Learning Controlled Separation of Small Objects Between Two Fingers with a Tactile Skin
Pith reviewed 2026-06-28 22:15 UTC · model grok-4.3
The pith
A robotic hand separates small objects to a precise count between two fingers using only tactile skin feedback without vision.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
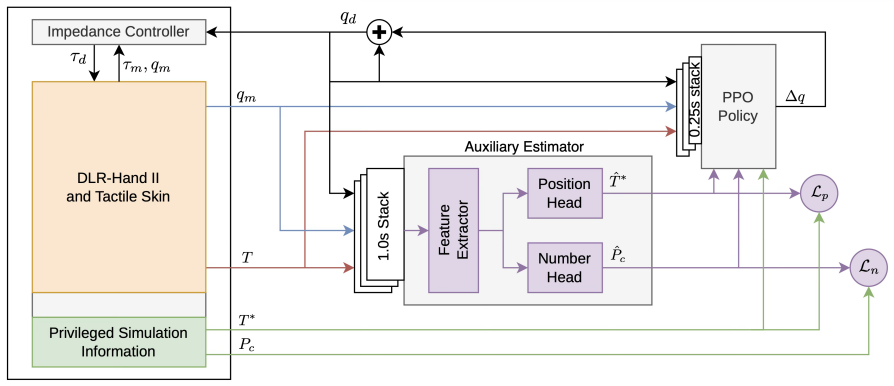
The central claim is that a reinforcement learning policy trained in simulation using only spatially-resolved tactile feedback from a fingertip sensor enables controlled dropping of small objects until exactly the desired number remains between the fingers, and that this policy transfers directly to the real DLR-Hand II without additional fine-tuning.
What carries the argument
Spatially-resolved tactile skin on the fingertip that supplies contact-position data to a reinforcement-learning policy trained with a sparse count-based reward.
If this is right
- An ideal high-resolution tactile sensor solves the separation task almost perfectly.
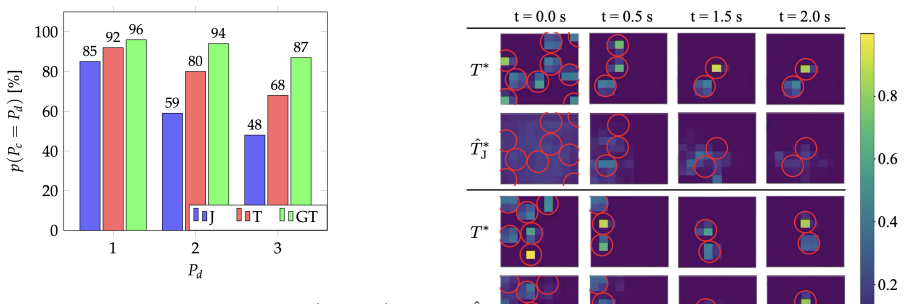
- A 4x4 taxel sensor improves success by up to 20 percent over joint sensors alone.
- Training an estimator alongside the policy allows prediction of ground-truth contact positions from tactile readings.
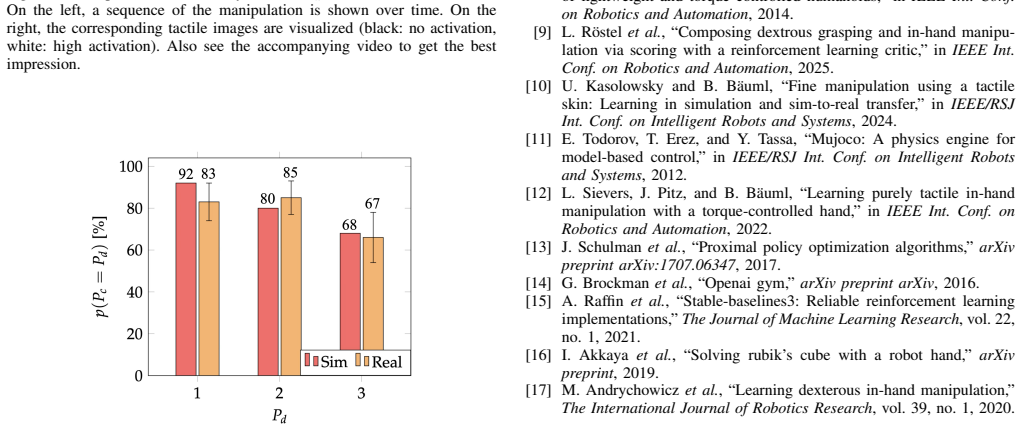
- The policy achieves successful sim-to-real transfer on the DLR-Hand II without real-world fine-tuning.
Where Pith is reading between the lines
- Tactile-only control of this kind could extend to other fine-manipulation tasks such as sorting or assembly of small parts where vision is occluded.
- Varying pellet size or friction in simulation could reveal the minimum sensor resolution needed for reliable performance.
- Combining the tactile policy with simple force thresholds might increase robustness when objects have varying weights.
Load-bearing premise
The physics simulation matches real-world contact dynamics, friction, and tactile sensor responses closely enough for direct transfer of the learned policy to hardware.
What would settle it
Running the transferred policy on the real DLR-Hand II and measuring whether it consistently leaves exactly the target number of pellets between the fingers across repeated trials.
Figures




read the original abstract
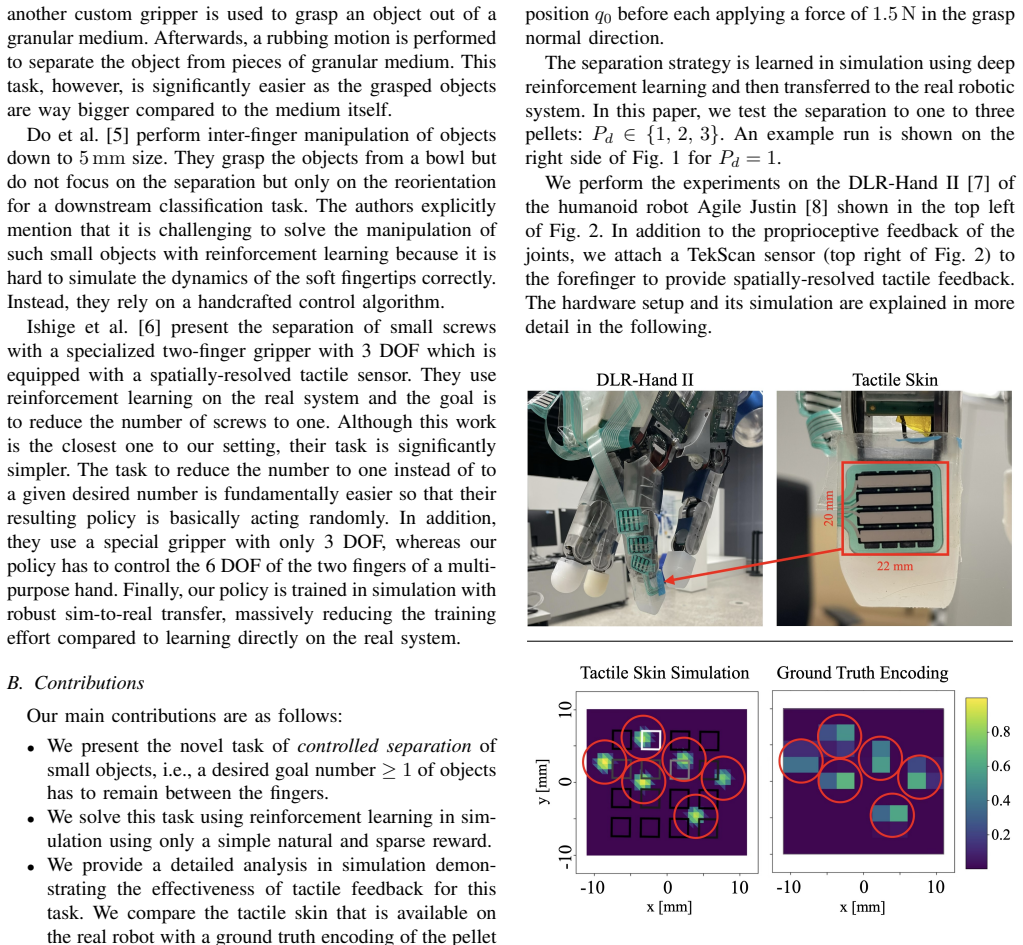
We introduce and solve the novel task of controlled separation of small objects with two fingers of a multi-purpose robotic hand: after grasping into a box of small objects, the task is to drop as many of them until a desired number remains between the fingers. The objects are small compared to the width of the fingers but also in absolute terms. In our case little pellets with a diameter of only 6mm are handled. We show that the task can be performed purely tactile (no vision) using a spatially-resolved tactile skin on a fingertip. The separation policy is trained in simulation via reinforcement learning using a straightforward sparse reward, which basically checks if the desired number of objects is reached. In simulation experiments, we provide an exhaustive analysis of the benefits of using spatially-resolved tactile feedback: while an ideal (high-resolution) tactile sensor allows solving the task almost perfectly, a sensor with lower spatial resolution (here 4x4 taxels) still leads to an improvement of up to 20% compared to using only the fingers' joint sensors. For this analysis, we further train an estimator alongside the policy that predicts the ground truth contact positions. Finally, we demonstrate the successful sim-to-real transfer for the DLR-Hand II equipped with a tactile skin.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the task of controlled separation of 6mm pellets grasped between two fingers of a multi-fingered hand, where the goal is to release objects until a target number remains. The approach uses reinforcement learning in simulation with a sparse reward based solely on the final object count, relying on spatially-resolved tactile skin (ideal or 4x4 taxels) without vision. It analyzes performance gains from tactile feedback (up to 20% over joint sensors), trains a contact-position estimator alongside the policy, and reports successful zero-shot sim-to-real transfer on the DLR-Hand II hardware.
Significance. If the sim-to-real modeling assumptions hold, the work would demonstrate a practical advance in tactile-only dexterous manipulation for small objects where vision is unreliable due to occlusion or scale. The systematic comparison of tactile resolutions and the accompanying estimator provide useful insights into sensor requirements. Credit is due for the hardware validation on the DLR-Hand II and the use of a simple sparse reward that still enables learning.
major comments (1)
- [Abstract and real-robot experiments section] The central claim of successful zero-shot sim-to-real transfer (Abstract and real-robot experiments section) rests on the unvalidated assumption that the simulator's contact dynamics, friction, and 4x4 tactile responses match hardware for 6mm pellets. No quantitative sim-vs-real comparison of raw taxel values, no domain randomization details for sensor noise or pellet properties, and no ablation showing transfer failure under mismatched parameters are provided; this directly undermines assessment of whether the policy exploits simulation-specific cues.
minor comments (2)
- The abstract states quantitative gains (up to 20% with 4x4 tactile) but omits error bars, trial counts, and failure-mode analysis; these details are needed to interpret the simulation results.
- Notation for the tactile sensor resolutions and the estimator architecture could be clarified with an explicit diagram or table relating taxel count to input dimensionality.
Simulated Author's Rebuttal
We thank the referee for the constructive review and for highlighting the need for stronger validation of the sim-to-real transfer. We address the single major comment point-by-point below.
read point-by-point responses
-
Referee: [Abstract and real-robot experiments section] The central claim of successful zero-shot sim-to-real transfer (Abstract and real-robot experiments section) rests on the unvalidated assumption that the simulator's contact dynamics, friction, and 4x4 tactile responses match hardware for 6mm pellets. No quantitative sim-vs-real comparison of raw taxel values, no domain randomization details for sensor noise or pellet properties, and no ablation showing transfer failure under mismatched parameters are provided; this directly undermines assessment of whether the policy exploits simulation-specific cues.
Authors: We agree that the current manuscript lacks quantitative sim-vs-real comparisons of raw taxel values, explicit domain randomization details, and ablations on mismatched parameters. The zero-shot hardware success on the DLR-Hand II is offered as empirical evidence that the simulation model was adequate for the task, but we acknowledge this does not fully address the referee's concern about potential simulation-specific cues. In revision we will add a dedicated subsection to the real-robot experiments section that includes (1) side-by-side quantitative plots of 4x4 taxel activation patterns for matched contact scenarios in simulation and on hardware, (2) a description of how contact dynamics and friction parameters were calibrated from hardware measurements, and (3) clarification that no domain randomization was applied because the simulator was tuned to the specific hardware and pellet properties. An ablation on deliberately mismatched parameters was not performed within the scope of this work; we will note this limitation explicitly. These additions will allow readers to better evaluate the transfer. revision: yes
Circularity Check
No circularity in RL training or sim-to-real claims
full rationale
The paper's core chain consists of RL policy training in simulation (sparse reward on object count) plus an auxiliary contact estimator, followed by zero-shot transfer to DLR-Hand II hardware. No equations define a quantity in terms of itself, no fitted parameters are relabeled as predictions, and no self-citations or imported uniqueness theorems carry the central result. The reported outcomes (simulation success rates and hardware transfer) are generated by independent training runs and physical experiments rather than by algebraic or definitional reduction to the inputs.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Learning to pick by digging: Data-driven dig-grasping for bin picking from clutter,
C. Zhao, Z. Tong, J. Rojas, and J. Seo, “Learning to pick by digging: Data-driven dig-grasping for bin picking from clutter,” inIEEE Int. Conf. on Robotics and Automation, 2022
2022
-
[2]
Vision-sensorless bin-picking system using compliant fingers with proximity sensors,
M. Ohara, K. Koyama, and K. Harada, “Vision-sensorless bin-picking system using compliant fingers with proximity sensors,” inIEEE/SICE Int. Symposium on System Integration, 2025
2025
-
[3]
In-hand singulation and scooping manipulation with a 5 dof tactile gripper,
Y . Zhou, P. Zhou, S. Wang, and Y . She, “In-hand singulation and scooping manipulation with a 5 dof tactile gripper,” inIEEE/RSJ Int. Conf. on Intelligent Robots and Systems, 2024
2024
-
[4]
In-hand singulation, scooping, and cable untangling with a 5- dof tactile-reactive gripper,
——, “In-hand singulation, scooping, and cable untangling with a 5- dof tactile-reactive gripper,”Advanced Robotics Research, 2025
2025
-
[5]
Inter-finger small object manipulation with densetact optical tactile sensor,
W. K. Do, B. Aumann, C. Chungyoun, and M. Kennedy, “Inter-finger small object manipulation with densetact optical tactile sensor,”IEEE Robotics and Automation Letters, vol. 9, no. 1, 2024
2024
-
[6]
Blind bin picking of small screws through in-finger manipulation with compliant robotic fingers,
M. Ishigeet al., “Blind bin picking of small screws through in-finger manipulation with compliant robotic fingers,” inIEEE/RSJ Int. Conf. on Intelligent Robots and Systems, 2020
2020
-
[7]
Dlr-hand ii: Next generation of a dextrous robot hand,
J. Butterfaß, M. Grebenstein, H. Liu, and G. Hirzinger, “Dlr-hand ii: Next generation of a dextrous robot hand,” inIEEE Int. Conf. on Robotics and Automation, 2001
2001
-
[8]
Agile justin: An upgraded member of dlr’s family of lightweight and torque controlled humanoids,
B. B ¨aumlet al., “Agile justin: An upgraded member of dlr’s family of lightweight and torque controlled humanoids,” inIEEE Int. Conf. on Robotics and Automation, 2014
2014
-
[9]
Composing dextrous grasping and in-hand manipu- lation via scoring with a reinforcement learning critic,
L. R ¨ostelet al., “Composing dextrous grasping and in-hand manipu- lation via scoring with a reinforcement learning critic,” inIEEE Int. Conf. on Robotics and Automation, 2025
2025
-
[10]
Fine manipulation using a tactile skin: Learning in simulation and sim-to-real transfer,
U. Kasolowsky and B. B ¨auml, “Fine manipulation using a tactile skin: Learning in simulation and sim-to-real transfer,” inIEEE/RSJ Int. Conf. on Intelligent Robots and Systems, 2024
2024
-
[11]
Mujoco: A physics engine for model-based control,
E. Todorov, T. Erez, and Y . Tassa, “Mujoco: A physics engine for model-based control,” inIEEE/RSJ Int. Conf. on Intelligent Robots and Systems, 2012
2012
-
[12]
Learning purely tactile in-hand manipulation with a torque-controlled hand,
L. Sievers, J. Pitz, and B. B ¨auml, “Learning purely tactile in-hand manipulation with a torque-controlled hand,” inIEEE Int. Conf. on Robotics and Automation, 2022
2022
-
[13]
Proximal Policy Optimization Algorithms
J. Schulmanet al., “Proximal policy optimization algorithms,”arXiv preprint arXiv:1707.06347, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[14]
Openai gym,
G. Brockmanet al., “Openai gym,”arXiv preprint arXiv, 2016
2016
-
[15]
Stable-baselines3: Reliable reinforcement learning implementations,
A. Raffinet al., “Stable-baselines3: Reliable reinforcement learning implementations,”The Journal of Machine Learning Research, vol. 22, no. 1, 2021
2021
-
[16]
Solving rubik’s cube with a robot hand,
I. Akkayaet al., “Solving rubik’s cube with a robot hand,”arXiv preprint, 2019
2019
-
[17]
Learning dexterous in-hand manipulation,
M. Andrychowiczet al., “Learning dexterous in-hand manipulation,” The International Journal of Robotics Research, vol. 39, no. 1, 2020
2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.