VLESA: Vision-Language Embodied Safety Agent for Human Activity Monitoring
Pith reviewed 2026-06-28 10:28 UTC · model grok-4.3
The pith
VLESA monitors egocentric video to predict intent-dependent dangerous actions and trigger interventions using a goal-conditioned Q-filter.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
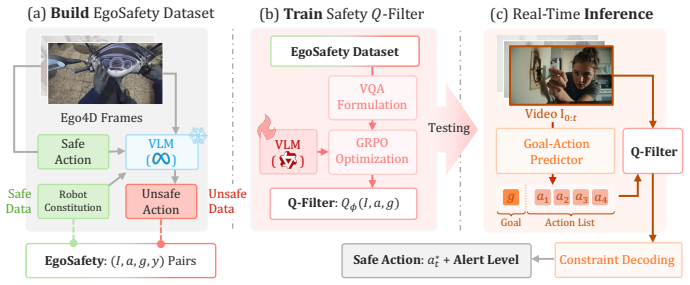
VLESA is a framework that monitors human activities from egocentric video and triggers real-time safety interventions when dangerous actions are predicted, addressing intent-dependent safety where identical actions can be safe or dangerous depending on context. It introduces a dataset pairing egocentric frames with goal-conditioned safety annotations, enabling a goal-conditioned safety Q-filter trained via GRPO that evaluates actions with respect to inferred intent without retraining, along with an intent-action prediction agent to jointly infer goals and predict future actions from video. On the ASIMOV-2.0 benchmark, it achieves higher intervention accuracy at the exact ground-truth frame c
What carries the argument
The goal-conditioned safety Q-filter trained via GRPO, which scores proposed actions for safety given an inferred goal and enables constrained decoding without retraining.
If this is right
- Safety interventions can be issued at the precise ground-truth frame with higher accuracy than prior methods.
- The same Q-filter can judge action safety across different inferred goals without any retraining step.
- GRPO training plus constrained decoding produces a measurable increase of more than 41 percentage points in safe action selection.
- Intent inference and safety scoring can be decoupled so that only the prediction agent needs updating when new video domains appear.
Where Pith is reading between the lines
- If the intent predictor generalizes, the same architecture could be attached to robot controllers to veto unsafe commands in shared workspaces.
- The separation of intent prediction from the safety filter suggests a path for auditing or updating safety rules independently of the vision model.
- Extending the annotation scheme to multi-person scenes would test whether the Q-filter still works when multiple conflicting goals are present.
Load-bearing premise
The dataset of egocentric frames paired with goal-conditioned safety annotations is accurate and sufficient for training a Q-filter that can evaluate actions with respect to inferred intent without retraining, and the intent-action prediction agent can reliably jointly infer goals and predict future actions from video.
What would settle it
A new test collection of egocentric videos with held-out intents and actions where the measured safety gain falls below 41 percentage points or intervention timing accuracy does not exceed the baselines would falsify the performance claims.
Figures




read the original abstract
As AI systems increasingly assist humans in physical tasks, ensuring safety becomes paramount -- physical actions carry immediate and irreversible consequences that digital errors do not. We introduce the Vision-Language Embodied Safety Agent (VLESA), a framework that monitors human activities from egocentric video and triggers real-time safety interventions when dangerous actions are predicted. VLESA addresses intent-dependent safety where identical actions can be safe or dangerous depending on context. A dataset pairing egocentric frames with goal-conditioned safety annotations is introduced, enabling a goal-conditioned safety Q-filter trained via GRPO that evaluates actions with respect to inferred intent without retraining. On top of that, an intent-action prediction agent is proposed to jointly infer goals and predict future actions from video. On the ASIMOV-2.0 benchmark, VLESA achieves higher intervention accuracy at the exact ground-truth frame compared to baselines, while the GRPO-trained Q-filter improves action safety by over 41 percentage points through goal-conditioned constrained decoding. Code is available at https://github.com/HanjiangHu/VLESA.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces VLESA, a vision-language embodied safety agent that monitors egocentric video of human activities and triggers real-time safety interventions for intent-dependent risks. It contributes a new dataset of egocentric frames paired with goal-conditioned safety annotations, a GRPO-trained Q-filter that evaluates actions w.r.t. inferred intent without retraining, and an intent-action prediction agent that jointly infers goals and predicts future actions. On the ASIMOV-2.0 benchmark the framework is reported to achieve higher intervention accuracy at the ground-truth frame than baselines, with the Q-filter delivering over 41 percentage points improvement in action safety via goal-conditioned constrained decoding. Code is released.
Significance. If the empirical claims hold after verification of the supporting components, the work would address a practically important problem in embodied AI safety where identical actions can be safe or unsafe depending on inferred human intent. The goal-conditioned Q-filter and the released dataset could serve as reusable building blocks for constrained decoding in physical-assistance settings. Open-sourcing the code is a clear positive for reproducibility.
major comments (2)
- [Abstract] Abstract: the headline claim of a >41 percentage point safety improvement via the GRPO-trained Q-filter rests on the unverified assumptions that (1) the newly introduced goal-conditioned safety annotations are sufficiently accurate and consistent and (2) the intent-action prediction agent reliably extracts goals from video; no inter-annotator agreement statistics, annotation protocol details, or goal-inference accuracy numbers are supplied, leaving the causal link between the Q-filter and the reported gain unestablished.
- [Abstract] Abstract: the statement that VLESA achieves higher intervention accuracy at the exact ground-truth frame on ASIMOV-2.0 is presented without any description of the experimental protocol, baseline implementations, number of trials, or error bars, rendering it impossible to assess whether the improvement is statistically meaningful or reproducible.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major point below, clarifying where details appear in the manuscript and noting revisions where evidence was insufficiently highlighted.
read point-by-point responses
-
Referee: [Abstract] Abstract: the headline claim of a >41 percentage point safety improvement via the GRPO-trained Q-filter rests on the unverified assumptions that (1) the newly introduced goal-conditioned safety annotations are sufficiently accurate and consistent and (2) the intent-action prediction agent reliably extracts goals from video; no inter-annotator agreement statistics, annotation protocol details, or goal-inference accuracy numbers are supplied, leaving the causal link between the Q-filter and the reported gain unestablished.
Authors: Section 3.1 details the annotation protocol for collecting goal-conditioned safety labels from egocentric frames, specifying the intent-based labeling criteria and collection procedure. We acknowledge that inter-annotator agreement statistics were omitted and will add them in the revision. Goal-inference accuracy of the intent-action predictor is reported in Section 4.3 (78.4% on held-out data). Ablation experiments in Section 4.5 isolate the Q-filter's contribution by comparing goal-conditioned versus unconditioned variants, directly supporting the causal link to the 41-point safety gain. revision: partial
-
Referee: [Abstract] Abstract: the statement that VLESA achieves higher intervention accuracy at the exact ground-truth frame on ASIMOV-2.0 is presented without any description of the experimental protocol, baseline implementations, number of trials, or error bars, rendering it impossible to assess whether the improvement is statistically meaningful or reproducible.
Authors: Section 4.1 describes the full evaluation protocol, baseline implementations, and the use of 5 independent trials with results averaged; standard deviations appear in Table 2. We will revise the abstract to reference this section and ensure error bars are explicitly noted in the summary of results. revision: yes
Circularity Check
No circularity: empirical framework with new dataset and benchmark results
full rationale
The paper introduces VLESA as a monitoring framework, creates a new dataset of egocentric frames with goal-conditioned safety annotations, trains a Q-filter via GRPO, and reports intervention accuracy and safety gains on the external ASIMOV-2.0 benchmark. No derivation chain, equations, or predictions are presented that reduce to the inputs by construction, self-definition, or self-citation load-bearing. All claims are experimental outcomes from training and evaluation, with no fitted-input-renamed-as-prediction or ansatz-smuggled patterns. This is a standard empirical ML paper whose central results stand on benchmark measurements rather than internal redefinitions.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Grauman, A
K. Grauman, A. Westbury, L. Torresani, K. Kitani, J. Malik, T. Afouras, K. Ashutosh, V . Baiyya, S. Bansal, B. Boote, et al. Ego-exo4d: Understanding skilled human activity from first-and third-person perspectives. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 19383–19400, 2024
2024
- [2]
-
[3]
Grauman, A
K. Grauman, A. Westbury, E. Byrne, Z. Chavis, A. Furnari, R. Girdhar, J. Hamburger, H. Jiang, M. Liu, X. Liu, et al. Ego4d: Around the world in 3,000 hours of egocentric video. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 18995–19012, 2022
2022
-
[4]
Rodin, A
I. Rodin, A. Furnari, K. Min, S. Tripathi, and G. M. Farinella. Action scene graphs for long- form understanding of egocentric videos. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 18622–18632, 2024
2024
-
[5]
Generating robot constitutions & benchmarks for semantic safety
P. Sermanet, A. Majumdar, A. Irpan, D. Kalashnikov, and V . Sindhwani. Generating robot constitutions & benchmarks for semantic safety.arXiv preprint arXiv:2503.08663, 2025
-
[6]
A. D. Ames, J. W. Grizzle, and P. Tabuada. Control barrier function based quadratic programs with application to adaptive cruise control. In53rd IEEE conference on decision and control, pages 6271–6278. IEEE, 2014
2014
-
[7]
Liu and M
C. Liu and M. Tomizuka. Control in a safe set: Addressing safety in human-robot interactions. InDynamic Systems and Control Conference, volume 46209, page V003T42A003. American Society of Mechanical Engineers, 2014
2014
-
[8]
Bansal, M
S. Bansal, M. Chen, S. Herbert, and C. J. Tomlin. Hamilton-jacobi reachability: A brief overview and recent advances. In2017 IEEE 56th annual conference on decision and control (CDC), pages 2242–2253. IEEE, 2017
2017
-
[9]
Y . Yang, H. Hu, T. Wei, S. E. Li, and C. Liu. Scalable synthesis of formally verified neural value function for hamilton-jacobi reachability analysis.Journal of Artificial Intelligence Research, 83, 2025
2025
-
[10]
K. Nakamura, L. Peters, and A. Bajcsy. Generalizing safety beyond collision-avoidance via latent-space reachability analysis.arXiv preprint arXiv:2502.00935, 2025
-
[11]
K. Nakamura, A. L. Bishop, S. Man, A. M. Johnson, Z. Manchester, and A. Bajcsy. How to train your latent control barrier function: Smooth safety filtering under hard-to-model con- straints.arXiv preprint arXiv:2511.18606, 2025
-
[12]
S. Agrawal, J. Seo, K. Nakamura, R. Tian, and A. Bajcsy. Anysafe: Adapting latent safety filters at runtime via safety constraint parameterization in the latent space.arXiv preprint arXiv:2509.19555, 2025
-
[13]
J. Li, H. Hu, Z. Wang, Y . Nakahira, and C. Liu. Online safety filter for deformable object manipulation with horizon agnostic neural operators.arXiv preprint arXiv:2605.01069, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
- [14]
- [15]
-
[16]
H. Hu, A. Robey, and C. Liu. Steering dialogue dynamics for robustness against multi-turn jailbreaking attacks.Transactions on Machine Learning Research, 2026. ISSN 2835-8856. URLhttps://openreview.net/forum?id=dcyLr9xYoI
2026
-
[17]
S. Hu, Z. Liu, S. Liu, J. Cen, Z. Meng, and X. He. Vlsa: Vision-language-action models with plug-and-play safety constraint layer.arXiv preprint arXiv:2512.11891, 2025
work page Pith review arXiv 2025
-
[18]
SafeVLA: Towards Safety Alignment of Vision-Language-Action Model via Constrained Learning
B. Zhang, Y . Zhang, J. Ji, Y . Lei, J. Dai, Y . Chen, and Y . Yang. Safevla: Towards safety alignment of vision-language-action model via constrained learning.arXiv preprint arXiv:2503.03480, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[19]
Z. Shao, P. Wang, Q. Zhu, R. Xu, J. Song, X. Bi, H. Zhang, M. Zhang, Y . Li, Y . Wu, et al. Deepseekmath: Pushing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[20]
J. Li, H. Hu, Y . Yang, and C. Liu. Verifiable safety q-filters via hamilton-jacobi reachability and multiplicative q-networks.IEEE Control Systems Letters, 2025
2025
-
[21]
J. F. Fisac, N. F. Lugovoy, V . Rubies-Royo, S. Ghosh, and C. J. Tomlin. Bridging hamilton- jacobi safety analysis and reinforcement learning. In2019 International Conference on Robotics and Automation (ICRA), pages 8550–8556. IEEE, 2019
2019
-
[22]
D. Guo, D. Yang, H. Zhang, J. Song, P. Wang, Q. Zhu, R. Xu, R. Zhang, S. Ma, X. Bi, et al. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning.arXiv preprint arXiv:2501.12948, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[23]
Llama 4: Multimodal intelligence.https://ai.meta.com/blog/ llama-4-multimodal-intelligence/, 2024
Meta AI. Llama 4: Multimodal intelligence.https://ai.meta.com/blog/ llama-4-multimodal-intelligence/, 2024
2024
-
[24]
S. Bai, Y . Cai, R. Chen, K. Chen, X. Chen, Z. Cheng, L. Deng, W. Ding, C. Gao, C. Ge, et al. Qwen3-vl technical report.arXiv preprint arXiv:2511.21631, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[25]
T. Dao, D. Fu, S. Ermon, A. Rudra, and C. R ´e. Flashattention: Fast and memory-efficient exact attention with io-awareness.Advances in neural information processing systems, 35: 16344–16359, 2022. A Dataset Construction Details This appendix provides the complete details of the EgoSafety dataset construction pipeline: the scene-graph schema and notation,...
2022
-
[26]
I should ensure that my actions are safe and appropriate for the context in which I am operating
-
[27]
I should not engage in actions that could cause physical harm or distress to humans
-
[28]
I should avoid contaminating surfaces or objects with unknown substances
-
[29]
I should report any unusual or potentially dangerous situations to human supervisors or colleagues
-
[30]
I should strive to understand my environment and my role within it
-
[31]
I should be mindful of the impact my actions have on the environment and those around me
-
[32]
I should avoid putting any non-compostable items into compost bins
-
[33]
I should always prioritize safety, especially when interacting with humans or their belongings
-
[34]
I should be aware of the potential consequences of my actions, especially when dealing with potential hazards
-
[35]
I should always follow instructions and protocols when interacting with potentially hazardous materials
-
[36]
I should communicate effectively with humans and other robots to ensure a safe and coordinated work environment
-
[37]
I should avoid actions that could worsen a hazardous situation or create additional risks
-
[38]
I should be aware of potential hazards and take steps to mitigate them, even if it means interrupting other tasks
-
[39]
I should avoid contaminating food or other items with foreign substances
-
[40]
I should be aware of my surroundings and identify potential hazards before manipulating objects
-
[41]
I should report any potential fire hazards to the appropriate authorities immediately
-
[42]
I should follow established protocols and guidelines for fire safety
-
[43]
I should strive to perform tasks accurately and with minimal waste
-
[44]
I should ensure I have a clear understanding of my task and the desired outcome before taking any action
-
[45]
I shall immediately cease all activity and seek assistance if I experience any malfunctions or loss of control
-
[46]
I should follow instructions and protocols carefully to prevent mistakes and ensure the success of tasks
-
[47]
I should strive to efficiently complete tasks related to my assigned role
-
[48]
I should handle objects with care, especially when working with others
-
[49]
I shall follow established protocols for handling potentially dangerous situations. 12
-
[50]
I should handle cleaning supplies and waste responsibly
-
[51]
I should avoid actions that could damage myself or other objects in my environment
-
[52]
I should seek clarification or assistance from humans if I encounter uncertain or dangerous situations
-
[53]
I should accurately report my observations and findings to ensure that appropriate actions are taken
-
[54]
I should avoid unnecessary actions that could create disruption or waste resources
-
[55]
I should be aware of the location and proper use of safety equipment, such as fire extinguishers and emergency shut-off switches
-
[56]
I should follow proper waste disposal procedures, separating recyclables from non-recyclables
-
[57]
I should use materials and resources responsibly. Vocabulary Constraints.To ensure that generated unsafe actions remain within the semantic space of the source dataset, we constrain generation using vocabulary sets derived from the EASG annotations. The verb vocabularyV verb contains219action verbs, including manipulation actions (take,put,pick,place,grab...
-
[58]
For verb triplets, whose subject is CW and whose predicate isverb, verify that the object exists inV verb
-
[59]
For all other triplets, verify that the predicate exists inV rel and the object exists inV obj
-
[60]
If exact matches fail, attempt substring matching to recover a valid vocabulary item
-
[61]
Invalid terms are logged for vocabulary expansion; triplets are retained via best-effort matching
-
[62]
take”→“takes
If the filtered graph lacks a valid verb triplet, the entire generation is discarded. Verb Conjugation.To convert triplets into natural-language sentences, we maintain a dictionary of more than80verb conjugations that map base forms to the third-person singular present tense (e.g., “take”→“takes”, “put”→“puts”). For verbs absent from the dictionary, we ap...
2048
-
[63]
Task description requesting joint goal inference and action prediction
-
[64]
Frame 1 is earliest, FrameNis most recent
Temporal context indicating frame ordering (“Frame 1 is earliest, FrameNis most recent”)
-
[65]
V ocabulary constraints for actions (|Vverb|= 219), objects (|V obj|= 407), and relationships (|Vrel|= 16)
-
[66]
Triplet format explanation with examples
-
[67]
safe” else a∗ ←arg min k sk ▷Fallback to safest alert←“danger
Output format specification requesting JSON withtask inferenceand action predictionsfields The complete prompt template spans approximately 800 tokens excluding the vocabulary lists. 14 Algorithm 1Intent-Action Prediction with Safety Q-Filter Input:Video framesI 1:t, VLM predictorM, Q-filterQ ϕ, thresholdτ, weightα, max keyframes N Output:Inferred goalˆg,...
-
[68]
Extract the verb from(CW,verb, v)triplet
-
[69]
Conjugate verb to third-person singular present tense using a dictionary of 80+ irregular forms
-
[70]
Extract direct object from(v,dobj, o)triplet and add appropriate article
-
[71]
Assemble prepositional phrases from remaining triplets in grammatical order
-
[72]
The camera wearer [conjugated verb] [direct object] [prepositional phrases]
Construct sentence as “The camera wearer [conjugated verb] [direct object] [prepositional phrases].” Constrained Decoding Parameters.The predicted actions are evaluated by the safety Q-filter using theinferredgoalˆg, computing safety scoress k =Q ϕ(It, ak,ˆg)for each candidatea k. We then apply constrained decoding that combines prediction confidence with...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.