The Rise of AI-Native Software Engineering: Implications for Practice, Education, and the Future Workforce
Pith reviewed 2026-06-27 06:20 UTC · model grok-4.3
The pith
AI-native software engineering demands education that prioritizes judgment, verification, and orchestration over code production.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Generative AI, LLMs, and agentic AI constitute the most disruptive transformation in software engineering history. The synthesis of 48 publications yields a conceptual framework organized around intent, collaboration, and verification, a nine-dimension competency model that includes specification, critical evaluation, agent orchestration, and metacognition, a four-phase university curriculum roadmap with AI-resilient assessment, faculty and workforce strategies, and a list of eleven research gaps, while underscoring that educating for judgment, verification, and orchestration rather than code production alone is the central challenge of the AI-native era.
What carries the argument
The four-agent research workflow that discovers, analyzes, and synthesizes literature into nine themes across practice, education, and workforce, yielding a framework built on intent, collaboration, and verification.
If this is right
- Productivity effects from AI tools remain strongly context-dependent rather than uniform.
- A nine-dimension competency model becomes necessary, covering specification, critical evaluation, agent orchestration, and metacognition.
- Universities should follow a four-phase curriculum roadmap that incorporates AI-resilient assessment methods.
- Faculty development programs and workforce transformation strategies are required to support the shift.
- Eleven specific research gaps should receive priority attention in future work.
Where Pith is reading between the lines
- Companies may need to restructure teams so that human roles focus on directing AI agents and verifying outputs.
- The new emphasis on verification could affect how software quality standards and liability rules evolve.
- Pilot testing the four-phase curriculum roadmap in actual university programs would supply direct evidence on its practicality.
- Links to human-AI collaboration research outside software engineering may clarify additional requirements for effective oversight.
Load-bearing premise
The 48 selected publications form a representative and unbiased sample of the literature from 2016 to 2026.
What would settle it
A broad survey of practicing software engineers showing that hiring and promotion still center primarily on traditional coding ability even after widespread AI tool adoption would undermine the central claim.
Figures


read the original abstract
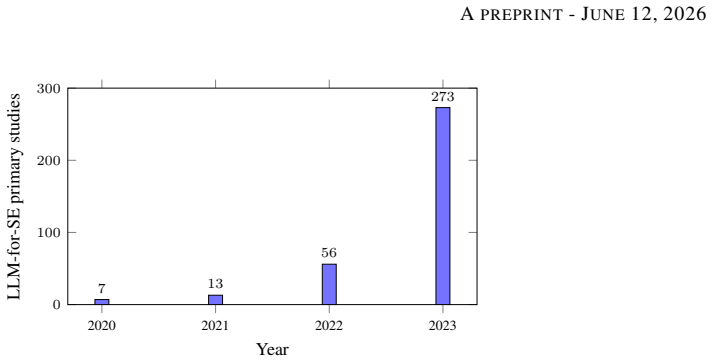
Generative Artificial Intelligence (GenAI), Large Language Models (LLMs), and emerging Agentic AI constitute the most disruptive transformation in the history of software engineering (SE), reshaping development processes, required competencies, professional roles, and the educational outcomes that universities must deliver. This paper presents a systematic review of 48 verified, influential peer-reviewed publications (2016--2026) drawn from leading venues in software engineering, machine learning, computing education, human--AI collaboration, and software productivity. Studies were discovered, screened, and analyzed through a four-agent research workflow (Literature Discovery, Scientometric Analysis, Curriculum Transformation, and Workforce Impact) and were verified against primary sources. We synthesize the evidence along nine themes and three trajectories -- practice, education, and workforce -- and report a scientometric inflection in which annual LLM-for-SE output grew roughly five-fold after late 2022. From this synthesis we contribute: (i) a conceptual framework for AI-native software engineering organized around \emph{intent}, \emph{collaboration}, and \emph{verification}; (ii) a nine-dimension competency model spanning specification, critical evaluation, agent orchestration, and metacognition; (iii) a four-phase university curriculum roadmap with AI-resilient assessment; (iv) faculty-development and workforce-transformation strategies; and (v) a prioritized agenda of eleven research gaps. The evidence base is internally contradictory on the magnitude and direction of productivity effects, underscoring that benefits are strongly context-dependent and that educating engineers for judgment, verification, and orchestration -- rather than code production alone -- is the central challenge of the AI-native era.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. This paper presents a systematic review of 48 verified peer-reviewed publications (2016–2026) on the effects of GenAI, LLMs, and Agentic AI on software engineering. Using a four-agent workflow (Literature Discovery, Scientometric Analysis, Curriculum Transformation, Workforce Impact), it extracts nine themes and three trajectories (practice, education, workforce), documents a roughly five-fold post-2022 increase in LLM-for-SE output, and contributes (i) a conceptual framework organized around intent, collaboration, and verification; (ii) a nine-dimension competency model; (iii) a four-phase university curriculum roadmap with AI-resilient assessment; (iv) faculty and workforce strategies; and (v) an eleven-item research agenda. The review explicitly notes internally contradictory evidence on productivity effects and concludes that educating engineers for judgment, verification, and orchestration—rather than code production—is the central challenge of the AI-native era.
Significance. If the synthesis is robust, the paper offers a timely, structured contribution to SE by integrating disparate literatures into a coherent framework and actionable curriculum recommendations. Explicitly flagging contradictory productivity findings and grounding the education emphasis in that context is a strength. The scientometric observation of the post-2022 inflection and the prioritized research gaps provide concrete value for the field. The work draws on external publications rather than self-referential modeling, which avoids circularity.
major comments (3)
- [Methods / four-agent workflow description] The paper selection criteria, screening process, and verification steps for the 48 publications are described only at a high level in the methods section. Without explicit inclusion/exclusion rules, venue coverage details, or inter-rater metrics, it is not possible to evaluate whether the sample is representative of 2016–2026 literature; this directly affects the load-bearing claim that the nine themes support elevating education for judgment/verification/orchestration as the central challenge.
- [Methods / Literature Discovery and Curriculum Transformation agents] The four-agent workflow is outlined conceptually but the specific prompts, decision rules, or coding scheme used to extract the nine themes and assign them to trajectories are not provided. Reproducibility of the synthesis that underpins the competency model and curriculum roadmap therefore cannot be assessed from the manuscript.
- [Discussion / Conclusion] The abstract states that productivity evidence is internally contradictory and context-dependent, yet the final weighting that positions education as the 'central challenge' lacks an explicit synthesis step (e.g., theme frequency counts, contradiction resolution protocol, or differential emphasis across the three trajectories). This leaves the central claim vulnerable to selection or interpretation bias in the 48-paper base.
minor comments (2)
- [Results] A table mapping the nine themes to the three trajectories (practice/education/workforce) would improve clarity and allow readers to trace how individual findings aggregate into the education emphasis.
- [Contributions (ii)] The nine-dimension competency model is introduced without an accompanying figure or explicit cross-reference to the source themes; adding such a mapping would strengthen traceability.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and the recognition of the paper's timely synthesis. We will revise the manuscript to enhance methodological transparency and strengthen the justification for the central claim. All major comments can be addressed through targeted additions without altering the core findings.
read point-by-point responses
-
Referee: [Methods / four-agent workflow description] The paper selection criteria, screening process, and verification steps for the 48 publications are described only at a high level in the methods section. Without explicit inclusion/exclusion rules, venue coverage details, or inter-rater metrics, it is not possible to evaluate whether the sample is representative of 2016–2026 literature; this directly affects the load-bearing claim that the nine themes support elevating education for judgment/verification/orchestration as the central challenge.
Authors: We agree that greater detail is needed. In the revised manuscript we will expand the Methods section to include: (1) explicit inclusion/exclusion criteria (e.g., peer-reviewed status, relevance to GenAI/LLM/Agentic AI in SE, 2016–2026 timeframe); (2) the specific venues searched (top SE, ML, education, and HCI conferences/journals); and (3) verification procedures, including how the 48 papers were cross-checked against primary sources. Inter-rater agreement metrics from the verification step will also be reported. These additions will allow readers to assess representativeness directly. revision: yes
-
Referee: [Methods / Literature Discovery and Curriculum Transformation agents] The four-agent workflow is outlined conceptually but the specific prompts, decision rules, or coding scheme used to extract the nine themes and assign them to trajectories are not provided. Reproducibility of the synthesis that underpins the competency model and curriculum roadmap therefore cannot be assessed from the manuscript.
Authors: We will add an appendix containing the exact prompts used by each agent, the decision rules for theme extraction, and the coding scheme for trajectory assignment. This will make the synthesis process fully reproducible while preserving the main text flow. revision: yes
-
Referee: [Discussion / Conclusion] The abstract states that productivity evidence is internally contradictory and context-dependent, yet the final weighting that positions education as the 'central challenge' lacks an explicit synthesis step (e.g., theme frequency counts, contradiction resolution protocol, or differential emphasis across the three trajectories). This leaves the central claim vulnerable to selection or interpretation bias in the 48-paper base.
Authors: We will insert a new subsection in the Discussion that provides: (a) frequency counts of themes across the 48 papers, (b) the protocol used to handle contradictory productivity findings (explicitly noting context-dependency rather than averaging), and (c) differential weighting across the practice, education, and workforce trajectories. This will make the elevation of education for judgment/verification/orchestration traceable to the evidence base. revision: yes
Circularity Check
No circularity: synthesis draws exclusively from external publications via described workflow
full rationale
The paper is a systematic literature review that selects 48 external peer-reviewed publications (2016-2026) from listed venues, applies a four-agent workflow for discovery/screening/analysis, and synthesizes nine themes and three trajectories to reach its education/workforce conclusions. No equations, fitted parameters, predictions, or self-referential derivations appear. The central claim (educating for judgment/verification/orchestration as the core challenge) is presented as a synthesis outcome from the cited external sources rather than a quantity defined by the paper's own inputs or a self-citation chain. The representativeness of the sample is an external-validity concern, not a circularity reduction of the derivation to its inputs by construction. This matches the default expectation for non-circular reviews.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The 48 verified influential peer-reviewed publications constitute a representative sample of developments in AI for software engineering from 2016-2026.
Reference graph
Works this paper leans on
-
[1]
Iftekhar Ahmed, Aldeida Aleti, Haipeng Cai, Alexander Chatzigeorgiou, Pinjia He, Xing Hu, Mauro Pezzè, Denys Poshyvanyk, and Xin Xia. Artificial intelligence for software engineering: The journey so far and the 15 APREPRINT- JUNE12, 2026 road ahead.ACM Transactions on Software Engineering and Methodology, 34(5):1–27, 2025
2026
-
[2]
A 2030 roadmap for software engineering.ACM Transactions on Software Engineering and Methodology, 34(5):1– 55, 2025
Mauro Pezzè, Silvia Abrahão, Birgit Penzenstadler, Denys Poshyvanyk, Abhik Roychoudhury, and Tao Yue. A 2030 roadmap for software engineering.ACM Transactions on Software Engineering and Methodology, 34(5):1– 55, 2025
2030
-
[3]
SWE-bench: Can Language Models Resolve Real-World GitHub Issues?
C.E. Jimenez, J. Yang, A. Wettig, S. Yao, et al. Swe-bench: Can language models resolve real-world github issues? InProc. ICLR, 2024. arXiv:2310.06770
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[4]
SWE-agent: Agent-Computer Interfaces Enable Automated Software Engineering
J. Yang, C.E. Jimenez, A. Wettig, et al. Swe-agent: Agent-computer interfaces enable automated software engineering. InProc. NeurIPS, 2024. arXiv:2405.15793
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[5]
A.E. Hassan, G.A. Oliva, D. Lin, B. Chen, and Z.M. Jiang. Towards ai-native software engineering (se 3.0): A vision and a challenge roadmap.arXiv / ACM TOSEM, 2024. arXiv:2410.06107
-
[6]
Z. Feng, D. Guo, D. Tang, N. Duan, et al. Codebert: A pre-trained model for programming and natural languages. InProc. Findings of EMNLP, 2020. aclanthology 2020.findings-emnlp.139
2020
-
[7]
Y . Wang, W. Wang, S. Joty, and S.C.H. Hoi. Codet5: Identifier-aware unified pre-trained encoder-decoder models for code. InProc. EMNLP, 2021. arXiv:2109.00859
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[8]
Evaluating Large Language Models Trained on Code
M. Chen et al. Evaluating large language models trained on code (codex). arXiv, 2021. arXiv:2107.03374
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[9]
Li et al
Y . Li et al. Competition-level code generation with alphacode.Science, 2022
2022
-
[10]
R. Li, L. Ben Allal, Y . Zi, et al. Starcoder: May the source be with you!TMLR / arXiv, 2023. arXiv:2305.06161
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[11]
X. Hou, Y . Zhao, Y . Liu, Z. Yang, K. Wang, L. Li, X. Luo, D. Lo, J. Grundy, and H. Wang. Large language models for software engineering: A systematic literature review.ACM TOSEM, 2024
2024
-
[12]
Prather, P
J. Prather, P. Denny, J. Leinonen, B.A. Becker, et al. The robots are here: Navigating the generative ai revolution in computing education. InProc. ITiCSE-WGR, 2023
2023
-
[13]
Denny, J
P. Denny, J. Prather, B.A. Becker, J. Finnie-Ansley, et al. Computing education in the era of generative ai.Comm. of the ACM, 2024
2024
-
[14]
C. Qian, W. Liu, et al. Chatdev: Communicative agents for software development. InProc. ACL, 2024. arXiv:2307.07924
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[15]
S. Hong, M. Zhuge, et al. Metagpt: Meta programming for a multi-agent collaborative framework. InProc. ICLR (Oral), 2024. arXiv:2308.00352
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[16]
S. Yao, J. Zhao, D. Yu, et al. React: Synergizing reasoning and acting in language models. InProc. ICLR, 2023. arXiv:2210.03629
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[17]
Reflexion: Language Agents with Verbal Reinforcement Learning
N. Shinn, F. Cassano, E. Berman, et al. Reflexion: Language agents with verbal reinforcement learning. InProc. NeurIPS, 2023. arXiv:2303.11366
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[18]
C.S. Xia, Y . Wei, and L. Zhang. Automated program repair in the era of large pre-trained language models. In Proc. ICSE, 2023
2023
-
[19]
Schäfer, S
M. Schäfer, S. Nadi, A. Eghbali, and F. Tip. An empirical evaluation of using llms for automated unit test generation (testpilot).IEEE TSE, 2024
2024
- [20]
-
[21]
Perry, M
N. Perry, M. Srivastava, D. Kumar, and D. Boneh. Do users write more insecure code with ai assistants? InProc. ACM CCS, 2023
2023
-
[22]
Mozannar, G
H. Mozannar, G. Bansal, A. Fourney, and E. Horvitz. Reading between the lines: Modeling user behavior and costs in ai-assisted programming. InProc. ACM CHI, 2024
2024
-
[23]
S. Peng, E. Kalliamvakou, P. Cihon, and M. Demirer. The impact of ai on developer productivity: Evidence from github copilot. arXiv (MSR), 2023. arXiv:2302.06590
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[24]
Ziegler, E
A. Ziegler, E. Kalliamvakou, X.A. Li, A. Rice, et al. Productivity assessment of neural code completion. InProc. ACM MAPS, 2022
2022
-
[25]
Ziegler, E
A. Ziegler, E. Kalliamvakou, X.A. Li, et al. Measuring github copilot’s impact on productivity.Comm. of the ACM, 2024
2024
-
[26]
Barke, M.B
S. Barke, M.B. James, and N. Polikarpova. Grounded copilot: How programmers interact with code-generating models.OOPSLA (PACMPL), 2023. 16 APREPRINT- JUNE12, 2026
2023
-
[27]
Vaithilingam, T
P. Vaithilingam, T. Zhang, and E.L. Glassman. Expectation vs. experience: Evaluating the usability of code generation tools powered by llms. InProc. ACM CHI EA, 2022
2022
-
[28]
Liang, C
J.T. Liang, C. Yang, and B.A. Myers. A large-scale survey on the usability of ai programming assistants: Suc- cesses and challenges. InProc. ICSE, 2024
2024
-
[29]
J. Becker, N. Rush, B. Barnes, and D. Rein. Measuring the impact of early-2025 ai on experienced open-source developer productivity. arXiv (METR), 2025. arXiv:2507.09089
-
[30]
Z.K. Cui, M. Demirer, S. Jaffe, L. Musolff, S. Peng, and T. Salz. The effects of generative ai on high-skilled work: Three field experiments with software developers.Management Science, 2025
2025
-
[31]
Brynjolfsson, D
E. Brynjolfsson, D. Li, and L.R. Raymond. Generative ai at work.NBER WP / QJE, 2023. NBER w31161
2023
-
[32]
Noy and W
S. Noy and W. Zhang. Experimental evidence on the productivity effects of generative artificial intelligence. Science, 2023
2023
-
[33]
Hoffmann, S
M. Hoffmann, S. Boysel, F. Nagle, S. Peng, and K. Xu. Generative ai and the nature of work. HBS Working Paper, 2024. SSRN 5007084
2024
-
[34]
A. Bick, A. Blandin, and D.J. Deming. The rapid adoption of generative ai. NBER WP, 2024. NBER w32966
2024
-
[35]
Finnie-Ansley, P
J. Finnie-Ansley, P. Denny, B.A. Becker, A. Luxton-Reilly, and J. Prather. The robots are coming: Exploring the implications of openai codex on introductory programming. InProc. ACE, 2022
2022
-
[36]
Finnie-Ansley, P
J. Finnie-Ansley, P. Denny, A. Luxton-Reilly, E.A. Santos, J. Prather, and B.A. Becker. My ai wants to know if this will be on the exam: Testing openai’s codex on cs2 exercises. InProc. ACE, 2023
2023
-
[37]
Phung, V .-A
T. Phung, V .-A. P˘adurean, J. Cambronero, S. Gulwani, T. Kohn, R. Majumdar, A. Singla, and G. Soares. Gener- ative ai for programming education: Benchmarking chatgpt, gpt-4, and human tutors. InProc. ICER, 2023
2023
-
[38]
Hellas, J
A. Hellas, J. Leinonen, S. Sarsa, C. Koutcheme, L. Kujanpää, and J. Sorva. Exploring the responses of large language models to beginner programmers’ help requests. InProc. ICER, 2023
2023
-
[39]
Wermelinger
M. Wermelinger. Using github copilot to solve simple programming problems. InProc. SIGCSE TS, 2023
2023
-
[40]
Denny, V
P. Denny, V . Kumar, and N. Giacaman. Conversing with copilot: Exploring prompt engineering for solving cs1 problems using natural language. InProc. SIGCSE TS, 2023
2023
-
[41]
Sarsa, P
S. Sarsa, P. Denny, A. Hellas, and J. Leinonen. Automatic generation of programming exercises and code explanations using llms. InProc. ICER, 2022
2022
-
[42]
MacNeil, A
S. MacNeil, A. Tran, A. Hellas, J. Kim, S. Sarsa, P. Denny, S. Bernstein, and J. Leinonen. Experiences from using code explanations generated by llms in a web development e-book. InProc. SIGCSE TS, 2023
2023
-
[43]
Leinonen, P
J. Leinonen, P. Denny, S. MacNeil, S. Sarsa, S. Bernstein, J. Kim, A. Tran, and A. Hellas. Comparing code explanations created by students and large language models. InProc. ITiCSE, 2023
2023
-
[44]
Denny, J
P. Denny, J. Leinonen, J. Prather, A. Luxton-Reilly, T. Amarouche, B.A. Becker, and B.N. Reeves. Prompt problems: A new programming exercise for the generative ai era. InProc. SIGCSE TS, 2024
2024
-
[45]
Liffiton, B
M. Liffiton, B. Sheese, J. Savelka, and P. Denny. Codehelp: Using llms with guardrails for scalable support in programming classes. InProc. Koli Calling, 2023
2023
-
[46]
Kazemitabaar, J
M. Kazemitabaar, J. Chow, C.K.T. Ma, B.J. Ericson, D. Weintrop, and T. Grossman. Studying the effect of ai code generators on supporting novice learners in introductory programming. InProc. CHI, 2023
2023
-
[47]
it’s weird that it knows what i want
J. Prather, B.N. Reeves, P. Denny, B.A. Becker, J. Leinonen, et al. "it’s weird that it knows what i want": Usability and interactions with copilot for novice programmers.ACM TOCHI, 2024
2024
-
[48]
Prather, B.N
J. Prather, B.N. Reeves, J. Leinonen, S. MacNeil, et al. The widening gap: The benefits and harms of generative ai for novice programmers. InProc. ICER, 2024
2024
-
[49]
Lau and P.J
S. Lau and P.J. Guo. From ’ban it till we understand it’ to ’resistance is futile’: How programming instructors plan to adapt to ai tools. InProc. ICER, 2023
2023
-
[50]
Becker, P
B.A. Becker, P. Denny, J. Finnie-Ansley, A. Luxton-Reilly, J. Prather, and E.A. Santos. Programming is hard - or at least it used to be: Educational opportunities and challenges of ai code generation. InProc. SIGCSE TS, 2023. 17
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.