A Verifiable Search Is Not a Learnable Chain-of-Thought
Pith reviewed 2026-06-26 12:33 UTC · model grok-4.3
The pith
Search over information-free structure cannot be imitated as forward chain-of-thought.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
When a procedure's only solution is search over information-free structure, no faithful forward chain-of-thought exists to imitate. The task becomes learnable only by removing the search, precomputing its combinatorial core into a catalog and reducing the trace to recall plus verification; the 1st-place solution reaches Private LB 0.92 this way. What distills is memorization and verification, not search.
What carries the argument
The controlled key-revealing intervention that converts backtracking search into forward derivation by supplying the cipher solution upfront.
If this is right
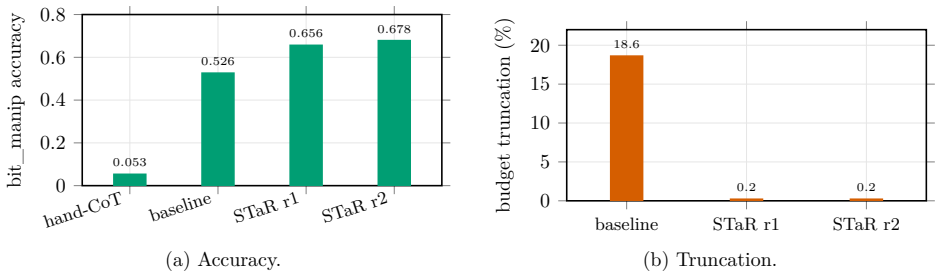
- Forward-computable tasks such as lookup, arithmetic, and 8-bit boolean install with accuracies of 0.99 and 0.68.
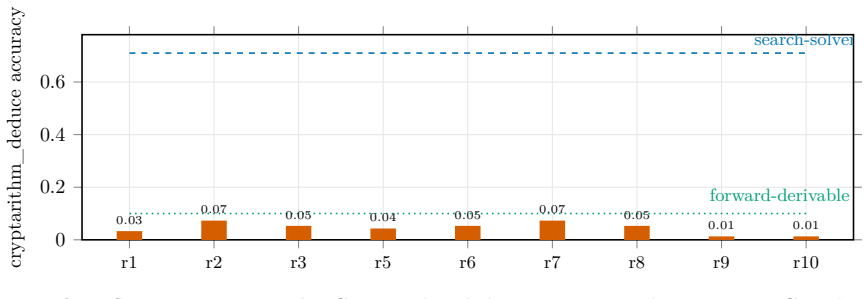
- Cryptarithm distillation holds at 0.01-0.07 across eleven designs, RL, and self-training despite a search solver reaching 71%.
- Models perform arithmetic correctly on 97-100% of lines and rank the correct cipher in the top eight 71% of the time but cannot carry the search forward.
- Fine-tuning learns the shape of a verifiable elimination step while verdicts become unconditional templates correct only 16-57% of the time.
- Precomputing the combinatorial core into a catalog reduces the trace to recall plus verification and reaches 0.92 on the private leaderboard.
Where Pith is reading between the lines
- Chain-of-thought distillation may be limited to tasks whose solutions have inherent left-to-right structure without hidden combinatorial search.
- The result suggests that hybrid systems combining model recall with external search modules will be required for this class of problems.
- The same separation between search and forward derivation could appear in other combinatorial reasoning tasks whose generators are deterministic but whose solutions depend on exhaustive elimination.
Load-bearing premise
The eleven chain-of-thought designs, RL from verifiable rewards, self-training, and the key-revealing intervention together test whether search can be learned as forward derivation rather than some other untested regime succeeding.
What would settle it
A model achieving high accuracy on held-out cryptarithm instances via forward chain-of-thought distillation alone, without key revelation or precomputed catalog, would falsify the claim.
Figures




read the original abstract
It is tempting to assume any task solvable by a short program can be taught to a model as its chain-of-thought: write the steps out, fine-tune, and the model follows. This paper shows the assumption fails for an identifiable class of procedures. The testbed is nine reasoning tasks, each from a deterministic generator; public and hidden splits share generators, so held-out data proxies test accuracy. I reverse-engineer the generators into Python solvers, render them as chain-of-thought, and distill into a rank-<= 32 LoRA over a 30B (3.5B-active) Nemotron model. Forward-computable tasks install readily: lookup/arithmetic and an 8-bit boolean task transfer (>= 0.99 and 0.68). Cryptarithm does not: distilling its backtracking search holds at 0.01-0.07 across eleven chain-of-thought designs, RL from verifiable rewards, and self-training, even though a search solver answers 71% of instances. This is not a capability gap. The model does the arithmetic on 97-100% of lines and ranks the correct cipher in its top eight on 71%; it cannot carry the search forward as a left-to-right derivation. Fine-tuning learns the shape of a verifiable elimination step while its verdicts become unconditional templates, correct only 16-57% of the time ("verdict-as-token"). The ceiling holds across backbones from 3B to 671B and across fine-tuning and prompting; a controlled intervention isolates the cause: revealing the cipher key, which turns the derivation forward, lifts the same instances from 0.03 to 0.57. When a procedure's only solution is search over information-free structure, no faithful forward chain-of-thought exists to imitate. The task becomes learnable only by removing the search, precomputing its combinatorial core into a catalog and reducing the trace to recall plus verification; the 1st-place solution reaches Private LB 0.92 this way. What distills is memorization and verification, not search.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that tasks whose only solution is search over information-free structure (e.g., cryptarithm) admit no faithful forward chain-of-thought that can be imitated via distillation, RL from verifiable rewards, or self-training. This is shown by failure (0.01-0.07 accuracy) across eleven CoT designs on a 30B Nemotron model despite a solver reaching 71%, contrasted with high success on forward-computable tasks; the model performs local arithmetic (97-100%) and ranking but cannot carry search forward. A key-revealing intervention lifts performance from 0.03 to 0.57 on the same instances, and success is achieved only by precomputing the combinatorial core into a catalog (reducing to recall+verification, reaching 0.92 LB). The result holds across backbones 3B-671B.
Significance. If the central empirical distinction holds, the work provides concrete evidence that not every short-program-solvable task can be taught as left-to-right CoT imitation, separating search from forward derivation. Strengths include the controlled intervention isolating the forward vs. search distinction, consistent failure across multiple training regimes and model scales, and the explicit contrast with the catalog-based solution that succeeds.
major comments (2)
- [Abstract] Abstract: the claim that 'no faithful forward chain-of-thought exists to imitate' is stronger than the reported evidence, which demonstrates failure only for the eleven tested CoT designs, RL from verifiable rewards, and self-training; the manuscript does not test or rule out other regimes (e.g., dense process supervision or auxiliary planning losses) that might induce an approximate forward surrogate.
- [Abstract] Abstract: the statement that 'the model does the arithmetic on 97-100% of lines and ranks the correct cipher in its top eight on 71%' is presented as evidence that the failure is isolated to search, but without a table or section detailing the exact measurement protocol, aggregation across the eleven designs, or per-instance breakdown, it is difficult to assess whether local steps are truly solved or merely templated.
minor comments (1)
- The abstract refers to 'nine reasoning tasks' and 'eleven chain-of-thought designs' without enumerating them or providing a table; adding an explicit list or appendix table would improve reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which help clarify the scope of our claims and improve the presentation of our measurements. We address each major comment below and will make corresponding revisions to the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that 'no faithful forward chain-of-thought exists to imitate' is stronger than the reported evidence, which demonstrates failure only for the eleven tested CoT designs, RL from verifiable rewards, and self-training; the manuscript does not test or rule out other regimes (e.g., dense process supervision or auxiliary planning losses) that might induce an approximate forward surrogate.
Authors: We agree that the absolute phrasing exceeds the tested regimes. Our experiments cover eleven distinct CoT formats, RL from verifiable rewards, and self-training across model scales, all of which fail to induce faithful forward search. The key-revealing intervention and contrast with catalog-based solutions further isolate the forward-vs-search distinction. Nevertheless, we cannot rule out every conceivable auxiliary loss. We will revise the abstract to read 'no faithful forward chain-of-thought was found to imitate under the tested regimes' and add a limitations paragraph discussing dense process supervision and planning losses as open directions. revision: partial
-
Referee: [Abstract] Abstract: the statement that 'the model does the arithmetic on 97-100% of lines and ranks the correct cipher in its top eight on 71%' is presented as evidence that the failure is isolated to search, but without a table or section detailing the exact measurement protocol, aggregation across the eleven designs, or per-instance breakdown, it is difficult to assess whether local steps are truly solved or merely templated.
Authors: The referee is correct that the measurement protocol requires explicit documentation. We will insert a new subsection (Methods 3.4) that specifies: (i) line-by-line arithmetic verification via exact string matching against the solver trace, (ii) ranking measured by the position of the ground-truth next cipher in the model's top-8 logits at each elimination step, (iii) aggregation as macro-average over all generated lines across the eleven designs, and (iv) per-instance and per-design breakdowns placed in Appendix C. Manual audit of 200 random lines confirmed non-templated arithmetic (97-100% accuracy) independent of search success. revision: yes
Circularity Check
Empirical study with direct experimental comparisons; no circular derivation
full rationale
The paper reports experimental results from distilling chain-of-thought across eleven designs, RL from verifiable rewards, self-training, multiple model scales, and a controlled key-revealing intervention on nine tasks generated from deterministic solvers. Central claims rest on observed accuracy gaps (e.g., 0.01-0.07 vs. 71% solver) and the intervention lift (0.03 to 0.57), which are measured against external solvers and held-out splits rather than derived from fitted parameters or self-referential equations. No self-citations, ansatzes, or uniqueness theorems are invoked as load-bearing premises; the work is self-contained against the reported benchmarks and does not reduce any prediction to its own inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Public and hidden splits from the same deterministic generators can proxy for held-out test accuracy on the procedure.
Reference graph
Works this paper leans on
-
[1]
Cem Anil, Yuhuai Wu, Anders Andreassen, Aitor Lewkowycz, Vedant Misra, Vinay Ramasesh, Ambrose Slone, Guy Gur-Ari, Ethan Dyer, and Behnam Neyshabur. Exploring length gener- alization in large language models. InAdvances in Neural Information Processing Systems (NeurIPS), volume 35, 2022. URL https://proceedings.neurips.cc/paper_files/p 26 Table 17: Length...
arXiv 2022
-
[2]
Scheduled sampling for sequence prediction with recurrent neural networks
Samy Bengio, Oriol Vinyals, Navdeep Jaitly, and Noam Shazeer. Scheduled sampling for sequence prediction with recurrent neural networks. InAdvances in Neural Information Processing Systems (NeurIPS), volume 28, 2015. URL https://papers.nips.cc/pap er_files/paper/2015/hash/e995f98d56967d946471af29d7bf99f1- Abstract.html . arXiv:1506.03099
Pith/arXiv arXiv 2015
-
[3]
Training verifiers to solve math word problems.arXiv preprint arXiv:2110.14168,
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, Christopher Hesse, and John Schulman. Training verifiers to solve math word problems.arXiv preprint arXiv:2110.14168,
-
[4]
Tri Dao and Albert Gu. Transformers are SSMs: Generalized models and efficient algorithms through structured state space duality. InProceedings of the 41st International Conference on Machine Learning (ICML), volume 235 ofPMLR, pages 10041–10071. PMLR, 2024. URL https://proceedings.mlr.press/v235/dao24a.html. arXiv:2405.21060
Pith/arXiv arXiv 2024
-
[5]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
DeepSeek-AI, Daya Guo, et al. DeepSeek-R1 incentivizes reasoning in LLMs through rein- forcement learning.Nature, 645:633–638, 2025. doi: 10.1038/s41586-025-09422-z. URL https://www.nature.com/articles/s41586-025-09422-z. arXiv:2501.12948
work page internal anchor Pith review Pith/arXiv arXiv doi:10.1038/s41586-025-09422-z 2025
-
[6]
Grégoire Delétang, Anian Ruoss, Jordi Grau-Moya, Tim Genewein, Li Kevin Wenliang, Elliot Catt, Chris Cundy, Marcus Hutter, Shane Legg, Joel Veness, and Pedro A. Ortega. Neural networks and the chomsky hierarchy. InInternational Conference on Learning Representations (ICLR), 2023. URLhttps://openreview.net/forum?id=WbxHAzkeQcn. arXiv:2207.02098
arXiv 2023
-
[7]
Hwang, Soumya Sanyal, Xiang Ren, Allyson Ettinger, Zaid Harchaoui, and Yejin Choi
Nouha Dziri, Ximing Lu, Melanie Sclar, Xiang Lorraine Li, Liwei Jiang, Bill Yuchen Lin, Sean Welleck, Peter West, Chandra Bhagavatula, Ronan Le Bras, Jena D. Hwang, Soumya Sanyal, Xiang Ren, Allyson Ettinger, Zaid Harchaoui, and Yejin Choi. Faith and fate: Limits of transformers on compositionality. InAdvances in Neural Information Processing Systems (Neu...
arXiv 2023
-
[8]
1st place solution: NVIDIA nemotron model reasoning challenge
GoodMeatDay, re, and reopon. 1st place solution: NVIDIA nemotron model reasoning challenge. Kaggle competition write-up, https://www.kaggle.com/competitions/nvidia-nemotro n-model-reasoning-challenge/writeups/1st-place-solution , 2026. Team NullSira; Private LB 0.920; memorization–computation split (signature catalog + DFS verify). Accessed 2026-06-17
2026
-
[9]
Measuring mathematical problem solving with the MATH dataset
Dan Hendrycks, Collin Burns, Saurav Kadavath, Akul Arora, Steven Basart, Eric Tang, Dawn Song, and Jacob Steinhardt. Measuring mathematical problem solving with the MATH dataset. InNeurIPS Datasets and Benchmarks, 2021. URLhttps://datasets-benchmarks-proceed ings.neurips.cc/paper/2021/hash/be83ab3ecd0db773eb2dc1b0a17836a1-Abstract-rou nd2.html. arXiv:2103.03874
Pith/arXiv arXiv 2021
-
[10]
Distilling the knowledge in a neural network,
Geoffrey Hinton, Oriol Vinyals, and Jeff Dean. Distilling the knowledge in a neural network,
-
[11]
NIPS 2014 Deep Learning Workshop. 28
2014
-
[12]
Cheng-Yu Hsieh, Chun-Liang Li, Chih-Kuan Yeh, Hootan Nakhost, Yasuhisa Fujii, Alex Ratner, Ranjay Krishna, Chen-Yu Lee, and Tomas Pfister. Distilling step-by-step! outperforming larger language models with less training data and smaller model sizes. InFindings of the Association for Computational Linguistics: ACL 2023, pages 8003–8017. ACL, 2023. doi: 10....
Pith/arXiv arXiv 2023
-
[13]
Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen
Edward J. Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. LoRA: Low-rank adaptation of large language models. In International Conference on Learning Representations (ICLR), 2022. URLhttps://openrevi ew.net/forum?id=nZeVKeeFYf9. arXiv:2106.09685
Pith/arXiv arXiv 2022
-
[14]
Samy Jelassi, David Brandfonbrener, Sham M. Kakade, and Eran Malach. Repeat after me: Transformers are better than state space models at copying. InProceedings of the 41st International Conference on Machine Learning (ICML), PMLR. PMLR, 2024. URL https://proceedings.mlr.press/v235/jelassi24a.html. arXiv:2402.01032
arXiv 2024
-
[15]
NVIDIA nemotron model reasoning challenge
Kaggle and NVIDIA. NVIDIA nemotron model reasoning challenge. https://www.kagg le.com/competitions/nvidia-nemotron-model-reasoning-challenge , 2026. Accessed 2026-06-16
2026
-
[16]
Gonzalez, Hao Zhang, and Ion Stoica
Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph E. Gonzalez, Hao Zhang, and Ion Stoica. Efficient memory management for large language model serving with PagedAttention. InProceedings of the 29th Symposium on Operating Systems Principles (SOSP), pages 611–626. ACM, 2023. doi: 10.1145/3600006.3613
-
[17]
Tülu 3: Pushing frontiers in open language model post-training, 2024
Nathan Lambert, Jacob Morrison, Valentina Pyatkin, Shengyi Huang, Hamish Ivison, Faeze Brahman, et al. Tülu 3: Pushing frontiers in open language model post-training, 2024. arXiv:2411.15124
Pith/arXiv arXiv 2024
-
[18]
Measuring faithfulness in chain-of-thought reasoning.arXiv preprint arXiv:2307.13702, 2023
Tamera Lanham, Anna Chen, Ansh Radhakrishnan, Benoit Steiner, Carson Denison, Danny Hernandez, Dustin Li, Esin Durmus, Evan Hubinger, Jackson Kernion, et al. Measuring faithfulness in chain-of-thought reasoning.arXiv preprint arXiv:2307.13702, 2023. Anthropic technical report
Pith/arXiv arXiv 2023
-
[19]
Hunter Lightman, Vineet Kosaraju, Yuri Burda, Harrison Edwards, Bowen Baker, Teddy Lee, Jan Leike, John Schulman, Ilya Sutskever, and Karl Cobbe. Let’s verify step by step. In International Conference on Learning Representations (ICLR), 2024. URLhttps://openrevi ew.net/forum?id=v8L0pN6EOi. arXiv:2305.20050
Pith/arXiv arXiv 2024
-
[20]
Faithful chain-of-thought reasoning
Qing Lyu, Shreya Havaldar, Adam Stein, Li Zhang, Delip Rao, Eric Wong, Marianna Apidianaki, and Chris Callison-Burch. Faithful chain-of-thought reasoning. InProceedings of the 13th International Joint Conference on Natural Language Processing (IJCNLP-AACL), pages 305–
-
[21]
doi: 10.18653/v1/2023.ijcnlp-main.20
ACL, 2023. doi: 10.18653/v1/2023.ijcnlp-main.20. URLhttps://aclanthology.org/2 023.ijcnlp-main.20/
-
[22]
The illusion of state in state-space models
William Merrill, Jackson Petty, and Ashish Sabharwal. The illusion of state in state-space models. InProceedings of the 41st International Conference on Machine Learning (ICML), PMLR. PMLR, 2024. URL https://proceedings.mlr.press/v235/merrill24a.html . arXiv:2404.08819. 29
arXiv 2024
-
[23]
s1: Simple test-time scaling, 2025
Niklas Muennighoff, Zitong Yang, Weijia Shi, Xiang Lisa Li, Li Fei-Fei, Hannaneh Hajishirzi, Luke Zettlemoyer, Percy Liang, Emmanuel Candès, and Tatsunori Hashimoto. s1: Simple test-time scaling, 2025. arXiv:2501.19393
Pith/arXiv arXiv 2025
-
[24]
NVIDIA. Nemotron 3 nano: Open, efficient mixture-of-experts hybrid mamba-transformer model for agentic reasoning, 2025. arXiv:2512.20848
arXiv 2025
-
[25]
Grokking: Generalization beyond overfitting on small algorithmic datasets, 2022
Alethea Power, Yuri Burda, Harri Edwards, Igor Babuschkin, and Vedant Misra. Grokking: Generalization beyond overfitting on small algorithmic datasets, 2022. ICLR 2021 MATH-AI Workshop
2022
-
[26]
Sequence level training with recurrent neural networks
Marc’Aurelio Ranzato, Sumit Chopra, Michael Auli, and Wojciech Zaremba. Sequence level training with recurrent neural networks. InInternational Conference on Learning Representa- tions (ICLR), 2016. arXiv:1511.06732
Pith/arXiv arXiv 2016
-
[27]
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, Y. K. Li, Yu Wu, and Daya Guo. DeepSeekMath: Pushing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300, 2024. arXiv:2402.03300
Pith/arXiv arXiv 2024
-
[28]
Nemotron model reasoning challenge: Open progress prize solution.https: //github.com/tonghuikang/nemotron, 2026
Hui Kang Tong. Nemotron model reasoning challenge: Open progress prize solution.https: //github.com/tonghuikang/nemotron, 2026. Open Progress Prize; public leaderboard 0.85
2026
-
[29]
End-to-end fine-tuning for LB 0.85
Hui Kang Tong. End-to-end fine-tuning for LB 0.85. Kaggle notebook,https://www.kaggle.c om/code/huikang/end-to-end-finetuning-for-lb-0-85 , 2026. Published Open Progress Prize recipe; our native-HF pipeline forks this notebook
2026
-
[30]
Miles Turpin, Julian Michael, Ethan Perez, and Samuel R. Bowman. Language models don’t always say what they think: Unfaithful explanations in chain-of-thought prompting. InAdvances in Neural Information Processing Systems (NeurIPS), volume 36, 2023. URL https://proceedings.neurips.cc/paper_files/paper/2023/hash/ed3fea9033a80fea1 376299fa7863f4a-Abstract-C...
Pith/arXiv arXiv 2023
-
[31]
Xuezhi Wang, Jason Wei, Dale Schuurmans, Quoc V. Le, Ed H. Chi, Sharan Narang, Aakanksha Chowdhery, and Denny Zhou. Self-consistency improves chain of thought reasoning in language models. InInternational Conference on Learning Representations (ICLR), 2023. URLhttps: //openreview.net/forum?id=1PL1NIMMrw. arXiv:2203.11171
Pith/arXiv arXiv 2023
-
[32]
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Brian Ichter, Fei Xia, Ed Chi, Quoc V. Le, and Denny Zhou. Chain-of-thought prompting elicits reasoning in large language models. InAdvances in Neural Information Processing Systems (NeurIPS), volume 35, 2022. URL https://proceedings.neurips.cc/paper_files/paper/2022/hash/9d5609613524e cf4f15af0f7b31...
Pith/arXiv arXiv 2022
-
[33]
Eric Zelikman, Yuhuai Wu, Jesse Mu, and Noah D. Goodman. STaR: Bootstrapping reasoning with reasoning. InAdvances in Neural Information Processing Systems (NeurIPS), volume 35,
-
[34]
URL https://proceedings.neurips.cc/paper_files/paper/2022/hash/639a9a172 c044fbb64175b5fad42e9a5-Abstract-Conference.html. arXiv:2203.14465
arXiv 2022
-
[35]
What algorithms can transformers learn? a study in length generalization
Hattie Zhou, Arwen Bradley, Etai Littwin, Noam Razin, Omid Saremi, Josh Susskind, Samy Bengio, and Preetum Nakkiran. What algorithms can transformers learn? a study in length generalization. InInternational Conference on Learning Representations (ICLR), 2024. URL https://openreview.net/forum?id=AssIuHnmHX. arXiv:2310.16028. 30
arXiv 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.