EstRTL: Functional Estimation Guided RTL Code Generation
Pith reviewed 2026-06-28 12:32 UTC · model grok-4.3
The pith
A functional estimation agent in a three-stage framework raises the rate at which generic LLMs produce correct RTL code by 3.2 to 9 percent.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
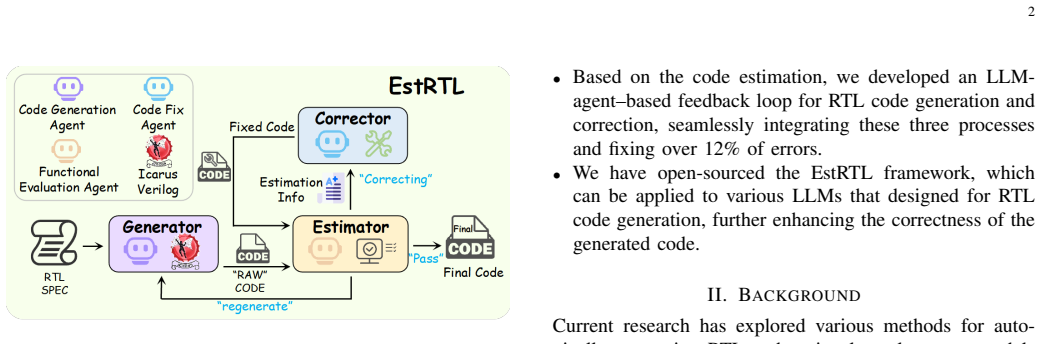
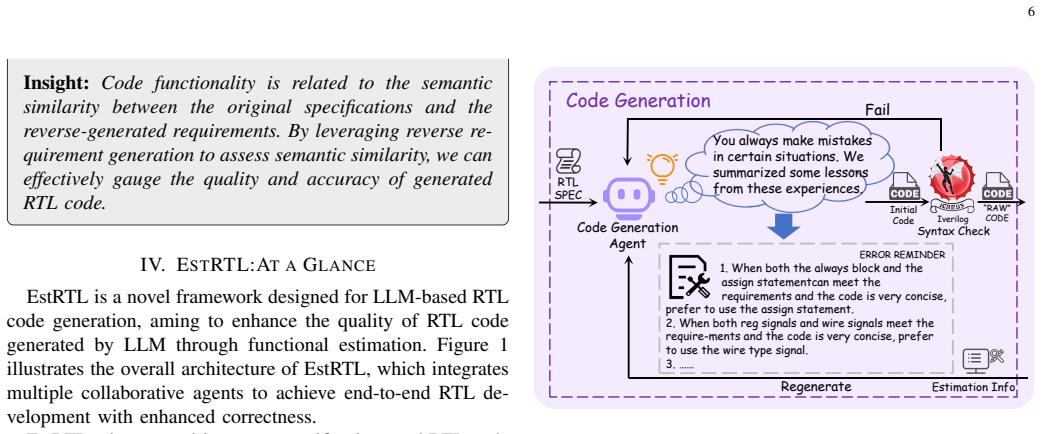
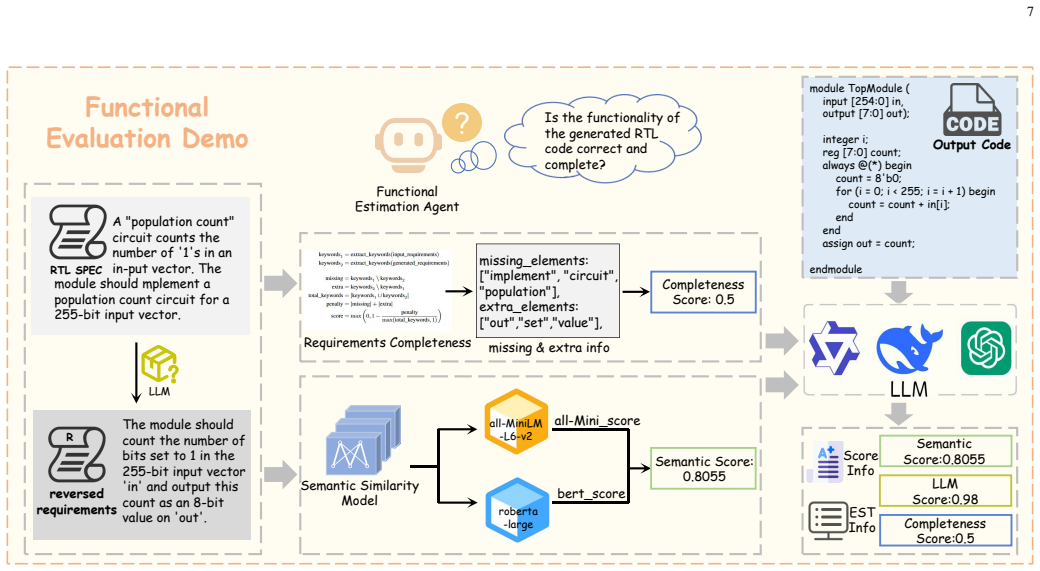
EstRTL operates a three-stage paradigm of Generation, Estimation and Correction where the functional estimation agent statically evaluates the generated code based on score and assessment results to decide whether to output the code directly, return it for regeneration, or forward it to the code correction agent, thereby improving correctness of RTL code generated by generic LLMs.
What carries the argument
The functional estimation agent that statically evaluates generated RTL code using quantitative scores and human-readable requirement comparisons to guide acceptance, regeneration, or correction.
Load-bearing premise
The functional estimation agent can produce a static score that reliably predicts whether the generated RTL code will behave correctly in real hardware implementations.
What would settle it
Run the generated RTL code on actual FPGA or ASIC hardware with functional tests and check if codes with high estimation scores pass more often than low-score ones.
Figures





read the original abstract
Optimizing register transfer level (RTL) code is of vital importance in hardware design. Large language models (LLMs) provide new methods for the automatic generation and optimization of RTL code, offering the potential to significantly accelerate the design process and reduce human effort. However, existing methods for generating RTL code often focus on model fine-tuning and the use of various expansion techniques to enhance the RTL code generation capabilities, lacking attention to the functional correctness. Ensuring that the generated RTL code not only compiles successfully but also behaves as intended in real hardware implementations remains a critical challenge. To address this issue, we propose EstRTL, an LLM-powered collaborative agent framework for RTL code generation based on static functional score estimation. EstRTL operates a three-stage paradigm: Generation, Estimation and Correction. During the stages, the functional estimation agent statically evaluates the generated code based on score and assessment results, and decides whether to output the code directly, return it for regeneration, or forward it to the code correction agent. This framework can be applied to various LLMs that designed for RTL code generation, further enhancing the correctness of the generated code. By providing quantitative scores and human-readable requirements comparisons, it improves the transparency of AI-assisted RTL code generation. Experiments show that EstRTL significantly improves the correctness of RTL code generation by generic LLM by 3.2\%-9.0\%, demonstrating the practical value of our system. The codes and experimental results are open-sourced at link: https://anonymous.4open.science/status/EstRTL-E200/.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes EstRTL, an LLM-powered three-stage agent framework (Generation, Estimation, Correction) for RTL code generation. A functional estimation agent statically scores generated code to decide direct output, regeneration, or forwarding to a correction agent, with the goal of improving functional correctness. Experiments are reported to show 3.2%-9.0% gains in correctness for generic LLMs, and the framework is claimed to add transparency via quantitative scores and requirement comparisons.
Significance. If the static estimation scores were shown to be a reliable proxy for simulation or hardware correctness, the framework could offer a practical, transparent method to boost LLM-based RTL generation without model retraining. The open-sourcing of code and results is a positive step toward reproducibility.
major comments (2)
- [Abstract / Experiments] Abstract and Experiments: The central claim attributes the 3.2%-9.0% correctness improvement to the estimation agent's static score deciding output vs. regeneration vs. correction, yet no precision-recall, correlation, or ablation results are supplied to demonstrate that the score predicts actual RTL simulation or hardware behavior; without this, the attribution cannot be verified and the reported gains could stem from the correction stage alone.
- [Framework description] Framework description: The soundness of the three-stage loop rests on the functional estimation agent producing a static score that reliably proxies real hardware behavior, but the manuscript supplies no measurement protocol, baseline details, test-case counts, or error analysis to support the empirical improvement claim.
minor comments (1)
- [Abstract] The open-source link uses an anonymous service; a permanent, non-anonymous repository would better support reproducibility claims.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. The comments highlight important aspects of validating the estimation agent's contribution. We respond to each major comment below and outline planned revisions to address the concerns.
read point-by-point responses
-
Referee: [Abstract / Experiments] Abstract and Experiments: The central claim attributes the 3.2%-9.0% correctness improvement to the estimation agent's static score deciding output vs. regeneration vs. correction, yet no precision-recall, correlation, or ablation results are supplied to demonstrate that the score predicts actual RTL simulation or hardware behavior; without this, the attribution cannot be verified and the reported gains could stem from the correction stage alone.
Authors: We agree that isolating the estimation stage's contribution requires additional evidence. The current experiments demonstrate end-to-end gains from the full Generation-Estimation-Correction loop. In revision we will add an ablation comparing the full framework against a version that bypasses the estimation decision (always accepting or always correcting), along with correlation analysis between static scores and simulation outcomes on the reported benchmarks. This will clarify attribution without altering the core claims. revision: yes
-
Referee: [Framework description] Framework description: The soundness of the three-stage loop rests on the functional estimation agent producing a static score that reliably proxies real hardware behavior, but the manuscript supplies no measurement protocol, baseline details, test-case counts, or error analysis to support the empirical improvement claim.
Authors: Section 3 describes the estimation agent's static scoring via requirement comparison, and Section 4 reports the overall correctness improvements. We acknowledge that expanded protocol details would improve clarity. In the revised manuscript we will add a dedicated subsection on the evaluation protocol, including test-case counts per benchmark, baseline LLM configurations, and any observed error patterns in the estimation scores. revision: yes
Circularity Check
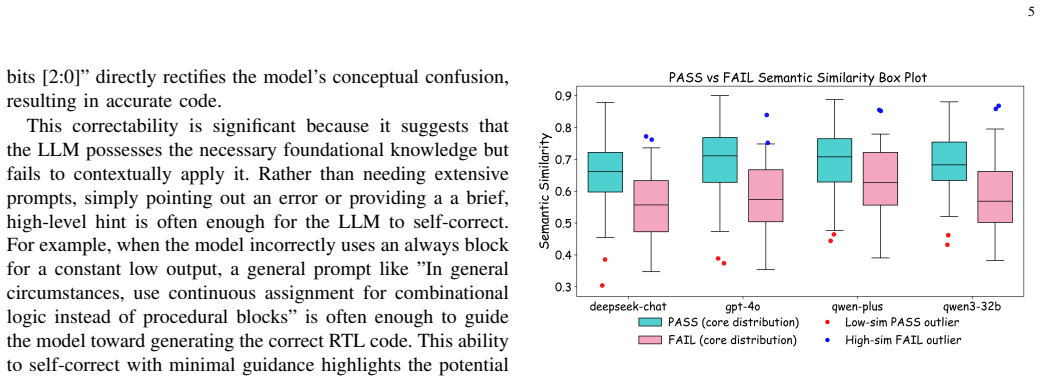
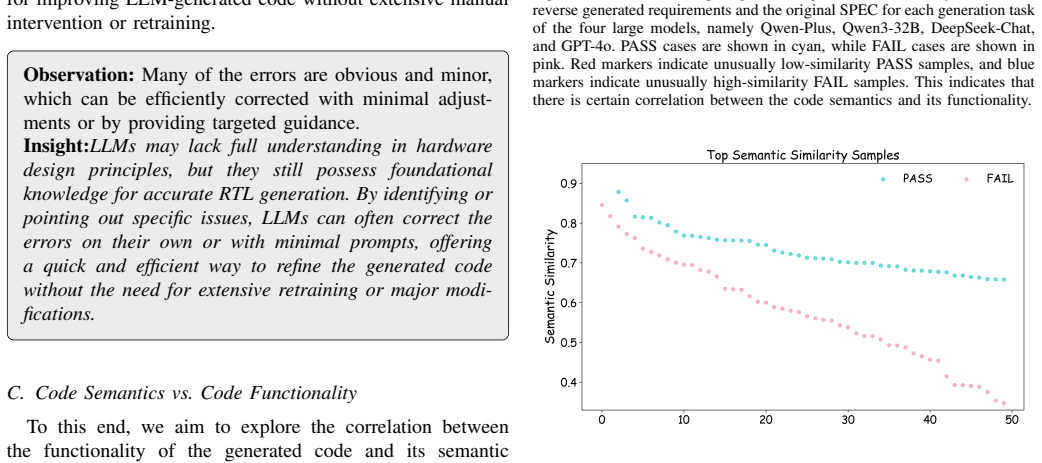
No circularity; experimental gains reported independently of any derivation chain
full rationale
The manuscript describes an agent framework (Generation-Estimation-Correction) and attributes correctness gains of 3.2%-9.0% to experimental evaluation on RTL code. No equations, fitted parameters, self-definitional loops, or load-bearing self-citations appear in the text. The reported improvements are presented as direct empirical outcomes measured against external simulation/hardware benchmarks, rendering the central claim self-contained without reduction to its own inputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Static analysis of RTL source can yield a numeric score that predicts functional correctness without simulation or testbench execution.
invented entities (1)
-
functional estimation agent
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Towards developing high performance RISC-V processors using agile methodology,
Y . Xu, Z. Yu, D. Tang, G. Chen, L. Chen, L. Gou, Y . Jin, Q. Li, X. Li, Z. Li, J. Lin, T. Liu, Z. Liu, J. Tan, H. Wang, H. Wang, K. Wang, C. Zhang, F. Zhang, L. Zhang, Z. Zhang, Y . Zhao, Y . Zhou, Y . Zhou, J. Zou, Y . Cai, D. Huan, Z. Li, J. Zhao, Z. Chen, W. He, Q. Quan, X. Liu, S. Wang, K. Shi, N. Sun, and Y . Bao, “Towards developing high performanc...
2022
-
[2]
Language models are few-shot learners,
T. B. Brown, B. Mann, N. Ryder, M. Subbiah, J. Kaplan, P. Dhariwal, A. Neelakantan, P. Shyam, G. Sastry, A. Askell, S. Agarwal, A. Herbert- V oss, G. Krueger, T. Henighan, R. Child, A. Ramesh, D. M. Ziegler, J. Wu, C. Winter, C. Hesse, M. Chen, E. Sigler, M. Litwin, S. Gray, B. Chess, J. Clark, C. Berner, S. McCandlish, A. Radford, I. Sutskever, and D. Am...
2020
-
[3]
Large language model and text generation,
Y . Wu, “Large language model and text generation,” inNatural language processing in biomedicine: A practical guide. Springer, 2024, pp. 265– 297
2024
-
[4]
From general llm to translation: How we dramatically improve trans- lation quality using human evaluation data for llm finetuning,
D. Elshin, N. Karpachev, B. Gruzdev, I. Golovanov, G. Ivanov, A. Antonov, N. Skachkov, E. Latypova, V . Layner, E. Enikeevaet al., “From general llm to translation: How we dramatically improve trans- lation quality using human evaluation data for llm finetuning,” in Proceedings of the Ninth Conference on Machine Translation, 2024, pp. 247–252
2024
-
[5]
Automatic question & answer generation using generative large language model (llm),
M. A. Ehsan, A. Hasan, K. B. Shahnoor, and S. S. Tasneem, “Automatic question & answer generation using generative large language model (llm),”arXiv preprint arXiv:2508.19475, 2025
-
[6]
Swe-bench: Can language models resolve real-world github issues?
C. E. Jimenez, J. Yang, A. Wettig, S. Yao, K. Pei, O. Press, and K. Narasimhan, “Swe-bench: Can language models resolve real-world github issues?”CoRR, 2023
2023
-
[7]
Swe-agent: Agent-computer interfaces enable automated soft- ware engineering,
J. Yang, C. E. Jimenez, A. Wettig, K. Lieret, S. Yao, K. Narasimhan, and O. Press, “Swe-agent: Agent-computer interfaces enable automated soft- ware engineering,”Advances in Neural Information Processing Systems, vol. 37, pp. 50 528–50 652, 2024
2024
-
[8]
L2MAC: large language model automatic computer for extensive code generation,
S. Holt, M. R. Luyten, and M. van der Schaar, “L2MAC: large language model automatic computer for extensive code generation,” inThe Twelfth International Conference on Learning Representations, (ICLR) 2024, Vienna, Austria, May 7-11, 2024
2024
-
[9]
Codeagent: Enhancing code generation with tool-integrated agent systems for real-world repo-level coding challenges,
K. Zhang, J. Li, G. Li, X. Shi, and Z. Jin, “Codeagent: Enhancing code generation with tool-integrated agent systems for real-world repo-level coding challenges,” inProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), ACL 2024, Bangkok, Thailand, August 11-16, L. Ku, A. Martins, and V . Srikumar,...
2024
-
[10]
Multipl-e: A scalable and polyglot approach to benchmarking neural code generation,
F. Cassano, J. Gouwar, D. Nguyen, S. Nguyen, L. Phipps-Costin, D. Pinckney, M.-H. Yee, Y . Zi, C. J. Anderson, M. Q. Feldmanet al., “Multipl-e: A scalable and polyglot approach to benchmarking neural code generation,”IEEE Transactions on Software Engineering, vol. 49, no. 7, pp. 3675–3691, 2023
2023
-
[11]
{HardFails}: insights into{software-exploitable}hardware bugs,
G. Dessouky, D. Gens, P. Haney, G. Persyn, A. Kanuparthi, H. Khattri, J. M. Fung, A.-R. Sadeghi, and J. Rajendran, “{HardFails}: insights into{software-exploitable}hardware bugs,” in28th USENIX Security Symposium (USENIX Security 19), 2019, pp. 213–230
2019
-
[12]
On hardware security bug code fixes by prompting large language models,
B. Ahmad, S. Thakur, B. Tan, R. Karri, and H. Pearce, “On hardware security bug code fixes by prompting large language models,”IEEE Transactions on Information Forensics and Security, vol. 19, pp. 4043– 4057, 2024
2024
-
[13]
Rtl- repair: Fast symbolic repair of hardware design code,
K. Laeufer, B. Fajardo, A. Ahuja, V . Iyer, B. Nikoli ´c, and K. Sen, “Rtl- repair: Fast symbolic repair of hardware design code,” inProceedings of the 29th ACM International Conference on Architectural Support for Programming Languages and Operating Systems, Volume 3, 2024, pp. 867–881
2024
-
[14]
S. Thakur, B. Ahmad, H. Pearce, B. Tan, B. Dolan-Gavitt, R. Karri, and S. Garg, “Verigen: A large language model for verilog code generation,”ACM Trans. Des. Autom. Electron. Syst., vol. 29, no. 3, Apr. 2024. [Online]. Available: https://doi.org/10.1145/3643681
-
[15]
Rtl- coder: Fully open-source and efficient llm-assisted rtl code generation technique,
S. Liu, W. Fang, Y . Lu, J. Wang, Q. Zhang, H. Zhang, and Z. Xie, “Rtl- coder: Fully open-source and efficient llm-assisted rtl code generation technique,”IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems, vol. 44, no. 4, pp. 1448–1461, 2025
2025
-
[16]
Teixeira, Ke Wang, Caroline Trippel, and Alex Aiken
A. Wei, H. Tan, T. Suresh, D. Mendoza, T. S. F. X. Teixeira, K. Wang, C. Trippel, and A. Aiken, “Vericoder: Enhancing llm-based RTL code generation through functional correctness validation,”CoRR, vol. abs/2504.15659, 2025
-
[17]
F. Cui, C. Yin, K. Zhou, Y . Xiao, G. Sun, Q. Xu, Q. Guo, Y . Liang, X. Zhang, D. Song, and D. Lin,OriGen: Enhancing RTL Code Generation with Code-to-Code Augmentation and Self-Reflection. New York, NY , USA: Association for Computing Machinery, 2025. [Online]. Available: https://doi.org/10.1145/3676536.3676830
-
[18]
Betterv: Controlled verilog generation with discriminative guidance,
Z. Pei, H. Zhen, M. Yuan, Y . Huang, and B. Yu, “Betterv: Controlled verilog generation with discriminative guidance,” inForty-first Interna- tional Conference on Machine Learning, ICML 2024, Vienna, Austria, July 21-27, 2024, 2024
2024
-
[19]
Autovcoder: A systematic framework for automated verilog code gen- eration using llms,
M. Gao, J. Zhao, Z. Lin, W. Ding, X. Hou, Y . Feng, C. Li, and M. Guo, “Autovcoder: A systematic framework for automated verilog code gen- eration using llms,” in2024 IEEE 42nd International Conference on Computer Design (ICCD), 2024, pp. 162–169
2024
-
[20]
Y . Zhao, D. Huang, C. Li, P. Jin, M. Song, Y . Xu, Z. Nan, M. Gao, T. Ma, L. Qiet al., “Codev: Empowering llms with hdl generation through multi-level summarization,”arXiv preprint arXiv:2407.10424, 2024
-
[21]
Craftrtl: High-quality synthetic data generation for verilog code models with correct-by-construction non-textual representations and targeted code repair,
M. Liu, Y . Tsai, W. Zhou, and H. Ren, “Craftrtl: High-quality synthetic data generation for verilog code models with correct-by-construction non-textual representations and targeted code repair,” inThe Thirteenth International Conference on Learning Representations, ICLR 2025, Singapore, April 24-28, 2025
2025
-
[22]
Scalertl: Scaling llms with reasoning data and test-time compute for accurate RTL code generation,
C. Deng, Y . Tsai, G. Liu, Z. Yu, and H. Ren, “Scalertl: Scaling llms with reasoning data and test-time compute for accurate RTL code generation,” CoRR, 2025
2025
-
[23]
RTL++: graph-enhanced LLM for RTL code generation,
M. Akyash, K. Z. Azar, and H. M. Kamali, “RTL++: graph-enhanced LLM for RTL code generation,”CoRR, 2025
2025
-
[24]
Rtlfixer: Automatically fixing RTL syntax errors with large language models,
Y . Tsai, M. Liu, and H. Ren, “Rtlfixer: Automatically fixing RTL syntax errors with large language models,”CoRR, 2023
2023
-
[25]
Towards llm-powered verilog RTL assistant: Self-verification and self-correction,
H. Huang, Z. Lin, Z. Wang, X. Chen, K. Ding, and J. Zhao, “Towards llm-powered verilog RTL assistant: Self-verification and self-correction,” CoRR, 2024
2024
-
[26]
MAGE: A multi- agent engine for automated RTL code generation,
Y . Zhao, H. Zhang, H. Huang, Z. Yu, and J. Zhao, “MAGE: A multi- agent engine for automated RTL code generation,”CoRR, 2024
2024
-
[27]
Understanding and mitigating errors of llm-generated rtl code,
J. Zhang, C. Liu, and H. Li, “Understanding and mitigating errors of llm-generated rtl code,”arXiv preprint arXiv:2508.05266, 2025
-
[28]
Spec2rtl- agent: Automated hardware code generation from complex specifications using llm agent systems,
Z. Yu, M. Liu, M. Zimmer, Y . Celine, Y . Liu, and H. Ren, “Spec2rtl- agent: Automated hardware code generation from complex specifications using llm agent systems,” in2025 IEEE International Conference on LLM-Aided Design (ICLAD). IEEE, 2025, pp. 37–43
2025
-
[29]
Autobench: Automatic testbench generation and evaluation using llms for hdl design,
R. Qiu, G. L. Zhang, R. Drechsler, U. Schlichtmann, and B. Li, “Autobench: Automatic testbench generation and evaluation using llms for hdl design,” inProceedings of the 2024 ACM/IEEE International Symposium on Machine Learning for CAD, 2024, pp. 1–10
2024
-
[30]
Correctbench: Automatic testbench generation with functional self-correction using llms for hdl design,
——, “Correctbench: Automatic testbench generation with functional self-correction using llms for hdl design,” in2025 Design, Automation & Test in Europe Conference (DATE). IEEE, 2025, pp. 1–7
2025
-
[31]
Llm-aided testbench generation and bug detection for finite-state ma- chines,
J. Bhandari, J. Knechtel, R. Narayanaswamy, S. Garg, and R. Karri, “Llm-aided testbench generation and bug detection for finite-state ma- chines,”CoRR, 2024
2024
-
[32]
Promptv: Leveraging llm-powered multi-agent prompting for high-quality verilog generation,
Z. Mi, R. Zheng, H. Zhong, Y . Sun, and S. Huang, “Promptv: Leveraging llm-powered multi-agent prompting for high-quality verilog generation,” CoRR, 2024
2024
-
[33]
Using reverse semantic traceability for quality control in agile msf-based projects,
K. Zhereb, V . Pavlov, A. Doroshenko, and V . Sergienko, “Using reverse semantic traceability for quality control in agile msf-based projects,” in 4th Software Engineering Conference, 2008
2008
-
[34]
A feature based methodology for variable requirements reverse engineering,
A. Alhamwieh and S. Ghoul, “A feature based methodology for variable requirements reverse engineering,”American Journal of Software Engineering and Applications, vol. 8, no. 1, p. 1, 2019. [Online]. Available: http://dx.doi.org/10.11648/j.ajsea.20190801.11
-
[35]
Unifying requirements and code: an example,
A. Naumchev, B. Meyer, and V . Rivera, “Unifying requirements and code: an example,”CoRR, 2016
2016
-
[36]
A. A. N. Ponnusamy, “Bridging llm-generated code and requirements: Reverse generation technique and sbc metric for developer insights,” arXiv preprint arXiv:2502.07835, 2025
-
[37]
Nl-debugging: Exploiting natural language as an intermediate representation for code debugging,
W. Zhang, Q. Li, X. Dai, J. Chen, K. Du, W. Zhang, W. Liu, Y . Wang, R. Tang, and Y . Yu, “Nl-debugging: Exploiting natural language as an intermediate representation for code debugging,”CoRR, 2025
2025
-
[38]
VerilogEval: evaluating large language models for verilog code generation,
M. Liu, N. Pinckney, B. Khailany, and H. Ren, “VerilogEval: evaluating large language models for verilog code generation,” in2023 IEEE/ACM International Conference on Computer-Aided Design (ICCAD), 2023
2023
-
[39]
Revisiting verilogeval: Newer llms, in-context learning, and specification-to-rtl tasks,
N. R. Pinckney, C. Batten, M. Liu, H. Ren, and B. Khailany, “Revisiting verilogeval: Newer llms, in-context learning, and specification-to-rtl tasks,”CoRR, 2024
2024
-
[40]
Itertl: An iterative framework for fine-tuning llms for rtl code generation,
P. Wu, N. Guo, X. Xiao, W. Li, X. Ye, and D. Fan, “Itertl: An iterative framework for fine-tuning llms for rtl code generation,” in2025 IEEE International Symposium on Circuits and Systems (ISCAS). IEEE, 2025, pp. 1–5
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.