Faster or Stronger: Towards Flexible Visual Place Recognition via Weighted Aggregation and Token Pruning
Pith reviewed 2026-05-21 06:21 UTC · model grok-4.3
The pith
Weighted cluster aggregation and inference-time token pruning let visual place recognition models trade accuracy for speed after one training run.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Assigning weights to clusters during aggregation yields more discriminative global descriptors for VPR, and the same importance information can supervise a pruning module that supports plug-and-play token reduction at inference after a single joint training phase, outperforming token-pruning techniques transferred from general vision tasks.
What carries the argument
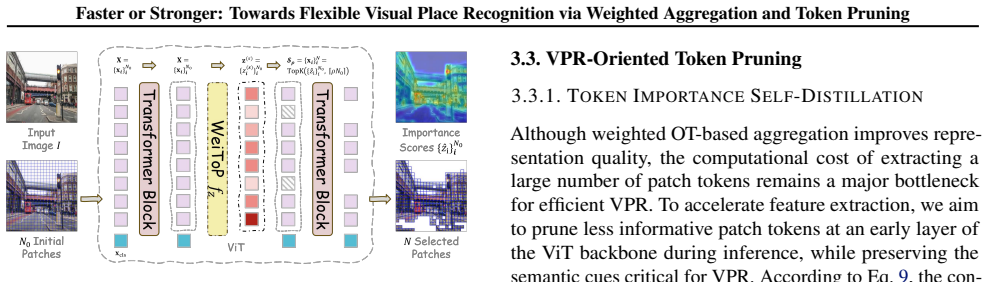
The Weighted Aggregated Descriptor (WeiAD) that multiplies cluster contributions by learned weights, together with the WeiToP self-distillation pipeline that transfers aggregation-derived token importance to an early-layer pruning module.
If this is right
- Global descriptors become more discriminative because clusters that matter more for place identity receive higher weight.
- Feature extraction cost can be reduced on demand at inference without retraining or separate models for each speed target.
- The accuracy-efficiency curve can be adjusted continuously by choosing how many tokens to keep.
- VPR-specific pruning outperforms general-purpose token pruning methods when both are applied to the same backbone.
Where Pith is reading between the lines
- The same weighting-plus-pruning pattern could be tested on other retrieval problems that rely on transformer patch tokens, such as landmark or product search.
- Pairing the pruned descriptors with existing compression techniques would further cut storage and search time for city-scale databases.
- Running the method on sequences with strong seasonal or illumination change would reveal whether the learned weights remain stable across domain shifts.
Load-bearing premise
Importance scores produced by the weighted aggregation step remain reliable enough to supervise pruning so that accuracy stays acceptable across different pruning ratios without any further training.
What would settle it
Measuring that top-1 retrieval accuracy on a standard VPR benchmark such as Oxford RobotCar falls more than five percent below the unpruned baseline once half the tokens are removed.
Figures












read the original abstract
Visual Place Recognition (VPR) aims to match a query image to reference images of the same place in a large-scale database. Recent state-of-the-art methods employ Vision Transformers (ViTs) as backbone foundation models to extract patch-level features that are robust to viewpoint, illumination, and seasonal variations, which are then aggregated into a compact global descriptor for retrieval. Most existing aggregation methods uniformly pool patch tokens into learned clusters, despite the fact that different clusters often encode distinct spatial or semantic patterns and contribute unequally to VPR performance. To address this limitation, we propose Weighted Aggregated Descriptor (WeiAD), which assigns weights to clusters during aggregation, producing more discriminative global representations. Beyond accuracy, retrieval latency is a critical concern for large-scale deployments and resource-constrained edge devices. Prior work mainly reduces latency by compressing global descriptors, while overlooking the cost of feature extraction, an issue exacerbated by ViT-based backbones. We therefore introduce WeiToP, a VPR-oriented token pruning framework that reduces feature extraction cost via self-distillation, where aggregation-induced token importance supervises a lightweight pruning module attached to an early transformer layer, enabling inference-time token pruning. After a single joint training phase, WeiToP enables plug-and-play token pruning at inference time, allowing flexible and on-demand control over the accuracy-efficiency trade-off without additional training. Moreover, WeiToP outperforms existing token pruning methods adapted from general vision tasks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes two modules for ViT-based Visual Place Recognition: WeiAD, which learns to weight clusters during aggregation to produce more discriminative global descriptors than uniform pooling, and WeiToP, a self-distillation framework that transfers token importance scores derived from the final weighted aggregation to train a lightweight pruning head attached after an early transformer block. After one joint training run, WeiToP permits inference-time token pruning at arbitrary ratios without retraining, aiming to improve the accuracy-efficiency trade-off over both standard VPR pipelines and token-pruning methods transferred from general vision tasks.
Significance. If the empirical claims hold, the work would offer a practical way to obtain stronger global descriptors while simultaneously reducing the dominant cost of ViT feature extraction in large-scale VPR. The plug-and-play character of WeiToP after a single training phase is a notable engineering contribution for edge deployment. However, the significance is tempered by the absence of any quantitative results, ablation tables, or error analysis in the provided abstract; the central claims therefore remain unverified at this stage.
major comments (2)
- [WeiToP framework] WeiToP description: the core assumption that final-layer aggregation weights can reliably supervise a pruning module attached to an early transformer block is load-bearing for the 'single-training, plug-and-play' claim. Early blocks primarily encode local texture and edges, while aggregation operates on the final token set; without reported layer-wise correlation statistics or an ablation that measures VPR recall degradation when early-layer importance is used, it is unclear whether the self-distillation objective aligns on VPR-critical structure or on spurious correlations.
- [Experiments] Experimental section: the abstract states that WeiToP 'outperforms existing token pruning methods adapted from general vision tasks,' yet no recall@N, latency, or FLOPs numbers, no baseline descriptions, and no ablation on pruning ratios are supplied. Because the soundness of the accuracy-efficiency curves cannot be assessed, the headline claim that flexible control is achieved without per-ratio retraining remains unverified.
minor comments (2)
- [Abstract] The abstract is unusually long and contains several compound claims; a shorter, more focused abstract would improve readability.
- [Method] Notation for the weighting function in WeiAD and the importance-score head in WeiToP should be introduced with explicit equations rather than prose descriptions.
Simulated Author's Rebuttal
We thank the referee for the thoughtful review and constructive feedback. We address each major comment below, providing clarifications and indicating revisions to the manuscript where appropriate.
read point-by-point responses
-
Referee: [WeiToP framework] WeiToP description: the core assumption that final-layer aggregation weights can reliably supervise a pruning module attached to an early transformer block is load-bearing for the 'single-training, plug-and-play' claim. Early blocks primarily encode local texture and edges, while aggregation operates on the final token set; without reported layer-wise correlation statistics or an ablation that measures VPR recall degradation when early-layer importance is used, it is unclear whether the self-distillation objective aligns on VPR-critical structure or on spurious correlations.
Authors: We appreciate the referee pointing out the need for further validation of the self-distillation alignment in WeiToP. While the manuscript describes the framework and its motivation, we acknowledge that explicit layer-wise correlation statistics and a dedicated ablation on recall degradation for early vs. late layer importance were not included. We will add these analyses in the revised version to demonstrate that the transferred importance scores capture VPR-relevant structures rather than spurious correlations. revision: yes
-
Referee: [Experiments] Experimental section: the abstract states that WeiToP 'outperforms existing token pruning methods adapted from general vision tasks,' yet no recall@N, latency, or FLOPs numbers, no baseline descriptions, and no ablation on pruning ratios are supplied. Because the soundness of the accuracy-efficiency curves cannot be assessed, the headline claim that flexible control is achieved without per-ratio retraining remains unverified.
Authors: The abstract is constrained by length and thus omits specific numerical results, which are presented in detail in the experimental section of the full manuscript, including comparisons with adapted token pruning methods, recall metrics, latency, FLOPs, and ablations across pruning ratios. To address this, we will revise the abstract to include key quantitative findings supporting the claims. revision: yes
Circularity Check
No significant circularity; proposals are independent architectural modules with external validation
full rationale
The paper introduces WeiAD as a weighted aggregation module and WeiToP as a self-distillation-based pruning framework supervised by aggregation-derived importance scores. These are presented as novel components trained jointly on VPR tasks, with claims supported by empirical comparisons on standard benchmarks rather than any definitional equivalence or reduction of outputs to fitted inputs from the same data. No equations or steps reduce the reported accuracy-efficiency trade-offs to quantities defined by construction from the inputs; the supervision link is a designed training objective, not a tautology. Self-citations for baselines or prior ViT work are not load-bearing for the central claims, which remain falsifiable via external datasets.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption ViT patch tokens encode spatial and semantic patterns that can be meaningfully clustered and weighted for place discrimination.
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
self-distillation... Ldistill = T² · 1/N0 Σ p(t)_i log(p(t)_i / p(s)_i)
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Proceedings of the ieee/cvf conference on computer vision and pattern recognition , pages=
Optimal transport aggregation for visual place recognition , author=. Proceedings of the ieee/cvf conference on computer vision and pattern recognition , pages=
-
[2]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Rethinking visual geo-localization for large-scale applications , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[3]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
Eigenplaces: Training viewpoint robust models for visual place recognition , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[4]
Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
NetVLAD: CNN architecture for weakly supervised place recognition , author=. Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
-
[5]
Proceedings of the IEEE/CVF winter conference on applications of computer vision , pages=
Mixvpr: Feature mixing for visual place recognition , author=. Proceedings of the IEEE/CVF winter conference on applications of computer vision , pages=
-
[6]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Cricavpr: Cross-image correlation-aware representation learning for visual place recognition , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[7]
Billion-scale similarity search with
Johnson, Jeff and Douze, Matthijs and J. Billion-scale similarity search with. IEEE Transactions on Big Data , volume=. 2019 , publisher=
work page 2019
-
[8]
IEEE Robotics and Automation Letters , year=
Anyloc: Towards universal visual place recognition , author=. IEEE Robotics and Automation Letters , year=
-
[9]
European Conference on Computer Vision , pages=
Revisit anything: Visual place recognition via image segment retrieval , author=. European Conference on Computer Vision , pages=. 2024 , organization=
work page 2024
-
[10]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
R2former: Unified retrieval and reranking transformer for place recognition , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[11]
Advances in Neural Information Processing Systems , volume=
SuperVLAD: Compact and robust image descriptors for visual place recognition , author=. Advances in Neural Information Processing Systems , volume=
-
[12]
Towards seamless adaptation of pre-trained models for visual place recognition,
Towards seamless adaptation of pre-trained models for visual place recognition , author=. arXiv preprint arXiv:2402.14505 , year=
-
[13]
European Conference on Computer Vision , pages=
VLAD-BuFF: burst-aware fast feature aggregation for visual place recognition , author=. European Conference on Computer Vision , pages=. 2024 , organization=
work page 2024
-
[14]
IEEE Robotics and Automation Letters , volume=
Dilated Superpixel Aggregation for Visual Place Recognition , author=. IEEE Robotics and Automation Letters , volume=. 2026 , publisher=
work page 2026
-
[15]
International conference on machine learning , pages=
Learning transferable visual models from natural language supervision , author=. International conference on machine learning , pages=. 2021 , organization=
work page 2021
-
[16]
DINOv2: Learning Robust Visual Features without Supervision
Dinov2: Learning robust visual features without supervision , author=. arXiv preprint arXiv:2304.07193 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[17]
Proceedings of the AAAI Conference on Artificial Intelligence , author=
Fit and Prune: Fast and Training-free Visual Token Pruning for Multi-modal Large Language Models , volume=. Proceedings of the AAAI Conference on Artificial Intelligence , author=. 2025 , month=. doi:10.1609/aaai.v39i21.34366 , number=
-
[18]
Advances in neural information processing systems , volume=
Dynamicvit: Efficient vision transformers with dynamic token sparsification , author=. Advances in neural information processing systems , volume=
-
[19]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Adavit: Adaptive vision transformers for efficient image recognition , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[20]
Gsv-cities: Toward appropriate supervised visual place recognition , author=. Neurocomputing , volume=. 2022 , publisher=
work page 2022
-
[21]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Mapillary street-level sequences: A dataset for lifelong place recognition , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[22]
IEEE Robotics and Automation Letters , volume=
Learning context flexible attention model for long-term visual place recognition , author=. IEEE Robotics and Automation Letters , volume=. 2018 , publisher=
work page 2018
-
[23]
Are we there yet? Challenging SeqSLAM on a 3000 km journey across all four seasons , author=. Proc. of workshop on long-term autonomy, IEEE international conference on robotics and automation (ICRA) , pages=. 2013 , organization=
work page 2013
-
[24]
2022 26th International Conference on Pattern Recognition (ICPR) , pages=
Amstertime: A visual place recognition benchmark dataset for severe domain shift , author=. 2022 26th International Conference on Pattern Recognition (ICPR) , pages=. 2022 , organization=
work page 2022
-
[25]
IEEE transactions on pattern analysis and machine intelligence , volume=
Fine-tuning CNN image retrieval with no human annotation , author=. IEEE transactions on pattern analysis and machine intelligence , volume=. 2018 , publisher=
work page 2018
-
[26]
Advances in neural information processing systems , volume=
Sinkhorn distances: Lightspeed computation of optimal transport , author=. Advances in neural information processing systems , volume=
-
[27]
Pacific Journal of Mathematics , volume=
Concerning nonnegative matrices and doubly stochastic matrices , author=. Pacific Journal of Mathematics , volume=. 1967 , publisher=
work page 1967
-
[28]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Superglue: Learning feature matching with graph neural networks , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[29]
Distilling the Knowledge in a Neural Network
Distilling the knowledge in a neural network , author=. arXiv preprint arXiv:1503.02531 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[30]
Proceedings of IEEE International conference on Robotics and Automation , volume=
Visual navigation using view-sequenced route representation , author=. Proceedings of IEEE International conference on Robotics and Automation , volume=. 1996 , organization=
work page 1996
-
[31]
Vpair-aerial visual place recognition and localization in large-scale outdoor environments
VPAIR--Aerial Visual Place Recognition and Localization in Large-scale Outdoor Environments , author=. arXiv preprint arXiv:2205.11567 , year=
-
[32]
European Conference on Computer Vision , pages=
Capturing, reconstructing, and simulating: the urbanscene3d dataset , author=. European Conference on Computer Vision , pages=. 2022 , organization=
work page 2022
-
[33]
2006 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR'06) , volume=
Scalable recognition with a vocabulary tree , author=. 2006 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR'06) , volume=. 2006 , organization=
work page 2006
-
[34]
The International Journal of Robotics Research , volume=
Persistent navigation and mapping using a biologically inspired SLAM system , author=. The International Journal of Robotics Research , volume=. 2010 , publisher=
work page 2010
-
[35]
IEEE transactions on robotics , volume=
ORB-SLAM: A versatile and accurate monocular SLAM system , author=. IEEE transactions on robotics , volume=. 2015 , publisher=
work page 2015
-
[36]
European conference on computer vision , pages=
Planet-photo geolocation with convolutional neural networks , author=. European conference on computer vision , pages=. 2016 , organization=
work page 2016
-
[37]
Mo- bilebert: a compact task-agnostic bert for resource-limited devices,
Mobilebert: a compact task-agnostic bert for resource-limited devices , author=. arXiv preprint arXiv:2004.02984 , year=
-
[38]
European Conference on Computer Vision , pages=
An image is worth 1/2 tokens after layer 2: Plug-and-play inference acceleration for large vision-language models , author=. European Conference on Computer Vision , pages=. 2024 , organization=
work page 2024
-
[39]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Multi-similarity loss with general pair weighting for deep metric learning , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[40]
Dinov3 , author=. arXiv preprint arXiv:2508.10104 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[41]
Decoupled Weight Decay Regularization
Decoupled weight decay regularization , author=. arXiv preprint arXiv:1711.05101 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[42]
International Conference on Learning Representations , year=
Not All Patches are What You Need: Expediting Vision Transformers via Token Reorganizations , author=. International Conference on Learning Representations , year=
-
[43]
Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision , pages=
Token fusion: Bridging the gap between token pruning and token merging , author=. Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision , pages=
-
[44]
Proceedings of the 28th ACM SIGKDD conference on knowledge discovery and data mining , pages=
Learned token pruning for transformers , author=. Proceedings of the 28th ACM SIGKDD conference on knowledge discovery and data mining , pages=
-
[45]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
Dynamic token pruning in plain vision transformers for semantic segmentation , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[46]
Token Merging: Your ViT But Faster
Token merging: Your vit but faster , author=. arXiv preprint arXiv:2210.09461 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[47]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Zero-TPrune: Zero-shot token pruning through leveraging of the attention graph in pre-trained transformers , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[48]
European conference on computer vision , pages=
Adaptive token sampling for efficient vision transformers , author=. European conference on computer vision , pages=. 2022 , organization=
work page 2022
-
[49]
arXiv preprint arXiv:2603.27758 , year=
RHO: Robust Holistic OSM-Based Metric Cross-View Geo-Localization , author=. arXiv preprint arXiv:2603.27758 , year=
-
[50]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Transgeo: Transformer is all you need for cross-view image geo-localization , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.