LLM-as-Code: Agentic Programming for Agent Harness
Pith reviewed 2026-06-27 04:13 UTC · model grok-4.3
The pith
Giving LLMs control over loops and branches produces token explosion and hallucinations because probabilistic models cannot reliably perform deterministic sequencing.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
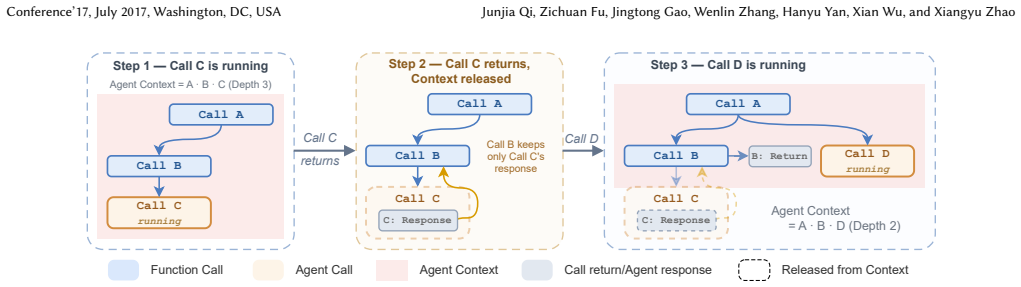
Agentic Programming places all control flow under program governance and treats the LLM as LLM-as-Code, an adaptive component invoked solely where reasoning or generation is required. The execution history is recorded as a call tree that becomes a directed acyclic graph for context construction, ensuring each call's context length depends on its depth in the tree rather than on the total number of steps taken.
What carries the argument
LLM-as-Code: the LLM treated as an adaptive component inside a program that fully owns control flow and prevents the model from altering execution paths.
If this is right
- Context length for each LLM call is bounded by call depth instead of growing with total steps.
- The LLM can still use full flexibility inside each invocation without risking changes to the overall execution path.
- Stability of long operation sequences improves because deterministic sequencing is removed from the probabilistic component.
- The call-tree DAG structure replaces linear accumulation of history.
Where Pith is reading between the lines
- The same separation could be tested in non-visual agent domains such as code editing or web navigation to check whether context management benefits generalize.
- Program-level control might allow cheaper models to be substituted for expensive ones on reasoning steps without loss of overall reliability.
- Explicit call-tree logging could enable new debugging tools that trace exactly which LLM invocations contributed to a final outcome.
Load-bearing premise
Token explosion, control-flow hallucination, and unreliable completion result from assigning deterministic looping, branching, and sequencing to a probabilistic LLM.
What would settle it
Run identical long visual operation sequences in a standard LLM-orchestrated agent versus an Agentic Programming version and compare the rates of hallucinated branches, premature stops, and token usage.
Figures

read the original abstract
Every major LLM agent framework gives the LLM the role of orchestrator; the model decides what to do next, when to call tools, and when to stop. We argue that token explosion, control-flow hallucination, and unreliable completion are not implementation bugs but architectural consequences of assigning the deterministic work of looping, branching, and sequencing to a probabilistic system. A better prompt or a stronger model cannot guarantee the reliability of the LLM agent. We therefore propose Agentic Programming, in which the program governs all control flow, and the LLM is itself part of it, an adaptive component we call LLM-as-Code and invoke only where a task calls for reasoning or generation. Within each call the model keeps full flexibility, but it cannot alter the program's execution path. With control in the program, the LLM's context is built from the execution history's call tree and forms a directed acyclic graph (DAG). Each call's context length is then determined by its call depth rather than by accumulation over steps. A case study of computer-use agents shows that the design is practical, not just a theoretical stance, substantially improving the stability of long visual operation sequences.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims that token explosion, control-flow hallucination, and unreliable completion in LLM agent frameworks are architectural issues arising from assigning deterministic control flow tasks to probabilistic LLMs. It proposes 'Agentic Programming' as an alternative where the program handles all control flow and invokes the LLM only as an 'LLM-as-Code' component for reasoning or generation tasks. In this setup, the LLM's context is constructed as a directed acyclic graph (DAG) from the execution history's call tree, with context length determined by call depth. A case study on computer-use agents is cited to show that this design improves stability of long visual operation sequences.
Significance. If the architectural separation holds and the case study generalizes, this approach could provide a more reliable foundation for building LLM agents by leveraging the strengths of deterministic programming for sequencing and probabilistic models for adaptive reasoning. The DAG-based context management directly mitigates context accumulation problems. The paper applies a standard engineering pattern to LLM agents, which is a strength in its conceptual clarity.
major comments (2)
- [Abstract] Abstract: the claim that the design is 'substantially improving the stability of long visual operation sequences' is presented without quantitative metrics, baselines, error rates, success percentages, or implementation details. This leaves the central practical claim without verifiable support.
- [Introduction / Argument] The core argument (that the listed failure modes are architectural consequences rather than implementation bugs) is logically consistent but load-bearing for the proposal; it would benefit from explicit discussion of why alternative mitigations (e.g., structured output constraints or external planners) cannot address the same issues within existing frameworks.
minor comments (1)
- [Terminology] Terminology: the newly introduced terms 'LLM-as-Code' and 'Agentic Programming' would benefit from an explicit comparison table or paragraph relating them to existing patterns such as ReAct, tool-calling agents, or program-guided LLM use.
Simulated Author's Rebuttal
We thank the referee for the constructive comments and the recommendation for major revision. We address each point below and commit to revisions that strengthen the verifiability and argumentation of the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that the design is 'substantially improving the stability of long visual operation sequences' is presented without quantitative metrics, baselines, error rates, success percentages, or implementation details. This leaves the central practical claim without verifiable support.
Authors: We agree that the abstract presents the improvement claim without accompanying quantitative evidence. The case study demonstrates practicality through qualitative observation of long-horizon stability, but to make the central claim verifiable we will revise the abstract to report specific metrics from the computer-use experiments, including success rates, error reductions, and baseline comparisons. revision: yes
-
Referee: [Introduction / Argument] The core argument (that the listed failure modes are architectural consequences rather than implementation bugs) is logically consistent but load-bearing for the proposal; it would benefit from explicit discussion of why alternative mitigations (e.g., structured output constraints or external planners) cannot address the same issues within existing frameworks.
Authors: We accept that an explicit discussion of alternatives would strengthen the load-bearing argument. We will add a subsection to the introduction that directly compares Agentic Programming against structured-output constraints and external-planner approaches, explaining why those mitigations leave token explosion, control-flow hallucination, and unreliable completion unresolved when the LLM retains the orchestrator role. revision: yes
Circularity Check
No significant circularity
full rationale
The paper is a conceptual architectural argument with no equations, fitted parameters, derivations, or quantitative predictions. The central claim—that token explosion, control-flow hallucination, and unreliable completion are architectural consequences of assigning deterministic control flow to a probabilistic model—follows directly from the proposed separation of concerns (program handles sequencing; LLM invoked only for reasoning). The DAG context construction is a straightforward consequence of fixing control flow outside the model rather than a redefinition or fit. No self-citations, uniqueness theorems, or ansatzes appear in a load-bearing role. The proposal is a standard engineering pattern and remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption LLMs are probabilistic systems unsuitable for deterministic control flow tasks such as looping, branching, and sequencing
invented entities (2)
-
LLM-as-Code
no independent evidence
-
Agentic Programming
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Islem Bouzenia and Michael Pradel. 2025. Understanding Software Engineering Agents: A Study of Thought-Action-Result Trajectories. InProceedings of the 40th IEEE/ACM International Conference on Automated Software Engineering (ASE). IEEE/ACM, New York, NY, USA, 12 pages. https://arxiv.org/abs/2506.18824
arXiv 2025
-
[2]
Harrison Chase and Nuno Campos. 2024. LangGraph: Building Stateful, Multi- Actor Applications with LLMs. https://github.com/langchain-ai/langgraph. Ac- cessed: 2026-05-30
2024
-
[3]
Tse-Hsun Chen. 2026. Towards Structured, State-Aware, and Execution-Grounded Reasoning for Software Engineering Agents. InProceedings of the 7th International Workshop on Bots and Agents in Software Engineering (BoatSE ’26). ACM, New York, NY, USA, 6 pages. doi:10.1145/3786161.3788456
-
[4]
Gonzalo Gonzalez-Pumariega, Vincent Tu, Chih-Lun Lee, Jiachen Yang, Ang Li, and Xin Eric Wang. 2025. The Unreasonable Effectiveness of Scaling Agents for Computer Use. arXiv:2510.02250 [cs.AI] https://arxiv.org/abs/2510.02250
arXiv 2025
-
[5]
Sirui Hong, Mingchen Zhuge, Jonathan Chen, Xiawu Zheng, Yuheng Cheng, Ceyao Zhang, Jinlin Wang, Zili Wang, Steven Ka Shing Yau, Zijuan Lin, Liyang Zhou, Chenyu Ran, Lingfeng Xiao, Chenglin Wu, and Jürgen Schmidhuber. 2024. MetaGPT: Meta Programming for a Multi-Agent Collaborative Framework. In International Conference on Learning Representations (ICLR). O...
Pith/arXiv arXiv 2024
-
[6]
Jie Huang, Xinyun Chen, Swaroop Mishra, Huaixiu Steven Zheng, Adams Wei Yu, Xinying Song, and Denny Zhou. 2024. Large Language Models Cannot Self- Correct Reasoning Yet. InInternational Conference on Learning Representations (ICLR). OpenReview.net, Vienna, Austria, 14 pages. https://arxiv.org/abs/2310. 01798
2024
-
[7]
Yuxin Jiang, Yufei Wang, Xingshan Zeng, Wanjun Zhong, Liangyou Li, Fei Mi, Lifeng Shang, Xin Jiang, Qun Liu, and Wei Wang. 2024. FollowBench: A Multi-level Fine-grained Constraints Following Benchmark for Large Lan- guage Models. InAnnual Meeting of the Association for Computational Linguistics (ACL). Association for Computational Linguistics, Bangkok, Th...
arXiv 2024
-
[8]
Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik Narasimhan
Carlos E. Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik Narasimhan. 2024. SWE-bench: Can Language Models Resolve Real- World GitHub Issues?. InInternational Conference on Learning Representations (ICLR). OpenReview.net, Vienna, Austria, 23 pages
2024
-
[9]
Joshi, Hanna Moazam, Heather Miller, Matei Zaharia, and Christopher Potts
Omar Khattab, Arnav Singhvi, Paridhi Maheshwari, Zhiyuan Zhang, Keshav Santhanam, Sri Vardhamanan, Saiful Haq, Ashutosh Sharma, Thomas T. Joshi, Hanna Moazam, Heather Miller, Matei Zaharia, and Christopher Potts. 2024. DSPy: Compiling Declarative Language Model Calls into Self-Improving Pipelines. InInternational Conference on Learning Representations (IC...
Pith/arXiv arXiv 2024
-
[10]
Mosh Levy, Alon Jacoby, and Yoav Goldberg. 2024. Same Task, More Tokens: the Impact of Input Length on the Reasoning Performance of Large Language Models. InAnnual Meeting of the Association for Computational Linguistics (ACL). Association for Computational Linguistics, Bangkok, Thailand, 15 pages. https: //arxiv.org/abs/2402.14848
arXiv 2024
-
[11]
Liu, Kevin Lin, John Hewitt, Ashwin Paranjape, Michele Bevilacqua, Fabio Petroni, and Percy Liang
Nelson F. Liu, Kevin Lin, John Hewitt, Ashwin Paranjape, Michele Bevilacqua, Fabio Petroni, and Percy Liang. 2024. Lost in the Middle: How Language Models Use Long Contexts.Transactions of the Association for Computational Linguistics (TACL)12 (2024), 157–173. https://aclanthology.org/2024.tacl-1.9/
2024
-
[12]
Norman Mu, Sarah Chen, Zifan Wang, Sizhe Chen, David Karamardian, Lulwa Aljeraisy, Basel Alomair, Dan Hendrycks, and David Wagner. 2023. Can LLMs Follow Simple Rules? arXiv:2311.04235 [cs.AI] https://arxiv.org/abs/2311.04235
arXiv 2023
-
[13]
Timo Schick, Jane Dwivedi-Yu, Roberto Dessì, Roberta Raileanu, Maria Lomeli, Eric Hambro, Luke Zettlemoyer, Nicola Cancedda, and Thomas Scialom. 2023. Toolformer: Language Models Can Teach Themselves to Use Tools. InAdvances in Neural Information Processing Systems (NeurIPS). Curran Associates, Inc., Red Hook, NY, USA, 14 pages
2023
-
[14]
Chi, Nathanael Schärli, and Denny Zhou
Freda Shi, Xinyun Chen, Kanishka Misra, Nathan Scales, David Dohan, Ed H. Chi, Nathanael Schärli, and Denny Zhou. 2023. Large Language Models Can Be Easily Distracted by Irrelevant Context. InInternational Conference on Machine Learning (ICML). PMLR, Honolulu, HI, USA, 14 pages. https://arxiv.org/abs/2302.00093
arXiv 2023
-
[15]
Noah Shinn, Federico Cassano, Edward Berman, Ashwin Gopinath, Karthik Narasimhan, and Shunyu Yao. 2023. Reflexion: Language Agents with Verbal Reinforcement Learning. InAdvances in Neural Information Processing Systems (NeurIPS). Curran Associates, Inc., Red Hook, NY, USA, 18 pages. https://arxiv. org/abs/2303.11366
Pith/arXiv arXiv 2023
-
[16]
Lei Wang, Chen Ma, Xueyang Feng, Zeyu Zhang, Hao Yang, Jingsen Zhang, et al
-
[17]
Frontiers of Com- puter Science18(6) (Mar 2024)
A Survey on Large Language Model based Autonomous Agents.Frontiers of Computer Science18, 6 (2024), 186345. doi:10.1007/s11704-024-40231-1
-
[18]
Xingyao Wang, Yangyi Chen, Lifan Yuan, Yizhe Zhang, Yunzhu Li, Hao Peng, and Heng Ji. 2024. Executable Code Actions Elicit Better LLM Agents. InProceedings of the 41st International Conference on Machine Learning (ICML). PMLR, Vienna, Austria, 15 pages. https://arxiv.org/abs/2402.01030
arXiv 2024
-
[19]
Xu, Xiangru Tang, Mingchen Zhuge, Jiayi Pan, Yueqi Song, Bowen Li, Jaskirat Singh, Hoang H
Xingyao Wang, Boxuan Li, Yufan Song, Frank F. Xu, Xiangru Tang, Mingchen Zhuge, Jiayi Pan, Yueqi Song, Bowen Li, Jaskirat Singh, Hoang H. Tran, Fuqiang Li, Ren Ma, Mingzhang Zheng, Bill Qian, Yanjun Shao, Niklas Muennighoff, Yizhe Zhang, Binyuan Hui, Junyang Lin, Robert Brennan, Hao Peng, Heng Ji, and Graham Neubig. 2025. OpenHands: An Open Platform for A...
Pith/arXiv arXiv 2025
-
[20]
White, Doug Burger, and Chi Wang
Qingyun Wu, Gagan Bansal, Jieyu Zhang, Yiran Wu, Beibin Li, Erkang Zhu, Li Jiang, Xiaoyun Zhang, Shaokun Zhang, Jiale Liu, Ahmed Hassan Awadallah, Ryen W. White, Doug Burger, and Chi Wang. 2024. AutoGen: Enabling Next-Gen LLM Applications via Multi-Agent Conversation. InConference on Language Modeling (COLM). OpenReview.net, Philadelphia, PA, USA, 41 pages
2024
-
[21]
Zhiheng Xi, Wenxiang Chen, Xin Guo, Wei He, Yiwen Ding, Boyang Hong, et al
-
[22]
https://arxiv.org/abs/2309.07864
The Rise and Potential of Large Language Model Based Agents: A Survey. https://arxiv.org/abs/2309.07864
-
[23]
Tianbao Xie, Danyang Zhang, Jixuan Chen, Xiaochuan Li, Siheng Zhao, Ruisheng Cao, Toh Jing Hua, Zhoujun Cheng, Dongchan Shin, Fangyu Lei, Yitao Liu, Yiheng Xu, Shuyan Zhou, Silvio Savarese, Caiming Xiong, Victor Zhong, and Tao Yu
-
[24]
InAdvances in Neural Information Processing Systems (NeurIPS)
OSWorld: Benchmarking Multimodal Agents for Open-Ended Tasks in Real Computer Environments. InAdvances in Neural Information Processing Systems (NeurIPS). Curran Associates, Inc., Red Hook, NY, USA, 64 pages
-
[25]
next step
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, and Yuan Cao. 2023. ReAct: Synergizing Reasoning and Acting in Language Models. InInternational Conference on Learning Representations (ICLR). OpenRe- view.net, Kigali, Rwanda, 33 pages. A Why Standard Patches Miss The category error is not for lack of effort, since the communit...
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.