SteadyDancer: Harmonized and Coherent Human Image Animation with First-Frame Preservation
Pith reviewed 2026-05-21 18:16 UTC · model grok-4.3
The pith
SteadyDancer is the first framework to robustly preserve first-frame identity in human image animation through a reconciled Image-to-Video approach.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
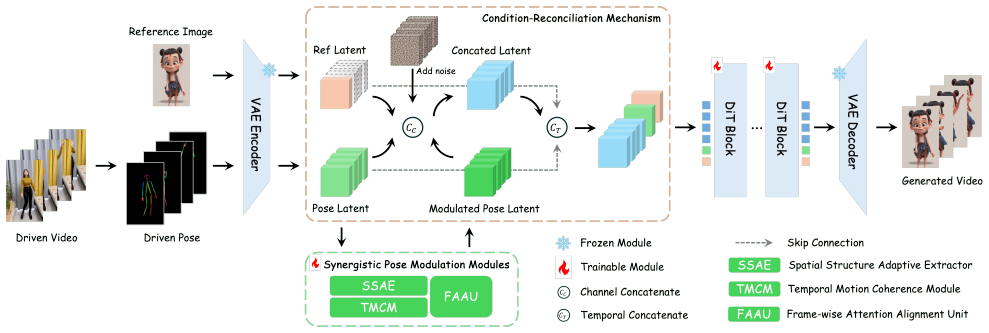
SteadyDancer is an Image-to-Video (I2V) paradigm-based framework that achieves harmonized and coherent animation and is the first to ensure first-frame preservation robustly. Firstly, it proposes a Condition-Reconciliation Mechanism to harmonize the two conflicting conditions, enabling precise control without sacrificing fidelity. Secondly, it designs Synergistic Pose Modulation Modules to generate an adaptive and coherent pose representation that is highly compatible with the reference image. Finally, it employs a Staged Decoupled-Objective Training Pipeline that hierarchically optimizes the model for motion fidelity, visual quality, and temporal coherence.
What carries the argument
Condition-Reconciliation Mechanism that harmonizes conflicting reference and motion conditions in the I2V framework
If this is right
- Achieves state-of-the-art performance in both appearance fidelity and motion control
- Requires significantly fewer training resources than comparable methods
- Produces harmonized and coherent results without identity drift or visual artifacts
- Enables robust first-frame preservation for the first time in this setting
Where Pith is reading between the lines
- Similar reconciliation techniques could be adapted for other conditional generation tasks like text-guided video editing.
- The reduced training resources might lower the barrier for creating custom animation models in smaller research groups.
- Extending the staged training to include more objectives could further improve long-term temporal coherence in generated videos.
Load-bearing premise
The Condition-Reconciliation Mechanism can harmonize the conflicting reference and motion conditions without introducing new visual artifacts or losing motion precision.
What would settle it
Videos generated by the model on challenging inputs with large spatio-temporal misalignments between the reference image and motion sequence still exhibiting identity drift or artifacts would falsify the claim.
Figures














read the original abstract
Preserving first-frame identity while ensuring precise motion control is a fundamental challenge in human image animation. The Image-to-Motion Binding process of the dominant Reference-to-Video (R2V) paradigm overlooks critical spatio-temporal misalignments common in real-world applications, leading to failures such as identity drift and visual artifacts. We introduce SteadyDancer, an Image-to-Video (I2V) paradigm-based framework that achieves harmonized and coherent animation and is the first to ensure first-frame preservation robustly. Firstly, we propose a Condition-Reconciliation Mechanism to harmonize the two conflicting conditions, enabling precise control without sacrificing fidelity. Secondly, we design Synergistic Pose Modulation Modules to generate an adaptive and coherent pose representation that is highly compatible with the reference image. Finally, we employ a Staged Decoupled-Objective Training Pipeline that hierarchically optimizes the model for motion fidelity, visual quality, and temporal coherence. Experiments demonstrate that SteadyDancer achieves state-of-the-art performance in both appearance fidelity and motion control, while requiring significantly fewer training resources than comparable methods. The model has been publicly released at \url{https://mcg-nju.github.io/steadydancer-web}.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces SteadyDancer, an Image-to-Video (I2V) paradigm framework for human image animation that addresses first-frame identity preservation and motion control. It proposes three main components: a Condition-Reconciliation Mechanism to harmonize conflicting reference and motion conditions, Synergistic Pose Modulation Modules for adaptive pose representations compatible with the reference image, and a Staged Decoupled-Objective Training Pipeline for hierarchical optimization of motion fidelity, visual quality, and temporal coherence. The work claims state-of-the-art performance in appearance fidelity and motion control with significantly fewer training resources than prior Reference-to-Video (R2V) methods, and releases the model publicly.
Significance. If the central claims hold, the shift to an I2V paradigm with explicit reconciliation of conditions could meaningfully improve robustness in human animation tasks, particularly for real-world scenarios with spatio-temporal misalignments. The public model release supports reproducibility and further research in the field.
major comments (2)
- [§3.2] §3.2 (Condition-Reconciliation Mechanism): The description of how the mechanism resolves reference-motion conflicts (e.g., via feature fusion or attention) does not include an explicit ablation or analysis isolating its performance under large initial pose/position offsets; this is load-bearing for the robustness claim over R2V baselines and the assertion of no new artifacts or identity drift.
- [Experiments section] Experiments section, Table 1 and Figure 4: Quantitative comparisons to baselines are presented, but the manuscript does not report error bars, statistical significance tests, or detailed dataset statistics (e.g., number of sequences with large misalignments), making it difficult to verify the SOTA claims in fidelity and control.
minor comments (2)
- [Abstract] The abstract states 'significantly fewer training resources' without specifying metrics such as GPU-hours or parameter counts relative to the compared methods.
- [§3.3] Notation for the Synergistic Pose Modulation Modules could be clarified with an equation showing how the adaptive pose representation is computed from the reference image.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed feedback. The comments highlight important aspects for strengthening the presentation of our robustness claims and experimental rigor. We address each point below and will incorporate the suggested additions in the revised manuscript.
read point-by-point responses
-
Referee: [§3.2] §3.2 (Condition-Reconciliation Mechanism): The description of how the mechanism resolves reference-motion conflicts (e.g., via feature fusion or attention) does not include an explicit ablation or analysis isolating its performance under large initial pose/position offsets; this is load-bearing for the robustness claim over R2V baselines and the assertion of no new artifacts or identity drift.
Authors: We agree that an explicit ablation isolating the Condition-Reconciliation Mechanism under large initial pose/position offsets would provide stronger evidence for our robustness claims and the absence of new artifacts or identity drift. In the revision, we will add a targeted ablation study on a subset of test sequences exhibiting significant misalignments. This will compare the full model against an ablated variant without the reconciliation module, reporting metrics on appearance fidelity and motion control to directly support the mechanism's contribution. revision: yes
-
Referee: Experiments section, Table 1 and Figure 4: Quantitative comparisons to baselines are presented, but the manuscript does not report error bars, statistical significance tests, or detailed dataset statistics (e.g., number of sequences with large misalignments), making it difficult to verify the SOTA claims in fidelity and control.
Authors: We concur that including error bars, statistical significance tests, and more granular dataset statistics would improve the verifiability of our SOTA claims. We will update the Experiments section and Table 1 to report error bars (e.g., standard deviation across multiple runs), include results of statistical significance tests (such as paired t-tests against baselines), and add details on the test set composition, specifically the count and percentage of sequences with large misalignments. These changes will be reflected in the revised manuscript. revision: yes
Circularity Check
No significant circularity; new mechanisms presented as independent contributions
full rationale
The paper proposes a new I2V paradigm framework with three explicitly introduced components: Condition-Reconciliation Mechanism, Synergistic Pose Modulation Modules, and Staged Decoupled-Objective Training Pipeline. These are described as novel designs to address spatio-temporal misalignments and first-frame preservation, without any equations, fitted parameters, or self-citations that reduce the claimed results to inputs by construction. The abstract and overview frame the improvements as arising from these architectural additions and a staged training pipeline, supported by experiments, rather than re-deriving prior quantities. No load-bearing step equates a prediction or uniqueness claim to a self-defined or previously fitted element.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We propose a Condition-Reconciliation Mechanism to harmonize the two conflicting conditions... Synergistic Pose Modulation Modules... Staged Decoupled-Objective Training Pipeline
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
element-wise addition... channel-wise concatenation... LoRA-based fine-tuning
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Stable Video Diffusion: Scaling Latent Video Diffusion Models to Large Datasets
Andreas Blattmann, Tim Dockhorn, Sumith Kulal, Daniel Mendelevitch, Maciej Kilian, Dominik Lorenz, Yam Levi, Zion English, Vikram V oleti, Adam Letts, Varun Jam- pani, and Robin Rombach. Stable video diffusion: Scal- ing latent video diffusion models to large datasets.CoRR, abs/2311.15127, 2023. 3
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[2]
Video generation models as world simulators.OpenAI Blog, 1(8):1, 2024
Tim Brooks, Bill Peebles, Connor Holmes, Will DePue, Yufei Guo, Li Jing, David Schnurr, Joe Taylor, Troy Luh- man, Eric Luhman, et al. Video generation models as world simulators.OpenAI Blog, 1(8):1, 2024. 3
work page 2024
-
[3]
X-dyna: Ex- pressive dynamic human image animation
Di Chang, Hongyi Xu, You Xie, Yipeng Gao, Zhengfei Kuang, Shengqu Cai, Chenxu Zhang, Guoxian Song, Chao Wang, Yichun Shi, Zeyuan Chen, Shijie Zhou, Linjie Luo, Gordon Wetzstein, and Mohammad Soleymani. X-dyna: Ex- pressive dynamic human image animation. InIEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2025, Nashville, TN, USA, June 1...
work page 2025
-
[4]
VideoCrafter1: Open Diffusion Models for High-Quality Video Generation
Haoxin Chen, Menghan Xia, Yingqing He, Yong Zhang, Xiaodong Cun, Shaoshu Yang, Jinbo Xing, Yaofang Liu, Qifeng Chen, Xintao Wang, Chao Weng, and Ying Shan. Videocrafter1: Open diffusion models for high-quality video generation.CoRR, abs/2310.19512, 2023. 3
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[5]
Gang Cheng, Xin Gao, Li Hu, Siqi Hu, Mingyang Huang, Chaonan Ji, Ju Li, Dechao Meng, Jinwei Qi, Penchong Qiao, Zhen Shen, Yafei Song, Ke Sun, Linrui Tian, Feng Wang, Guangyuan Wang, Qi Wang, Zhongjian Wang, Jiayu Xiao, Sheng Xu, Bang Zhang, Peng Zhang, Xindi Zhang, Zhe Zhang, Jingren Zhou, and Lian Zhuo. Wan-animate: Uni- fied character animation and repl...
-
[6]
Martin Heusel, Hubert Ramsauer, Thomas Unterthiner, Bernhard Nessler, and Sepp Hochreiter. Gans trained by a two time-scale update rule converge to a local nash equilib- rium.Advances in neural information processing systems, 30, 2017. 7
work page 2017
-
[7]
Image quality metrics: Psnr vs
Alain Hore and Djemel Ziou. Image quality metrics: Psnr vs. ssim. In2010 20th international conference on pattern recognition, pages 2366–2369. IEEE, 2010. 7
work page 2010
-
[8]
Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen- Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen
Edward J. Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen- Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. Lora: Low-rank adaptation of large language models. In The Tenth International Conference on Learning Represen- tations, ICLR 2022, Virtual Event, April 25-29, 2022. Open- Review.net, 2022. 5
work page 2022
-
[9]
Animate anyone: Consistent and controllable image- to-video synthesis for character animation
Li Hu. Animate anyone: Consistent and controllable image- to-video synthesis for character animation. InIEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2024, Seattle, WA, USA, June 16-22, 2024, pages 8153–8163. IEEE, 2024. 3, 6
work page 2024
-
[10]
Li Hu, Guangyuan Wang, Zhen Shen, Xin Gao, Dechao Meng, Lian Zhuo, Peng Zhang, Bang Zhang, and Liefeng Bo. Animate anyone 2: High-fidelity character image animation with environment affordance.arXiv preprint arXiv:2502.06145, 2025. 3
-
[11]
VBench: Com- prehensive benchmark suite for video generative models
Ziqi Huang, Yinan He, Jiashuo Yu, Fan Zhang, Chenyang Si, Yuming Jiang, Yuanhan Zhang, Tianxing Wu, Qingyang Jin, Nattapol Chanpaisit, Yaohui Wang, Xinyuan Chen, Limin Wang, Dahua Lin, Yu Qiao, and Ziwei Liu. VBench: Com- prehensive benchmark suite for video generative models. In Proceedings of the IEEE/CVF Conference on Computer Vi- sion and Pattern Reco...
work page 2024
-
[12]
Ziqi Huang, Fan Zhang, Xiaojie Xu, Yinan He, Jiashuo Yu, Ziyue Dong, Qianli Ma, Nattapol Chanpaisit, Chenyang Si, Yuming Jiang, Yaohui Wang, Xinyuan Chen, Ying- Cong Chen, Limin Wang, Dahua Lin, Yu Qiao, and Zi- wei Liu. Vbench++: Comprehensive and versatile bench- mark suite for video generative models.arXiv preprint arXiv:2411.13503, 2024. 7
-
[13]
Learning high fi- delity depths of dressed humans by watching social media dance videos
Yasamin Jafarian and Hyun Soo Park. Learning high fi- delity depths of dressed humans by watching social media dance videos. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 12753– 12762, 2021. 6, 7
work page 2021
-
[14]
Vace: All-in-one video creation and editing
Zeyinzi Jiang, Zhen Han, Chaojie Mao, Jingfeng Zhang, Yulin Pan, and Yu Liu. Vace: All-in-one video creation and editing. InProceedings of the IEEE/CVF International Con- ference on Computer Vision, pages 17191–17202, 2025. 2, 3, 6
work page 2025
-
[15]
Diederik P. Kingma and Max Welling. Auto-encoding vari- ational bayes. In2nd International Conference on Learning Representations, ICLR 2014, Banff, AB, Canada, April 14- 16, 2014, Conference Track Proceedings, 2014. 3
work page 2014
-
[16]
HunyuanVideo: A Systematic Framework For Large Video Generative Models
Weijie Kong, Qi Tian, Zijian Zhang, Rox Min, Zuozhuo Dai, Jin Zhou, Jiangfeng Xiong, Xin Li, Bo Wu, Jianwei Zhang, Kathrina Wu, Qin Lin, Junkun Yuan, Yanxin Long, Aladdin Wang, Andong Wang, Changlin Li, Duojun Huang, Fang Yang, Hao Tan, Hongmei Wang, Jacob Song, Jiawang Bai, Jianbing Wu, Jinbao Xue, Joey Wang, Kai Wang, Mengyang Liu, Pengyu Li, Shuai Li, ...
work page internal anchor Pith review Pith/arXiv arXiv
-
[17]
Dreamactor-m1: Holistic, expres- sive and robust human image animation with hybrid guid- ance
Yuxuan Luo, Zhengkun Rong, Lizhen Wang, Longhao Zhang, and Tianshu Hu. Dreamactor-m1: Holistic, expres- sive and robust human image animation with hybrid guid- ance. InProceedings of the IEEE/CVF International Con- ference on Computer Vision, pages 11036–11046, 2025. 3, 6
work page 2025
-
[18]
MIMO: controllable character video synthesis with spa- tial decomposed modeling
Yifang Men, Yuan Yao, Miaomiao Cui, and Liefeng Bo. MIMO: controllable character video synthesis with spa- tial decomposed modeling. InIEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2025, Nashville, TN, USA, June 11-15, 2025, pages 21181–21191. Computer Vision Foundation / IEEE, 2025. 6
work page 2025
-
[19]
Scalable diffusion models with transformers
William Peebles and Saining Xie. Scalable diffusion models with transformers. InIEEE/CVF International Conference on Computer Vision, ICCV 2023, Paris, France, October 1- 6, 2023, pages 4172–4182. IEEE, 2023. 3 11
work page 2023
-
[20]
High-resolution image syn- thesis with latent diffusion models
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Bj¨orn Ommer. High-resolution image syn- thesis with latent diffusion models. InIEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2022, New Orleans, LA, USA, June 18-24, 2022, pages 10674– 10685. IEEE, 2022. 3
work page 2022
-
[21]
U-net: Convolutional networks for biomedical image segmentation
Olaf Ronneberger, Philipp Fischer, and Thomas Brox. U-net: Convolutional networks for biomedical image segmentation. InMedical Image Computing and Computer-Assisted Inter- vention - MICCAI 2015 - 18th International Conference Mu- nich, Germany, October 5 - 9, 2015, Proceedings, Part III, pages 234–241. Springer, 2015. 3
work page 2015
-
[22]
Aliaksandr Siarohin, St ´ephane Lathuili`ere, Sergey Tulyakov, Elisa Ricci, and Nicu Sebe. First order motion model for image animation.Advances in neural information processing systems, 32, 2019. 3
work page 2019
-
[23]
Motion representations for ar- ticulated animation
Aliaksandr Siarohin, Oliver J Woodford, Jian Ren, Menglei Chai, and Sergey Tulyakov. Motion representations for ar- ticulated animation. InProceedings of the IEEE/CVF con- ference on computer vision and pattern recognition, pages 13653–13662, 2021. 3
work page 2021
-
[24]
Guoxian Song, Hongyi Xu, Xiaochen Zhao, You Xie, Tianpei Gu, Zenan Li, Chenxu Zhang, and Linjie Luo. X-unimotion: Animating human images with expres- sive, unified and identity-agnostic motion latents.CoRR, abs/2508.09383, 2025. 6
-
[25]
Animate-x: Universal character image ani- mation with enhanced motion representation
Shuai Tan, Biao Gong, Xiang Wang, Shiwei Zhang, Dandan Zheng, Ruobing Zheng, Kecheng Zheng, Jingdong Chen, and Ming Yang. Animate-x: Universal character image ani- mation with enhanced motion representation. InThe Thir- teenth International Conference on Learning Representa- tions, ICLR 2025, Singapore, April 24-28, 2025. OpenRe- view.net, 2025. 6
work page 2025
-
[26]
Stableanimator: High- quality identity-preserving human image animation
Shuyuan Tu, Zhen Xing, Xintong Han, Zhi-Qi Cheng, Qi Dai, Chong Luo, and Zuxuan Wu. Stableanimator: High- quality identity-preserving human image animation. InPro- ceedings of the Computer Vision and Pattern Recognition Conference, pages 21096–21106, 2025. 3, 6
work page 2025
-
[27]
Towards Accurate Generative Models of Video: A New Metric & Challenges
Thomas Unterthiner, Sjoerd Van Steenkiste, Karol Kurach, Raphael Marinier, Marcin Michalski, and Sylvain Gelly. To- wards accurate generative models of video: A new metric & challenges.arXiv preprint arXiv:1812.01717, 2018. 7
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[28]
Wan: Open and Advanced Large-Scale Video Generative Models
Ang Wang, Baole Ai, Bin Wen, Chaojie Mao, Chen-Wei Xie, Di Chen, Feiwu Yu, Haiming Zhao, Jianxiao Yang, Jianyuan Zeng, Jiayu Wang, Jingfeng Zhang, Jingren Zhou, Jinkai Wang, Jixuan Chen, Kai Zhu, Kang Zhao, Keyu Yan, Lianghua Huang, Xiaofeng Meng, Ningyi Zhang, Pandeng Li, Pingyu Wu, Ruihang Chu, Ruili Feng, Shiwei Zhang, Siyang Sun, Tao Fang, Tianxing Wa...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[29]
Disco: Disentangled control for realistic human dance generation
Tan Wang, Linjie Li, Kevin Lin, Yuanhao Zhai, Chung- Ching Lin, Zhengyuan Yang, Hanwang Zhang, Zicheng Liu, and Lijuan Wang. Disco: Disentangled control for realistic human dance generation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 9326–9336, 2024. 3, 6
work page 2024
-
[30]
Xiang Wang, Shiwei Zhang, Longxiang Tang, Yingya Zhang, Changxin Gao, Yuehuan Wang, and Nong Sang. Unianimate-dit: Human image animation with large-scale video diffusion transformer.CoRR, abs/2504.11289, 2025. 3, 6
-
[31]
Zhou Wang, Alan C Bovik, Hamid R Sheikh, and Eero P Si- moncelli. Image quality assessment: from error visibility to structural similarity.IEEE transactions on image processing, 13(4):600–612, 2004. 7
work page 2004
-
[32]
Humanvid: Demystifying train- ing data for camera-controllable human image animation
Zhenzhi Wang, Yixuan Li, Yanhong Zeng, Youqing Fang, Yuwei Guo, Wenran Liu, Jing Tan, Kai Chen, Tianfan Xue, Bo Dai, and Dahua Lin. Humanvid: Demystifying train- ing data for camera-controllable human image animation. In Advances in Neural Information Processing Systems 38: An- nual Conference on Neural Information Processing Systems 2024, NeurIPS 2024, V...
work page 2024
-
[33]
Shuolin Xu, Siming Zheng, Ziyi Wang, HC Yu, Jinwei Chen, Huaqi Zhang, Bo Li, and Peng-Tao Jiang. Hypermotion: Dit- based pose-guided human image animation of complex mo- tions.CoRR, abs/2505.22977, 2025. 3, 6
-
[34]
Magicanimate: Temporally consistent human im- age animation using diffusion model
Zhongcong Xu, Jianfeng Zhang, Jun Hao Liew, Hanshu Yan, Jia-Wei Liu, Chenxu Zhang, Jiashi Feng, and Mike Zheng Shou. Magicanimate: Temporally consistent human im- age animation using diffusion model. InIEEE/CVF Con- ference on Computer Vision and Pattern Recognition, CVPR 2024, Seattle, WA, USA, June 16-22, 2024, pages 1481–
work page 2024
-
[35]
Cogvideox: Text-to-video diffusion models with an expert transformer
Zhuoyi Yang, Jiayan Teng, Wendi Zheng, Ming Ding, Shiyu Huang, Jiazheng Xu, Yuanming Yang, Wenyi Hong, Xiao- han Zhang, Guanyu Feng, Da Yin, Yuxuan Zhang, Weihan Wang, Yean Cheng, Bin Xu, Xiaotao Gu, Yuxiao Dong, and Jie Tang. Cogvideox: Text-to-video diffusion models with an expert transformer. InThe Thirteenth International Confer- ence on Learning Repr...
work page 2025
-
[36]
Hauptmann, Ming- Hsuan Yang, Yuan Hao, Irfan Essa, and Lu Jiang
Lijun Yu, Yong Cheng, Kihyuk Sohn, Jos ´e Lezama, Han Zhang, Huiwen Chang, Alexander G. Hauptmann, Ming- Hsuan Yang, Yuan Hao, Irfan Essa, and Lu Jiang. MAGVIT: masked generative video transformer. InIEEE/CVF Confer- ence on Computer Vision and Pattern Recognition, CVPR 2023, Vancouver, BC, Canada, June 17-24, 2023, pages 10459–10469. IEEE, 2023. 3
work page 2023
-
[37]
Adding conditional control to text-to-image diffusion models
Lvmin Zhang, Anyi Rao, and Maneesh Agrawala. Adding conditional control to text-to-image diffusion models. In IEEE/CVF International Conference on Computer Vision, ICCV 2023, Paris, France, October 1-6, 2023, pages 3813–
work page 2023
-
[38]
The unreasonable effectiveness of deep features as a perceptual metric
Richard Zhang, Phillip Isola, Alexei A Efros, Eli Shecht- man, and Oliver Wang. The unreasonable effectiveness of deep features as a perceptual metric. InProceedings of the 12 IEEE conference on computer vision and pattern recogni- tion, pages 586–595, 2018. 7
work page 2018
-
[39]
I2VGen-XL: High-Quality Image-to-Video Synthesis via Cascaded Diffusion Models
Shiwei Zhang, Jiayu Wang, Yingya Zhang, Kang Zhao, Hangjie Yuan, Zhiwu Qing, Xiang Wang, Deli Zhao, and Jin- gren Zhou. I2vgen-xl: High-quality image-to-video synthe- sis via cascaded diffusion models.CoRR, abs/2311.04145,
work page internal anchor Pith review Pith/arXiv arXiv
-
[40]
Flexiact: Towards flexible action control in heterogeneous scenarios
Shiyi Zhang, Junhao Zhuang, Zhaoyang Zhang, Ying Shan, and Yansong Tang. Flexiact: Towards flexible action control in heterogeneous scenarios. InProceedings of the Special Interest Group on Computer Graphics and Interactive Tech- niques Conference Conference Papers, pages 1–11, 2025. 3, 6
work page 2025
-
[41]
Yuang Zhang, Jiaxi Gu, Li-Wen Wang, Han Wang, Junqi Cheng, Yuefeng Zhu, and Fangyuan Zou. Mimicmo- tion: High-quality human motion video generation with confidence-aware pose guidance.CoRR, abs/2406.19680,
-
[42]
Thin-plate spline motion model for image animation
Jian Zhao and Hui Zhang. Thin-plate spline motion model for image animation. InProceedings of the IEEE/CVF con- ference on computer vision and pattern recognition, pages 3657–3666, 2022. 3
work page 2022
-
[43]
Jingkai Zhou, Benzhi Wang, Weihua Chen, Jingqi Bai, Dongyang Li, Aixi Zhang, Hao Xu, Mingyang Yang, and Fan Wang. Realisdance: Equip controllable character anima- tion with realistic hands.arXiv preprint arXiv:2409.06202,
-
[44]
Jingkai Zhou, Yifan Wu, Shikai Li, Min Wei, Chao Fan, Wei- hua Chen, Wei Jiang, and Fan Wang. Realisdance-dit: Sim- ple yet strong baseline towards controllable character anima- tion in the wild.CoRR, abs/2504.14977, 2025. 3, 6, 7
-
[45]
Champ: Controllable and consistent human image an- imation with 3d parametric guidance
Shenhao Zhu, Junming Leo Chen, Zuozhuo Dai, Zilong Dong, Yinghui Xu, Xun Cao, Yao Yao, Hao Zhu, and Siyu Zhu. Champ: Controllable and consistent human image an- imation with 3d parametric guidance. InEuropean Confer- ence on Computer Vision, pages 145–162. Springer, 2024. 3, 6 13 SteadyDancer: Harmonized and Coherent Human Image Animation with First-Frame...
work page 2024
-
[46]
X-Dance Standard benchmarks, such as TikTok and RealisDance, source both the reference image and pose sequence from the same video. This idealized setup fails to reflect the spatio- temporal misalignment challenges prevalent in real-world applications. As shown in Fig. 14, to more robustly eval- uate the model’s generalization capabilities in such scenar-...
-
[47]
Motion Discontinuity Mitigation
Model Details 7.1. Motion Discontinuity Mitigation. As discussed in the main text, to address the abrupt transi- tion between the reference frame and the initial pose frame, we proposePose Simulationto explicitly replicate this dis- continuity within the training data. Specifically, given a smooth training sequence{p 0, p1, . . . , pT }, we first con- str...
-
[48]
1) Domain Gap in Stylized Im- ages
Limitation and Future Work Despite the promising results achieved by SteadyDancer in harmonized and coherent animation, several limitations remain to be addressed. 1) Domain Gap in Stylized Im- ages. While our model delivers visually pleasing and co- herent results for anime reference frames, its performance remains slightly inferior to the exceptional fi...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.