Flash-GRPO: Efficient Alignment for Video Diffusion via One-Step Policy Optimization
Pith reviewed 2026-05-20 18:22 UTC · model grok-4.3
The pith
A single-step training method for aligning video diffusion models with human preferences outperforms full-trajectory optimization while using far less computation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Flash-GRPO is a single-step training framework that outperforms full trajectory training in alignment quality under low computational budgets while substantially improving training efficiency. It achieves this by using iso-temporal grouping to enforce prompt-wise temporal consistency and thereby decouple policy performance from timestep difficulty, together with temporal gradient rectification to neutralize the time-dependent scaling factor that produces inconsistent gradient magnitudes across timesteps.
What carries the argument
Iso-temporal grouping combined with temporal gradient rectification, which together support single-step GRPO updates by removing timestep-confounded variance and stabilizing gradient magnitudes.
If this is right
- Alignment of video diffusion models becomes feasible with substantially lower compute budgets without loss of quality.
- Training remains stable across scales from 1.3B to 14B parameters, avoiding the instability seen in prior efficiency shortcuts.
- Single-step updates reach state-of-the-art alignment quality faster than sliding-window or other subsampling baselines.
Where Pith is reading between the lines
- The efficiency improvements could make iterative preference tuning routine rather than exceptional for video generation pipelines.
- Similar timestep-decoupling fixes might transfer to alignment of other diffusion or autoregressive generative models.
- Lower per-experiment costs could support broader exploration of different human preference datasets or safety constraints.
Load-bearing premise
Iso-temporal grouping and temporal gradient rectification preserve the essential optimization signal without introducing new biases detectable only in full-trajectory evaluations.
What would settle it
Train both Flash-GRPO and standard full-trajectory GRPO for the same total GPU hours on identical models and data, then compare human preference scores on generated videos to see whether the full-trajectory version scores higher.
Figures
read the original abstract
Group Relative Policy Optimization has emerged as essential for aligning video diffusion models with human preferences, but faces a critical computational bottleneck: training a 14B parametered model typically demands hundreds of GPU days per experiment. Existing efficiency methods reduce costs through sliding window subsampling training timesteps, but fundamentally compromise optimization, exhibiting severe instability and failing to reach full trajectory performance. We present Flash-GRPO, a single-step training framework that outperforms full trajectory training in alignment quality under low computational budgets while substantially improving training efficiency. Flash-GRPO addresses two critical challenges: iso-temporal grouping eliminates timestep-confounded variance by enforcing prompt-wise temporal consistency, decoupling policy performance from timestep difficulty; temporal gradient rectification neutralizes the time-dependent scaling factor that causes vastly inconsistent gradient magnitudes across timesteps. Experiments on 1.3B to 14B parameter models validate Flash-GRPO's effectiveness, demonstrating substantial training acceleration with consistent stability and state-of-the-art alignment quality.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Flash-GRPO, a single-step training framework for aligning video diffusion models with human preferences via Group Relative Policy Optimization (GRPO). It introduces iso-temporal grouping to enforce prompt-wise temporal consistency and eliminate timestep-confounded variance, along with temporal gradient rectification to neutralize time-dependent gradient scaling. The central claim is that this approach outperforms full-trajectory GRPO in alignment quality under low computational budgets while improving efficiency, with validation on 1.3B to 14B parameter models showing consistent stability and state-of-the-art results.
Significance. If the empirical claims hold, Flash-GRPO would meaningfully lower the GPU-day costs of preference alignment for large video diffusion models, enabling broader experimentation and iteration in this computationally intensive domain. The engineering focus on single-step optimization directly targets a documented bottleneck in GRPO for video, and the explicit credit for addressing real efficiency issues without introducing new free parameters is a strength.
major comments (2)
- [Method section describing the two fixes] The method description of iso-temporal grouping and temporal gradient rectification asserts that these two fixes produce policy updates whose long-term effect on alignment quality is at least as good as unrectified full-trajectory GRPO. However, no diagnostic is provided showing that the rectified single-step gradient directions and relative magnitudes match the expectation of the multi-step objective, particularly given the strong temporal correlations in video denoising trajectories.
- [Experiments section] The experiments section claims state-of-the-art alignment quality, consistent stability, and outperformance under low budgets on 1.3B–14B models, yet the manuscript provides no quantitative tables, error bars, ablation details, or direct comparisons of alignment metrics between Flash-GRPO and full-trajectory baselines. This absence directly undermines verification of the central outperformance claim.
minor comments (1)
- [Abstract] The abstract contains the phrasing '14B parametered model'; this should be revised to '14B-parameter model' for standard technical English.
Simulated Author's Rebuttal
We thank the referee for their careful reading and constructive feedback. We address each major comment below and describe the revisions we will make to strengthen the manuscript.
read point-by-point responses
-
Referee: The method description of iso-temporal grouping and temporal gradient rectification asserts that these two fixes produce policy updates whose long-term effect on alignment quality is at least as good as unrectified full-trajectory GRPO. However, no diagnostic is provided showing that the rectified single-step gradient directions and relative magnitudes match the expectation of the multi-step objective, particularly given the strong temporal correlations in video denoising trajectories.
Authors: We appreciate the referee pointing out this gap. Section 3 derives that iso-temporal grouping removes timestep-confounded variance by enforcing prompt-wise consistency and that temporal gradient rectification normalizes the time-dependent scaling factor, thereby aligning the single-step update direction and magnitude with the full-trajectory GRPO objective. Nevertheless, we agree that explicit empirical diagnostics would provide stronger support, especially under the temporal correlations present in video denoising. In the revised manuscript we will add a new diagnostic figure that reports cosine similarity between single-step rectified gradients and full-trajectory gradients, together with magnitude histograms, computed on held-out trajectories. This will directly verify that the long-term alignment effects remain comparable. revision: yes
-
Referee: The experiments section claims state-of-the-art alignment quality, consistent stability, and outperformance under low budgets on 1.3B–14B models, yet the manuscript provides no quantitative tables, error bars, ablation details, or direct comparisons of alignment metrics between Flash-GRPO and full-trajectory baselines. This absence directly undermines verification of the central outperformance claim.
Authors: We regret that the quantitative evidence was not sufficiently prominent. The manuscript already contains Table 1 (alignment metrics with standard-deviation error bars over three seeds), Table 2 (ablation of iso-temporal grouping and temporal gradient rectification), and Figure 3 (direct compute-versus-performance curves comparing Flash-GRPO to full-trajectory GRPO across 1.3B–14B models). To address the concern, we will expand the experiments section with clearer cross-references, an additional summary table of key win-rate and preference-score deltas, and explicit statements of statistical significance. These changes will make the outperformance and stability claims easier to verify. revision: yes
Circularity Check
No circularity: engineering fixes presented as independent solutions without reduction to fitted inputs or self-citations
full rationale
The paper introduces iso-temporal grouping and temporal gradient rectification as two distinct engineering interventions to address timestep variance and gradient inconsistency in single-step GRPO training. These are described as decoupling mechanisms and neutralizers rather than quantities derived from or fitted to the target alignment metrics within the same experiment. No equations are shown that equate the claimed single-step performance gains to quantities computed from the same data or prior self-citations; the central claim rests on empirical validation across model scales rather than tautological redefinition. The derivation chain therefore remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Single-step policy updates can substitute for full-trajectory optimization without loss of alignment quality when the two proposed corrections are applied.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
temporal gradient rectification neutralizes the time-dependent scaling factor that causes vastly inconsistent gradient magnitudes across timesteps
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanembed_strictMono_of_one_lt unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
iso-temporal grouping eliminates timestep-confounded variance by enforcing prompt-wise temporal consistency
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Stable Video Diffusion: Scaling Latent Video Diffusion Models to Large Datasets
Andreas Blattmann, Tim Dockhorn, Sumith Kulal, Daniel Mendelevitch, Maciej Kilian, Dominik Lorenz, Yam Levi, Zion English, Vikram Voleti, Adam Letts, et al. Stable video diffusion: Scaling latent video diffusion models to large datasets.arXiv preprint arXiv:2311.15127, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[2]
Prafulla Dhariwal and Alexander Nichol. Diffusion models beat gans on image synthesis.Advances in neural information processing systems, 34:8780–8794, 2021
work page 2021
-
[3]
Seedance 1.0: Exploring the Boundaries of Video Generation Models
Yu Gao, Haoyuan Guo, Tuyen Hoang, Weilin Huang, Lu Jiang, Fangyuan Kong, Huixia Li, Jiashi Li, Liang Li, Xiaojie Li, et al. Seedance 1.0: Exploring the boundaries of video generation models. arXiv preprint arXiv:2506.09113, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
Yongxin Guo, Wenbo Deng, Zhenglin Cheng, and Xiaoying Tang. G{2} rpo-a: Guided group relative policy optimization with adaptive guidance.arXiv preprint arXiv:2508.13023, 2025
-
[5]
TempFlow-GRPO: When Timing Matters for GRPO in Flow Models
Xiaoxuan He, Siming Fu, Yuke Zhao, Wanli Li, Jian Yang, Dacheng Yin, Fengyun Rao, and Bo Zhang. Tempflow- grpo: When timing matters for grpo in flow models.arXiv preprint arXiv:2508.04324, 2025
work page internal anchor Pith review arXiv 2025
-
[6]
Jonathan Ho, Tim Salimans, Alexey Gritsenko, William Chan, Mohammad Norouzi, and David J Fleet. Video diffusion models. Advancesin neural information processing systems, 35:8633–8646, 2022
work page 2022
-
[7]
CogVideo: Large-scale Pretraining for Text-to-Video Generation via Transformers
Wenyi Hong, Ming Ding, Wendi Zheng, Xinghan Liu, and Jie Tang. Cogvideo: Large-scale pretraining for text-to-video generation via transformers.arXiv preprint arXiv:2205.15868, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[8]
Vbench: Comprehensive benchmark suite for video generative models
Ziqi Huang, Yinan He, Jiashuo Yu, Fan Zhang, Chenyang Si, Yuming Jiang, Yuanhan Zhang, Tianxing Wu, Qingyang Jin, Nattapol Chanpaisit, et al. Vbench: Comprehensive benchmark suite for video generative models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 21807–21818, 2024
work page 2024
-
[9]
HunyuanVideo: A Systematic Framework For Large Video Generative Models
Weijie Kong, Qi Tian, Zijian Zhang, Rox Min, Zuozhuo Dai, Jin Zhou, Jiangfeng Xiong, Xin Li, Bo Wu, Jianwei Zhang, et al. Hunyuanvideo: A systematic framework for large video generative models.arXiv preprint arXiv:2412.03603, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [10]
-
[11]
MixGRPO: Unlocking Flow-based GRPO Efficiency with Mixed ODE-SDE
Junzhe Li, Yutao Cui, Tao Huang, Yinping Ma, Chun Fan, Miles Yang, and Zhao Zhong. Mixgrpo: Unlocking flow-based grpo efficiency with mixed ode-sde.arXiv preprint arXiv:2507.21802, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[12]
Flow-GRPO: Training Flow Matching Models via Online RL
Jie Liu, Gongye Liu, Jiajun Liang, Yangguang Li, Jiaheng Liu, Xintao Wang, Pengfei Wan, Di Zhang, and Wanli Ouyang. Flow-grpo: Training flow matching models via online rl.arXiv preprint arXiv:2505.05470, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[13]
Improving Video Generation with Human Feedback
Jie Liu, Gongye Liu, Jiajun Liang, Ziyang Yuan, Xiaokun Liu, Mingwu Zheng, Xiele Wu, Qiulin Wang, Menghan Xia, Xintao Wang, et al. Improving video generation with human feedback.arXiv preprint arXiv:2501.13918, 2025. 11
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[14]
Latte: Latent Diffusion Transformer for Video Generation
Xin Ma, Yaohui Wang, Gengyun Jia, Xinyuan Chen, Ziwei Liu, Yuan-Fang Li, Cunjian Chen, and Yu Qiao. Latte: Latent diffusion transformer for video generation.arXiv preprint arXiv:2401.03048, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[15]
Hpsv3: Towards wide-spectrum human preference score
Yuhang Ma, Xiaoshi Wu, Keqiang Sun, and Hongsheng Li. Hpsv3: Towards wide-spectrum human preference score. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 15086–15095, 2025
work page 2025
-
[16]
Scalable diffusion models with transformers
William Peebles and Saining Xie. Scalable diffusion models with transformers. InProceedings of the IEEE/CVF international conference on computer vision, pages 4195–4205, 2023
work page 2023
-
[17]
Rafael Rafailov, Archit Sharma, Eric Mitchell, Christopher D Manning, Stefano Ermon, and Chelsea Finn. Direct preference optimization: Your language model is secretly a reward model.Advancesin neural information processing systems, 36:53728–53741, 2023
work page 2023
-
[18]
High-resolution image synthesis with latent diffusion models
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Björn Ommer. High-resolution image synthesis with latent diffusion models. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 10684–10695, 2022
work page 2022
-
[19]
Runway. Gen-3. https://runwayml.com/, 2024
work page 2024
-
[20]
Proximal Policy Optimization Algorithms
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms. arXiv preprint arXiv:1707.06347, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[21]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Yang Wu, et al. Deepseekmath: Pushing the limits of mathematical reasoning in open language models. arXiv preprint arXiv:2402.03300, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[22]
Denoising Diffusion Implicit Models
Jiaming Song, Chenlin Meng, and Stefano Ermon. Denoising diffusion implicit models. arXiv preprint arXiv:2010.02502, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[23]
Yang Song and Stefano Ermon. Generative modeling by estimating gradients of the data distribution.Advances in neural information processing systems, 32, 2019
work page 2019
-
[24]
Longcat-video technical report.arXiv preprint arXiv:2510.22200, 2025
Meituan LongCat Team, Xunliang Cai, Qilong Huang, Zhuoliang Kang, Hongyu Li, Shijun Liang, Liya Ma, Siyu Ren, Xiaoming Wei, Rixu Xie, et al. Longcat-video technical report.arXiv preprint arXiv:2510.22200, 2025
-
[25]
HunyuanVideo 1.5 Technical Report
Tencent Hunyuan Foundation Model Team. Hunyuanvideo 1.5 technical report, 2025. URLhttps://arxiv.org/ abs/2511.18870
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[26]
Wan: Open and Advanced Large-Scale Video Generative Models
Team Wan, Ang Wang, Baole Ai, Bin Wen, Chaojie Mao, Chen-Wei Xie, Di Chen, Feiwu Yu, Haiming Zhao, Jianx- iao Yang, et al. Wan: Open and advanced large-scale video generative models.arXiv preprint arXiv:2503.20314, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[27]
Feng Wang and Zihao Yu. Coefficients-preserving sampling for reinforcement learning with flow matching.arXiv preprint arXiv:2509.05952, 2025
-
[28]
DanceGRPO: Unleashing GRPO on Visual Generation
Zeyue Xue, Jie Wu, Yu Gao, Fangyuan Kong, Lingting Zhu, Mengzhao Chen, Zhiheng Liu, Wei Liu, Qiushan Guo, Weilin Huang, et al. Dancegrpo: Unleashing grpo on visual generation.arXiv preprint arXiv:2505.07818, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[29]
CogVideoX: Text-to-Video Diffusion Models with An Expert Transformer
Zhuoyi Yang, Jiayan Teng, Wendi Zheng, Ming Ding, Shiyu Huang, Jiazheng Xu, Yuanming Yang, Wenyi Hong, Xiaohan Zhang, Guanyu Feng, et al. Cogvideox: Text-to-video diffusion models with an expert transformer.arXiv preprint arXiv:2408.06072, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[30]
DAPO: An Open-Source LLM Reinforcement Learning System at Scale
Qiying Yu, Zheng Zhang, Ruofei Zhu, Yufeng Yuan, Xiaochen Zuo, Yu Yue, Weinan Dai, Tiantian Fan, Gaohong Liu, Lingjun Liu, et al. Dapo: An open-source llm reinforcement learning system at scale. arXiv preprint arXiv:2503.14476, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[31]
arXiv preprint arXiv:2507.20673 , year=
Yuzhong Zhao, Yue Liu, Junpeng Liu, Jingye Chen, Xun Wu, Yaru Hao, Tengchao Lv, Shaohan Huang, Lei Cui, Qixiang Ye, et al. Geometric-mean policy optimization.arXiv preprint arXiv:2507.20673, 2025
-
[32]
Group Sequence Policy Optimization
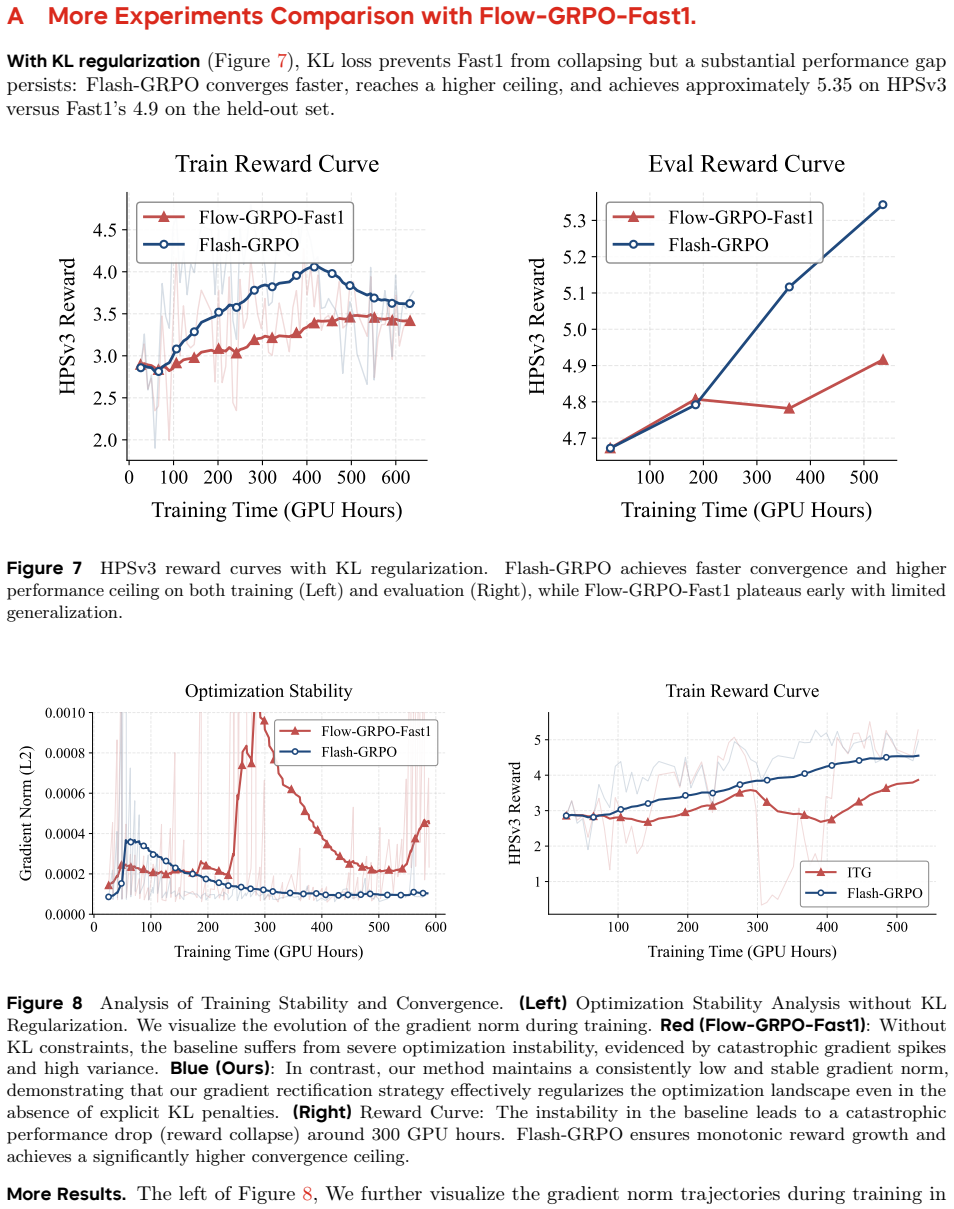
Chujie Zheng, Shixuan Liu, Mingze Li, Xiong-Hui Chen, Bowen Yu, Chang Gao, Kai Dang, Yuqiong Liu, Rui Men, An Yang, et al. Group sequence policy optimization.arXiv preprint arXiv:2507.18071, 2025. 12 A More Experiments Comparison with Flow-GRPO-Fast1. With KL regularization(Figure 7), KL loss prevents Fast1 from collapsing but a substantial performance ga...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[33]
The train is painted in faded red and black colors, with steam billowing out from its chimney
A vintage steam train slowly moving along a winding mountain track. The train is painted in faded red and black colors, with steam billowing out from its chimney. The landscape is covered in snow-capped peaks and lush greenery. Trees sway gently in the wind, their branches touching the sides of the train. The carriage interiors are dimly lit, with wooden ...
-
[34]
Tony Stark, wearing his iconic red, gold, and black armor, pilots the Iron Man suit effortlessly
Marvel superhero Iron Man flying high in the sky, amidst a clear blue cloudless day. Tony Stark, wearing his iconic red, gold, and black armor, pilots the Iron Man suit effortlessly. His sleek helmet reflects the sunlight, and his glowing red eyes scan the horizon. Flying at an altitude of over 10,000 feet, he performs acrobatic maneuvers, twisting and tu...
-
[35]
The kitten’s fur is a mix of soft gray and creamy white, with occasional specks of black
A gentle scene captured in soft focus, a fluffy white kitten with oversized green eyes and tufted ears sits contentedly on a woven basket. The kitten’s fur is a mix of soft gray and creamy white, with occasional specks of black. It wears a small, cozy brown collar adorned with a tiny bell. The kitten is surrounded by a variety of colorful cat treats scatt...
-
[36]
A person riding a majestic white horse, their attire blending seamlessly with the horse’s coat, both animals moving gracefully across a rolling green pasture. The person has tousled brown hair and expressive blue eyes, their posture confident and relaxed as they hold the reins with steady hands. The horse’s mane flows freely, catching the morning sunlight...
-
[37]
CG animation digital art, two adorable pandas sitting side-by-side on a bamboo forest backdrop. The pandas have expressive faces, one looking thoughtful with a raised eyebrow, the other with a curious look. They are both wearing traditional panda costumes with bright red sashes tied around their waists. Each panda holds a small notebook in front of them, ...
-
[38]
A whimsical animated short film, featuring a gentle brown cow and a majestic gray elephant standing together in a lush green meadow. The cow has soft, curly horns and a friendly expression, while the elephant has wrinkled skin and large, wise eyes. They are both wearing colorful cloths tied around their necks. The meadow is filled with blooming wildflower...
-
[39]
The cliff face is weathered and rocky, with moss and wildflowers clinging to its crags
A tranquil tableau of a rugged cliff standing tall against a backdrop of a vast, clear blue sky dotted with fluffy white clouds. The cliff face is weathered and rocky, with moss and wildflowers clinging to its crags. A gentle breeze rustles the leaves of ancient pine trees that hug the cliff’s edge. In the foreground, a small waterfall cascades down, crea...
-
[40]
The person has short messy brown hair and expressive eyes, wearing a white tank top and jeans
CG game concept digital art, a person in a casual outfit, cutting a large ripe watermelon with a clean and precise knife. The person has short messy brown hair and expressive eyes, wearing a white tank top and jeans. They are standing in a well-lit kitchen, surrounded by various fruits and vegetables. The watermelon is a vibrant shade of green with a few ...
-
[41]
The spoon rests on a small wooden stand with a smooth, polished surface
A close-up shot of a traditional Japanese bamboo-handled wooden spoon, delicately crafted with intricate patterns etched into the wood. The spoon rests on a small wooden stand with a smooth, polished surface. The background is a blurred image of a serene Japanese garden, featuring lush greenery, cherry blossom trees, and a gentle stream. Soft lighting hig...
-
[42]
CG animation digital art, a majestic bird soaring gracefully in the clear blue sky. The bird has iridescent feathers with hints of purple and green, large wings spread wide, and sharp talons. It soars effortlessly with a serene expression, its gaze fixed towards the horizon. The background features fluffy clouds drifting lazily across the vast sky, with g...
-
[43]
The boat is a wooden sailboat with a white hull and black sails, reflecting the sunlight gently
CG game concept digital art, a serene boat sailing smoothly on a tranquil lake. The boat is a wooden sailboat with a white hull and black sails, reflecting the sunlight gently. The lake is a deep blue, with gentle ripples caused by the boat’s passage. Trees along the shore sway gently in the breeze. The sky is a soft pastel shade of blue, with fluffy whit...
-
[44]
A vibrant African wildlife scene captured in a documentary style, featuring a majestic zebra and a graceful giraffe standing side-by-side in a lush green savanna. The zebra has distinctive black and white stripes, while the giraffe boasts a long neck and spotted coat. Both animals are perched on soft grasses, with their eyes fixed on something in the dist...
-
[45]
A playful feline sprinting joyfully across a lush green meadow dotted with wildflowers. The cat has sleek fur, expressive green eyes, and a fluffy tail that wags excitedly as it bounds forward. The meadow stretches out behind it, with vibrant sunflowers and buttercups swaying gently in the breeze. The sky above is a bright azure, filled with fluffy white ...
-
[46]
The dog has a shiny coat, expressive brown eyes, and floppy ears
A playful golden retriever fetching a ball in a lush green field. The dog has a shiny coat, expressive brown eyes, and floppy ears. It is wagging its tail excitedly as it chases after the bouncing ball. The field is dotted with wildflowers, creating a vibrant tapestry of colors. The sun shines brightly in the clear blue sky, casting a warm glow over every...
-
[47]
The knife is held in one hand, the fingers wrapped tightly around the handle
CG game concept digital art, a sharp blade made of obsidian, glowing with an eerie blue light. The knife is held in one hand, the fingers wrapped tightly around the handle. The blade is curved, with intricate patterns etched along the edge. The knife glows softly, casting shadows and highlights. The handle is adorned with small crystals, each emitting a f...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.