PEEK: Context Map as an Orientation Cache for Long-Context LLM Agents
Pith reviewed 2026-05-20 05:46 UTC · model grok-4.3
The pith
LLM agents improve accuracy and cut costs on recurring long-context tasks by caching reusable orientation knowledge in a small context map.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
A context map is a small, constant-sized artifact placed in the agent's prompt that records orientation knowledge about a recurring external context; it is kept up to date by a programmable policy whose Distiller extracts transferable facts from inference-time signals, whose Cartographer converts those facts into structured map edits, and whose priority-based Evictor enforces a fixed token limit. When this map is present, agents solve long-context reasoning and information-aggregation problems more accurately, require fewer iterations, and incur lower cost than agents that rely on raw context access or prior prompt-learning methods.
What carries the argument
The context map, a fixed-budget cache of orientation knowledge updated by a three-module policy (Distiller for extraction, Cartographer for structured edits, Evictor for token control).
If this is right
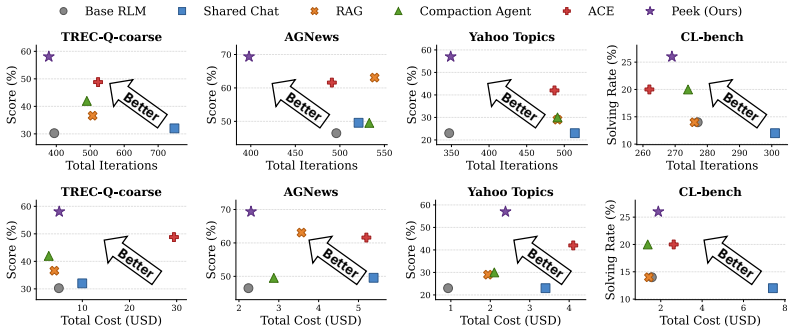
- On long-context reasoning tasks the map raises success rates 6.3-34.0 percent while cutting iterations by 93-145 and cost by 1.7-5.8 times relative to the ACE baseline.
- On context-learning tasks the map lifts solving rate by 6.0-14.0 percent and rubric accuracy by 7.8-12.1 percent at 1.4 times lower cost.
- The same map-based policy produces gains across different language models and agent architectures, including a production coding agent.
- Because the map is kept to a fixed token budget, agents can reuse the same external context across many independent sessions without growing prompt size.
Where Pith is reading between the lines
- The approach could be tested on contexts that slowly evolve, such as live code repositories with new commits, to see whether the eviction policy can still surface the most relevant orientation facts.
- Sharing a single context map across multiple agents working on the same corpus might reduce redundant exploration even further than single-agent results show.
- If the map is made inspectable by humans, it could serve as an audit trail for which parts of a large context an agent has historically found useful.
Load-bearing premise
Useful orientation knowledge about what the context contains and which parts have been helpful can be extracted and kept inside a small constant-sized artifact without dropping task-critical details over many uses.
What would settle it
Run the same long-context reasoning and context-learning benchmarks with the context map disabled while keeping every other component identical; if accuracy, iteration count, and cost show no meaningful degradation, the central claim is falsified.
Figures





read the original abstract
Large language model (LLM) agents increasingly operate over long and recurring external contexts, like document corpora and code repositories. Across invocations, existing approaches preserve either the agent's trajectory, passive access to raw material, or task-level strategies. None of them preserves what we argue is most needed for repeated same-context workloads: reusable orientation knowledge (e.g., what the context contains, how it is organized, and which entities, constants, and schemas have historically been useful) about the recurring context itself. We introduce PEEK, a system that caches and maintains this orientation knowledge as a context map: a small, constant-sized artifact in the agent's prompt that gives it a persistent peek into the external context. The map is maintained by a programmable cache policy with three modules: a Distiller that extracts transferable knowledge from inference-time signals, a Cartographer that translates it into structured edits, and a priority-based Evictor that enforces a fixed token budget. On long-context reasoning and information aggregation, PEEK improves over strong baselines by 6.3-34.0% while using 93-145 fewer iterations and incurring 1.7-5.8x lower cost than the state-of-the-art prompt-learning framework, ACE. On context learning, PEEK improves solving rate and rubric accuracy by 6.0-14.0% and 7.8-12.1%, respectively, at 1.4x lower cost than ACE. These gains generalize across LMs and agent architectures, including OpenAI Codex, a production-grade coding agent. Together, these results show that a context map helps long-context LLM agents interact with recurring external contexts more accurately and efficiently.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces PEEK, a system for LLM agents operating over long and recurring external contexts such as document corpora and code repositories. It argues that existing methods preserve trajectories, raw context, or task strategies but not reusable 'orientation knowledge' (what the context contains, how it is organized, and which entities/schemas have been useful). PEEK maintains this knowledge in a small constant-sized 'context map' artifact via a programmable cache policy consisting of a Distiller (extracts transferable knowledge from inference-time signals), a Cartographer (translates into structured edits), and a priority-based Evictor (enforces fixed token budget). On long-context reasoning and information aggregation tasks, PEEK reports 6.3-34.0% gains, 93-145 fewer iterations, and 1.7-5.8x lower cost than the ACE prompt-learning baseline; on context learning it reports 6.0-14.0% higher solving rate and 7.8-12.1% higher rubric accuracy at 1.4x lower cost. Results are claimed to generalize across LMs and agent architectures, including a production-grade coding agent.
Significance. If the empirical results hold under rigorous controls, the work provides a practical engineering contribution to efficient long-context agent design by shifting focus from full context retention or trajectory replay to a compact, updatable orientation cache. The programmable policy with explicit Distiller/Cartographer/Evictor decomposition and the inclusion of a production coding agent are positive aspects. The approach could influence memory management in agents for recurring workloads, though its value depends on whether the fixed-size map reliably preserves task-critical details without loss.
major comments (2)
- [Evictor module / cache policy] Evictor module (and associated cache policy description): The priority-based Evictor enforces a hard token budget on the context map, but the manuscript provides no explicit mechanism for deriving priorities from inference-time signals alone or for handling cases where useful orientation knowledge exceeds the budget. This directly bears on the central claim that the Distiller + Cartographer + Evictor pipeline reliably extracts, structures, and retains reusable orientation knowledge across repeated invocations without discarding task-critical details.
- [Results / experimental evaluation] Results section (performance claims vs. ACE): The reported gains (6.3-34.0% accuracy, iteration and cost reductions) are presented without details on the number of runs, statistical significance tests, variance across seeds, or precise definitions of the long-context reasoning and information aggregation tasks. This undermines evaluation of whether the improvements are robust or specific to the chosen workloads.
minor comments (2)
- [System overview] The three-module pipeline would benefit from a single overview figure or pseudocode early in the paper to clarify data flow between Distiller, Cartographer, and Evictor.
- [Related work] Ensure the related-work section explicitly contrasts PEEK with prior context-compression and agent-memory techniques to highlight the novelty of the orientation-cache framing.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed review. We address each major comment point by point below, indicating where we will revise the manuscript to improve clarity and rigor.
read point-by-point responses
-
Referee: [Evictor module / cache policy] Evictor module (and associated cache policy description): The priority-based Evictor enforces a hard token budget on the context map, but the manuscript provides no explicit mechanism for deriving priorities from inference-time signals alone or for handling cases where useful orientation knowledge exceeds the budget. This directly bears on the central claim that the Distiller + Cartographer + Evictor pipeline reliably extracts, structures, and retains reusable orientation knowledge across repeated invocations without discarding task-critical details.
Authors: We thank the referee for this observation. The Distiller extracts signals from inference-time behavior (e.g., access patterns and relevance indicators), which the Cartographer structures; the Evictor then assigns priorities to these structured entries to enforce the token budget. We acknowledge that the current text does not spell out the priority function or the overflow policy in sufficient algorithmic detail. In the revision we will expand Section 3.3 with (i) the explicit priority derivation rule that operates solely on the inference-time signals produced by the Distiller and (ii) the eviction procedure that retains the highest-priority orientation knowledge when the budget is exceeded. This will make the reliability claim easier to evaluate. revision: yes
-
Referee: [Results / experimental evaluation] Results section (performance claims vs. ACE): The reported gains (6.3-34.0% accuracy, iteration and cost reductions) are presented without details on the number of runs, statistical significance tests, variance across seeds, or precise definitions of the long-context reasoning and information aggregation tasks. This undermines evaluation of whether the improvements are robust or specific to the chosen workloads.
Authors: We agree that these experimental details are necessary for assessing robustness. The reported figures are means over five independent runs with distinct random seeds; we will add error bars, standard deviations, and the results of paired statistical significance tests in the revised results section. We will also insert a new subsection that gives precise task definitions, input formats, and example instances for the long-context reasoning and information aggregation benchmarks. These additions will directly address the concern about workload specificity. revision: yes
Circularity Check
No circularity: empirical system evaluated against external baselines
full rationale
The paper introduces PEEK as an engineering system (Distiller + Cartographer + Evictor) that maintains a fixed-size context map for orientation knowledge in recurring long-context workloads. All reported gains (accuracy, iteration count, cost) are measured empirically against external baselines such as ACE on concrete tasks; no equations, fitted parameters, derivations, or self-citation chains are present in the provided text that would reduce any claim to a tautology or input by construction. The evaluation is therefore self-contained against independent benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Orientation knowledge about recurring contexts is transferable across invocations and can be distilled into a compact structured map.
invented entities (4)
-
Context map
no independent evidence
-
Distiller module
no independent evidence
-
Cartographer module
no independent evidence
-
Evictor module
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Build a read-through semantic cache with Amazon OpenSearch Serverless and Amazon Bedrock. https://aws.amazon.com/blogs/machine-learning/build-a-read-through-sem antic-cache-with-amazon-opensearch-serverless-and-amazon-bedrock/
-
[2]
Agent Skills. Agent Skills Overview. https://agentskills.io/home , 2026. Accessed: 2026-05-04
work page 2026
-
[3]
GEPA: Reflective Prompt Evolution Can Outperform Reinforcement Learning
Lakshya A Agrawal, Shangyin Tan, Dilara Soylu, Noah Ziems, Rishi Khare, Krista Opsahl-Ong, Arnav Singhvi, Herumb Shandilya, Michael J Ryan, Meng Jiang, et al. Gepa: Reflective prompt evolution can outperform reinforcement learning.arXiv preprint arXiv:2507.19457, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
Claude code.https://docs.anthropic.com/en/docs/claude-code, 2025
Anthropic. Claude code.https://docs.anthropic.com/en/docs/claude-code, 2025
work page 2025
-
[5]
Anthropic. Agent Skills. https://platform.claude.com/docs/en/agents-and-tools /agent-skills/overview, 2026. Claude API Docs. Accessed: 2026-05-04
work page 2026
-
[6]
Fu Bang. GPTCache: An open-source semantic cache for LLM applications enabling faster answers and cost savings. In Liling Tan, Dmitrijs Milajevs, Geeticka Chauhan, Jeremy Gwin- nup, and Elijah Rippeth, editors,Proceedings of the 3rd Workshop for Natural Language Processing Open Source Software (NLP-OSS 2023), pages 212–218, Singapore, December
work page 2023
-
[7]
Association for Computational Linguistics
-
[8]
Amanda Bertsch, Adithya Pratapa, Teruko Mitamura, Graham Neubig, and Matthew R Gorm- ley. Oolong: Evaluating long context reasoning and aggregation capabilities.arXiv preprint arXiv:2511.02817, 2025
-
[9]
Qwen3-Coder-Next Technical Report
Ruisheng Cao, Mouxiang Chen, Jiawei Chen, Zeyu Cui, Yunlong Feng, Binyuan Hui, Yuheng Jing, Kaixin Li, Mingze Li, Junyang Lin, et al. Qwen3-coder-next technical report.arXiv preprint arXiv:2603.00729, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[10]
Zijian Chen, Xueguang Ma, Shengyao Zhuang, Ping Nie, Kai Zou, Andrew Liu, Joshua Green, Kshama Patel, Ruoxi Meng, Mingyi Su, et al. Browsecomp-plus: A more fair and transparent evaluation benchmark of deep-research agent.arXiv preprint arXiv:2508.06600, 2025
-
[11]
Cursor. Agent Skills. https://cursor.com/docs/skills, 2026. Cursor Docs. Accessed: 2026-05-04
work page 2026
-
[12]
Cl-bench: A benchmark for context learning
Shihan Dou, Ming Zhang, Zhangyue Yin, Chenhao Huang, Yujiong Shen, Junzhe Wang, Jiayi Chen, Yuchen Ni, Junjie Ye, Cheng Zhang, et al. Cl-bench: A benchmark for context learning. arXiv preprint arXiv:2602.03587, 2026
-
[13]
Bitdecoding: Unlocking tensor cores for long-context llms with low-bit kv cache
Dayou Du, Shijie Cao, Jianyi Cheng, Luo Mai, Ting Cao, and Mao Yang. Bitdecoding: Unlocking tensor cores for long-context llms with low-bit kv cache. In2026 IEEE International Symposium on High Performance Computer Architecture (HPCA), pages 1–13. IEEE, 2026
work page 2026
-
[14]
Shaoting Feng, Yuhan Liu, Hanchen Li, Xiaokun Chen, Samuel Shen, Kuntai Du, Zhuohan Gu, Rui Zhang, Yuyang Huang, Yihua Cheng, et al. Evicpress: Joint kv-cache compression and eviction for efficient llm serving.arXiv preprint arXiv:2512.14946, 2025
-
[15]
In Gim, Guojun Chen, Seung-seob Lee, Nikhil Sarda, Anurag Khandelwal, and Lin Zhong. Prompt cache: Modular attention reuse for low-latency inference.Proceedings of Machine Learning and Systems, 6:325–338, 2024. 10
work page 2024
-
[16]
Llmsteer: Improving long-context llm inference by steering attention on reused contexts, 2024
Zhuohan Gu, Jiayi Yao, Kuntai Du, and Junchen Jiang. Llmsteer: Improving long-context llm inference by steering attention on reused contexts, 2024
work page 2024
-
[17]
Inan, Lukas Wutschitz, Yanzhi Chen, Robert Sim, and Saravan Rajmohan
Minki Kang, Wei-Ning Chen, Dongge Han, Huseyin A Inan, Lukas Wutschitz, Yanzhi Chen, Robert Sim, and Saravan Rajmohan. Acon: Optimizing context compression for long-horizon llm agents.arXiv preprint arXiv:2510.00615, 2025
-
[18]
Heejun Lee, Geon Park, Jaduk Suh, and Sung Ju Hwang. Infinitehip: Extending language model context up to 3 million tokens on a single gpu, 2025.URL https://arxiv. org/abs/2502.08910
-
[19]
Infinigen: Efficient generative inference of large language models with dynamic kv cache management
Wonbeom Lee, Jungi Lee, Junghwan Seo, and Jaewoong Sim. Infinigen: Efficient generative inference of large language models with dynamic kv cache management. In18th USENIX Symposium on Operating Systems Design and Implementation (OSDI 24), pages 155–172, 2024
work page 2024
-
[20]
Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, et al. Retrieval-augmented generation for knowledge-intensive nlp tasks.Advances in neural information processing systems, 33:9459–9474, 2020
work page 2020
-
[21]
Commvq: Commutative vector quantization for kv cache compression, 2025
Junyan Li, Yang Zhang, Muhammad Yusuf Hassan, Talha Chafekar, Tianle Cai, Zhile Ren, Peng- sheng Guo, Foroozan Karimzadeh, Colorado Reed, Chong Wang, and Chuang Gan. Commvq: Commutative vector quantization for kv cache compression, 2025
work page 2025
-
[22]
Yuhan Liu, Yuyang Huang, Jiayi Yao, Shaoting Feng, Zhuohan Gu, Kuntai Du, Hanchen Li, Yihua Cheng, Junchen Jiang, Shan Lu, et al. Droidspeak: Kv cache sharing for cross-llm communication and multi-llm serving.arXiv preprint arXiv:2411.02820, 2024
-
[23]
Cachegen: Kv cache compression and streaming for fast large language model serving
Yuhan Liu, Hanchen Li, Yihua Cheng, Siddhant Ray, Yuyang Huang, Qizheng Zhang, Kuntai Du, Jiayi Yao, Shan Lu, Ganesh Ananthanarayanan, et al. Cachegen: Kv cache compression and streaming for fast large language model serving. InProceedings of the ACM SIGCOMM 2024 Conference, pages 38–56, 2024
work page 2024
-
[24]
KIVI: A Tuning-Free Asymmetric 2bit Quantization for KV Cache
Zirui Liu, Jiayi Yuan, Hongye Jin, Shaochen Zhong, Zhaozhuo Xu, Vladimir Braverman, Beidi Chen, and Xia Hu. Kivi: A tuning-free asymmetric 2bit quantization for kv cache.arXiv preprint arXiv:2402.02750, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[25]
Xing Han Lù, Amirhossein Kazemnejad, Nicholas Meade, Arkil Patel, Dongchan Shin, Ale- jandra Zambrano, Karolina Sta´nczak, Peter Shaw, Christopher J Pal, and Siva Reddy. Agen- trewardbench: Evaluating automatic evaluations of web agent trajectories.arXiv preprint arXiv:2504.08942, 2025
- [26]
-
[27]
Accessed: 2026-03-22
work page 2026
- [28]
-
[29]
OpenAI. Agent Skills – Codex. https://developers.openai.com/codex/skills, 2026. OpenAI Developers. Accessed: 2026-05-04
work page 2026
-
[30]
Gpt-5.4 nano model | openai api, 2026
OpenAI. Gpt-5.4 nano model | openai api, 2026. https://developers.openai.com/api/ docs/models/gpt-5.4-nano
work page 2026
- [31]
-
[32]
OpenAI. text-embedding-3-small Model. https://developers.openai.com/api/do cs/models/text-embedding-3-small , 2026. OpenAI API documentation. Accessed: 2026-04-28
work page 2026
-
[33]
Agentdiagnose: An open toolkit for diagnosing llm agent trajectories
Tianyue Ou, Wanyao Guo, Apurva Gandhi, Graham Neubig, and Xiang Yue. Agentdiagnose: An open toolkit for diagnosing llm agent trajectories. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing: System Demonstrations, pages 207–215, 2025. 11
work page 2025
-
[34]
Richard Yuanzhe Pang, Alicia Parrish, Nitish Joshi, Nikita Nangia, Jason Phang, Angelica Chen, Vishakh Padmakumar, Johnny Ma, Jana Thompson, He He, et al. Quality: Question answering with long input texts, yes! InProceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, ...
work page 2022
-
[35]
Metis: fast quality-aware rag systems with configuration adaptation
Siddhant Ray, Rui Pan, Zhuohan Gu, Kuntai Du, Shaoting Feng, Ganesh Ananthanarayanan, Ravi Netravali, and Junchen Jiang. Metis: fast quality-aware rag systems with configuration adaptation. InProceedings of the ACM SIGOPS 31st symposium on operating systems principles, pages 606–622, 2025
work page 2025
- [36]
-
[37]
Reflexion: Language Agents with Verbal Reinforcement Learning
Noah Shinn, Federico Cassano, Edward Berman, Ashwin Gopinath, Karthik Narasimhan, and Shunyu Yao. Reflexion: Language agents with verbal reinforcement learning, 2023.URL https://arxiv.org/abs/2303.11366, 8, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[38]
Aaditya Singh, Adam Fry, Adam Perelman, Adam Tart, Adi Ganesh, Ahmed El-Kishky, Aidan McLaughlin, Aiden Low, AJ Ostrow, Akhila Ananthram, et al. Openai gpt-5 system card.arXiv preprint arXiv:2601.03267, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[39]
Openclaw: Personal ai assistant
Peter Steinberger and contributors. Openclaw: Personal ai assistant. https://github.com/o penclaw/openclaw, 2025
work page 2025
-
[40]
Scaling long-horizon llm agent via context-folding.arXiv preprint arXiv:2510.11967, 2025
Weiwei Sun, Miao Lu, Zhan Ling, Kang Liu, Xuesong Yao, Yiming Yang, and Jiecao Chen. Scal- ing long-horizon llm agent via context-folding, 2025.URL https://arxiv. org/abs/2510.11967
-
[41]
Dy- namic cheatsheet: Test-time learning with adaptive memory, 2025.URL https://arxiv
Mirac Suzgun, Mert Yuksekgonul, Federico Bianchi, Dan Jurafsky, and James Zou. Dy- namic cheatsheet: Test-time learning with adaptive memory, 2025.URL https://arxiv. org/abs/2504.07952, 2025
-
[42]
Xixi Wu, Kuan Li, Yida Zhao, Liwen Zhang, Litu Ou, Huifeng Yin, Zhongwang Zhang, Xinmiao Yu, Dingchu Zhang, Yong Jiang, et al. Resum: Unlocking long-horizon search intelligence via context summarization.arXiv preprint arXiv:2509.13313, 2025
-
[43]
Zhiqiang Xie, Ziyi Xu, Mark Zhao, Yuwei An, Vikram Sharma Mailthody, Scott Mahlke, Michael Garland, and Christos Kozyrakis. Strata: Hierarchical context caching for long context language model serving.arXiv preprint arXiv:2508.18572, 2025
-
[44]
Amy Yang, Jingyi Yang, Aya Ibrahim, Xinfeng Xie, Bangsheng Tang, Grigory Sizov, Jongsoo Park, and Jianyu Huang. Context parallelism for scalable million-token inference.Proceedings of Machine Learning and Systems, 7, 2025
work page 2025
-
[45]
Jingbo Yang, Bairu Hou, Wei Wei, Yujia Bao, and Shiyu Chang. Kvlink: Accelerating large language models via efficient kv cache reuse.arXiv preprint arXiv:2502.16002, 2025
-
[46]
Cacheblend: Fast large language model serving for rag with cached knowledge fusion
Jiayi Yao, Hanchen Li, Yuhan Liu, Siddhant Ray, Yihua Cheng, Qizheng Zhang, Kuntai Du, Shan Lu, and Junchen Jiang. Cacheblend: Fast large language model serving for rag with cached knowledge fusion. InProceedings of the twentieth European conference on computer systems, pages 94–109, 2025
work page 2025
-
[47]
Jinghan Yao, Sam A Jacobs, Masahiro Tanaka, Olatunji Ruwase, Hari Subramoni, and Dha- baleswar Panda. Training ultra long context language model with fully pipelined distributed transformer.Proceedings of Machine Learning and Systems, 7, 2025
work page 2025
-
[48]
MemAgent: Reshaping Long-Context LLM with Multi-Conv RL-based Memory Agent
Hongli Yu, Tinghong Chen, Jiangtao Feng, Jiangjie Chen, Weinan Dai, Qiying Yu, Ya-Qin Zhang, Wei-Ying Ma, Jingjing Liu, Mingxuan Wang, et al. Memagent: Reshaping long-context llm with multi-conv rl-based memory agent, 2025.URL https://arxiv.org/abs/2507.02259, 2259, 2025. 12
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[49]
Optimizing generative ai by backpropagating language model feedback.Nature, 639(8055):609–616, 2025
Mert Yuksekgonul, Federico Bianchi, Joseph Boen, Sheng Liu, Pan Lu, Zhi Huang, Carlos Guestrin, and James Zou. Optimizing generative ai by backpropagating language model feedback.Nature, 639(8055):609–616, 2025
work page 2025
-
[50]
TurboQuant: Online Vector Quantization with Near-optimal Distortion Rate
Amir Zandieh, Majid Daliri, Majid Hadian, and Vahab Mirrokni. Turboquant: Online vector quantization with near-optimal distortion rate.arXiv preprint arXiv:2504.19874, 2025
work page internal anchor Pith review arXiv 2025
-
[51]
Alex L Zhang, Tim Kraska, and Omar Khattab. Recursive language models.arXiv preprint arXiv:2512.24601, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[52]
Agentic Context Engineering: Evolving Contexts for Self-Improving Language Models
Qizheng Zhang, Changran Hu, Shubhangi Upasani, Boyuan Ma, Fenglu Hong, Vamsidhar Kamanuru, Jay Rainton, Chen Wu, Mengmeng Ji, Hanchen Li, et al. Agentic context engi- neering: Evolving contexts for self-improving language models, 2025a.URL https://arxiv. org/abs/2510.04618
work page internal anchor Pith review Pith/arXiv arXiv
-
[53]
Agentic plan caching: Test-time memory for fast and cost-efficient llm agents, 2026
Qizheng Zhang, Michael Wornow, Gerry Wan, and Kunle Olukotun. Agentic plan caching: Test-time memory for fast and cost-efficient llm agents, 2026
work page 2026
-
[54]
Zhenyu Zhang, Ying Sheng, Tianyi Zhou, Tianlong Chen, Lianmin Zheng, Ruisi Cai, Zhao Song, Yuandong Tian, Christopher Ré, Clark Barrett, et al. H2o: Heavy-hitter oracle for efficient generative inference of large language models.Advances in Neural Information Processing Systems, 36:34661–34710, 2023
work page 2023
-
[55]
Fanoutqa: A multi-hop, multi-document question answering benchmark for large language models
Andrew Zhu, Alyssa Hwang, Liam Dugan, and Chris Callison-Burch. Fanoutqa: A multi-hop, multi-document question answering benchmark for large language models. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers), pages 18–37, 2024
work page 2024
-
[56]
what could go in that constant-sized map?
Mingchen Zhuge, Changsheng Zhao, Dylan Ashley, Wenyi Wang, Dmitrii Khizbullin, Yunyang Xiong, Zechun Liu, Ernie Chang, Raghuraman Krishnamoorthi, Yuandong Tian, et al. Agent- as-a-judge: Evaluate agents with agents.arXiv preprint arXiv:2410.10934, 2024. 13 A Related Work KV-Cache Optimization.KV-cache optimization is an important line of work for improvin...
-
[57]
You should check the content of the ‘context‘ variable to understand what you are working with
A ‘context‘ variable that contains extremely important information about your query. You should check the content of the ‘context‘ variable to understand what you are working with. Make sure you look through it sufficiently as you answer your query
-
[58]
A ‘llm_query‘ function that allows you to query an LLM (that can handle around 500K chars) inside your REPL environment
-
[59]
This is much faster than sequential ‘llm_query‘ calls when you have multiple independent queries
A ‘llm_query_batched‘ function that allows you to query multiple prompts concurrently: ‘llm_query_batched(prompts: List[str]) -> List[str]‘. This is much faster than sequential ‘llm_query‘ calls when you have multiple independent queries. Results are returned in the same order as the input prompts
-
[60]
Use this to check what variables exist before using FINAL_VAR
A ‘SHOW_VARS()‘ function that returns all variables you have created in the REPL. Use this to check what variables exist before using FINAL_VAR
-
[61]
What is the magic number in the context? Here is the chunk: {{chunk}}
The ability to use ‘print()‘ statements to view the output of your REPL code and continue your reasoning. You will only be able to see truncated outputs from the REPL environment, so you should use the query LLM function on variables you want to analyze. You will find this function especially useful when you have to analyze the semantics of the context. U...
-
[62]
Use FINAL(your final answer here) to provide the answer directly
-
[63]
Use FINAL_VAR(variable_name) to return a variable you have created in the REPL environment as your final output WARNING - COMMON MISTAKE: FINAL_VAR retrieves an EXISTING variable. You MUST create and assign the variable in a ‘‘‘repl‘‘‘ block FIRST, then call FINAL_VAR in a SEPARATE step. For example: - WRONG: Calling FINAL_VAR(my_answer) without first cre...
-
[64]
Add CLI entry with file args
-
[65]
Parse Markdown via CommonMark library
-
[66]
Apply semantic HTML template
-
[67]
Handle code blocks, images, links
-
[68]
Add error handling for invalid files Example 2:
-
[69]
Define CSS variables for colors
-
[70]
Add toggle with localStorage state
-
[71]
Refactor components to use variables
-
[72]
Verify all views for readability
-
[73]
Add smooth theme-change transition Example 3:
-
[74]
Set up Node.js + WebSocket server
-
[75]
Add join/leave broadcast events
-
[76]
Implement messaging with timestamps
-
[77]
Add usernames + mention highlighting
-
[78]
Persist messages in lightweight DB
-
[79]
Add typing indicators + unread count **Low-quality plans** Example 1:
-
[80]
Convert to HTML Example 2:
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.