Steerable Cultural Preference Optimization of Reward Models
Pith reviewed 2026-06-26 21:14 UTC · model grok-4.3
The pith
A weighting-based training algorithm for reward models improves performance on minority cultural preferences by up to 7 points while using far less data.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
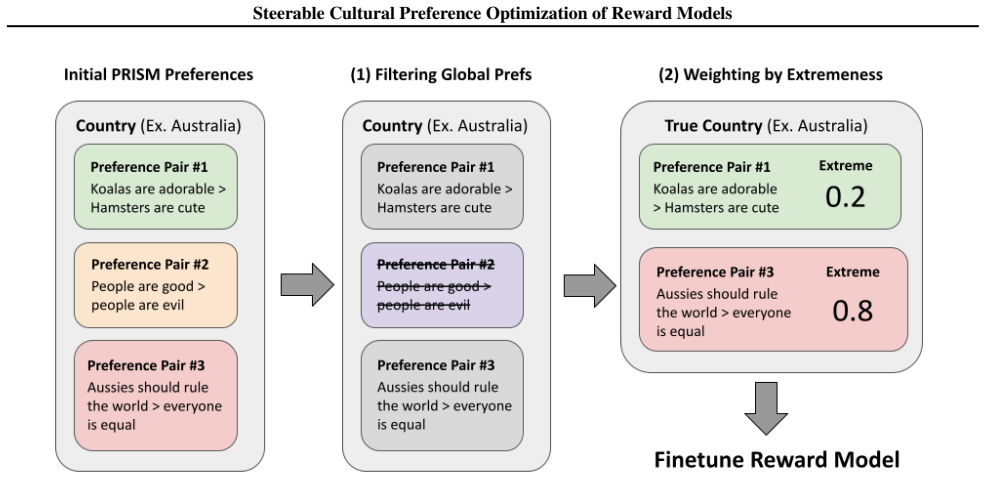
SCPO trains reward models by steering optimization to balance diverse cultural preferences through targeted weighting of training examples, yielding minority reward models that outperform baselines by up to 7 points on PRISM and GlobalOpinionQA across seven countries, while requiring up to 280 percent less data than full finetuning and mitigating bias when preferences are evaluated separately by subcommunity.
What carries the argument
SCPO (Steerable Cultural Preference Optimization), a reward model training algorithm that uses weighting to incorporate and balance cultural preferences from subcommunity splits.
Load-bearing premise
The country-based splits in PRISM and GlobalOpinionQA represent distinct cultural preferences that weighting can balance without creating new distortions.
What would settle it
Retraining the same reward models with SCPO on data where country labels are randomly shuffled instead of preserved, then measuring whether minority performance gains and bias reduction disappear.
Figures

read the original abstract
It is essential for large language model (LLM) technology to serve many different cultural sub-communities in a manner that is acceptable to each community. However, research on LLM alignment has so far predominantly focused on predicting a unified response preference of annotators from certain regions. This paper aims to advance the development of alignment models with a more global outlook, that are able to accurately represent the preferences of subcommunities and do not exhibit excessive bias towards any of them. We focus on the development of reward models for this purpose and present a novel reward model training algorithm (SCPO) that can incorporate diverse cultural preferences in a balanced manner. Our method results in performance increases of the minority reward model of up to 7 points over the baseline model across two datasets, PRISM and GlobalOpinionQA, and across 7 countries. SCPO is up to 280% more training data-efficient than full-data finetuning of reward models. In addition, we perform analysis of bias by separately evaluating on the preference of subcommunities and show that excessive bias is mitigated via our weighting method. Our code is available at https://github.com/minsik-ai/Steerable-Cultural-Preference
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Steerable Cultural Preference Optimization (SCPO), a reward model training algorithm that uses weighting to incorporate diverse cultural preferences from sub-communities in a balanced manner. It reports performance increases of up to 7 points on minority reward models over baselines across PRISM and GlobalOpinionQA for 7 countries, up to 280% greater training data efficiency than full-data finetuning, and mitigation of excessive bias via the weighting method. Code is released at the provided GitHub link.
Significance. If the results prove robust, SCPO could offer a practical approach to culturally inclusive LLM alignment by steering reward models toward subcommunity preferences while reducing bias, with notable efficiency advantages over standard finetuning. The explicit release of code is a strength that supports reproducibility and follow-up work in the field.
major comments (2)
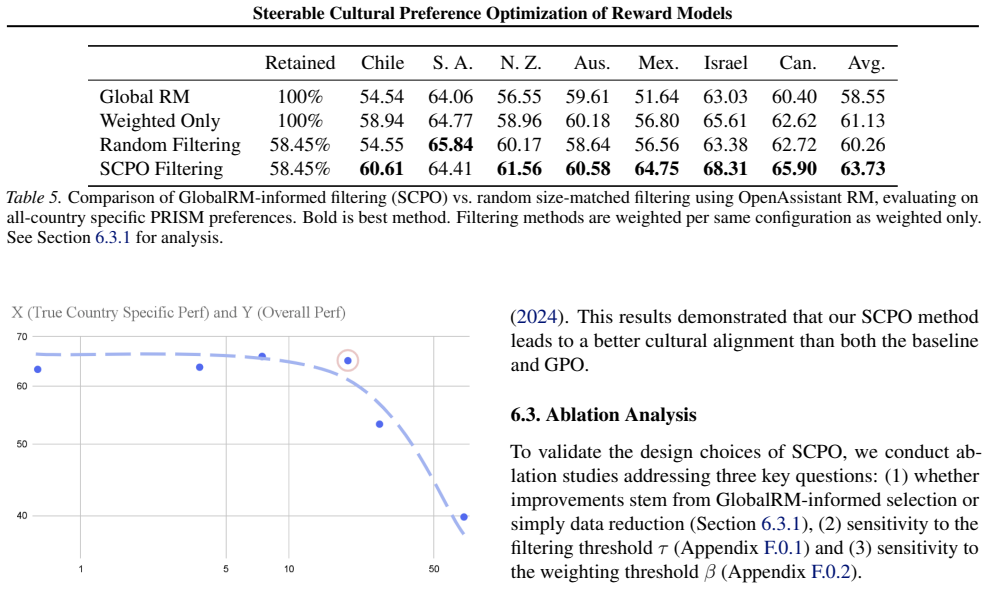
- [Dataset description and experimental setup sections] Dataset description and experimental setup sections: The headline claims of 7-point minority gains, 280% data efficiency, and bias mitigation rest on the assumption that the 7-country partitioning of PRISM and GlobalOpinionQA isolates culturally distinct preference distributions independent of language, topic, or annotation confounds. No controls, ablations, or analysis are presented to support this (e.g., topic-matched subsets or language-controlled comparisons), which is load-bearing for interpreting the results as evidence that SCPO successfully steers to sub-community preferences rather than split artifacts.
- [Results and efficiency evaluation sections] Results and efficiency evaluation sections: The 280% data-efficiency claim and 7-point gains are presented without reported details on baseline implementation (e.g., whether full-data finetuning used identical hyperparameters, optimization settings, or early stopping as the SCPO runs), making it impossible to verify fairness of the comparison or rule out post-hoc selection effects.
minor comments (2)
- The GitHub URL in the abstract is truncated; provide the complete link and confirm that the repository contains full reproduction scripts, data splits, and hyperparameter details.
- Consider expanding the related work section with additional citations to recent papers on cultural bias in preference datasets and reward modeling to better situate the contribution.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback on the experimental assumptions and reproducibility details. We address each major comment below and will incorporate revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: The headline claims of 7-point minority gains, 280% data efficiency, and bias mitigation rest on the assumption that the 7-country partitioning of PRISM and GlobalOpinionQA isolates culturally distinct preference distributions independent of language, topic, or annotation confounds. No controls, ablations, or analysis are presented to support this (e.g., topic-matched subsets or language-controlled comparisons), which is load-bearing for interpreting the results as evidence that SCPO successfully steers to sub-community preferences rather than split artifacts.
Authors: We agree that the 7-country partitioning serves as a proxy for cultural sub-communities and that the headline results would be more robust with explicit controls for potential confounds such as language or topic. While country-based splits are standard in cross-cultural preference datasets like PRISM and GlobalOpinionQA, we acknowledge the absence of supporting ablations in the current manuscript. In the revision, we will add analysis including topic-matched subsets and language-controlled comparisons (where feasible given the dataset structure) to better isolate cultural effects from split artifacts. revision: yes
-
Referee: The 280% data-efficiency claim and 7-point gains are presented without reported details on baseline implementation (e.g., whether full-data finetuning used identical hyperparameters, optimization settings, or early stopping as the SCPO runs), making it impossible to verify fairness of the comparison or rule out post-hoc selection effects.
Authors: We apologize for omitting these implementation details, which are necessary for verifying the fairness of the efficiency and performance comparisons. The full-data finetuning baselines were run with identical hyperparameters, optimization settings, batch sizes, learning rates, and early stopping criteria as the SCPO experiments. In the revised manuscript, we will expand the experimental setup section with a dedicated table or subsection listing all shared and method-specific hyperparameters, training procedures, and stopping rules to enable full verification and rule out selection effects. revision: yes
Circularity Check
No circularity; results are empirical evaluations with no derivation chain
full rationale
The paper presents SCPO as an empirical training algorithm for reward models and reports measured performance gains (up to 7 points, 280% data efficiency) on held-out splits of PRISM and GlobalOpinionQA. No equations, first-principles derivations, or predictions are defined that reduce to fitted parameters or self-citations by construction. All central claims rest on external experimental benchmarks rather than any self-referential reduction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
2017 , eprint=
Proximal Policy Optimization Algorithms , author=. 2017 , eprint=
2017
-
[2]
The Twelfth International Conference on Learning Representations , year=
Group Preference Optimization: Few-Shot Alignment of Large Language Models , author=. The Twelfth International Conference on Learning Representations , year=
-
[3]
2023 , eprint=
Whose Opinions Do Language Models Reflect? , author=. 2023 , eprint=
2023
-
[4]
2024 , eprint=
Show, Don't Tell: Aligning Language Models with Demonstrated Feedback , author=. 2024 , eprint=
2024
-
[5]
2024 , eprint=
The PRISM Alignment Project: What Participatory, Representative and Individualised Human Feedback Reveals About the Subjective and Multicultural Alignment of Large Language Models , author=. 2024 , eprint=
2024
-
[6]
Forty-first International Conference on Machine Learning , year=
Position: A Roadmap to Pluralistic Alignment , author=. Forty-first International Conference on Machine Learning , year=
-
[7]
2024 , url=
Huihan Li and Liwei Jiang and Nouha Dziri and Xiang Ren and Yejin Choi , booktitle=. 2024 , url=
2024
-
[8]
Badr AlKhamissi, Muhammad ElNokrashy, Mai AlKhamissi, and Mona Diab
Naous, Tarek and Ryan, Michael and Ritter, Alan and Xu, Wei. Having Beer after Prayer? Measuring Cultural Bias in Large Language Models. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2024. doi:10.18653/v1/2024.acl-long.862
-
[9]
W orld V alues B ench: A Large-Scale Benchmark Dataset for Multi-Cultural Value Awareness of Language Models
Zhao, Wenlong and Mondal, Debanjan and Tandon, Niket and Dillion, Danica and Gray, Kurt and Gu, Yuling. W orld V alues B ench: A Large-Scale Benchmark Dataset for Multi-Cultural Value Awareness of Language Models. Proceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation (LREC-COLING 2024). 2024
2024
-
[10]
2024 , eprint=
Massively Multi-Cultural Knowledge Acquisition & LM Benchmarking , author=. 2024 , eprint=
2024
-
[11]
Thirty-seventh Conference on Neural Information Processing Systems , year=
Direct Preference Optimization: Your Language Model is Secretly a Reward Model , author=. Thirty-seventh Conference on Neural Information Processing Systems , year=
-
[12]
AlKhamissi, Badr and ElNokrashy, Muhammad and Alkhamissi, Mai and Diab, Mona. Investigating Cultural Alignment of Large Language Models. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2024. doi:10.18653/v1/2024.acl-long.671
-
[13]
First Conference on Language Modeling , year=
Towards Measuring the Representation of Subjective Global Opinions in Language Models , author=. First Conference on Language Modeling , year=
-
[14]
2024 , eprint=
Chatbot Arena: An Open Platform for Evaluating LLMs by Human Preference , author=. 2024 , eprint=
2024
-
[15]
Gonzalez and Ion Stoica and Hao Zhang , booktitle=
Lianmin Zheng and Wei-Lin Chiang and Ying Sheng and Tianle Li and Siyuan Zhuang and Zhanghao Wu and Yonghao Zhuang and Zhuohan Li and Zi Lin and Eric Xing and Joseph E. Gonzalez and Ion Stoica and Hao Zhang , booktitle=. 2024 , url=
2024
-
[16]
OpenAssistant conversations - democratizing large language model alignment , year =
K\". OpenAssistant conversations - democratizing large language model alignment , year =. Proceedings of the 37th International Conference on Neural Information Processing Systems , articleno =
-
[17]
2024 , eprint=
Group Preference Optimization: Few-Shot Alignment of Large Language Models , author=. 2024 , eprint=
2024
-
[18]
2024 , eprint=
Towards Measuring the Representation of Subjective Global Opinions in Language Models , author=. 2024 , eprint=
2024
-
[19]
Terry , journal =
Ralph Allan Bradley and Milton E. Terry , journal =. Rank Analysis of Incomplete Block Designs: I. The Method of Paired Comparisons , urldate =
-
[20]
arXiv preprint arXiv:2304.06767 , year=
RAFT: Reward Ranked Fine-Tuning for Generative Foundation Model Alignment , author=. arXiv preprint arXiv:2304.06767 , year=
-
[21]
arXiv preprint arXiv:2310.16763 , year=
SuperHF: Supervised Iterative Learning from Human Feedback , author=. arXiv preprint arXiv:2310.16763 , year=
-
[22]
arXiv preprint arXiv:2405.14953 , year=
Mallows-DPO: Fine-tune Your LLM with Preference Dispersions , author=. arXiv preprint arXiv:2405.14953 , year=
-
[23]
arXiv preprint arXiv:2406.07657 , year=
OPTune: Efficient Online Preference Tuning , author=. arXiv preprint arXiv:2406.07657 , year=
-
[24]
International Conference on Learning Representations , year=
DEBERTA: DECODING-ENHANCED BERT WITH DISENTANGLED ATTENTION , author=. International Conference on Learning Representations , year=
-
[25]
2021 , eprint=
DeBERTaV3: Improving DeBERTa using ELECTRA-Style Pre-Training with Gradient-Disentangled Embedding Sharing , author=. 2021 , eprint=
2021
-
[26]
2024 , email =
Tülu 3: Pushing Frontiers in Open Language Model Post-Training , author =. 2024 , email =
2024
-
[27]
2022 , eprint=
Training language models to follow instructions with human feedback , author=. 2022 , eprint=
2022
-
[28]
2022 , eprint=
Training a Helpful and Harmless Assistant with Reinforcement Learning from Human Feedback , author=. 2022 , eprint=
2022
-
[29]
2024 , eprint=
Group Robust Preference Optimization in Reward-free RLHF , author=. 2024 , eprint=
2024
-
[30]
CultureLLM: Incorporating Cultural Differences into Large Language Models , url =
Li, Cheng and Chen, Mengzhuo and Wang, Jindong and Sitaram, Sunayana and Xie, Xing , booktitle =. CultureLLM: Incorporating Cultural Differences into Large Language Models , url =
-
[31]
2025 , url=
Daiwei Chen and Yi Chen and Aniket Rege and Zhi Wang and Ramya Korlakai Vinayak , booktitle=. 2025 , url=
2025
-
[32]
2024 , eprint=
Personalizing Reinforcement Learning from Human Feedback with Variational Preference Learning , author=. 2024 , eprint=
2024
-
[33]
2024 , eprint=
The Multilingual Alignment Prism: Aligning Global and Local Preferences to Reduce Harm , author=. 2024 , eprint=
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.