ProbeScale: Probing Analysis to Optimize Neural Scaling Laws for Efficient Small Language Model Inference
Pith reviewed 2026-06-28 14:51 UTC · model grok-4.3
The pith
Task-specific probes on layer outputs select subnetworks inside small language models that use 5-10 times fewer parameters while keeping 95-98 percent of original task performance.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
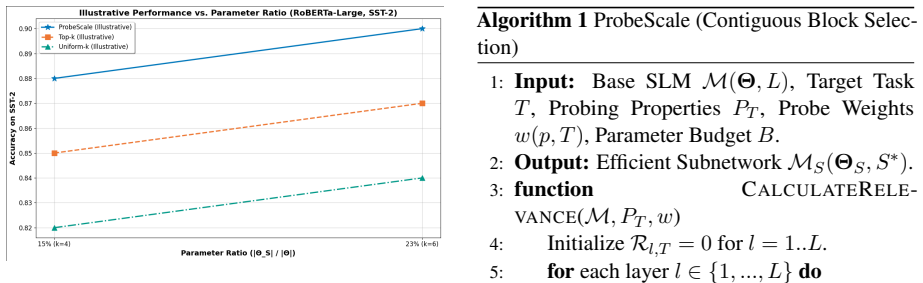
ProbScale formulates subnetwork selection as an optimization problem that maximizes the sum of task-weighted probe accuracies across chosen layers subject to a total parameter limit, and shows that the resulting layer subsets deliver 5-10x compression at 95-98 percent retained performance on the target tasks.
What carries the argument
Lightweight task-specific probes trained on individual layer representations to produce a numerical relevance score for each layer.
If this is right
- Targeted tasks can run on hardware with far lower memory and compute budgets.
- The probe-based selection beats random or uniform layer dropping on the tested models.
- The same procedure applies to different SLM families without retraining the base model.
- Only the chosen layers need to be stored and executed at inference time.
Where Pith is reading between the lines
- The method could be used to decide which layers to update during continued pre-training or task adaptation.
- If the probe scores turn out to be stable across tasks, they might offer a finer-grained view of how model size contributes to capability than total parameter count alone.
- Applying the same selection logic to models trained at different scales could test whether layer importance patterns themselves follow scaling laws.
Load-bearing premise
The accuracy of a small probe that reads only one layer's output is a good stand-in for how much that layer actually matters to the complete model's performance on the same task.
What would settle it
Selecting a subnetwork according to the probe scores and then measuring its actual accuracy on the downstream task; a large gap between the expected and observed accuracy would indicate the proxy is unreliable.
Figures

read the original abstract
Small Language Models (SLMs) offer a balance between capability and computational feasibility. Neural scaling laws inform their optimal training, suggesting that they possess rich internal representations that scale with their size. However, deploying even these SLMs can be challenging under strict resource constraints. Language model probing provides methods for analyzing the linguistic knowledge encoded in a model's internals. We propose ProbScale, a framework that unifies insights from scaling laws and probing to identify parameter-efficient subnetworks within pre-trained SLMs. ProbScale utilizes the high-quality representations of well-scaled SLMs and uses task-specific probes to mathematically quantify the relevance of each layer for target downstream capabilities. This allows selecting subnetworks that optimally trade off performance against parameter size. We formulate the subnetwork selection as finding a layer subset maximizing aggregated, task-weighted probe performance under a parameter budget. Experiments on representative SLMs such as RoBERTa-Large and T5-Base demonstrate that ProbScale identifies subnetworks achieving significant parameter reduction, from 5 to 10 times, while maintaining high performance (95% to 98% of the original SLMs) on targeted tasks, outperforming heuristic baselines.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes ProbScale, a framework that unifies scaling laws and probing to identify parameter-efficient subnetworks in pre-trained SLMs. It quantifies each layer's relevance via accuracy of a lightweight task-specific probe trained on its frozen representations, then selects a layer subset that maximizes the aggregated, task-weighted probe performance subject to a parameter budget. Experiments on RoBERTa-Large and T5-Base are reported to yield 5-10× parameter reductions while retaining 95-98% of original downstream performance, outperforming heuristic baselines.
Significance. If the central claim holds, the work could supply a principled, optimization-based approach to pruning SLMs for efficient inference. The explicit formulation of subnetwork selection as a budgeted maximization of probe scores is a clear strength, as is the attempt to ground layer relevance in task-specific probes rather than heuristics. However, the result's significance is limited by the untested assumption that per-layer probe scores serve as reliable, additive proxies for end-to-end subnetwork capability.
major comments (2)
- [Abstract / Method] Abstract and method formulation: the subnetwork selection objective maximizes the sum of task-weighted probe scores under a parameter budget. This treats probe accuracies as independent and additive contributions. Because removing an upstream layer necessarily alters the input distribution seen by all downstream layers, the probe scores computed on the intact model cannot be guaranteed to predict the performance of the pruned subnetwork. This assumption is load-bearing for the reported 95-98% retention figures.
- [Experiments] Experiments section: the manuscript states that ProbScale 'identifies subnetworks achieving significant parameter reduction... while maintaining high performance (95% to 98%)'. It is unclear whether these percentages reflect measured end-to-end accuracy of the selected subnetworks or merely the probe-predicted scores used in the optimization. Without an explicit comparison of probe-predicted versus realized subnetwork performance (or an ablation that measures actual task accuracy after layer removal), the empirical support for the proxy remains incomplete.
minor comments (2)
- [Abstract] The abstract refers to 'mathematically quantify the relevance of each layer'; the precise mapping from probe accuracy to a relevance score (including any normalization or weighting) should be stated explicitly with an equation in the main text.
- Notation for the parameter budget and task weights is introduced but not given symbols in the provided abstract; consistent mathematical notation would improve readability.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below with clarifications on our methodology and evaluation, and we commit to revisions that will strengthen the presentation of results and assumptions.
read point-by-point responses
-
Referee: [Abstract / Method] Abstract and method formulation: the subnetwork selection objective maximizes the sum of task-weighted probe scores under a parameter budget. This treats probe accuracies as independent and additive contributions. Because removing an upstream layer necessarily alters the input distribution seen by all downstream layers, the probe scores computed on the intact model cannot be guaranteed to predict the performance of the pruned subnetwork. This assumption is load-bearing for the reported 95-98% retention figures.
Authors: We agree that the additive treatment of probe scores is an approximation, since upstream layer removal changes the input distribution to downstream layers and the scores are computed on the intact model. ProbScale is presented as a practical optimization heuristic rather than a provably exact predictor. The manuscript reports realized end-to-end performance of the selected subnetworks; we will revise the method and discussion sections to explicitly acknowledge this modeling assumption and note its empirical effectiveness as validated by the downstream results. revision: yes
-
Referee: [Experiments] Experiments section: the manuscript states that ProbScale 'identifies subnetworks achieving significant parameter reduction... while maintaining high performance (95% to 98%)'. It is unclear whether these percentages reflect measured end-to-end accuracy of the selected subnetworks or merely the probe-predicted scores used in the optimization. Without an explicit comparison of probe-predicted versus realized subnetwork performance (or an ablation that measures actual task accuracy after layer removal), the empirical support for the proxy remains incomplete.
Authors: The 95–98% retention figures refer to measured end-to-end task accuracy obtained after layer selection, subnetwork construction, and direct evaluation on the downstream tasks (i.e., realized performance). We will revise the experiments section to state this explicitly and add a comparison (or ablation table) of probe-predicted scores versus realized task accuracy to provide clearer empirical support for the proxy. revision: yes
Circularity Check
No circularity detected in derivation or selection procedure
full rationale
The paper formulates ProbScale as an explicit optimization: train per-layer task-specific probes on frozen representations, then select a layer subset that maximizes the sum of task-weighted probe accuracies subject to a parameter budget. No equations, fitted parameters, or predictions are shown that reduce by construction to the inputs (e.g., no probe score is both the fitting target and the claimed output). No self-citations, uniqueness theorems, or ansatzes are invoked as load-bearing premises. The method is presented as a direct search procedure whose validity rests on empirical verification against held-out subnetwork performance rather than on any definitional equivalence or self-referential step.
Axiom & Free-Parameter Ledger
free parameters (2)
- parameter budget
- task weights
axioms (1)
- domain assumption Probe performance on a layer's representations is a valid quantitative measure of that layer's relevance to the target task.
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:2001.08361 , year=
Scaling laws for neural language models , author=. arXiv preprint arXiv:2001.08361 , year=
Pith/arXiv arXiv 2001
-
[2]
Proceedings of the 36th International Conference on Neural Information Processing Systems , pages=
Training compute-optimal large language models , author=. Proceedings of the 36th International Conference on Neural Information Processing Systems , pages=
-
[3]
Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies , pages=
It’s Not Just Size That Matters: Small Language Models Are Also Few-Shot Learners , author=. Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies , pages=
2021
-
[4]
Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing , year=
The Power of Scale for Parameter-Efficient Prompt Tuning , author=. Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing , year=
2021
-
[5]
Advances in neural information processing systems , volume=
Language models are few-shot learners , author=. Advances in neural information processing systems , volume=
-
[6]
arXiv preprint arXiv:1510.00149 , year=
Deep compression: Compressing deep neural networks with pruning, trained quantization and huffman coding , author=. arXiv preprint arXiv:1510.00149 , year=
-
[7]
arXiv preprint arXiv:1910.01108 , year=
DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter , author=. arXiv preprint arXiv:1910.01108 , year=
Pith/arXiv arXiv 1910
-
[8]
Computational Linguistics , volume=
Probing classifiers: Promises, shortcomings, and advances , author=. Computational Linguistics , volume=. 2022 , publisher=
2022
-
[9]
A structural probe for finding syntax in word representations , author=. Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers) , pages=
2019
-
[10]
ACL 2019-57th Annual Meeting of the Association for Computational Linguistics , year=
What does BERT learn about the structure of language? , author=. ACL 2019-57th Annual Meeting of the Association for Computational Linguistics , year=
2019
-
[11]
arXiv preprint arXiv:1610.01644 , year=
Understanding intermediate layers using linear classifier probes , author=. arXiv preprint arXiv:1610.01644 , year=
-
[12]
Findings of the Association for Computational Linguistics: EMNLP 2023 , pages=
Give Me the Facts! A Survey on Factual Knowledge Probing in Pre-trained Language Models , author=. Findings of the Association for Computational Linguistics: EMNLP 2023 , pages=
2023
-
[13]
Proceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation (LREC-COLING 2024) , pages=
Decoding Probing: Revealing Internal Linguistic Structures in Neural Language Models Using Minimal Pairs , author=. Proceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation (LREC-COLING 2024) , pages=
2024
-
[14]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Probing linguistic information for logical inference in pre-trained language models , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[15]
Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Probing for predicate argument structures in pretrained language models , author=. Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[16]
International Conference on Learning Representations , year=
The Lottery Ticket Hypothesis: Finding Sparse, Trainable Neural Networks , author=. International Conference on Learning Representations , year=
-
[17]
International Conference on Machine Learning , pages=
Smoothquant: Accurate and efficient post-training quantization for large language models , author=. International Conference on Machine Learning , pages=. 2023 , organization=
2023
-
[18]
Proceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies , pages=
Symbolic Knowledge Distillation: from General Language Models to Commonsense Models , author=. Proceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies , pages=
2022
-
[19]
ACM Transactions on Intelligent Systems and Technology , year=
Survey on knowledge distillation for large language models: methods, evaluation, and application , author=. ACM Transactions on Intelligent Systems and Technology , year=
-
[20]
Advances in neural information processing systems , volume=
Llm-pruner: On the structural pruning of large language models , author=. Advances in neural information processing systems , volume=
-
[21]
Advances in Neural Information Processing Systems , volume=
Slimgpt: Layer-wise structured pruning for large language models , author=. Advances in Neural Information Processing Systems , volume=
-
[22]
Proceedings of the 7th BlackboxNLP Workshop: Analyzing and Interpreting Neural Networks for NLP , pages=
Investigating Layer Importance in Large Language Models , author=. Proceedings of the 7th BlackboxNLP Workshop: Analyzing and Interpreting Neural Networks for NLP , pages=
-
[23]
arXiv preprint arXiv:1907.11692 , year=
Roberta: A robustly optimized bert pretraining approach , author=. arXiv preprint arXiv:1907.11692 , year=
Pith/arXiv arXiv 1907
-
[24]
Journal of machine learning research , volume=
Exploring the limits of transfer learning with a unified text-to-text transformer , author=. Journal of machine learning research , volume=
-
[25]
Proceedings of the 2013 conference on empirical methods in natural language processing , pages=
Recursive deep models for semantic compositionality over a sentiment treebank , author=. Proceedings of the 2013 conference on empirical methods in natural language processing , pages=
2013
-
[26]
Proceedings of the 2018 EMNLP Workshop BlackboxNLP: Analyzing and Interpreting Neural Networks for NLP , year=
GLUE: A Multi-Task Benchmark and Analysis Platform for Natural Language Understanding , author=. Proceedings of the 2018 EMNLP Workshop BlackboxNLP: Analyzing and Interpreting Neural Networks for NLP , year=
2018
-
[27]
Computational Linguistics , volume=
Bias and fairness in large language models: A survey , author=. Computational Linguistics , volume=. 2024 , publisher=
2024
-
[28]
Proceedings of the 2021 ACM conference on fairness, accountability, and transparency , pages=
On the dangers of stochastic parrots: Can language models be too big? , author=. Proceedings of the 2021 ACM conference on fairness, accountability, and transparency , pages=
2021
-
[29]
Advances in Neural Information Processing Systems , volume=
Scaling laws and compute-optimal training beyond fixed training durations , author=. Advances in Neural Information Processing Systems , volume=
-
[30]
International conference on machine learning , pages=
Unified scaling laws for routed language models , author=. International conference on machine learning , pages=. 2022 , organization=
2022
-
[31]
Proceedings of the 3rd Wordplay: When Language Meets Games Workshop (Wordplay 2022). 2022
2022
-
[32]
A Systematic Survey of Text Worlds as Embodied Natural Language Environments
Jansen, Peter. A Systematic Survey of Text Worlds as Embodied Natural Language Environments. Proceedings of the 3rd Wordplay: When Language Meets Games Workshop (Wordplay 2022). 2022. doi:10.18653/v1/2022.wordplay-1.1
-
[33]
A Minimal Computational Improviser Based on Oral Thought
Montfort, Nick and Bartlett Fernandez, Sebastian. A Minimal Computational Improviser Based on Oral Thought. Proceedings of the 3rd Wordplay: When Language Meets Games Workshop (Wordplay 2022). 2022. doi:10.18653/v1/2022.wordplay-1.2
-
[34]
Volum, Ryan and Rao, Sudha and Xu, Michael and DesGarennes, Gabriel and Brockett, Chris and Van Durme, Benjamin and Deng, Olivia and Malhotra, Akanksha and Dolan, Bill. Craft an Iron Sword: Dynamically Generating Interactive Game Characters by Prompting Large Language Models Tuned on Code. Proceedings of the 3rd Wordplay: When Language Meets Games Worksho...
-
[35]
A Sequence Modelling Approach to Question Answering in Text-Based Games
Furman, Gregory and Toledo, Edan and Shock, Jonathan and Buys, Jan. A Sequence Modelling Approach to Question Answering in Text-Based Games. Proceedings of the 3rd Wordplay: When Language Meets Games Workshop (Wordplay 2022). 2022. doi:10.18653/v1/2022.wordplay-1.4
-
[36]
Automatic Exploration of Textual Environments with Language-Conditioned Autotelic Agents
Teodorescu, Laetitia and Yuan, Xingdi and C \^o t \'e , Marc-Alexandre and Oudeyer, Pierre-Yves. Automatic Exploration of Textual Environments with Language-Conditioned Autotelic Agents. Proceedings of the 3rd Wordplay: When Language Meets Games Workshop (Wordplay 2022). 2022. doi:10.18653/v1/2022.wordplay-1.5
-
[37]
Proceedings of the Sixth Workshop on Online Abuse and Harms (WOAH). 2022
2022
-
[38]
Separating Hate Speech and Offensive Language Classes via Adversarial Debiasing
Yuan, Shuzhou and Maronikolakis, Antonis and Sch. Separating Hate Speech and Offensive Language Classes via Adversarial Debiasing. Proceedings of the Sixth Workshop on Online Abuse and Harms (WOAH). 2022. doi:10.18653/v1/2022.woah-1.1
-
[39]
Towards Automatic Generation of Messages Countering Online Hate Speech and Microaggressions
Ashida, Mana and Komachi, Mamoru. Towards Automatic Generation of Messages Countering Online Hate Speech and Microaggressions. Proceedings of the Sixth Workshop on Online Abuse and Harms (WOAH). 2022. doi:10.18653/v1/2022.woah-1.2
-
[40]
G rease V ision: Rewriting the Rules of the Interface
Datta, Siddhartha and Kollnig, Konrad and Shadbolt, Nigel. G rease V ision: Rewriting the Rules of the Interface. Proceedings of the Sixth Workshop on Online Abuse and Harms (WOAH). 2022. doi:10.18653/v1/2022.woah-1.3
-
[41]
Ludwig, Florian and Dolos, Klara and Zesch, Torsten and Hobley, Eleanor. Improving Generalization of Hate Speech Detection Systems to Novel Target Groups via Domain Adaptation. Proceedings of the Sixth Workshop on Online Abuse and Harms (WOAH). 2022. doi:10.18653/v1/2022.woah-1.4
-
[42]
`` Zo Grof ! '' : A Comprehensive Corpus for Offensive and Abusive Language in D utch
Ruitenbeek, Ward and Zwart, Victor and Van Der Noord, Robin and Gnezdilov, Zhenja and Caselli, Tommaso. `` Zo Grof ! '' : A Comprehensive Corpus for Offensive and Abusive Language in D utch. Proceedings of the Sixth Workshop on Online Abuse and Harms (WOAH). 2022. doi:10.18653/v1/2022.woah-1.5
-
[43]
Counter- TWIT : An I talian Corpus for Online Counterspeech in Ecological Contexts
Goffredo, Pierpaolo and Basile, Valerio and Cepollaro, Bianca and Patti, Viviana. Counter- TWIT : An I talian Corpus for Online Counterspeech in Ecological Contexts. Proceedings of the Sixth Workshop on Online Abuse and Harms (WOAH). 2022. doi:10.18653/v1/2022.woah-1.6
-
[44]
S tereo KG : Data-Driven Knowledge Graph Construction For Cultural Knowledge and Stereotypes
Deshpande, Awantee and Ruiter, Dana and Mosbach, Marius and Klakow, Dietrich. S tereo KG : Data-Driven Knowledge Graph Construction For Cultural Knowledge and Stereotypes. Proceedings of the Sixth Workshop on Online Abuse and Harms (WOAH). 2022. doi:10.18653/v1/2022.woah-1.7
-
[45]
Lu, Christina and Jurgens, David. The subtle language of exclusion: Identifying the Toxic Speech of Trans-exclusionary Radical Feminists. Proceedings of the Sixth Workshop on Online Abuse and Harms (WOAH). 2022. doi:10.18653/v1/2022.woah-1.8
-
[46]
Lost in Distillation: A Case Study in Toxicity Modeling
Chvasta, Alyssa and Lees, Alyssa and Sorensen, Jeffrey and Vasserman, Lucy and Goyal, Nitesh. Lost in Distillation: A Case Study in Toxicity Modeling. Proceedings of the Sixth Workshop on Online Abuse and Harms (WOAH). 2022. doi:10.18653/v1/2022.woah-1.9
-
[47]
Cleansing & expanding the HURTLEX (el) with a multidimensional categorization of offensive words
Stamou, Vivian and Alexiou, Iakovi and Klimi, Antigone and Molou, Eleftheria and Saivanidou, Alexandra and Markantonatou, Stella. Cleansing & expanding the HURTLEX (el) with a multidimensional categorization of offensive words. Proceedings of the Sixth Workshop on Online Abuse and Harms (WOAH). 2022. doi:10.18653/v1/2022.woah-1.10
-
[48]
Free speech or Free Hate Speech? Analyzing the Proliferation of Hate Speech in Parler
Israeli, Abraham and Tsur, Oren. Free speech or Free Hate Speech? Analyzing the Proliferation of Hate Speech in Parler. Proceedings of the Sixth Workshop on Online Abuse and Harms (WOAH). 2022. doi:10.18653/v1/2022.woah-1.11
-
[49]
Resources for Multilingual Hate Speech Detection
Arango Monnar, Ayme and Perez, Jorge and Poblete, Barbara and Salda \ n a, Magdalena and Proust, Valentina. Resources for Multilingual Hate Speech Detection. Proceedings of the Sixth Workshop on Online Abuse and Harms (WOAH). 2022. doi:10.18653/v1/2022.woah-1.12
-
[50]
Enriching Abusive Language Detection with Community Context
Saleem, Haji Mohammad and Kurrek, Jana and Ruths, Derek. Enriching Abusive Language Detection with Community Context. Proceedings of the Sixth Workshop on Online Abuse and Harms (WOAH). 2022. doi:10.18653/v1/2022.woah-1.13
-
[51]
DeTox: A Comprehensive Dataset for G erman Offensive Language and Conversation Analysis
Demus, Christoph and Pitz, Jonas and Sch. DeTox: A Comprehensive Dataset for G erman Offensive Language and Conversation Analysis. Proceedings of the Sixth Workshop on Online Abuse and Harms (WOAH). 2022. doi:10.18653/v1/2022.woah-1.14
-
[52]
Multilingual H ate C heck: Functional Tests for Multilingual Hate Speech Detection Models
R. Multilingual H ate C heck: Functional Tests for Multilingual Hate Speech Detection Models. Proceedings of the Sixth Workshop on Online Abuse and Harms (WOAH). 2022. doi:10.18653/v1/2022.woah-1.15
-
[53]
Distributional properties of political dogwhistle representations in S wedish BERT
Hertzberg, Niclas and Cooper, Robin and Lindgren, Elina and R. Distributional properties of political dogwhistle representations in S wedish BERT. Proceedings of the Sixth Workshop on Online Abuse and Harms (WOAH). 2022. doi:10.18653/v1/2022.woah-1.16
-
[54]
Hate Speech Criteria: A Modular Approach to Task-Specific Hate Speech Definitions
Khurana, Urja and Vermeulen, Ivar and Nalisnick, Eric and Van Noorloos, Marloes and Fokkens, Antske. Hate Speech Criteria: A Modular Approach to Task-Specific Hate Speech Definitions. Proceedings of the Sixth Workshop on Online Abuse and Harms (WOAH). 2022. doi:10.18653/v1/2022.woah-1.17
-
[55]
Accounting for Offensive Speech as a Practice of Resistance
Diaz, Mark and Amironesei, Razvan and Weidinger, Laura and Gabriel, Iason. Accounting for Offensive Speech as a Practice of Resistance. Proceedings of the Sixth Workshop on Online Abuse and Harms (WOAH). 2022. doi:10.18653/v1/2022.woah-1.18
-
[56]
Zheng, Joan and Friedman, Scott and Schmer-galunder, Sonja and Magnusson, Ian and Wheelock, Ruta and Gottlieb, Jeremy and Gomez, Diana and Miller, Christopher. Towards a Multi-Entity Aspect-Based Sentiment Analysis for Characterizing Directed Social Regard in Online Messaging. Proceedings of the Sixth Workshop on Online Abuse and Harms (WOAH). 2022. doi:1...
-
[57]
Flexible text generation for counterfactual fairness probing
Fryer, Zee and Axelrod, Vera and Packer, Ben and Beutel, Alex and Chen, Jilin and Webster, Kellie. Flexible text generation for counterfactual fairness probing. Proceedings of the Sixth Workshop on Online Abuse and Harms (WOAH). 2022. doi:10.18653/v1/2022.woah-1.20
-
[58]
Users Hate Blondes: Detecting Sexism in User Comments on Online R omanian News
Moldovan, Andreea and Cs. Users Hate Blondes: Detecting Sexism in User Comments on Online R omanian News. Proceedings of the Sixth Workshop on Online Abuse and Harms (WOAH). 2022. doi:10.18653/v1/2022.woah-1.21
-
[59]
Targeted Identity Group Prediction in Hate Speech Corpora
Sachdeva, Pratik and Barreto, Renata and Von Vacano, Claudia and Kennedy, Chris. Targeted Identity Group Prediction in Hate Speech Corpora. Proceedings of the Sixth Workshop on Online Abuse and Harms (WOAH). 2022. doi:10.18653/v1/2022.woah-1.22
-
[60]
Revisiting Queer Minorities in Lexicons
Ramesh, Krithika and Kumar, Sumeet and Khudabukhsh, Ashiqur. Revisiting Queer Minorities in Lexicons. Proceedings of the Sixth Workshop on Online Abuse and Harms (WOAH). 2022. doi:10.18653/v1/2022.woah-1.23
-
[61]
HATE - ITA : Hate Speech Detection in I talian Social Media Text
Nozza, Debora and Bianchi, Federico and Attanasio, Giuseppe. HATE - ITA : Hate Speech Detection in I talian Social Media Text. Proceedings of the Sixth Workshop on Online Abuse and Harms (WOAH). 2022. doi:10.18653/v1/2022.woah-1.24
-
[62]
Proceedings of the Eighth Workshop on Noisy User-generated Text (W-NUT 2022). 2022
2022
-
[63]
Changes in Tweet Geolocation over Time: A Study with Carmen 2.0
Zhang, Jingyu and DeLucia, Alexandra and Dredze, Mark. Changes in Tweet Geolocation over Time: A Study with Carmen 2.0. Proceedings of the Eighth Workshop on Noisy User-generated Text (W-NUT 2022). 2022
2022
-
[64]
Extracting Mathematical Concepts from Text
Collard, Jacob and de Paiva, Valeria and Fong, Brendan and Subrahmanian, Eswaran. Extracting Mathematical Concepts from Text. Proceedings of the Eighth Workshop on Noisy User-generated Text (W-NUT 2022). 2022
2022
-
[65]
Data-driven Approach to Differentiating between Depression and Dementia from Noisy Speech and Language Data
Ehghaghi, Malikeh and Rudzicz, Frank and Novikova, Jekaterina. Data-driven Approach to Differentiating between Depression and Dementia from Noisy Speech and Language Data. Proceedings of the Eighth Workshop on Noisy User-generated Text (W-NUT 2022). 2022
2022
-
[66]
Cross-Dialect Social Media Dependency Parsing for Social Scientific Entity Attribute Analysis
Eggleston, Chloe and O ' Connor, Brendan. Cross-Dialect Social Media Dependency Parsing for Social Scientific Entity Attribute Analysis. Proceedings of the Eighth Workshop on Noisy User-generated Text (W-NUT 2022). 2022
2022
-
[67]
Impact of Environmental Noise on A lzheimer ' s Disease Detection from Speech: Should You Let a Baby Cry?
Novikova, Jekaterina. Impact of Environmental Noise on A lzheimer ' s Disease Detection from Speech: Should You Let a Baby Cry?. Proceedings of the Eighth Workshop on Noisy User-generated Text (W-NUT 2022). 2022
2022
-
[68]
Exploring Multimodal Features and Fusion Strategies for Analyzing Disaster Tweets
Pranesh, Raj. Exploring Multimodal Features and Fusion Strategies for Analyzing Disaster Tweets. Proceedings of the Eighth Workshop on Noisy User-generated Text (W-NUT 2022). 2022
2022
-
[69]
NTULM : Enriching Social Media Text Representations with Non-Textual Units
Li, Jinning and Mishra, Shubhanshu and El-Kishky, Ahmed and Mehta, Sneha and Kulkarni, Vivek. NTULM : Enriching Social Media Text Representations with Non-Textual Units. Proceedings of the Eighth Workshop on Noisy User-generated Text (W-NUT 2022). 2022
2022
-
[70]
Robust Candidate Generation for Entity Linking on Short Social Media Texts
Hebert, Liam and Makki, Raheleh and Mishra, Shubhanshu and Saghir, Hamidreza and Kamath, Anusha and Merhav, Yuval. Robust Candidate Generation for Entity Linking on Short Social Media Texts. Proceedings of the Eighth Workshop on Noisy User-generated Text (W-NUT 2022). 2022
2022
-
[71]
T rans POS : Transformers for Consolidating Different POS Tagset Datasets
Li, Alex and Bankole-Hameed, Ilyas and Singh, Ranadeep and Ng, Gabriel and Gupta, Akshat. T rans POS : Transformers for Consolidating Different POS Tagset Datasets. Proceedings of the Eighth Workshop on Noisy User-generated Text (W-NUT 2022). 2022
2022
-
[72]
An Effective, Performant Named Entity Recognition System for Noisy Business Telephone Conversation Transcripts
Fu, Xue-Yong and Chen, Cheng and Laskar, Md Tahmid Rahman and Tn, Shashi Bhushan and Corston-Oliver, Simon. An Effective, Performant Named Entity Recognition System for Noisy Business Telephone Conversation Transcripts. Proceedings of the Eighth Workshop on Noisy User-generated Text (W-NUT 2022). 2022
2022
-
[73]
Leveraging Semantic and Sentiment Knowledge for User-Generated Text Sentiment Classification
Khan, Jawad and Ahmad, Niaz and Alam, Aftab and Lee, Youngmoon. Leveraging Semantic and Sentiment Knowledge for User-Generated Text Sentiment Classification. Proceedings of the Eighth Workshop on Noisy User-generated Text (W-NUT 2022). 2022
2022
-
[74]
An Emotional Journey: Detecting Emotion Trajectories in D utch Customer Service Dialogues
Labat, Sofie and Hadifar, Amir and Demeester, Thomas and Hoste, Veronique. An Emotional Journey: Detecting Emotion Trajectories in D utch Customer Service Dialogues. Proceedings of the Eighth Workshop on Noisy User-generated Text (W-NUT 2022). 2022
2022
-
[75]
Supervised and Unsupervised Evaluation of Synthetic Code-Switching
Orlov, Evgeny and Artemova, Ekaterina. Supervised and Unsupervised Evaluation of Synthetic Code-Switching. Proceedings of the Eighth Workshop on Noisy User-generated Text (W-NUT 2022). 2022
2022
-
[76]
A rab G end: Gender Analysis and Inference on A rabic T witter
Mubarak, Hamdy and Chowdhury, Shammur Absar and Alam, Firoj. A rab G end: Gender Analysis and Inference on A rabic T witter. Proceedings of the Eighth Workshop on Noisy User-generated Text (W-NUT 2022). 2022
2022
-
[77]
Automatic Identification of 5 C Vaccine Behaviour on Social Media
Sampath Kumar, Ajay Hemanth and Shausan, Aminath and Demartini, Gianluca and Rahimi, Afshin. Automatic Identification of 5 C Vaccine Behaviour on Social Media. Proceedings of the Eighth Workshop on Noisy User-generated Text (W-NUT 2022). 2022
2022
-
[78]
Automatic Extraction of Structured Mineral Drillhole Results from Unstructured Mining Company Reports
Dimeski, Adam and Rahimi, Afshin. Automatic Extraction of Structured Mineral Drillhole Results from Unstructured Mining Company Reports. Proceedings of the Eighth Workshop on Noisy User-generated Text (W-NUT 2022). 2022
2022
-
[79]
`` Kanglish alli names! '' Named Entity Recognition for K annada- E nglish Code-Mixed Social Media Data
S, Sumukh and Shrivastava, Manish. `` Kanglish alli names! '' Named Entity Recognition for K annada- E nglish Code-Mixed Social Media Data. Proceedings of the Eighth Workshop on Noisy User-generated Text (W-NUT 2022). 2022
2022
-
[80]
Span Extraction Aided Improved Code-mixed Sentiment Classification
S, Ramaneswaran and Benhur, Sean and Ghosh, Sreyan. Span Extraction Aided Improved Code-mixed Sentiment Classification. Proceedings of the Eighth Workshop on Noisy User-generated Text (W-NUT 2022). 2022
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.