FedLAS: Feature-Modulated Bidirectional Label Smoothing for Neural Network Calibration
Pith reviewed 2026-06-30 09:18 UTC · model grok-4.3
The pith
Feature-norm indicator and bidirectional gating let label smoothing correct both over- and under-confidence on a per-sample basis.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By coupling a feature-norm confidence indicator with a bidirectional gating mechanism, FedLAS supplies each training sample with the precise degree and direction of smoothing required at that training step, thereby removing the uniform-rule and one-sided limitations of prior label-smoothing methods and yielding measurably better calibrated softmax outputs.
What carries the argument
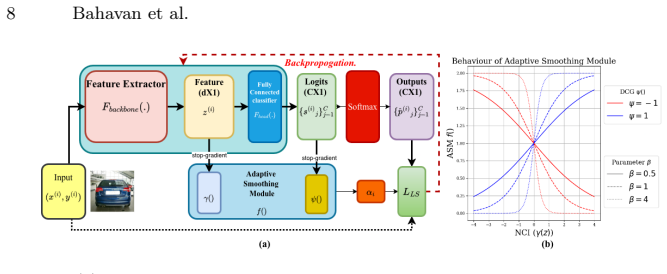
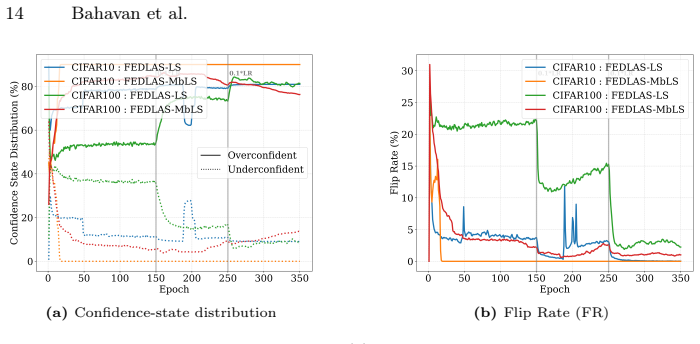
Feature Norm-based Confidence Indicator (NCI) paired with Bidirectional Calibration Gating (BCG) module, which together read per-sample feature norms to detect over- or under-confidence and modulate the smoothing target accordingly.
If this is right
- ECE and Adaptive ECE drop relative to modern label-smoothing baselines on standard and fine-grained vision benchmarks.
- Top-1 accuracy remains unchanged.
- The method integrates directly with both conventional label smoothing and margin-based label smoothing losses.
- Gains appear across both coarse and fine-grained high-resolution image classification tasks.
Where Pith is reading between the lines
- Because NCI is derived from internal feature norms rather than external validation data, the same idea could be tested on sequential or reinforcement-learning losses where confidence must be adjusted on the fly.
- If feature norms track confidence reliably, similar norm-based gating could be inserted into other entropy-regularization schemes beyond label smoothing.
- The bidirectional aspect suggests that training dynamics in later epochs may benefit from deliberately increasing target probabilities for under-confident but correct examples.
Load-bearing premise
The Feature Norm-based Confidence Indicator accurately identifies the specific confidence state of each sample at each training step and that this state interacts usefully with the Bidirectional Calibration Gating module.
What would settle it
Running the same vision benchmarks with FedLAS and with ordinary label smoothing and finding no reduction in ECE or Adaptive ECE, or finding that NCI values show no statistical association with per-sample prediction correctness.
Figures

read the original abstract
Deep Neural Network (DNN) classifiers suffer from poor calibration when their softmax outputs (predictive confidence) deviate from the empirical likelihoods. This manifests itself as either overconfident incorrect predictions or under-confident correct predictions. Label smoothing (LS) enhances model calibration by introducing entropy regularization during training through redistributing probability mass from the ground-truth label to the remaining classes. LS, including Margin-based LS (MbLS), have restrictive assumptions: they rely on predefined, uniform smoothing rules and only tackle overconfidence. In reality, samples exhibit diverse characteristics, such as difficulty/ambiguity, that interact with the evolving nature of the model being trained. In training, samples may have various degrees of under- or overconfidence. To overcome this, a mechanism that identifies the specific confidence state of each sample and determines the appropriate degree of smoothing in each training step is needed, tailoring the adjustment to the individual sample. We propose FedLAS: Feature-Modulated Bidirectional Label Smoothing, a plug-and-play algorithm for label smoothing-based losses. In FedLAS, we introduce a Feature Norm-based Confidence Indicator (NCI) to control smoothing and a Bidirectional Calibration Gating (BCG) module to detect both over and under-confidence. Our algorithm can be integrated with LS and MbLS based losses when applied to standard DNNs, enhancing performance. Extensive experiments on standard and fine-grained high-resolution vision benchmarks show that FedLAS consistently improves calibration compared to modern baselines, reducing Expected Calibration Error (ECE) and Adaptive ECE while maintaining Top-1 accuracy. Code: github.com/nadarasarbahavan/FEDLAS
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes FedLAS, a plug-and-play label-smoothing algorithm for DNN calibration. It introduces a Feature Norm-based Confidence Indicator (NCI) to detect per-sample over- or under-confidence states during training and a Bidirectional Calibration Gating (BCG) module to apply tailored bidirectional smoothing, extending beyond uniform LS/MbLS. The central claim is that this sample-adaptive mechanism yields consistent reductions in ECE and Adaptive ECE on standard and fine-grained vision benchmarks while preserving Top-1 accuracy.
Significance. If the NCI reliably correlates with per-sample calibration error and the BCG applies effective bidirectional adjustments, the method would provide a more nuanced, state-aware alternative to fixed smoothing rules. This could matter for calibration-sensitive tasks, though the current description offers no parameter-free derivations, machine-checked proofs, or reproducible code artifacts beyond a GitHub link.
major comments (2)
- [Method (NCI and BCG)] The load-bearing assumption that the NCI 'accurately identifies the specific confidence state of each sample at each training step' (abstract) is not supported by any per-sample correlation analysis, ablation isolating NCI accuracy, or failure-case examination. Without such evidence, it is unclear whether the claimed ECE gains exceed those achievable by standard LS/MbLS.
- [Experiments] The abstract states 'extensive experiments ... show that FedLAS consistently improves calibration' but supplies no experimental setup details, statistical significance tests, ablation results, or per-benchmark breakdowns. This prevents verification that the improvements are attributable to the proposed modules rather than implementation choices.
minor comments (2)
- The abstract mentions integration with 'LS and MbLS based losses' but does not clarify the exact loss formulations or how FedLAS modifies the smoothing parameter in each case.
- Notation for NCI (feature norm) and BCG gating thresholds is introduced without explicit equations or pseudocode in the provided abstract.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on FedLAS. We address each major comment below, indicating where revisions will be made to strengthen the manuscript.
read point-by-point responses
-
Referee: [Method (NCI and BCG)] The load-bearing assumption that the NCI 'accurately identifies the specific confidence state of each sample at each training step' (abstract) is not supported by any per-sample correlation analysis, ablation isolating NCI accuracy, or failure-case examination. Without such evidence, it is unclear whether the claimed ECE gains exceed those achievable by standard LS/MbLS.
Authors: We acknowledge that the current manuscript does not provide explicit per-sample correlation analysis between NCI values and confidence states, nor dedicated ablations isolating NCI accuracy or failure-case studies. The NCI is derived from the empirical observation that feature norms increase with model confidence during training, and the overall ECE improvements in experiments are consistent with this. However, to directly address the concern, we will add in the revision: (i) scatter plots and Pearson correlation coefficients between NCI and per-sample ECE across training epochs on multiple datasets, (ii) an ablation comparing FedLAS with and without the NCI component (replacing it with a constant or random indicator), and (iii) qualitative examination of samples where NCI may misclassify the state. These additions will help isolate whether the bidirectional adjustments yield gains beyond uniform LS/MbLS. revision: yes
-
Referee: [Experiments] The abstract states 'extensive experiments ... show that FedLAS consistently improves calibration' but supplies no experimental setup details, statistical significance tests, ablation results, or per-benchmark breakdowns. This prevents verification that the improvements are attributable to the proposed modules rather than implementation choices.
Authors: The full manuscript contains an Experiments section (Section 4) detailing datasets (CIFAR-10/100, ImageNet, fine-grained benchmarks), training protocols, baselines (including LS and MbLS variants), and evaluation metrics (ECE, AdaECE, Top-1 accuracy). Ablation studies isolating NCI and BCG are included in Section 5, with per-benchmark tables reporting results. That said, the referee is correct that statistical significance tests (e.g., across random seeds) are not reported. In revision we will add: (i) explicit hyperparameter tables and code snippets for reproducibility, (ii) mean and standard deviation over 3-5 runs with paired t-tests or Wilcoxon tests for ECE differences, and (iii) expanded per-benchmark breakdowns with confidence intervals. These changes will make attribution to the modules clearer. revision: partial
Circularity Check
No circularity: empirical algorithm with no derivations or self-referential reductions
full rationale
The paper presents FedLAS as a plug-and-play algorithmic extension to label smoothing, introducing NCI (feature-norm based indicator) and BCG (bidirectional gating) modules. No equations, derivations, or fitted-parameter predictions appear in the provided text. The central claims rest on experimental results on vision benchmarks rather than any chain that reduces by construction to inputs. No self-citation load-bearing steps, uniqueness theorems, or ansatz smuggling are referenced. This matches the default expectation of a non-circular empirical contribution.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Feature norm of internal activations correlates with model confidence state during training
- domain assumption Detecting and correcting both over- and under-confidence via gating improves calibration beyond unidirectional smoothing
invented entities (2)
-
Feature Norm-based Confidence Indicator (NCI)
no independent evidence
-
Bidirectional Calibration Gating (BCG)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) Findings
Bahavan, T.T.N., Seneviratne, S., Halgamuge, S.: Sphor: A representation learning perspective on open-set recognition for identifying unknown classes in deep neural networks. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) Findings. pp. 6901–6910 (June 2026)
2026
-
[2]
Estimating or Propagating Gradients Through Stochastic Neurons for Conditional Computation
Bengio, Y., Léonard, N., Courville, A.C.: Estimating or propagating gradients through stochastic neurons for conditional computation. ArXivabs/1308.3432 (2013),https://api.semanticscholar.org/CorpusID:18406556
work page internal anchor Pith review Pith/arXiv arXiv 2013
-
[3]
In: Proceedings of the 32nd International Conference on Machine Learning (ICML)
Blundell, C., Cornebise, J., Kavukcuoglu, K., Wierstra, D.: Weight uncertainty in neural networks. In: Proceedings of the 32nd International Conference on Machine Learning (ICML). p. 1613–1622. ICML’15, JMLR.org (2015)
2015
-
[4]
Cheng, J., Vasconcelos, N.: Calibrating deep neural networks by pairwise con- straints. In: 2022 IEEE/CVF Conference on Computer Vision and Pattern Recog- nition (CVPR). pp. 13699–13708 (2022).https://doi.org/10.1109/CVPR52688. 2022.01334
-
[5]
De Bernardi, G., Narteni, S., Cambiaso, E., Mongelli, M.: Rule-based out-of- distributiondetection.IEEETransactionsonArtificialIntelligence5(6),2627–2637 (2024).https://doi.org/10.1109/TAI.2023.3323923
-
[6]
In: 2009 IEEE Conference on Computer Vision and Pattern Recognition
Deng, J., Dong, W., Socher, R., Li, L.J., Li, K., Fei-Fei, L.: ImageNet: A large- scale hierarchical image database. In: 2009 IEEE Conference on Computer Vision and Pattern Recognition. pp. 248–255. IEEE (2009).https://doi.org/10.1109/ CVPR.2009.5206848
-
[7]
In: International Conference on Learning Representations (2021)
Dosovitskiy, A., Beyer, L., Kolesnikov, A., Weissenborn, D., Zhai, X., Unterthiner, T., Dehghani, M., Minderer, M., Heigold, G., Gelly, S., Uszkoreit, J., Houlsby, N.: An image is worth 16x16 words: Transformers for image recognition at scale. In: International Conference on Learning Representations (2021)
2021
-
[8]
In: Proceedings of the 33rd International Confer- ence on International Conference on Machine Learning - Volume 48
Gal,Y.,Ghahramani,Z.:Dropoutasabayesianapproximation:representingmodel uncertainty in deep learning. In: Proceedings of the 33rd International Confer- ence on International Conference on Machine Learning - Volume 48. p. 1050–1059. ICML’16, JMLR.org (2016)
2016
-
[9]
In: Proceedings of the 36th International Conference on Neural Information Processing Systems
Ghosh, A., Schaaf, T., Gormley, M.: Adafocal: calibration-aware adaptive focal loss. In: Proceedings of the 36th International Conference on Neural Information Processing Systems. NIPS ’22, Curran Associates Inc., Red Hook, NY, USA (2022)
2022
-
[10]
In: Proceedings of the 34th International Conference on Machine Learning - Volume 70
Guo, C., Pleiss, G., Sun, Y., Weinberger, K.Q.: On calibration of modern neu- ral networks. In: Proceedings of the 34th International Conference on Machine Learning - Volume 70. p. 1321–1330. ICML’17, JMLR.org (2017) 16 Bahavan et al
2017
-
[11]
He, K., Zhang, X., Ren, S., Sun, J.: Deep residual learning for image recognition. In: 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). pp. 770–778 (2016).https://doi.org/10.1109/CVPR.2016.90
-
[12]
In: Proceed- ings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Hebbalaguppe, R., Prakash, J., Madan, N., Arora, C.: A stitch in time saves nine: A train-time regularizing loss for improved neural network calibration. In: Proceed- ings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 16081–16090 (June 2022)
2022
-
[13]
In: International Confer- ence on Machine Learning (2018),https://api.semanticscholar.org/CorpusID: 51880858
Hébert-Johnson, Ú., Kim, M.P., Reingold, O., Rothblum, G.N.: Multicalibration: Calibration for the (computationally-identifiable) masses. In: International Confer- ence on Machine Learning (2018),https://api.semanticscholar.org/CorpusID: 51880858
2018
-
[14]
In: Proceedings of the 32nd International Conference on International Conference on Machine Learning - Volume 37
Hernández-Lobato, J.M., Adams, R.P.: Probabilistic backpropagation for scalable learning of bayesian neural networks. In: Proceedings of the 32nd International Conference on International Conference on Machine Learning - Volume 37. p. 1861–1869. ICML’15, JMLR.org (2015)
2015
-
[15]
In: Proceedings of the 41st International Conference on Machine Learning
Jordahn, M., Olmos, P.M.: Decoupling feature extraction and classification layers for calibrated neural networks. In: Proceedings of the 41st International Conference on Machine Learning. ICML’24, JMLR.org (2024)
2024
-
[16]
Kim,M.,Jain,A.K.,Liu,X.:Adaface:Qualityadaptivemarginforfacerecognition. In: 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 18729–18738 (2022).https://doi.org/10.1109/CVPR52688.2022. 01819
-
[17]
Krizhevsky, A., Hinton, G.: Learning multiple layers of features from tiny images. Tech. rep., University of Toronto (2009),https://www.cs.toronto.edu/~kriz/ learning-features-2009-TR.pdf
2009
-
[18]
In: Dy, J.G., Krause, A
Kumar, A., Sarawagi, S., Jain, U.: Trainable calibration measures for neural net- works from kernel mean embeddings. In: Dy, J.G., Krause, A. (eds.) ICML. Pro- ceedings of Machine Learning Research, vol. 80, pp. 2810–2819. PMLR (2018), http://dblp.uni-trier.de/db/conf/icml/icml2018.html#KumarSJ18
2018
-
[19]
Lakshminarayanan, B., Pritzel, A., Blundell, C.: Simple and scalable predictive un- certaintyestimationusingdeepensembles.In:Proceedingsofthe31stInternational Conference on Neural Information Processing Systems. p. 6405–6416. NIPS’17, Curran Associates Inc., Red Hook, NY, USA (2017)
2017
-
[20]
Larrazabal, A.J., Martínez, C., Dolz, J., Ferrante, E.: Orthogonal ensemble net- works for biomedical image segmentation. In: Medical Image Computing and Com- puter Assisted Intervention – MICCAI 2021: 24th International Conference, Stras- bourg, France, September 27–October 1, 2021, Proceedings, Part III. p. 594–603. Springer-Verlag, Berlin, Heidelberg (...
-
[21]
Lin, T.Y., Goyal, P., Girshick, R., He, K., Dollár, P.: Focal loss for dense object detection. IEEE Transactions on Pattern Analysis and Machine Intelligence42(2), 318–327 (2020).https://doi.org/10.1109/TPAMI.2018.2858826
-
[22]
Liu, B., Ayed, I.B., Galdran, A., Dolz, J.: The Devil is in the Margin: Margin- based Label Smoothing for Network Calibration . In: 2022 IEEE/CVF Confer- ence on Computer Vision and Pattern Recognition (CVPR). pp. 80–88. IEEE Computer Society, Los Alamitos, CA, USA (Jun 2022).https : / / doi . org / 10.1109/CVPR52688.2022.00018,https://doi.ieeecomputersoc...
-
[23]
In: Proceedings of the 33rd International Conference on Machine Learning (ICML)
Louizos, C., Welling, M.: Structured and efficient variational deep learning with matrix gaussian posteriors. In: Proceedings of the 33rd International Conference on Machine Learning (ICML). p. 1708–1716. JMLR.org (2016) FeDLaS 17
2016
-
[24]
Fine-Grained Visual Classification of Aircraft
Maji, S., Rahtu, E., Kannala, J., Blaschko, M., Vedaldi, A.: Fine-grained visual classification of aircraft. arXiv preprint arXiv:1306.5151 (2013),https://arxiv. org/abs/1306.5151
work page internal anchor Pith review Pith/arXiv arXiv 2013
-
[25]
In: Proceedings of the 40th International Conference on Machine Learning
Mao, A., Mohri, M., Zhong, Y.: Cross-entropy loss functions: theoretical analysis and applications. In: Proceedings of the 40th International Conference on Machine Learning. ICML’23, JMLR.org (2023)
2023
-
[26]
In: Proceedings of the 37th International Conference on Machine Learning
Moon, J., Kim, J., Shin, Y., Hwang, S.: Confidence-aware learning for deep neu- ral networks. In: Proceedings of the 37th International Conference on Machine Learning. ICML’20, JMLR.org (2020)
2020
-
[27]
In: Proceedings of the 34th International Conference on Neural Information Processing Systems
Mukhoti, J., Kulharia, V., Sanyal, A., Golodetz, S., Torr, P.H.S., Dokania, P.K.: Calibrating deep neural networks using focal loss. In: Proceedings of the 34th International Conference on Neural Information Processing Systems. NIPS ’20, Curran Associates Inc., Red Hook, NY, USA (2020)
2020
-
[28]
Curran Associates Inc., Red Hook, NY, USA (2019)
Müller, R., Kornblith, S., Hinton, G.: When does label smoothing help? In: Pro- ceedings of the 33rd International Conference on Neural Information Processing Systems. Curran Associates Inc., Red Hook, NY, USA (2019)
2019
-
[29]
In: Proceedings of the Twenty-Ninth AAAI Conference on Artificial Intelligence
Naeini,M.P.,Cooper,G.F.,Hauskrecht,M.:Obtainingwellcalibratedprobabilities using bayesian binning. In: Proceedings of the Twenty-Ninth AAAI Conference on Artificial Intelligence. p. 2901–2907. AAAI’15, AAAI Press (2015)
2015
-
[30]
Nixon, J., Dusenberry, M.W., Zhang, L., Jerfel, G., Tran, D.: Measuring calibration indeeplearning.In:ProceedingsoftheIEEE/CVFConferenceonComputerVision and Pattern Recognition (CVPR) Workshops (June 2019)
2019
-
[31]
In: 2023 IEEE/CVF International Conference on Computer Vision (ICCV)
Noh, J., Park, H., Lee, J., Ham, B.: Rankmixup: Ranking-based mixup training for network calibration. In: 2023 IEEE/CVF International Conference on Computer Vision (ICCV). pp. 1358–1368 (2023).https://doi.org/10.1109/ICCV51070. 2023.00131
-
[32]
In: Neural Information Processing Systems (2019),https://api.semanticscholar.org/CorpusID:174803437
Ovadia, Y., Fertig, E., Ren, J.J., Nado, Z., Sculley, D., Nowozin, S., Dillon, J.V., Lakshminarayanan, B., Snoek, J.: Can you trust your model’s uncertainty? evalu- ating predictive uncertainty under dataset shift. In: Neural Information Processing Systems (2019),https://api.semanticscholar.org/CorpusID:174803437
2019
-
[33]
Scalable diffusion models with transformers
Park, H., Noh, J., Oh, Y., Baek, D., Ham, B.: Acls: Adaptive and conditional label smoothing for network calibration. In: 2023 IEEE/CVF International Conference on Computer Vision (ICCV). pp. 3913–3922 (2023).https://doi.org/10.1109/ ICCV51070.2023.00364
-
[34]
In: Proceedings - 2023 IEEE/CVF International Conference on Computer Vision, ICCV 2023
Park, J., Chai, J.C.L., Yoon, J., Teoh, A.B.J.: Understanding the Feature Norm for Out-of-Distribution Detection. In: Proceedings - 2023 IEEE/CVF International Conference on Computer Vision, ICCV 2023. pp. 1557–1567. Institute of Electrical and Electronics Engineers Inc. (2023)
2023
-
[35]
Regularizing Neural Networks by Penalizing Confident Output Distributions
Pereyra, G., Tucker, G., Chorowski, J., Kaiser, L., Hinton, G.E.: Regularizing neu- ral networks by penalizing confident output distributions. ArXivabs/1701.06548 (2017),https://api.semanticscholar.org/CorpusID:9545399
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[36]
In: Advances in Large Margin Classifiers
Platt, J.: Probabilistic outputs for support vector machines and comparisons to regularized likelihood methods. In: Advances in Large Margin Classifiers. pp. 61–
-
[37]
Scott, T.R., Gallagher, A.C., Mozer, M.C.: von Mises–Fisher Loss: An Explo- ration of Embedding Geometries for Supervised Learning . In: 2021 IEEE/CVF International Conference on Computer Vision (ICCV). pp. 10592–10602. IEEE Computer Society, Los Alamitos, CA, USA (Oct 2021).https : / / doi . org / 10.1109/ICCV48922.2021.01044,https://doi.ieeecomputersoci...
-
[38]
In: Proceedings of the 40th International Conference on Machine Learning
Tao, L., Dong, M., Xu, C.: Dual focal loss for calibration. In: Proceedings of the 40th International Conference on Machine Learning. ICML’23, JMLR.org (2023)
2023
-
[39]
In: Pro- ceedings of the AAAI Conference on Artificial Intelligence
Tao, L., Dong, M., Xu, C.: Feature clipping for uncertainty calibration. In: Pro- ceedings of the AAAI Conference on Artificial Intelligence. vol. 39, pp. 20841– 20849. AAAI Press (2025).https://doi.org/10.1609/aaai.v39i19.34297, https://ojs.aaai.org/index.php/AAAI/article/view/34297
-
[40]
Tomani, C., Gruber, S., Erdem, M.E., Cremers, D., Buettner, F.: Post-hoc un- certainty calibration for domain drift scenarios. In: 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 10119–10127 (2021). https://doi.org/10.1109/CVPR46437.2021.00999
-
[41]
Vaze, S., Han, K., Vedaldi, A., Zisserman, A.: Open-set recognition: a good closed- set classifier is all you need? In: International Conference on Learning Representa- tions (2022)
2022
-
[42]
Technical Report CNS-TR-2011-001, California Institute of Technology (2011)
Wah, C., Branson, S., Welinder, P., Perona, P., Belongie, S.: The caltech-ucsd birds-200-2011 dataset. Technical Report CNS-TR-2011-001, California Institute of Technology (2011)
2011
-
[43]
In: Proceedings of the 34th International Conference on Neural Information Processing Systems
Wenzel, F., Snoek, J., Tran, D., Jenatton, R.: Hyperparameter ensembles for ro- bustness and uncertainty quantification. In: Proceedings of the 34th International Conference on Neural Information Processing Systems. NIPS ’20, Curran Asso- ciates Inc., Red Hook, NY, USA (2020)
2020
-
[44]
In: Proceedings of the 37th International Conference on Neural Information Processing Systems
Yang, J.Q., Zhan, D.C., Gan, L.: Beyond probability partitions: calibrating neural networks with semantic aware grouping. In: Proceedings of the 37th International Conference on Neural Information Processing Systems. NIPS ’23, Curran Asso- ciates Inc., Red Hook, NY, USA (2023)
2023
-
[45]
In: Proceedings of the 37th International Conference on Machine Learning
Zhang, J., Kailkhura, B., Han, T.Y.J.: Mix-n-match: ensemble and compositional methods for uncertainty calibration in deep learning. In: Proceedings of the 37th International Conference on Machine Learning. ICML’20, JMLR.org (2020)
2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.