Prior Knowledge or Search? A Study of LLM Agents in Hardware-Aware Code Optimization
Pith reviewed 2026-05-20 06:07 UTC · model grok-4.3
The pith
LLMs in hardware code optimization depend on pretrained priors rather than feedback or agentic structure.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
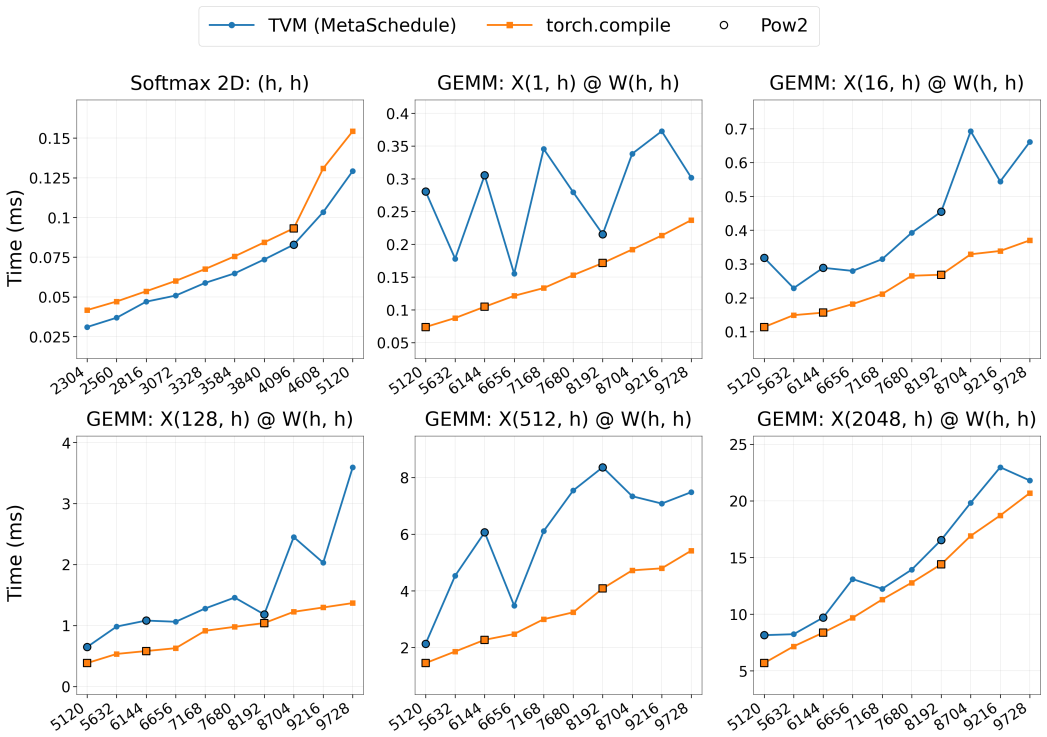
The authors establish that LLM agents in hardware-aware code optimization tasks highly depend on pretrained priors rather than provided feedback or agentic structure. This is shown by their greedy behavior in black-box optimization, their convergence to identical kernel parameters regardless of explicit size instructions or temperature, their sharp performance drop on uncommon sizes, and their monotonic improvement under feedback in high-density CUDA contrasted with active degradation in low-density TVM IR.
What carries the argument
The propose-evaluate-revise loop applied to kernel optimization, tested with and without feedback across CUDA and TVM IR representations and with varying size information.
If this is right
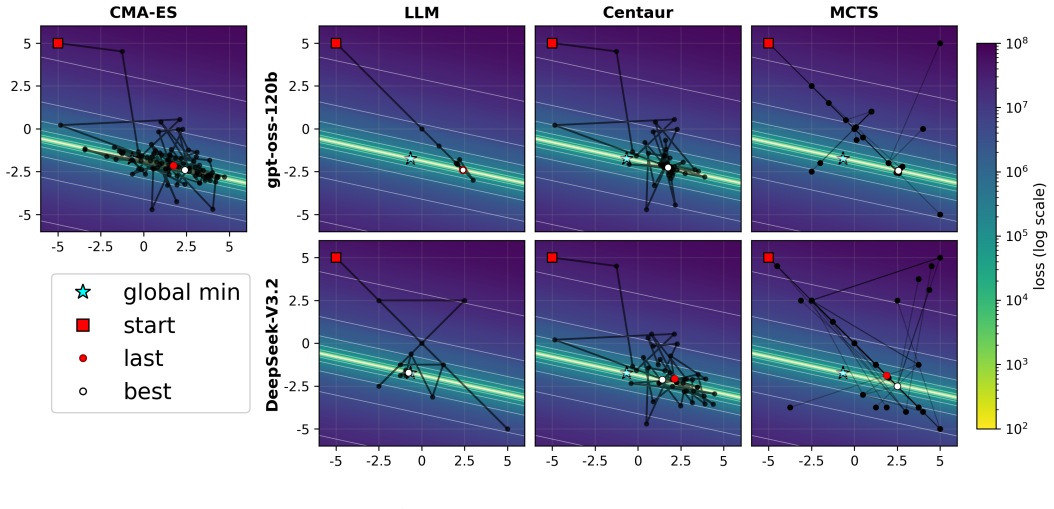
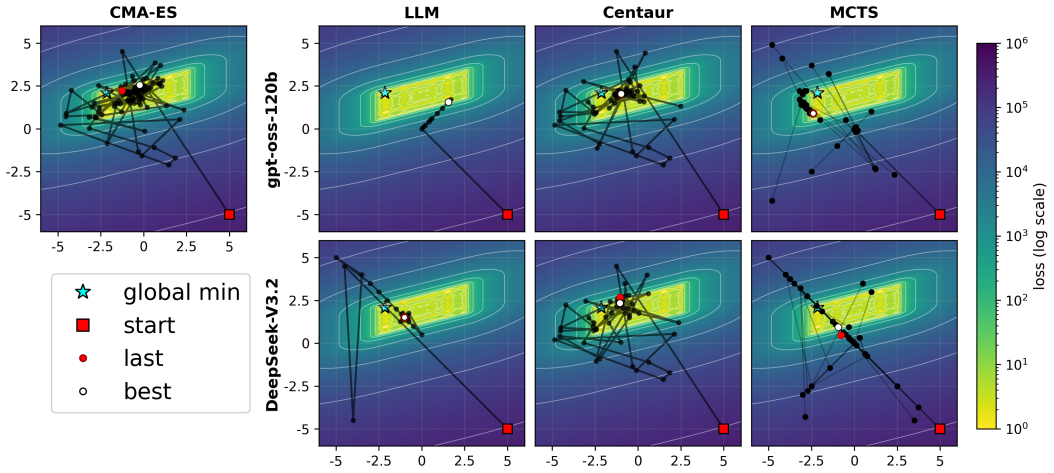
- In black-box optimization LLMs act as greedy optimizers rather than performing broad search.
- Models converge to the same kernel parameters regardless of input size or temperature setting.
- Kernel optimization performance degrades sharply for sizes uncommon in training data.
- Iterative feedback produces monotonic improvement in high-density languages like CUDA but degradation in low-density ones like TVM IR.
Where Pith is reading between the lines
- Improving results may require expanding training data to cover more kernel sizes and low-density representations instead of adding agent complexity.
- The same pattern of prior dominance could appear in other LLM-driven technical search tasks such as algorithm design.
- Hybrid systems that pair LLMs with conventional search or symbolic optimizers could reduce the degradation observed in unfamiliar languages.
Load-bearing premise
The performance differences between CUDA and TVM IR and the lack of effect from explicit size information result from reliance on pretrained priors rather than prompt design, model capability limits, or other experimental variables.
What would settle it
An experiment in which models generate distinct kernel parameters for different input sizes after size information is made more prominent in the prompt or after testing a model with no prior exposure to CUDA or TVM code would challenge the central claim.
Figures



























read the original abstract
LLM discovery and optimization systems are increasingly applied across domains, implementing a common propose-evaluate-revise loop. Such optimization or discovery progresses via context conditioning on received feedback from an environment. However, as modern LLM agents are increasingly complex in their structure, it is difficult to evaluate which components contribute the most, and when and how this exploration may fail. We answer these questions through three controlled experiments. Our findings: (1) In pure black-box optimization, LLMs act as greedy optimizers. (2) In zero-shot kernel generation, providing explicit input-size information has no measurable effect, models converge to the same kernel parameters regardless of size or temperature, as though the size instruction were invisible. Moreover, when tasked to perform kernel optimization for uncommon kernel sizes, performance sharply degrades regardless of the language used. (3) In feedback-loop kernel optimization, CUDA improves monotonically under iterative feedback, while TVM IR actively degrades, which demonstrates that kernel optimization degrades when models operate with low-density language. Our results conclude that LLMs in code optimization tasks highly depend on pretrained priors rather than provided feedback or agentic structure.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper reports three controlled experiments on LLM agents performing hardware-aware code optimization via propose-evaluate-revise loops. Experiment 1 examines black-box optimization behavior; Experiment 2 tests zero-shot kernel generation with and without explicit size information across common and uncommon sizes; Experiment 3 compares iterative feedback-driven optimization in CUDA versus low-density TVM IR. The central claim is that LLMs rely primarily on pretrained priors rather than feedback or agentic structure, evidenced by greedy optimization, size-insensitivity, convergence independent of temperature, and monotonic improvement in CUDA contrasted with degradation in TVM IR.
Significance. If the empirical patterns hold after addressing confounds, the work offers a useful diagnostic on the limits of current LLM agents in code optimization, showing that added agentic complexity and feedback may not overcome reliance on pretraining. This has direct implications for designing more effective LLM-based systems in hardware-aware tasks and for understanding when context conditioning succeeds or fails in low-density languages.
major comments (2)
- [abstract and §3] The interpretation in the abstract and §3 (zero-shot kernel generation) that size information has 'no measurable effect' and is 'invisible' attributes this to pretrained priors, yet the experiments do not include controls that isolate prompt-following ability (e.g., rephrased instructions, chain-of-thought variants, or comparison to non-code-pretrained models). This leaves open the possibility that the patterns arise from generic limitations in parsing numerical constraints rather than kernel-specific pretraining, directly affecting the load-bearing claim that performance differences demonstrate reliance on priors.
- [§4] In the feedback-loop experiment (§4), the monotonic improvement in CUDA versus active degradation in TVM IR is taken to show that optimization fails with low-density language due to prior dependence. However, without reported ablations on prompt density, instruction adherence, or model scale, the degradation could stem from coherence maintenance issues in IR tokens independent of pretraining; this alternative is not ruled out and weakens the causal link to the central conclusion.
minor comments (2)
- [Experiments 1-3] The manuscript does not report sample sizes, statistical tests, exact model versions, or full prompt templates; these details are needed to assess reproducibility and effect sizes.
- [Figures] Figure captions and axis labels should explicitly state the number of runs and any error bars to clarify the reported performance trends.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback on our manuscript. We address each major comment below with clarifications on our experimental design and interpretations, while indicating where we will make revisions to improve the presentation of our results.
read point-by-point responses
-
Referee: [abstract and §3] The interpretation in the abstract and §3 (zero-shot kernel generation) that size information has 'no measurable effect' and is 'invisible' attributes this to pretrained priors, yet the experiments do not include controls that isolate prompt-following ability (e.g., rephrased instructions, chain-of-thought variants, or comparison to non-code-pretrained models). This leaves open the possibility that the patterns arise from generic limitations in parsing numerical constraints rather than kernel-specific pretraining, directly affecting the load-bearing claim that performance differences demonstrate reliance on priors.
Authors: We appreciate the referee's point regarding potential confounds in attributing size-insensitivity solely to pretrained priors. Our experiments demonstrate that models converge to identical kernel parameters irrespective of provided size information and exhibit sharp degradation specifically on uncommon sizes, a pattern that would not be expected from a uniform parsing limitation. Nevertheless, we acknowledge that controls such as non-code-pretrained models or additional prompt variants were not performed. In the revised manuscript, we will update the abstract and §3 to explicitly discuss this alternative explanation and qualify our interpretation as supported by the uncommon-size degradation results rather than definitively proven by them. revision: partial
-
Referee: [§4] In the feedback-loop experiment (§4), the monotonic improvement in CUDA versus active degradation in TVM IR is taken to show that optimization fails with low-density language due to prior dependence. However, without reported ablations on prompt density, instruction adherence, or model scale, the degradation could stem from coherence maintenance issues in IR tokens independent of pretraining; this alternative is not ruled out and weakens the causal link to the central conclusion.
Authors: We agree that the absence of ablations on prompt density, instruction adherence, and model scale leaves room for alternative accounts such as general coherence challenges with IR token sequences. At the same time, the contrast between monotonic gains under feedback in CUDA and active performance degradation in TVM IR is difficult to explain solely by coherence issues, as both languages receive identical feedback structures. We will revise §4 to include an explicit discussion of these alternative explanations and to temper the causal claim accordingly while retaining the observed language-dependent divergence as supporting evidence for prior dependence. revision: partial
Circularity Check
No circularity: purely empirical study with direct experimental outcomes
full rationale
The paper reports three controlled experiments on LLM behavior in code optimization tasks, drawing conclusions from observed performance patterns such as size-insensitivity in zero-shot generation and differential improvement under feedback in CUDA versus TVM IR. No mathematical derivations, equations, fitted parameters presented as predictions, or self-citation chains are present in the provided text. The central claim that LLMs rely on pretrained priors is an interpretive summary of experimental results rather than a reduction of any result to its own inputs by construction. The study is self-contained against external benchmarks through direct measurement of agent outputs, with no load-bearing steps that qualify as circular under the defined patterns.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption LLM behavior in prompting and feedback loops is sufficiently stable across runs to support comparative conclusions.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Our results conclude that LLMs in code optimization tasks highly depend on pretrained priors rather than provided feedback or agentic structure.
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Zero-shot generation produces kernels with generic parameters regardless of stated tensor dimensions
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
CUDA agent: Large-scale agentic RL for high- performance CUDA kernel generation. Fabio Ferreira, Lucca Wobbe, Arjun Krishnakumar, Frank Hutter, and Arber Zela. 2026. Can llms beat classical hyperparameter optimization algorithms? A study on autoresearch. Steffen Finck, Nikolaus Hansen, Raymond Ros, and Anne Auger. 2009. Real-parameter black-box optimizati...
work page 2026
-
[9]
Make code agnostic to device number, allocate output on the same GPU as the input (e.g. using`input.options()`)
-
[10]
Start code with # Hypothesis: ... comment. {% if hardware_info %} **Target Hardware:** {{ hardware_info }}{% if compute_capability %} (Compute Capability: {{ compute_capability }}){% endif %} {% endif %} <reference> {{ reference_code }} </reference> Start the file with a single comment line:`# Hypothesis: <your plan>`- briefly describe which specific opti...
-
[11]
This is the entry point used to instantiate your kernel
**Class Definition:** You must define a class named exactly`ModelNew`. This is the entry point used to instantiate your kernel
-
[12]
**Inheritance:** The class must inherit from`torch.nn.Module`
-
[13]
**Initialization:**`__init__(self, ...)`must accept the arguments provided by the reference implementation's`get_init_inputs()`
-
[14]
**Forward Pass:**`forward(self, ...)`must accept the arguments provided by the reference implementation's`get_inputs()`. - *Example:* If the baseline`get_inputs()`returns`[x, y]`, your method signature must be`forward(self, x, y)`
-
[15]
**Output:** The return value of`forward`must have the exact same shape and data type as the reference output
-
[16]
Use torch.utils.cpp_extension.load_inline to compile C++/CUDA source strings
-
[17]
Do not write any code except described above
-
[18]
Make code agnostic to device number, allocate output on the same GPU as the input (e.g. using`input.options()`). {% if require_hypothesis %}9. Start code with # Hypothesis: ... comment.{% endif %} {% if hardware_info %} **Target Hardware:** {{ hardware_info }}{% if compute_capability %} (Compute Capability: {{ compute_capability }}){% endif %} {% endif %}...
work page 2048
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.