EngiAI: A Multi-Agent Framework and Benchmark Suite for LLM-Driven Engineering Design
Pith reviewed 2026-05-20 05:18 UTC · model grok-4.3
The pith
A multi-agent system called EngiAI uses a supervisor to coordinate seven specialized agents for engineering tasks from topology optimization to 3D printer control.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
EngiAI operationalizes engineering design by routing tasks through a supervisor that assigns work to seven agents handling topology optimization, document retrieval, HPC orchestration, and printer control; the accompanying benchmark isolates contributions from retrieval and reveals that conditional logic and long-running multi-step workflows remain the hardest for current models.
What carries the argument
Supervisor architecture in LangGraph that coordinates seven specialized agents to manage the full pipeline from optimization through retrieval and manufacturing execution.
Load-bearing premise
The seven prompt styles and two EngiBench problems capture the key cognitive and technical demands of actual engineering design work that includes simulation and manufacturing preparation.
What would settle it
An engineering project that requires conditional decisions across more than five sequential steps where the reported task-completion rates no longer predict successful completion of the full design-to-fabrication cycle.
Figures










read the original abstract
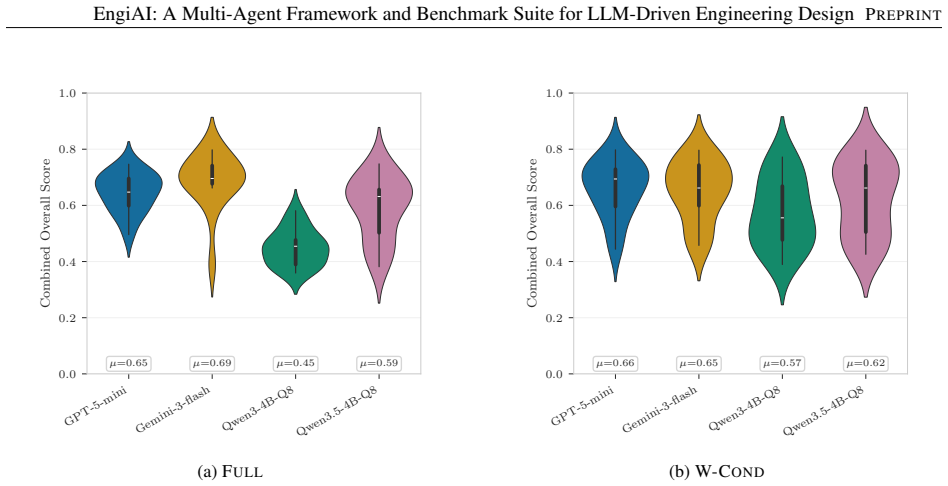
Large Language Model (LLM) agents are increasingly applied to engineering design tasks, yet existing evaluation frameworks do not adequately address multi-agent systems that combine simulation, retrieval, and manufacturing preparation. We introduce a benchmark suite with three evaluation dimensions: (1) a workflow benchmark with seven prompt styles targeting distinct cognitive demands-including direct tool use, semantic disambiguation, conditional branching, and working-memory tasks; (2) a Retrieval-Augmented Generation (RAG) benchmark with gated scoring isolating retrieval contributions to parameter selection; and (3) an High Performance Computing (HPC) benchmark evaluating end-to-end ML training orchestration on a SLURM cluster. Alongside the benchmark we present EngiAI, a Multi-Agent System (MAS) reference implementation built on LangGraph that operationalizes the benchmark by coordinating seven specialized agents through a supervisor architecture, unifying topology optimization, document retrieval, HPC job orchestration, and 3D printer control. Across four LLM backends and two EngiBench problems, proprietary models achieve 96-97% average task completion on Beams2D, while open-source 4B-parameter models reach 55-78%, with clear generational improvement. Conditional branching proves most challenging, with task completion dropping to 20-53% for the conditional style on Photonics2D. RAG gating confirms near-perfect retrieval-augmented scores ($\approx 1.0$) versus near-zero without retrieval, validating the evaluation design. On HPC orchestration, one model completes all pipeline steps in 100% of runs while another drops to 50%, revealing that multi-step instruction following degrades over long-running workflows.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces EngiAI, a multi-agent system built on LangGraph that coordinates seven specialized agents via a supervisor architecture to handle topology optimization, document retrieval, HPC job orchestration, and 3D printer control. It also presents EngiBench, a benchmark suite with three dimensions: (1) a workflow benchmark using seven prompt styles that target distinct cognitive demands (direct tool use, semantic disambiguation, conditional branching, working-memory tasks); (2) a RAG benchmark with gated scoring to isolate retrieval contributions; and (3) an HPC benchmark for end-to-end ML training orchestration on SLURM. Across four LLM backends and two problems (Beams2D, Photonics2D), the paper reports proprietary models achieving 96-97% average task completion on Beams2D versus 55-78% for open-source 4B models, with conditional branching dropping to 20-53% on Photonics2D and variable success on long-running HPC pipelines.
Significance. If the seven prompt styles and two EngiBench problems prove representative of real engineering design loops involving simulation, retrieval, and manufacturing, the results would usefully quantify current LLM limitations in multi-step, conditional, and long-horizon workflows. The RAG gating results (near-1.0 with retrieval vs near-zero without) and the generational improvement signal between open-source models provide concrete, falsifiable measurements that could guide future agent architectures. The work ships a reference implementation and newly defined tasks, which strengthens its utility as a benchmark contribution.
major comments (3)
- [Benchmark Design] Benchmark Design section: The seven prompt styles are asserted to target distinct cognitive demands of engineering design, yet the manuscript provides no external mapping, expert validation, or comparison against established engineering task taxonomies (e.g., those used in topology optimization or manufacturing workflows). This is load-bearing for the central performance claims, because the reported gaps (proprietary 96-97% vs open-source 55-78% on Beams2D; conditional branching at 20-53% on Photonics2D) only generalize if the stylized tasks instantiate the full requirements of multi-step design loops.
- [Experimental Results] Experimental Results (abstract and §4): Specific performance numbers (96-97%, 55-78%, 20-53%, 100% vs 50% on HPC) are presented without details on number of runs, error bars, dataset sizes, exclusion criteria, or statistical tests. This gap directly affects verification of the headline claims and the assertion that multi-step instruction following degrades over long-running workflows.
- [HPC Benchmark] HPC Benchmark subsection: The claim that one model completes all pipeline steps in 100% of runs while another drops to 50% requires explicit definition of what constitutes a 'pipeline step' and how success is scored across variable-length SLURM jobs; without this, the degradation observation cannot be reproduced or compared to other orchestration frameworks.
minor comments (2)
- [EngiAI Framework] The description of the supervisor architecture would benefit from a diagram or pseudocode showing the exact hand-off protocol between the seven agents.
- [Results] Table or figure captions for the prompt-style results should explicitly state the number of trials per cell to allow readers to assess variance.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed review. The comments identify areas where additional clarity and rigor will strengthen the manuscript. We address each major comment below and indicate the revisions we will make.
read point-by-point responses
-
Referee: [Benchmark Design] Benchmark Design section: The seven prompt styles are asserted to target distinct cognitive demands of engineering design, yet the manuscript provides no external mapping, expert validation, or comparison against established engineering task taxonomies (e.g., those used in topology optimization or manufacturing workflows). This is load-bearing for the central performance claims, because the reported gaps (proprietary 96-97% vs open-source 55-78% on Beams2D; conditional branching at 20-53% on Photonics2D) only generalize if the stylized tasks instantiate the full requirements of multi-step design loops.
Authors: We appreciate the referee's observation that the prompt styles require stronger grounding. The seven styles were constructed by enumerating recurring failure modes observed during pilot engineering design sessions (direct instruction following, ambiguity resolution, conditional logic, memory retention, etc.). While the manuscript lists these demands, we agree that an explicit mapping to established taxonomies would improve generalizability. In the revised version we will add a dedicated paragraph in the Benchmark Design section that (1) references standard engineering task decompositions from topology optimization literature and manufacturing workflow studies, (2) provides a table mapping each prompt style to the corresponding cognitive or procedural requirement, and (3) notes that the styles were iteratively refined against real Beams2D and Photonics2D design traces. This addition will not require new experiments but will make the design rationale transparent. revision: yes
-
Referee: [Experimental Results] Experimental Results (abstract and §4): Specific performance numbers (96-97%, 55-78%, 20-53%, 100% vs 50% on HPC) are presented without details on number of runs, error bars, dataset sizes, exclusion criteria, or statistical tests. This gap directly affects verification of the headline claims and the assertion that multi-step instruction following degrades over long-running workflows.
Authors: The referee correctly identifies that the current manuscript omits key experimental metadata. All reported percentages were obtained from repeated trials (minimum of five independent runs per model-prompt-problem combination) using fixed random seeds for reproducibility. In the revised manuscript we will expand §4 to include: (i) the exact number of runs and total trials per configuration, (ii) standard deviation or inter-quartile range for each aggregate score, (iii) the size of the prompt and retrieval corpora, (iv) explicit exclusion criteria (e.g., runs terminated by infrastructure timeouts), and (v) results of paired statistical tests (Wilcoxon signed-rank) comparing proprietary versus open-source models. These additions will allow readers to assess the reliability of the observed gaps. revision: yes
-
Referee: [HPC Benchmark] HPC Benchmark subsection: The claim that one model completes all pipeline steps in 100% of runs while another drops to 50% requires explicit definition of what constitutes a 'pipeline step' and how success is scored across variable-length SLURM jobs; without this, the degradation observation cannot be reproduced or compared to other orchestration frameworks.
Authors: We agree that the HPC evaluation section is currently underspecified. A pipeline step is defined as any of the following discrete actions: (1) job script generation, (2) SLURM submission via sbatch, (3) status polling until completion or failure, (4) log parsing and result extraction, and (5) error recovery or graceful termination. Success for a full run requires correct execution of every step without external intervention. In the revision we will insert a new paragraph and accompanying figure that (a) enumerates the steps with pseudocode, (b) describes how variable-length jobs are handled (timeout thresholds and retry logic), and (c) provides the exact success criterion used to obtain the 100% versus 50% figures. This clarification will make the benchmark reproducible. revision: yes
Circularity Check
No circularity: empirical results on newly defined benchmarks
full rationale
The paper introduces a new benchmark suite (seven prompt styles targeting cognitive demands plus two EngiBench problems) and a LangGraph-based multi-agent reference implementation. All headline performance figures—96-97% task completion for proprietary models on Beams2D, 55-78% for open-source models, 20-53% on conditional branching for Photonics2D, and RAG/HPC orchestration outcomes—are presented as direct empirical measurements obtained by executing the LLMs on these freshly defined tasks. No equations, fitted parameters, or first-principles derivations appear; the RAG gating result (≈1.0 with retrieval vs. near-zero without) is an internal consistency check on the evaluation protocol rather than a reduction of the main claims. The work is therefore self-contained against external benchmarks and contains no load-bearing self-citation chains or self-definitional steps.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We introduce a benchmark suite with three evaluation dimensions: (1) a workflow benchmark with seven prompt styles targeting distinct cognitive demands—including direct tool use, semantic disambiguation, conditional branching, and working-memory tasks; (2) a Retrieval-Augmented Generation (RAG) benchmark with gated scoring isolating retrieval contributions to parameter selection; and (3) an High Performance Computing (HPC) benchmark evaluating end-to-end ML training orchestration on a SLURM cluster.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Perspectives on iteration in design and development
Wynn, David C and Eckert, Claudia M. “Perspectives on iteration in design and development.”Research in Engineering DesignV ol. 28 No. 2 (2017): pp. 153–184
work page 2017
-
[2]
Deep generative models in engineering design: A review
Regenwetter, Lyle, Nobari, Amin Heyrani and Ahmed, Faez. “Deep generative models in engineering design: A review.”Journal of Mechanical DesignV ol. 144 No. 7 (2022): p. 071704
work page 2022
-
[3]
ChatGPT [Large language model]
OpenAI. “ChatGPT [Large language model].”https://chat.openai.com(2026)
work page 2026
-
[4]
LangGraph: Build Resilient Language Agents as Graphs
LangChain, Inc. “LangGraph: Build Resilient Language Agents as Graphs.” (2024). URL https://github. com/langchain-ai/langgraph. Open-source Python library
work page 2024
-
[5]
Engineering design: a systematic approach
Beitz, W, Pahl, G and Grote, K. “Engineering design: a systematic approach.”Mrs BulletinV ol. 71 No. 30 (1996): p. 3
work page 1996
-
[6]
EngiBench: A Framework for Data-Driven Engineering Design Research
Felten, Florian, Apaza, Gabriel, Bräunlich, Gerhard et al. “EngiBench: A Framework for Data-Driven Engineering Design Research.”The Thirty-ninth Annual Conference on Neural Information Processing Systems Datasets and Benchmarks Track. 2025. URLhttps://openreview.net/forum?id=YowD33Q89V
work page 2025
-
[7]
Intelligent Design 4.0: Paradigm Evolution Toward the Agentic Artificial Intelligence Era
Jiang, Shuo, Xie, Min, Chen, Frank Youhua et al. “Intelligent Design 4.0: Paradigm Evolution Toward the Agentic Artificial Intelligence Era.”Journal of Computing and Information Science in Engineering V ol. 25 No. 12 (2025): p. 120808. doi:10.1115/1.4070438. URL https://asmedigitalcollection. asme.org/computingengineering/article-pdf/25/12/120808/7569711/...
-
[8]
Agentic AI: Autonomous Intelligence for Complex Goals—A Comprehensive Survey,
Acharya, Deepak Bhaskar, Kuppan, Karthigeyan and Divya, B. “Agentic AI: Autonomous Intelli- gence for Complex Goals—A Comprehensive Survey.”IEEE AccessV ol. 13 (2025): pp. 18912–18936. doi:10.1109/ACCESS.2025.3532853
-
[9]
Agentic AI for Scientific Discovery: A Survey of Progress, Challenges, and Future Directions
Gridach, Mourad, Nanavati, Jay, Mack, Christina et al. “Agentic AI for Scientific Discovery: A Survey of Progress, Challenges, and Future Directions.”Towards Agentic AI for Science: Hypothesis Generation, Comprehension, Quantification, and Validation. 2025. URLhttps://openreview.net/forum?id=TyCYakX9BD
work page 2025
-
[10]
AutoGen: Enabling Next-Gen LLM Applications via Multi-Agent Conversation
Wu, Qingyun, Bansal, Gagan, Zhang, Jieyu et al. “AutoGen: Enabling Next-Gen LLM Applications via Multi- Agent Conversation.”First Conference on Language Modeling (COLM). 2024. URL https://openreview. net/forum?id=BAakY1hNKS. ArXiv:2308.08155
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[11]
CrewAI: Framework for Orchestrating Role-Playing Autonomous AI Agents
CrewAI. “CrewAI: Framework for Orchestrating Role-Playing Autonomous AI Agents.” (2024). URL https: //github.com/crewAIInc/crewAI. Open-source Python library
work page 2024
-
[12]
OpenAI. “OpenAI Agents SDK.” (2025). URL https://github.com/openai/openai-agents-python. Open-source Python library
work page 2025
-
[13]
Gottweis, Juraj, Weng, Wei-Hung, Daryin, Alexander et al. “Towards an AI co-scientist.” (2025). doi:10.48550/arXiv.2502.18864. URLhttp://arxiv.org/abs/2502.18864. ArXiv:2502.18864 [cs]
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2502.18864 2025
-
[14]
Ni, Bo and Buehler, Markus J. “MechAgents: Large language model multi-agent collaborations can solve mechanics problems, generate new data, and integrate knowledge.”Extreme Mechanics LettersV ol. 67 (2024): p. 102131. doi:https://doi.org/10.1016/j.eml.2024.102131. URL https://www.sciencedirect.com/science/ article/pii/S2352431624000117
-
[15]
FeaGPT: an End-to-End agentic-AI for Finite Element Analysis
Qi, Yupeng, Xu, Ran and Chu, Xu. “FeaGPT: an End-to-End agentic-AI for Finite Element Analysis.” (2025). doi:10.48550/arXiv.2510.21993. URLhttps://arxiv.org/abs/2510.21993. 15 EngiAI: A Multi-Agent Framework and Benchmark Suite for LLM-Driven Engineering DesignPREPRINT
-
[16]
ALL-FEM: Agentic Large Language Models Fine-Tuned for Finite Element Methods
Deotale, Rushikesh, Srinivasan, Adithya, Tian, Yuan et al. “ALL-FEM: Agentic Large Language Models Fine-Tuned for Finite Element Methods.”SSRN Electronic Journal(2026)doi:10.2139/ssrn.6103826. URL https://ssrn.com/abstract=6103826
-
[17]
DUCTILE: Agentic LLM Orchestration of Engineering Analysis in Product Development Practice
Pradas-Gomez, Alejandro, Brahma, Arindam and Isaksson, Ola. “DUCTILE: Agentic LLM Orchestration of Engineering Analysis in Product Development Practice.” (2026). URL 2603.10249, URL https://arxiv. org/abs/2603.10249
-
[18]
AI Agents in Engineering Design: A Multi-Agent Framework for Aesthetic and Aerodynamic Car Design
Elrefaie, Mohamed, Qian, Janet, Wu, Raina et al. “AI Agents in Engineering Design: A Multi-Agent Framework for Aesthetic and Aerodynamic Car Design.”Volume 3B: 51st Design Automation Conference (DAC). 2025. American Society of Mechanical Engineers. doi:10.1115/detc2025-169682. URL http://dx.doi.org/10. 1115/DETC2025-169682
-
[19]
An LLM-based multi-agent system to assist early-stage product design and evaluation
Chen, Pei, Cai, Yichen, Zhou, Zihong et al. “An LLM-based multi-agent system to assist early-stage product design and evaluation.”Journal of Engineering DesignV ol. 37 No. 3 (2026): pp. 945–980. doi:10.1080/09544828.2026.2616583. URL https://doi.org/10.1080/09544828.2026.2616583, URL https://doi.org/10.1080/09544828.2026.2616583
-
[20]
An LLM-enabled multi-agent autonomous mechatronics design framework
Wang, Zeyu, Lo, Frank Po Wen, Chen, Qian et al. “An LLM-enabled multi-agent autonomous mechatronics design framework.”Proceedings of the computer vision and pattern recognition conference: pp. 4205–4215. 2025
work page 2025
-
[21]
Agentic Large Language Models for Conceptual Systems Engineering and Design
Massoudi, Soheyl and Fuge, Mark. “Agentic Large Language Models for Conceptual Systems Engineering and Design.”Journal of Mechanical DesignV ol. 148 No. 5 (2026): p. 051405. doi:10.1115/1.4070328. URL https://asmedigitalcollection.asme.org/mechanicaldesign/article-pdf/148/5/051405/ 7561928/md-25-1500.pdf, URLhttps://doi.org/10.1115/1.4070328
-
[22]
Anthropic. “Model Context Protocol.” (2025). URL https://modelcontextprotocol.io/specification/ 2025-11-25
work page 2025
-
[23]
MCP-Bench: A Benchmark for Tool-Using LLM Agents with Complex Real-World Tasks via MCP Servers
Wang, Zhenting, Chang, Qi, Patel, Hemani et al. “MCP-Bench: A Benchmark for Tool-Using LLM Agents with Complex Real-World Tasks via MCP Servers.” (2025). doi:10.48550/arXiv.2504.11457. ArXiv:2504.11457
-
[24]
LLM-3D print: Large Language Mod- els to monitor and control 3D printing
Jadhav, Yayati, Pak, Peter and Barati Farimani, Amir. “LLM-3D print: Large Language Mod- els to monitor and control 3D printing.”Additive ManufacturingV ol. 114 (2025): p. 105027. doi:https://doi.org/10.1016/j.addma.2025.105027. URL https://www.sciencedirect.com/science/ article/pii/S2214860425003926
-
[25]
Retrieval-augmented generation for knowledge-intensive NLP tasks
Lewis, Patrick, Perez, Ethan, Piktus, Aleksandra et al. “Retrieval-augmented generation for knowledge-intensive NLP tasks.”Proceedings of the 34th International Conference on Neural Information Processing Systems. 2020. Curran Associates Inc., Red Hook, NY , USA
work page 2020
-
[26]
Retrieval-Augmented Generation for Large Language Models: A Survey
Gao, Yunfan, Xiong, Yun, Gao, Xinyu et al. “Retrieval-Augmented Generation for Large Language Models: A Sur- vey.” (2024). doi:10.48550/arXiv.2312.10997. URLhttp://arxiv.org/abs/2312.10997. ArXiv:2312.10997 [cs]
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2312.10997 2024
-
[27]
AMGPT: A large language model for contextual querying in additive manufacturing
Chandrasekhar, Achuth, Chan, Jonathan, Ogoke, Francis et al. “AMGPT: A large language model for contextual querying in additive manufacturing.”Additive Manufacturing LettersV ol. 11 (2024): p. 100232. doi:https://doi.org/10.1016/j.addlet.2024.100232. URL https://www.sciencedirect.com/ science/article/pii/S2772369024000409
-
[28]
Khanghah, Kiarash Naghavi, Chen, Zhiling, Romeo, Lela et al. “Zero-Shot Anomaly Detection in Laser Powder Bed Fusion Using Multimodal Retrieval-Augmented Generation and Large Language Models.”Journal of Mechani- cal DesignV ol. 148 No. 7 (2025): p. 072001. doi:10.1115/1.4070585. URLhttps://asmedigitalcollection. asme.org/mechanicaldesign/article-pdf/148/7...
-
[29]
Evaluation and Benchmarking of LLM Agents: A Survey
Mohammadi, Mahmoud, Li, Yipeng, Lo, Jane et al. “Evaluation and Benchmarking of LLM Agents: A Survey.” Proceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V .2: p. 6129–6139
-
[30]
Evaluation and Benchmarking of LLM Agents: A Survey , url=
Association for Computing Machinery, New York, NY , USA. doi:10.1145/3711896.3736570. URL https://doi.org/10.1145/3711896.3736570
-
[31]
ACEBench: A Comprehensive Evaluation of LLM Tool Usage
Chen, Chen, Hao, Xinlong, Liu, Weiwen, Huang, Xu, Zeng, Xingshan, Yu, Shuai, Li, Dexun, Huang, Yuefeng, Liu, Xiangcheng, Xinzhi, Wang and Liu, Wu. “ACEBench: A Comprehensive Evaluation of LLM Tool Usage.” Christodoulopoulos, Christos, Chakraborty, Tanmoy, Rose, Carolyn and Peng, Violet (eds.).Findings of the Association for Computational Linguistics: EMNL...
-
[32]
Lu, Jiarui, Holleis, Thomas, Zhang, Yizhe et al. “ToolSandbox: A Stateful, Conversational, Interactive Evaluation Benchmark for LLM Tool Use Capabilities.” Chiruzzo, Luis, Ritter, Alan and Wang, Lu (eds.).Findings of the Association for Computational Linguistics: NAACL 2025: pp. 1160–1183. 2025. Association for Computational Linguistics, Albuquerque, New ...
-
[33]
Patil, Shishir G, Mao, Huanzhi, Yan, Fanjia et al. “The Berkeley Function Calling Leaderboard (BFCL): From Tool Use to Agentic Evaluation of Large Language Models.”Forty-second International Conference on Machine Learning. 2025. URLhttps://openreview.net/forum?id=2GmDdhBdDk
work page 2025
-
[34]
ToolLLM: Facilitating Large Language Models to Master 16000+ Real-world APIs
Qin, Yujia, Liang, Shihao, Ye, Yining et al. “ToolLLM: Facilitating Large Language Models to Master 16000+ Real-world APIs.”The Twelfth International Conference on Learning Representations. 2024. URL https: //openreview.net/forum?id=dHng2O0Jjr
work page 2024
-
[35]
AgentBench: Evaluating LLMs as Agents
Liu, Xiao, Yu, Hao, Zhang, Hanchen et al. “AgentBench: Evaluating LLMs as Agents.”The Twelfth International Conference on Learning Representations. 2024. URLhttps://openreview.net/forum?id=zAdUB0aCTQ
work page 2024
-
[36]
NeurIPS / arXiv preprint 2401.13178
Ma, Chang, Zhang, Junlei, Zhu, Zhihao et al. “AgentBoard: An Analytical Evaluation Board of Multi- turn LLM Agents.” (2024). doi:10.48550/arXiv.2401.13178. URL http://arxiv.org/abs/2401.13178. ArXiv:2401.13178 [cs]
-
[37]
Chen, Ziru, Chen, Shijie, Ning, Yuting et al. “ScienceAgentBench: Toward Rigorous Assessment of Lan- guage Agents for Data-Driven Scientific Discovery.”The Thirteenth International Conference on Learning Representations. 2025. URLhttps://openreview.net/forum?id=6z4YKr0GK6
work page 2025
-
[38]
Eslaminia, Ahmadreza, Jackson, Adrian, Tian, Beitong et al. “FDM-bench: a domain-specific benchmark for evaluating large language models in additive manufacturing.”Manufacturing LettersV ol. 44 (2025): pp. 1415–
work page 2025
-
[39]
URL https://www.sciencedirect.com/science/ article/pii/S2213846325001968
doi:https://doi.org/10.1016/j.mfglet.2025.06.161. URL https://www.sciencedirect.com/science/ article/pii/S2213846325001968. 53rd SME North American Manufacturing Research Conference (NAMRC 53)
-
[40]
EngiBench: A Benchmark for Evaluating Large Language Models on Engineering Problem Solving
Zhou, Xiyuan, Wang, Xinlei, He, Yirui et al. “EngiBench: A Benchmark for Evaluating Large Language Models on Engineering Problem Solving.” (2025). doi:10.48550/arXiv.2509.17677. URL http://arxiv.org/abs/ 2509.17677. ArXiv:2509.17677 [cs]
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2509.17677 2025
-
[41]
τ-bench: A Benchmark for Tool-Agent-User Interaction in Real-World Domains
Yao, Shunyu, Shinn, Noah, Razavi, Pedram et al. “ τ-bench: A Benchmark for Tool-Agent-User Interaction in Real-World Domains.”The Thirteenth International Conference on Learning Representations. 2025. URL https://openreview.net/forum?id=roNSXZpUDN
work page 2025
-
[42]
WebVoyager: Building an End-to-End Web Agent with Large Multimodal Models
He, Hongliang, Yao, Wenlin, Ma, Kaixin et al. “WebV oyager: Building an End-to-End Web Agent with Large Multimodal Models.”arXiv preprint arXiv:2401.13919(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[43]
Mind2Web: Towards a Generalist Agent for the Web
Deng, Xiang, Gu, Yu, Zheng, Boyuan et al. “Mind2Web: Towards a Generalist Agent for the Web.” (2023). doi:10.48550/arXiv.2306.06070. URLhttp://arxiv.org/abs/2306.06070. ArXiv:2306.06070 [cs]
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2306.06070 2023
- [44]
-
[45]
M(M)ORE : Massive Multimodal Open RAG & Extraction
Sallinen, Alexandre, Krsteski, Stefan, Teiletche, Paul et al. “M(M)ORE : Massive Multimodal Open RAG & Extraction.”Championing Open-source DEvelopment in ML Workshop @ ICML25. 2025. URL https: //openreview.net/forum?id=6j1HjfIdKn
work page 2025
-
[46]
Sigmund, O. “A 99 line topology optimization code written in Matlab.”Struct. Multidiscip. Optim.V ol. 21 No. 2 (2001): p. 120–127. doi:10.1007/s001580050176. URLhttps://doi.org/10.1007/s001580050176
-
[47]
Andreassen, Erik, Clausen, Anders, Schevenels, Mattias et al. “Efficient topology optimization in MAT- LAB using 88 lines of code.”Structural and Multidisciplinary OptimizationV ol. 43 No. 1 (2011): pp. 1–16. doi:10.1007/s00158-010-0594-7. URLhttp://link.springer.com/10.1007/s00158-010-0594-7
-
[48]
Singh, Aaditya, Fry, Adam, Perelman, Adam et al. “OpenAI GPT-5 System Card.” (2025). URL2601.03267, URLhttps://arxiv.org/abs/2601.03267
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[49]
Yang, An, Li, Anfeng, Yang, Baosong et al. “Qwen3 Technical Report.” (2025). doi:10.48550/arXiv.2505.09388. URLhttp://arxiv.org/abs/2505.09388. ArXiv:2505.09388 [cs]
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2505.09388 2025
-
[50]
SOPTX: A High-Performance Multi-Backend Framework for Topol- ogy Optimization
He, Liang, Wei, Huayi and Tian, Tian. “SOPTX: A High-Performance Multi-Backend Framework for Topol- ogy Optimization.” (2025). doi:10.48550/arXiv.2505.02438. URL http://arxiv.org/abs/2505.02438. ArXiv:2505.02438 [math]
-
[51]
Doris, Anna C., Grandi, Daniele, Tomich, Ryan et al. “DesignQA: A Multimodal Bench- mark for Evaluating Large Language Models’ Understanding of Engineering Documentation.”Jour- nal of Computing and Information Science in EngineeringV ol. 25 No. 2 (2024): p. 021009. 17 EngiAI: A Multi-Agent Framework and Benchmark Suite for LLM-Driven Engineering DesignPRE...
- [52]
-
[53]
Anthropic. “Claude Code.” (2025). URLhttps://docs.anthropic.com/en/docs/claude-code
work page 2025
-
[54]
OpenClaw: An Open-Source Agentic Coding Framework
OpenClaw Contributors. “OpenClaw: An Open-Source Agentic Coding Framework.” (2025). URL https: //github.com/openclaw/openclaw
work page 2025
-
[55]
Saaty, R.W. “The analytic hierarchy process—what it is and how it is used.”Mathematical ModellingV ol. 9 No. 3 (1987): pp. 161–176. doi:https://doi.org/10.1016/0270-0255(87)90473-8. URL https://www.sciencedirect. com/science/article/pii/0270025587904738. A Scoring Methodology A.1 Design Quality Metrics The design quality score is a weighted combination of...
-
[58]
Post-processing & Export - Thresholding: Apply a 0.58 density threshold to convert the continuous density map into binary geometry - Mirror: Mirror the design across the y-axis for the final geometry - XY Scaling: Scale the X and Y dimensions by 2.47 - Extrusion: Extrude the 2D result by 17.9 units in the Z-axis to create a 3D volume - Export: Save the fi...
-
[61]
Post-processing & Export The STL export parameters must be derived from the optimization inputs: - Thresholding: Use the volume fraction value as the density threshold 20 EngiAI: A Multi-Agent Framework and Benchmark Suite for LLM-Driven Engineering DesignPREPRINT - Mirror: Mirror the design across the y-axis only if the volume fraction is greater than 0....
-
[64]
Post-processing & Export - Threshold the density field at 0.42 to preview the design topology - Apply a 0.58 density threshold to produce the final solid/void geometry - Scale the preview display by 1.76x in XY for quick inspection - Scale the X and Y dimensions of the part by 2.47 for manufacturing - Mirror the design across the y-axis for the final geom...
-
[67]
Post-processing & Export (conditional on compliance) - If compliance > 254.8: - Thresholding: Apply a 0.48 density threshold to convert the continuous density map into binary geometry - Mirror: Mirror the design across the y-axis for the final geometry - If compliance <= 254.8: - Thresholding: Apply a 0.64 density threshold to convert the continuous densi...
-
[68]
Optimization Configuration - Volume Fraction: 0.4 - Force Distance: 0.65 - Filter Radius (rmin): 4.0 - Objective: Minimize compliance
-
[69]
Simulation - After optimization, simulate the design to obtain the compliance value
-
[70]
Post-processing & Export Export A: - Thresholding: Apply a 0.48 density threshold to convert the continuous density map into binary geometry - Mirror: Mirror the design across the y-axis for the final geometry - XY Scaling: Scale the X and Y dimensions by 3.64 21 EngiAI: A Multi-Agent Framework and Benchmark Suite for LLM-Driven Engineering DesignPREPRINT...
work page 2025
-
[71]
Use the volume fraction and force distance from the EngiBench paper’s API walkthrough example (the non-default values shown in the code snippet)
-
[72]
(2025) for their 2D cantilever beam benchmark
Use the filter radius from the SOPTX paper by He et al. (2025) for their 2D cantilever beam benchmark. Search the relevant papers to find each value, then generate a 2D beam design using exactly those three parameters. Use default values for all other parameters and do not ask for clarification. D Supplementary Results D.1 Diffusion Model Results Figure 9...
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.