Fine-Tuning Causal LLMs for Text Classification: Embedding-Based vs. Instruction-Based Approaches
Pith reviewed 2026-05-25 07:21 UTC · model grok-4.3
The pith
Attaching a classification head to a causal LLM's final-token embedding matches instruction-tuning on single-label tasks while training 10 to 30 times fewer parameters.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
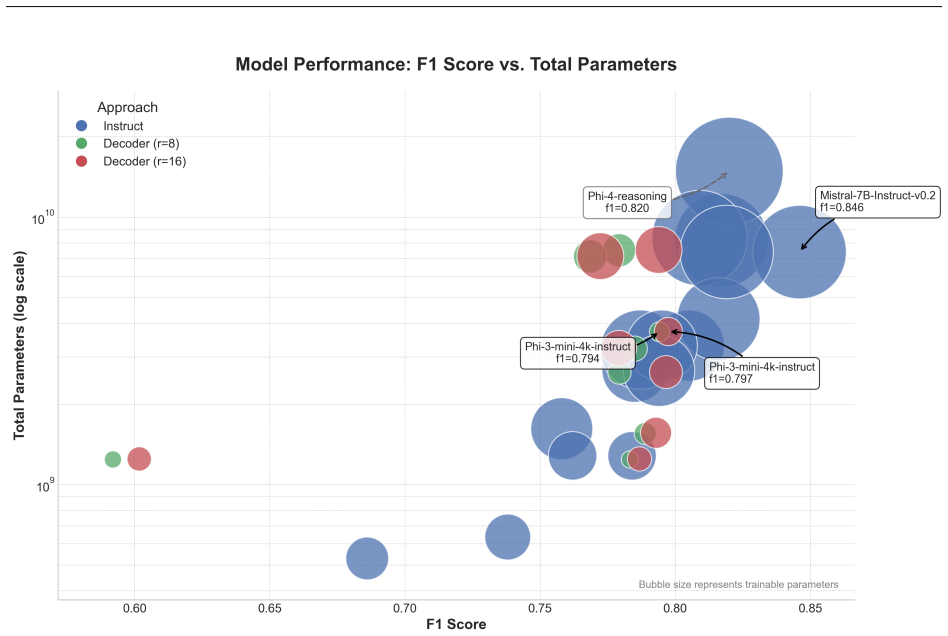
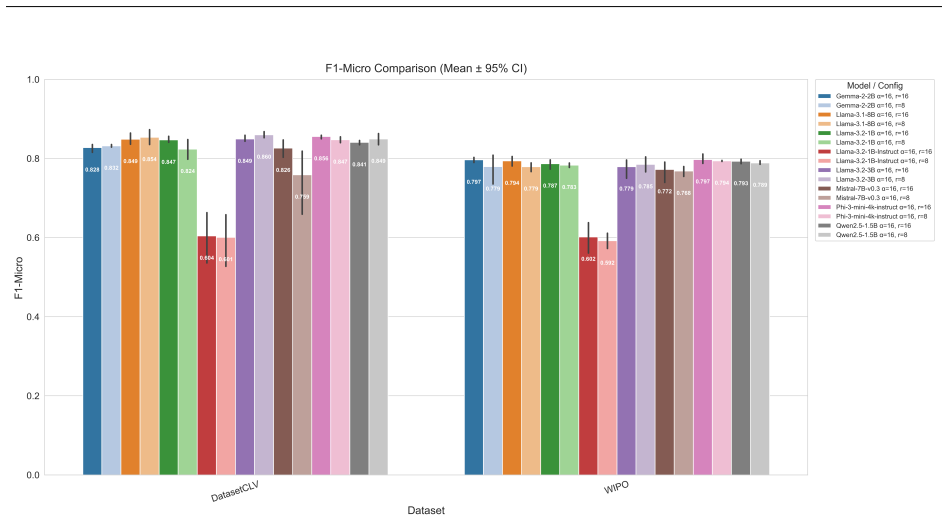
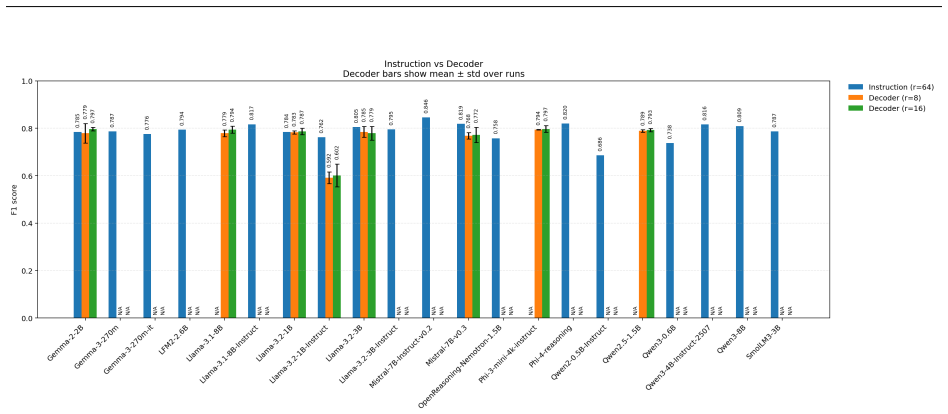
On a proprietary 5-class single-label patent corpus and the public WIPO-Alpha multi-label set, the embedding-based method matches or exceeds the instruction-tuned method on single-label classification while training 10 to 30 times fewer parameters; instruction-tuning is competitive only in the multi-label regime and only with at least 100M trainable parameters. Both methods are competitive with or surpass fine-tuned domain-specific BERT models on single-label tasks.
What carries the argument
The embedding-based approach that extracts the final-token embedding from a pre-trained causal LLM and feeds it to a classification head, trained with 4-bit quantization and LoRA.
If this is right
- On single-label tasks the embedding approach can replace instruction-tuning with large savings in trainable parameters.
- Instruction-tuning needs substantially larger trainable budgets (at least 100M parameters) to become competitive in multi-label settings.
- Both methods can match or exceed fine-tuned domain-specific BERT models on single-label patent classification.
- A distillation step can recover BERT-class inference speed from either LLM approach.
Where Pith is reading between the lines
- For many classification problems the internal states of a causal LLM may already be adequate for downstream use without retraining the model's generation behavior.
- When training compute is the bottleneck, practitioners can default to the embedding-head method for single-label problems.
- The same embedding extraction could be tested on other sequence tasks such as named-entity recognition or sentence-pair classification.
Load-bearing premise
The final-token embedding already supplies a sufficient sequence representation for classification without any extra pooling or architectural changes that would change the comparison.
What would settle it
On the same two patent benchmarks, if the embedding-head method falls below the instruction-tuned method by more than the reported 95 percent bootstrap intervals when both are trained with identical parameter budgets, the performance claim is falsified.
Figures



read the original abstract
We explore efficient strategies to fine-tune decoder-only Large Language Models (LLMs) for downstream text classification under resource constraints. Two approaches are investigated: (1) attaching a classification head to a pretrained causal LLM and fine-tuning it on the task, using the LLM's final-token embedding as a sequence representation, and (2) instruction-tuning the LLM in a prompt-to-response format for classification. To enable single-GPU fine-tuning of models up to 8B parameters, we combine 4-bit model quantization with Low-Rank Adaptation (LoRA) for parameter-efficient training. Experiments on two patent benchmarks, a 5-class single-label internal corpus and the public WIPO-Alpha multi-label dataset with 14 categories, show that the embedding-head approach matches or exceeds fine-tuned BERT baselines on single-label classification while training 10-30x fewer parameters. Instruction-tuning is competitive only in the multi-label regime, and only with substantially larger trainable budgets of at least 100M parameters. These results demonstrate that directly leveraging the internal representations of causal LLMs, together with efficient fine-tuning techniques, yields strong classification performance under limited computational resources. We discuss the advantages of each approach and outline practical guidelines and future directions for optimizing LLM fine-tuning in classification scenarios.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper compares two fine-tuning strategies for causal LLMs on text classification under resource constraints: (1) an embedding-based approach attaching a classification head to the final-token embedding of a 4-bit quantized LLM with LoRA, and (2) instruction-tuning in a prompt-to-response format. Experiments on two patent benchmarks (proprietary 5-class single-label and public WIPO-Alpha multi-label) show the embedding method matches or exceeds instruction-tuning on single-label tasks while using 10-30x fewer trainable parameters; instruction-tuning is competitive only for multi-label with larger budgets (>=100M parameters). Both approaches are competitive with or surpass domain-specific BERT models on single-label tasks. The work includes McNemar tests and bootstrap CIs (directionally consistent but p>0.05), ablations on pooling/verbalizer/calibration, generalization to AG News, and a distillation recipe.
Significance. If the empirical comparisons hold, the work provides practical value for efficient LLM deployment in classification by quantifying the parameter-efficiency tradeoff between embedding-based and instruction-based fine-tuning, with explicit statistical qualification and ablations. The transparency around non-significant differences and the single-GPU feasibility for up to 8B models strengthen its utility for resource-constrained settings.
major comments (1)
- [Abstract] Abstract and implied results: The central claim that the embedding-based method 'matches or exceeds' instruction-tuning on single-label classification rests on numerical differences whose statistical tests (McNemar and bootstrap Delta F1 CIs) show directional consistency but p>0.05; this qualification is already noted but should be reflected more explicitly in the headline claim to avoid overinterpretation of the efficiency advantage.
minor comments (2)
- Methods or appendix: Full details on LoRA rank, scaling, exact data splits, and hyperparameter search procedures should be provided to support reproducibility of the 10-30x parameter reduction and performance numbers.
- The multi-label regime comparison would benefit from explicit reporting of the trainable parameter budgets used for the instruction-tuned models to clarify the 'at least 100M parameters' threshold.
Simulated Author's Rebuttal
We thank the referee for the thorough review, the positive evaluation of the work's practical value, and the recommendation for minor revision. We address the single major comment below and will incorporate the suggested clarification.
read point-by-point responses
-
Referee: [Abstract] Abstract and implied results: The central claim that the embedding-based method 'matches or exceeds' instruction-tuning on single-label classification rests on numerical differences whose statistical tests (McNemar and bootstrap Delta F1 CIs) show directional consistency but p>0.05; this qualification is already noted but should be reflected more explicitly in the headline claim to avoid overinterpretation of the efficiency advantage.
Authors: We agree that the primary claim sentence in the abstract would benefit from a more explicit qualification of the statistical results to reduce any risk of overinterpretation, even though the abstract already contains a dedicated sentence on the McNemar tests and bootstrap CIs. In the revised version we will adjust the headline phrasing to: 'show that the embedding-based method numerically matches or exceeds the instruction-tuned method on single-label classification (directionally consistent but p>0.05) while training 10 to 30 times fewer parameters.' This makes the non-significant nature of the difference visible at the outset while preserving the reported efficiency advantage. revision: yes
Circularity Check
No significant circularity; purely empirical comparison
full rationale
The paper reports experimental results comparing embedding-based and instruction-based fine-tuning of causal LLMs on held-out patent and AG News benchmarks, with ablations on pooling/verbalizer/calibration, McNemar tests, bootstrap CIs, and parameter counts. No derivation chain, equations, fitted parameters renamed as predictions, or self-citation load-bearing premises exist; the final-token representation is a standard choice directly ablated in the work. All performance claims rest on independent measurements rather than reducing to inputs by construction.
Axiom & Free-Parameter Ledger
free parameters (1)
- LoRA rank and scaling
axioms (1)
- domain assumption The final-token hidden state of a causal LLM provides an adequate fixed-length representation of an input sequence for classification.
Forward citations
Cited by 2 Pith papers
-
Beyond Generative Decoding: Discriminative Hidden-State Readout from a Native Omni-Modal LLM for Multimodal Sentiment Analysis
Discriminative readout from the last hidden state of Qwen2.5-Omni-7B outperforms generative decoding for multimodal sentiment regression on MOSI and MOSEI while using far less compute.
-
Investigating Detection and Obfuscation of Prompt Injection Attacks Against Software Reverse Engineering AI Agents
This work examines prompt injection vulnerabilities in agentic software reverse engineering AI systems and tests detection, obfuscation, and defense techniques.
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.