ChainWorld: Composing Long-Horizon Desktop Workloads from Atomic OSWorld Tasks
Pith reviewed 2026-06-26 14:03 UTC · model grok-4.3
The pith
ChainWorld composes atomic desktop tasks into long-horizon workloads where current agents reach at most 31 percent completion.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
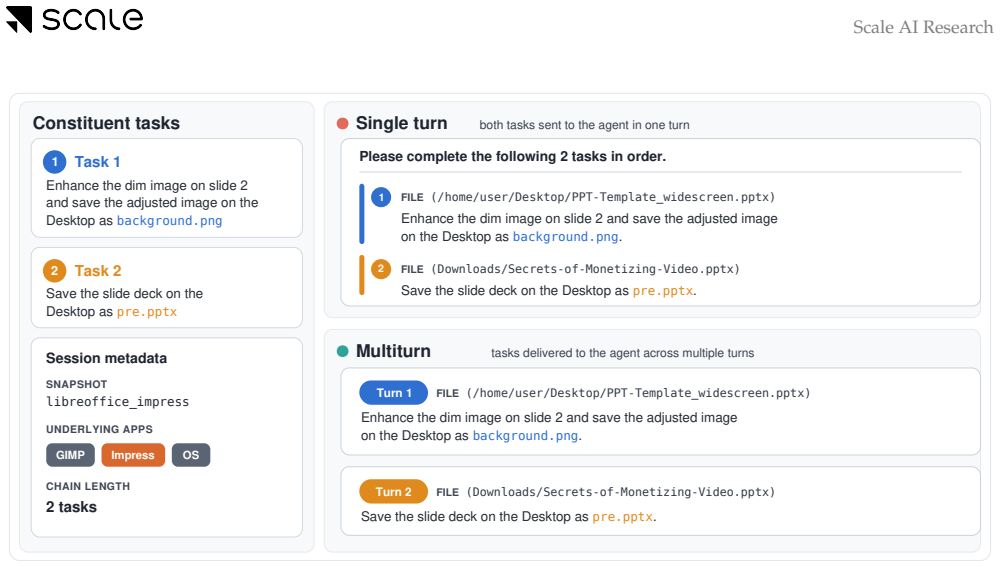
ChainWorld uses directional compatibility search to build 347 chains from atomic OSWorld tasks. These chains test whether agents can sustain state across sequential objectives. In single-turn evaluation all tasks are given at once, while multi-turn reveals them sequentially. Across four agents the highest chain completion rate is 31 percent. Multi-turn improves results for three models, but the two protocols highlight different weaknesses: single-turn struggles with precise artifact handling and multi-turn with session management and disengagement.
What carries the argument
ChainWorld, the composition system that assembles long-horizon desktop workloads from atomic OSWorld tasks through directional compatibility search while preserving the source evaluators.
Load-bearing premise
The directional compatibility search produces valid, realistic long-horizon workloads that preserve the source evaluators and meaningfully test sustained state across objectives.
What would settle it
A new agent achieving high completion rates on these chains while still failing on extended real-world desktop sessions would show the chains do not capture the intended sustained-state challenge.
Figures


read the original abstract
Computer use agents are evaluated almost exclusively on atomic desktop tasks, but realistic desktop work requires sustaining state across multiple objectives. We study this gap with ChainWorld, which composes atomic OSWorld tasks into long horizon desktop workloads through directional compatibility search while preserving the source evaluators. The resulting workload contains 347 chains of length two to four and compares two renderings of the same task sequence. In single turn evaluation, all tasks are presented together in one prompt. In multi turn evaluation, tasks are revealed one at a time. Across four current computer use agents, maximum chain completion is 31%. Multi turn evaluation improves completion for three models, but both protocols remain challenging. The two protocols also expose different failure profiles. Single turn failures concentrate on artifact precision, while multi turn failures more often reflect session management problems such as fragmented progress and later turn disengagement.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces ChainWorld to compose atomic OSWorld tasks into long-horizon desktop workloads via directional compatibility search while preserving source evaluators. It generates 347 chains of length 2–4 and evaluates four computer-use agents under single-turn (all tasks in one prompt) versus multi-turn (tasks revealed sequentially) protocols. The central empirical claim is that maximum chain completion reaches only 31%, multi-turn improves completion for three models, both protocols remain challenging, and the protocols expose distinct failure profiles (artifact precision in single-turn; session management and disengagement in multi-turn).
Significance. If the directional compatibility search produces chains with genuine state-sustaining dependencies, the work supplies a concrete benchmark exposing the gap between atomic-task and realistic long-horizon desktop performance. The dual-protocol design and differentiated failure-mode analysis would be useful for guiding agent development.
major comments (2)
- [Abstract / Methods] Abstract and Methods (directional compatibility search): the headline result (max 31% chain completion and protocol-dependent failure profiles) requires that the 347 chains test sustained state across objectives. The manuscript provides no definition of directional compatibility, no dependency analysis, and no validation (human or automated) that consecutive tasks require carrying over artifacts or session state; without this, the reported completion rates and differing failure modes could be artifacts of surface-attribute matching rather than evidence about long-horizon behavior.
- [Abstract] Abstract: concrete numbers (347 chains, 31% completion) are reported without details on search implementation, chain validation procedure, agent prompts, or statistical significance testing, undermining verifiability of the empirical claims.
minor comments (2)
- Clarify whether the source OSWorld evaluators are run unchanged on the composed chains or require any adaptation.
- Provide the exact criteria or algorithm used for directional compatibility search so that the construction can be reproduced or audited.
Simulated Author's Rebuttal
We thank the referee for these constructive comments highlighting the need for explicit definitions, validation, and implementation details. We address each point below and will make revisions to improve verifiability while preserving the core empirical claims.
read point-by-point responses
-
Referee: [Abstract / Methods] Abstract and Methods (directional compatibility search): the headline result (max 31% chain completion and protocol-dependent failure profiles) requires that the 347 chains test sustained state across objectives. The manuscript provides no definition of directional compatibility, no dependency analysis, and no validation (human or automated) that consecutive tasks require carrying over artifacts or session state; without this, the reported completion rates and differing failure modes could be artifacts of surface-attribute matching rather than evidence about long-horizon behavior.
Authors: We agree that a precise definition and validation of state-sustaining dependencies are essential to support claims about long-horizon behavior. The directional compatibility search is intended to identify task sequences where output artifacts from one task serve as inputs to the next, but the current manuscript does not include an explicit definition, dependency graph analysis, or validation step. We will revise the Methods section to add (1) a formal definition of directional compatibility, (2) examples of chains with explicit state carry-over requirements, and (3) any automated checks or human validation performed. If no such validation was conducted beyond the search heuristic itself, we will state this limitation clearly and note it as a direction for future work. revision: yes
-
Referee: [Abstract] Abstract: concrete numbers (347 chains, 31% completion) are reported without details on search implementation, chain validation procedure, agent prompts, or statistical significance testing, undermining verifiability of the empirical claims.
Authors: We concur that the abstract and main text should supply sufficient methodological detail for reproducibility. We will expand the Methods section with the exact implementation of the directional compatibility search (including compatibility criteria and search algorithm), the procedure used to validate generated chains, the full prompts provided to each agent under both protocols, and any statistical tests or confidence intervals applied to the completion rates. revision: yes
Circularity Check
No circularity: empirical benchmark construction with direct measurements
full rationale
The paper describes construction of 347 task chains via directional compatibility search on OSWorld tasks, followed by direct empirical evaluation of four agents under single-turn and multi-turn protocols. Maximum completion rate of 31% and protocol-dependent failure profiles are reported as measured outcomes. No equations, fitted parameters, self-citations, or uniqueness theorems appear in the provided text. The directional compatibility search is a construction method whose validity is assumed for the benchmark but is not itself derived from or reduced to the reported results. All load-bearing claims remain independent empirical observations rather than self-referential reductions.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Atomic OSWorld tasks can be composed into valid long-horizon workloads via directional compatibility search without invalidating the original task evaluators.
Reference graph
Works this paper leans on
-
[1]
Claude Opus 4.7, 2026
Anthropic. Claude Opus 4.7, 2026. URLhttps://www.anthropic.com/news/claude-opus-4-7. 11 Scale AI Research
2026
-
[2]
L. Boisvert, M. Thakkar, M. Gasse, M. Caccia, T. L. S. D. Chezelles, Q. Cappart, N. Chapados, A. Lacoste, and A. Drouin. Workarena++: Towards compositional planning and reasoning-based common knowledge work tasks, 2025. URLhttps://arxiv.org/abs/2407.05291
arXiv 2025
-
[3]
R. Cao, F. Lei, H. Wu, J. Chen, Y. Fu, H. Gao, X. Xiong, H. Zhang, Y. Mao, W. Hu, T. Xie, H. Xu, D. Zhang, S. Wang, R. Sun, P . Yin, C. Xiong, A. Ni, Q. Liu, V . Zhong, L. Chen, K. Yu, and T. Yu. Spider2-v: How far are multimodal agents from automating data science and engineering work- flows?CoRR, abs/2407.10956, 2024. URLhttps://arxiv.org/abs/2407.10956
arXiv 2024
-
[4]
C. Chen, K. Ji, H. Zhong, M. Zhu, A. Li, G. Gan, Z. Huang, C. Zou, J. Liu, J. Chen, H. Chen, and C. Shen. Gui-shepherd: Reliable process reward and verification for long-sequence gui tasks, 2025. URLhttps://arxiv.org/abs/2509.23738
arXiv 2025
-
[5]
Gemini 3.1 pro model card, 2026
Google DeepMind. Gemini 3.1 pro model card, 2026. URL https://deepmind.google/models/ model-cards/gemini-3-1-pro
2026
-
[6]
Y. He, J. Jin, and P . Liu. Efficient agent training for computer use, 2026. URLhttps://arxiv.org/ abs/2505.13909
arXiv 2026
-
[7]
J. Y. Koh, R. Lo, L. Jang, V . Duvvur, M. C. Lim, P .-Y. Huang, G. Neubig, S. Zhou, R. Salakhutdinov, and D. Fried. Visualwebarena: Evaluating multimodal agents on realistic visual web tasks.arXiv preprint arXiv:2401.13649, 2024
Pith/arXiv arXiv 2024
-
[8]
P . Laban, H. Hayashi, Y. Zhou, and J. Neville. Llms get lost in multi-turn conversation, 2025. URL https://arxiv.org/abs/2505.06120
Pith/arXiv arXiv 2025
-
[9]
H. Lai, X. Liu, Y. Zhao, H. Xu, H. Zhang, B. Jing, Y. Ren, S. Yao, Y. Dong, and J. Tang. Computerrl: Scaling end-to-end online reinforcement learning for computer use agents, 2025. URL https: //arxiv.org/abs/2508.14040
arXiv 2025
-
[10]
C. Ma, J. Zhang, Z. Zhu, C. Yang, Y. Yang, Y. Jin, Z. Lan, L. Kong, and J. He. Agentboard: An analytical evaluation board of multi-turn llm agents, 2024
2024
-
[11]
Murty, H
S. Murty, H. Zhu, D. Bahdanau, and C. D. Manning. Nnetnav: Unsupervised learning of browser agents through environment interaction in the wild, 2025. URL https://arxiv.org/abs/2410. 02907
2025
-
[12]
T. Ou, F. F. Xu, A. Madaan, J. Liu, R. Lo, A. Sridhar, S. Sengupta, D. Roth, G. Neubig, and S. Zhou. Synatra: Turning indirect knowledge into direct demonstrations for digital agents at scale, 2024. URLhttps://arxiv.org/abs/2409.15637
arXiv 2024
- [13]
-
[14]
J. Pan, Y. Zhang, N. Tomlin, Y. Zhou, S. Levine, and A. Suhr. Autonomous evaluation and refinement of digital agents, 2024. URLhttps://arxiv.org/abs/2404.06474
arXiv 2024
-
[15]
Rawles, S
C. Rawles, S. Clinckemaillie, Y. Chang, J. Waltz, G. Lau, M. Fair, A. Li, W. Bishop, W. Li, F. Campbell- Ajala, D. Toyama, R. Berry, D. Tyamagundlu, T. Lillicrap, and O. Riva. Androidworld: A dynamic benchmarking environment for autonomous agents, 2024. URL https://arxiv.org/abs/2405. 14573. 12 Scale AI Research
2024
-
[16]
A. Singh, A. Fry, A. Perelman, A. Tart, A. Ganesh, A. El-Kishky, A. McLaughlin, A. Low, A. Ostrow, A. Ananthram, A. Nathan, A. Luo, A. Helyar, A. Madry, A. Efremov, A. Spyra, A. Baker-Whitcomb, A. Beutel, A. Karpenko, A. Makelov, A. Neitz, A. Wei, A. Barr, A. Kirchmeyer, A. Ivanov, A. Chris- takis, A. Gillespie, A. Tam, A. Bennett, A. Wan, A. Huang, A. M....
Pith/arXiv arXiv 2026
-
[17]
Q. Sun, K. Cheng, Z. Ding, C. Jin, Y. Wang, F. Xu, Z. Wu, C. Jia, L. Chen, Z. Liu, B. Kao, G. Li, J. He, Y. Qiao, and Z. Wu. Os-genesis: Automating gui agent trajectory construction via reverse task synthesis, 2025. URLhttps://arxiv.org/abs/2412.19723
arXiv 2025
-
[18]
K. Team, T. Bai, Y. Bai, Y. Bao, S. H. Cai, Y. Cao, Y. Charles, H. S. Che, C. Chen, G. Chen, H. Chen, J. Chen, J. Chen, J. Chen, J. Chen, K. Chen, L. Chen, R. Chen, X. Chen, Y. Chen, Y. Chen, Y. Chen, Y. Chen, Y. Chen, Y. Chen, Y. Chen, Y. Chen, Z. Chen, Z. Chen, D. Cheng, M. Chu, J. Cui, J. Deng, M. Diao, H. Ding, M. Dong, M. Dong, Y. Dong, Y. Dong, A. D...
Pith/arXiv arXiv 2026
-
[19]
H. Wang, H. Zou, H. Song, J. Feng, J. Fang, J. Lu, L. Liu, Q. Luo, S. Liang, S. Huang, W. Zhong, Y. Ye, Y. Qin, Y. Xiong, Y. Song, Z. Wu, A. Li, B. Li, C. Dun, C. Liu, D. Zan, F. Leng, H. Wang, H. Yu, H. Chen, H. Guo, J. Su, J. Huang, K. Shen, K. Shi, L. Yan, P . Zhao, P . Liu, Q. Ye, R. Zheng, S. Xin, W. X. Zhao, W. Heng, W. Huang, W. Wang, X. Qin, Y. Li...
Pith/arXiv arXiv 2025
-
[20]
W. Wang, D. Han, D. M. Diaz, J. Xu, V . Rühle, and S. Rajmohan. Odysseybench: Evaluating llm agents on long-horizon complex office application workflows, 2025. URL https://arxiv.org/abs/ 2508.09124
arXiv 2025
-
[21]
J. Xie, D. Xu, X. Zhao, and D. Song. Agentsynth: Scalable task generation for generalist computer-use agents, 2026. URLhttps://arxiv.org/abs/2506.14205
arXiv 2026
-
[22]
T. Xie, D. Zhang, J. Chen, X. Li, S. Zhao, R. Cao, T. J. Hua, Z. Cheng, D. Shin, F. Lei, Y. Liu, Y. Xu, S. Zhou, S. Savarese, C. Xiong, V . Zhong, and T. Yu. Osworld: Benchmarking multimodal agents for open-ended tasks in real computer environments, 2024
2024
-
[23]
F. F. Xu, Y. Song, B. Li, Y. Tang, K. Jain, M. Bao, Z. Z. Wang, X. Zhou, Z. Guo, M. Cao, M. Yang, H. Y. Lu, A. Martin, Z. Su, L. Maben, R. Mehta, W. Chi, L. Jang, Y. Xie, S. Zhou, and G. Neubig. Theagentcompany: Benchmarking llm agents on consequential real world tasks, 2025. URL https: //arxiv.org/abs/2412.14161
Pith/arXiv arXiv 2025
-
[24]
Y. Xu, D. Lu, Z. Shen, J. Wang, Z. Wang, Y. Mao, C. Xiong, and T. Yu. Agenttrek: Agent trajectory synthesis via guiding replay with web tutorials, 2025. URLhttps://arxiv.org/abs/2412.09605
arXiv 2025
-
[25]
S. Zhou, F. F. Xu, H. Zhu, X. Zhou, R. Lo, A. Sridhar, X. Cheng, Y. Bisk, D. Fried, U. Alon, et al. Webarena: A realistic web environment for building autonomous agents.ICLR, 2024
2024
-
[26]
Zhuge, C
M. Zhuge, C. Zhao, D. Ashley, W. Wang, D. Khizbullin, Y. Xiong, Z. Liu, E. Chang, R. Krishnamoorthi, Y. Tian, Y. Shi, V . Chandra, and J. Schmidhuber. Agent-as-a-judge: Evaluate agents with agents,
-
[27]
URLhttps://arxiv.org/abs/2410.10934. 15 Scale AI Research A Workload Construction Details A.1 Pipeline Statistics An anonymous release of the construction code and workload metadata is available at https:// anonymous.4open.science/r/os_world_chained_review-E8D6. The release includes the composition engine, accepted workload metadata, and judging schema us...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.