and pool-expansion methods are reported with bootstrap CIs and correction, but without any reported correlation between the span-overlap labels and end-task QA accuracy on heterogeneous documents, it is unclear whether the metric choice drives the differential effectiveness claims across methods.
minor comments (2)
- The abstract states the main finding clearly but could specify the exact number of methods and the shared backbone model used for all comparisons.
- SSCC is described as setting 'a separate acceptance threshold for each score source'; a short additional sentence on how thresholds are calibrated (e.g., on a validation split) would improve clarity without lengthening the paper.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our work. The points raised about the proxy nature of span-overlap labels are substantive and merit explicit discussion in the manuscript. We respond to each major comment below and will incorporate clarifications via partial revisions.
read point-by-point responses
-
Referee: [§3] §3 (HetDocQA construction): The central claim that only query expansion and SSCC yield reliable gains (while hierarchical summarization, graph expansion, routing, and rank fusion do not) depends on span-overlap labels being faithful proxies for downstream QA utility. On mixed-format collections (code, tables, PDFs), these labels risk missing paraphrases, cross-format synthesis, and partial matches that matter for actual utility, which could make the 'no reliable gain' results metric artifacts rather than pipeline behavior.
Authors: We agree that span-overlap labels are an imperfect proxy and may miss paraphrases, cross-format synthesis, or partial matches relevant to actual QA utility on heterogeneous collections. This limitation is inherent to many lexical overlap metrics. The design choice was driven by the requirement for chunker-agnostic labels to enable fair evaluation across retrieval methods with varying chunking strategies, which is a core contribution of HetDocQA. Similar span-based labeling is standard in IR benchmarks. We will add an explicit discussion of this proxy limitation and its implications for result interpretation in §3, while keeping the core empirical claims tied to the retrieval metric. revision: partial
-
Referee: [§4] §4 (experimental results): The no-gain conclusions for reranking and pool-expansion methods are reported with bootstrap CIs and correction, but without any reported correlation between the span-overlap labels and end-task QA accuracy on heterogeneous documents, it is unclear whether the metric choice drives the differential effectiveness claims across methods.
Authors: We did not report a correlation between span-overlap labels and end-task QA accuracy, as the study centers on retrieval performance metrics under a consistent labeling scheme, following standard practice in RAG retrieval research. Computing such a correlation would necessitate full end-to-end QA experiments for every method on heterogeneous documents, which lies outside the current scope though it represents a useful future direction. The bootstrap CIs and multiple-comparison correction provide statistical support for the retrieval-level claims. We will add a clarifying paragraph in the discussion section acknowledging the proxy nature and the absence of direct QA correlation. revision: partial
Circularity Check
No circularity: purely empirical evaluation on new benchmark
full rationale
The paper reports experimental results from evaluating retrieval methods on the newly constructed HetDocQA benchmark (with MuSiQue and QASPER controls), using bootstrap confidence intervals and multiple-comparison correction. Central claims rest on direct measurements of retrieval quality with a shared backbone and cross-encoder reranker; no equations, derivations, fitted parameters renamed as predictions, or self-citation chains appear in the load-bearing steps. The introduction of SSCC is an empirical method contribution, not a self-referential reduction. This matches the default case of a self-contained empirical study.
Axiom & Free-Parameter Ledger
axioms (2)
- standard math Bootstrap resampling yields valid confidence intervals for retrieval metrics
- standard math Multiple-comparison correction appropriately controls error rate across eight methods
invented entities (2)
-
HetDocQA benchmark
no independent evidence
-
SSCC (per-source calibrated corrector)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Retrieval-augmented generation for knowledge- intensive NLP tasks
Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, Sebastian Riedel, and Douwe Kiela. Retrieval-augmented generation for knowledge- intensive NLP tasks. InAdvances in Neural In- formation Processing Systems (NeurIPS), 2020
2020
-
[2]
REALM: Retrieval- augmented language model pre-training
Kelvin Guu, Kenton Lee, Zora Tung, Panupong Pasupat, and Ming-Wei Chang. REALM: Retrieval- augmented language model pre-training. InInter- national Conference on Machine Learning (ICML), 2020
2020
-
[3]
Leveraging passage retrieval with generative models for open domain question answering
Gautier Izacard and Edouard Grave. Leveraging passage retrieval with generative models for open domain question answering. InProceedings of the European Chapter of the ACL (EACL), 2021
2021
-
[4]
Precise zero-shot dense retrieval without relevance labels
Luyu Gao, Xueguang Ma, Jimmy Lin, and Jamie Callan. Precise zero-shot dense retrieval without relevance labels. InProceedings of the Association for Computational Linguistics (ACL), 2023
2023
-
[5]
Chi, Quoc V
Huaixiu Steven Zheng, Swaroop Mishra, Xinyun Chen, Heng-Tze Cheng, Ed H. Chi, Quoc V. Le, and Denny Zhou. Take a step back: Evoking reasoning via abstraction in large language models. InInter- national Conference on Learning Representations (ICLR), 2024
2024
-
[6]
Query2doc: Query expansion with large language models
Liang Wang, Nan Yang, and Furu Wei. Query2doc: Query expansion with large language models. In Proceedings of Empirical Methods in Natural Lan- guage Processing (EMNLP), 2023
2023
-
[7]
Parth Sarthi, Salman Abdullah, Aditi Tuli, Shubh Khanna, Anna Goldie, and Christopher D. Manning. RAPTOR: Recursive abstractive processing for tree- organized retrieval. InInternational Conference on Learning Representations (ICLR), 2024
2024
-
[8]
From Local to Global: A Graph RAG Approach to Query-Focused Summarization
Darren Edge, Ha Trinh, Newman Cheng, Joshua Bradley, Alex Chao, Apurva Mody, Steven Truitt, Dasha Metropolitansky, Robert Osazuwa Ness, and Jonathan Larson. From local to global: A graph RAG approach to query-focused summarization. arXiv preprint arXiv:2404.16130, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[9]
HippoRAG: Neu- robiologically inspired long-term memory for large language models
Bernal Jiménez Gutiérrez, Yiheng Shu, Yu Gu, Michihiro Yasunaga, and Yu Su. HippoRAG: Neu- robiologically inspired long-term memory for large language models. InAdvances in Neural Informa- tion Processing Systems (NeurIPS), 2024
2024
-
[10]
Corrective Retrieval Augmented Generation
Shi-Qi Yan, Jia-Chen Gu, Yun Zhu, and Zhen-Hua Ling. Corrective retrieval augmented generation. arXiv preprint arXiv:2401.15884, 2024. 9
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[11]
Self-RAG: Learning to re- trieve, generate, and critique through self-reflection
Akari Asai, Zeqiu Wu, Yizhong Wang, Avirup Sil, and Hannaneh Hajishirzi. Self-RAG: Learning to re- trieve, generate, and critique through self-reflection. InInternational Conference on Learning Represen- tations (ICLR), 2024
2024
-
[12]
Xu, Luyu Gao, Zhiqing Sun, Qian Liu, Jane Dwivedi-Yu, Yiming Yang, Jamie Callan, and Graham Neubig
Zhengbao Jiang, Frank F. Xu, Luyu Gao, Zhiqing Sun, Qian Liu, Jane Dwivedi-Yu, Yiming Yang, Jamie Callan, and Graham Neubig. Active retrieval augmented generation. InProceedings of Empirical Methods in Natural Language Processing (EMNLP), 2023
2023
-
[13]
SoyeongJeong, JinheonBaek, SukminCho, SungJu Hwang, and Jong C. Park. Adaptive-RAG: Learning to adapt retrieval-augmented large language models through question complexity. InProceedings of the North American Chapter of the ACL (NAACL), 2024
2024
-
[14]
Cormack, Charles L
Gordon V. Cormack, Charles L. A. Clarke, and Ste- fan Buettcher. Reciprocal rank fusion outperforms Condorcet and individual rank learning methods. InProceedings of ACM SIGIR, 2009
2009
-
[15]
Natural questions: A bench- mark for question answering research.Transactions of the Association for Computational Linguistics (TACL), 2019
Tom Kwiatkowski, Jennimaria Palomaki, Olivia Redfield, Michael Collins, Ankur Parikh, Chris Al- berti, Danielle Epstein, Illia Polosukhin, Jacob De- vlin, Kenton Lee, et al. Natural questions: A bench- mark for question answering research.Transactions of the Association for Computational Linguistics (TACL), 2019
2019
-
[16]
Cohen, Ruslan Salakhutdinov, and Christopher D
Zhilin Yang, Peng Qi, Saizheng Zhang, Yoshua Ben- gio, William W. Cohen, Ruslan Salakhutdinov, and Christopher D. Manning. HotpotQA: A dataset for diverse, explainable multi-hop question answer- ing. InProceedings of Empirical Methods in Natural Language Processing (EMNLP), 2018
2018
-
[17]
MuSiQue: Multi- hop questions via single-hop question composition
Harsh Trivedi, Niranjan Balasubramanian, Tushar Khot, and Ashish Sabharwal. MuSiQue: Multi- hop questions via single-hop question composition. Transactions of the Association for Computational Linguistics (TACL), 2022
2022
-
[18]
Constructing a multi- hop QA dataset for comprehensive evaluation of reasoning steps
Xanh Ho, Anh-Khoa Duong Nguyen, Saku Sug- awara, and Akiko Aizawa. Constructing a multi- hop QA dataset for comprehensive evaluation of reasoning steps. InProceedings of the International Conference on Computational Linguistics (COL- ING), 2020
2020
-
[19]
Smith, and Matt Gardner
Pradeep Dasigi, Kyle Lo, Iz Beltagy, Arman Cohan, Noah A. Smith, and Matt Gardner. A dataset of information-seeking questions and answers anchored in research papers. InProceedings of the North American Chapter of the ACL (NAACL), 2021
2021
-
[20]
Richard Yuanzhe Pang, Alicia Parrish, Nitish Joshi, Nikita Nangia, Jason Phang, Angelica Chen, Vishakh Padmakumar, Johnny Ma, Jana Thomp- son, He He, and Samuel R. Bowman. QuALITY: Question answering with long input texts, yes! In Proceedings of the North American Chapter of the ACL (NAACL), 2022
2022
-
[21]
Cross-granularity hypergraph retrieval-augmented generation for multi-hop ques- tion answering, 2025
Changjian Wang, Weihong Deng, Weili Guan, Quan Lu, and Ning Jiang. Cross-granularity hypergraph retrieval-augmented generation for multi-hop ques- tion answering, 2025
2025
-
[22]
A-RAG: Scaling agentic retrieval-augmented generation via hierarchical retrieval interfaces, 2026
Mingxuan Du, Benfeng Xu, Chiwei Zhu, Shaohan Wang, Pengyu Wang, Xiaorui Wang, and Zhendong Mao. A-RAG: Scaling agentic retrieval-augmented generation via hierarchical retrieval interfaces, 2026
2026
-
[23]
You don’t need pre-built graphs for RAG: Retrieval augmented gen- eration with adaptive reasoning structures, 2025
Shengyuan Chen, Chuang Zhou, Zheng Yuan, Qing- gang Zhang, Zeyang Cui, Hao Chen, Yilin Xiao, Jiannong Cao, and Xiao Huang. You don’t need pre-built graphs for RAG: Retrieval augmented gen- eration with adaptive reasoning structures, 2025
2025
-
[24]
Rea- soning in trees: Improving retrieval-augmented gen- eration for multi-hop question answering, 2026
Yuling Shi, Maolin Sun, Zijun Liu, Mo Yang, Yix- iong Fang, Tianran Sun, and Xiaodong Gu. Rea- soning in trees: Improving retrieval-augmented gen- eration for multi-hop question answering, 2026
2026
-
[25]
RAGRouter: Learning to route queries to multiple retrieval-augmented language models, 2025
Jiarui Zhang, Xiangyu Liu, Yong Hu, Chaoyue Niu, Fan Wu, and Guihai Chen. RAGRouter: Learning to route queries to multiple retrieval-augmented language models, 2025
2025
-
[26]
RouteRAG: Efficient retrieval-augmented genera- tion from text and graph via reinforcement learning, 2025
Yucan Guo, Miao Su, Saiping Guan, Zihao Sun, Xiaolong Jin, Jiafeng Guo, and Xueqi Cheng. RouteRAG: Efficient retrieval-augmented genera- tion from text and graph via reinforcement learning, 2025
2025
-
[27]
InfoGain-RAG: Boosting retrieval-augmented generation via document infor- mation gain-based reranking and filtering, 2025
Zihan Wang, Zihan Liang, Zhou Shao, Yufei Ma, Huangyu Dai, Ben Chen, Lingtao Mao, Chenyi Lei, Yuqing Ding, and Han Li. InfoGain-RAG: Boosting retrieval-augmented generation via document infor- mation gain-based reranking and filtering, 2025
2025
-
[28]
ParallelSearch: Train your LLMs to decompose query and search sub-queries in parallel with reinforcement learning, 2025
Shu Zhao, Tan Yu, Anbang Xu, Japinder Singh, Aa- ditya Shukla, and Rama Akkiraju. ParallelSearch: Train your LLMs to decompose query and search sub-queries in parallel with reinforcement learning, 2025
2025
-
[29]
Out of style: RAG’s fragility to linguistic variation, 2025
Tianyu Cao, Neel Bhandari, Akhila Yerukola, Akari Asai, and Maarten Sap. Out of style: RAG’s fragility to linguistic variation, 2025
2025
-
[30]
A system- atic review of key retrieval-augmented generation 10 (RAG) systems: Progress, gaps, and future direc- tions, 2025
Agada Joseph Oche, Ademola Glory Folashade, Tirthankar Ghosal, and Arpan Biswas. A system- atic review of key retrieval-augmented generation 10 (RAG) systems: Progress, gaps, and future direc- tions, 2025
2025
-
[31]
Retrieval-augmented genera- tion: A comprehensive survey of architectures, en- hancements, and robustness frontiers, 2025
Chaitanya Sharma. Retrieval-augmented genera- tion: A comprehensive survey of architectures, en- hancements, and robustness frontiers, 2025
2025
-
[32]
Towards global retrieval aug- mented generation: A benchmark for corpus-level reasoning, 2025
Qi Luo, Xiaonan Li, Tingshuo Fan, Xinchi Chen, and Xipeng Qiu. Towards global retrieval aug- mented generation: A benchmark for corpus-level reasoning, 2025
2025
-
[33]
Smucker, James Allan, and Ben Carterette
Mark D. Smucker, James Allan, and Ben Carterette. A comparison of statistical significance tests for information retrieval evaluation. InProceedings of ACM CIKM, 2007
2007
-
[34]
Bootstrap methods: Another look at the jackknife.The Annals of Statistics, 7(1):1–26, 1979
Bradley Efron. Bootstrap methods: Another look at the jackknife.The Annals of Statistics, 7(1):1–26, 1979
1979
-
[35]
A simple sequentially rejective multiple test procedure.Scandinavian Journal of Statistics, 6(2):65–70, 1979
Sture Holm. A simple sequentially rejective multiple test procedure.Scandinavian Journal of Statistics, 6(2):65–70, 1979
1979
-
[36]
Controlling the false discovery rate: A practical and powerful approach to multiple testing.Journal of the Royal Statistical Society: Series B, 57(1):289–300, 1995
Yoav Benjamini and Yosef Hochberg. Controlling the false discovery rate: A practical and powerful approach to multiple testing.Journal of the Royal Statistical Society: Series B, 57(1):289–300, 1995
1995
-
[37]
Dense passage retrieval for open-domain question answering
Vladimir Karpukhin, Barlas Oğuz, Sewon Min, Patrick Lewis, Ledell Wu, Sergey Edunov, Danqi Chen, and Wen-tau Yih. Dense passage retrieval for open-domain question answering. InProceedings of Empirical Methods in Natural Language Processing (EMNLP), 2020
2020
-
[38]
Unsupervised dense informa- tion retrieval with contrastive learning.Transac- tions on Machine Learning Research (TMLR), 2022
Gautier Izacard, Mathilde Caron, Lucas Hosseini, Sebastian Riedel, Piotr Bojanowski, Armand Joulin, and Edouard Grave. Unsupervised dense informa- tion retrieval with contrastive learning.Transac- tions on Machine Learning Research (TMLR), 2022
2022
-
[39]
Jianlv Chen, Shitao Xiao, Peitian Zhang, Kun Luo, Defu Lian, and Zheng Liu. BGE M3-Embedding: Multi-lingual, multi-functionality, multi-granularity text embeddings through self-knowledge distillation. arXiv preprint arXiv:2402.03216, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[40]
Sentence-BERT: SentenceembeddingsusingsiameseBERT-networks
Nils Reimers and Iryna Gurevych. Sentence-BERT: SentenceembeddingsusingsiameseBERT-networks. InProceedings of Empirical Methods in Natural Language Processing (EMNLP), 2019
2019
-
[41]
Document ranking with a pre- trained sequence-to-sequence model
Rodrigo Nogueira, Zhiying Jiang, Ronak Pradeep, and Jimmy Lin. Document ranking with a pre- trained sequence-to-sequence model. InFindings of the ACL: EMNLP, 2020
2020
-
[42]
ColBERTv2: Effective and efficient retrieval via lightweight late interaction
Keshav Santhanam, Omar Khattab, Jon Saad- Falcon, Christopher Potts, and Matei Zaharia. ColBERTv2: Effective and efficient retrieval via lightweight late interaction. InProceedings of the North American Chapter of the ACL (NAACL), 2022
2022
-
[43]
Weld, and Luke Zettlemoyer
Mandar Joshi, Eunsol Choi, Daniel S. Weld, and Luke Zettlemoyer. TriviaQA: A large scale distantly supervised challenge dataset for reading comprehen- sion. InProceedings of the Association for Compu- tational Linguistics (ACL), 2017
2017
-
[44]
MultiHop-RAG: Benchmarking Retrieval-Augmented Generation for Multi-Hop Queries
Yixuan Tang and Yi Yang. MultiHop-RAG: Bench- marking retrieval-augmented generation for multi- hop queries.arXiv preprint arXiv:2401.15391, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[45]
BEIR: A heterogeneous benchmark for zero-shot evalua- tion of information retrieval models
Nandan Thakur, Nils Reimers, Andreas Rücklé, Abhishek Srivastava, and Iryna Gurevych. BEIR: A heterogeneous benchmark for zero-shot evalua- tion of information retrieval models. InNeurIPS Datasets and Benchmarks Track, 2021
2021
-
[46]
KILT: a benchmark for knowl- edge intensive language tasks
Fabio Petroni, Aleksandra Piktus, Angela Fan, Patrick Lewis, Majid Yazdani, Nicola De Cao, James Thorne, Yacine Jernite, Vladimir Karpukhin, Jean Maillard, et al. KILT: a benchmark for knowl- edge intensive language tasks. InProceedings of the North American Chapter of the ACL (NAACL), 2021
2021
-
[47]
CodeSearchNet Challenge: Evaluating the State of Semantic Code Search
Hamel Husain, Ho-Hsiang Wu, Tiferet Gazit, Mil- tiadis Allamanis, and Marc Brockschmidt. Code- SearchNet challenge: Evaluating the state of seman- tic code search.arXiv preprint arXiv:1909.09436, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1909
-
[48]
Cumulated gain-based evaluation of IR techniques.ACM Trans- actions on Information Systems (TOIS), 20(4):422– 446, 2002
Kalervo Järvelin and Jaana Kekäläinen. Cumulated gain-based evaluation of IR techniques.ACM Trans- actions on Information Systems (TOIS), 20(4):422– 446, 2002
2002
-
[49]
Datasheets for datasets.Communications of the ACM, 64(12):86– 92, 2021
Timnit Gebru, Jamie Morgenstern, Briana Vec- chione, Jennifer Wortman Vaughan, Hanna Wallach, Hal Daumé III, and Kate Crawford. Datasheets for datasets.Communications of the ACM, 64(12):86– 92, 2021
2021
-
[50]
UMAP: Uniform Manifold Approximation and Projection for Dimension Reduction
Leland McInnes, John Healy, and James Melville. UMAP: Uniform manifold approximation and pro- jection for dimension reduction.arXiv preprint arXiv:1802.03426, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[51]
Estimating the dimension of a model.The Annals of Statistics, 6(2):461–464, 1978
Gideon Schwarz. Estimating the dimension of a model.The Annals of Statistics, 6(2):461–464, 1978
1978
-
[52]
Hamilton, Rex Ying, and Jure Leskovec
William L. Hamilton, Rex Ying, and Jure Leskovec. Inductiverepresentationlearningonlargegraphs. In Advances in Neural Information Processing Systems (NeurIPS), 2017. 11
2017
-
[53]
Hamil- ton, Pietro Liò, Yoshua Bengio, and R Devon Hjelm
Petar Veličković, William Fedus, William L. Hamil- ton, Pietro Liò, Yoshua Bengio, and R Devon Hjelm. Deep graph infomax. InInternational Conference on Learning Representations (ICLR), 2019
2019
-
[54]
Haveliwala
Taher H. Haveliwala. Topic-sensitive PageRank. In Proceedings of the International World Wide Web Conference (WWW), 2002
2002
-
[55]
jina-reranker- v3: Last but not late interaction for listwise docu- ment reranking, 2025
Feng Wang, Yuqing Li, and Han Xiao. jina-reranker- v3: Last but not late interaction for listwise docu- ment reranking, 2025
2025
-
[56]
Xing, Hao Zhang, Joseph E
Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric P. Xing, Hao Zhang, Joseph E. Gonzalez, and Ion Stoica. Judg- ing LLM-as-a-judge with MT-Bench and Chatbot Arena. InAdvances in Neural Information Process- ing Systems (NeurIPS), Datasets and Benchmarks Track, 2023
2023
-
[57]
FActScore: Fine-grained atomic evaluation of fac- tual precision in long form text generation
Sewon Min, Kalpesh Krishna, Xinxi Lyu, Mike Lewis, Wen-tau Yih, Pang Wei Koh, Mohit Iyyer, Luke Zettlemoyer, and Hannaneh Hajishirzi. FActScore: Fine-grained atomic evaluation of fac- tual precision in long form text generation. InPro- ceedings of Empirical Methods in Natural Language Processing (EMNLP), 2023
2023
-
[58]
RAGAs: Automated evaluation of retrieval augmented generation
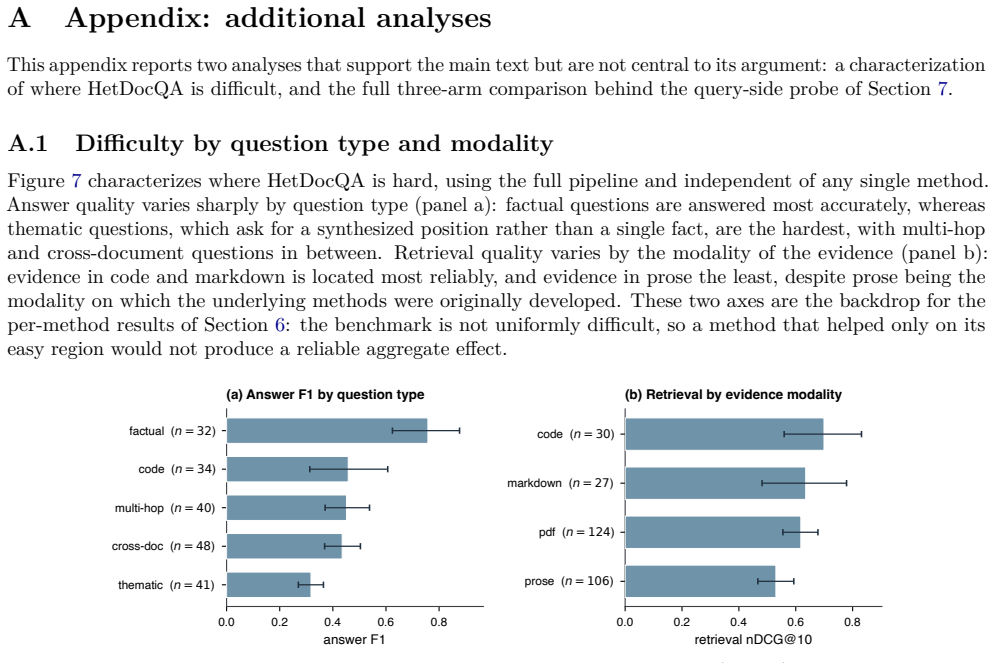
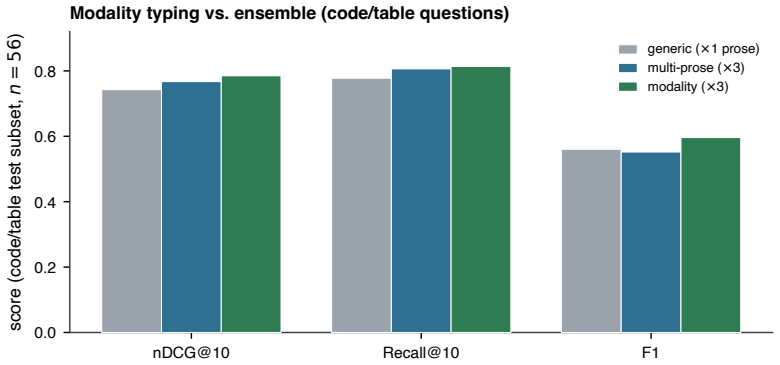
Shahul Es, Jithin James, Luis Espinosa-Anke, and Steven Schockaert. RAGAs: Automated evaluation of retrieval augmented generation. InProceedings of the European Chapter of the ACL (EACL): System Demonstrations, 2024. 12 A Appendix: additional analyses Thisappendixreportstwoanalysesthatsupportthemaintextbutarenotcentraltoitsargument: acharacterization of w...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.