FreeStreamGS: Online Feed-forward 3D Gaussian Splatting from Unposed Streaming Inputs
Pith reviewed 2026-06-28 10:39 UTC · model grok-4.3
The pith
FreeStreamGS performs online 3D Gaussian Splatting from unposed streaming images at quality levels competitive with offline methods.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
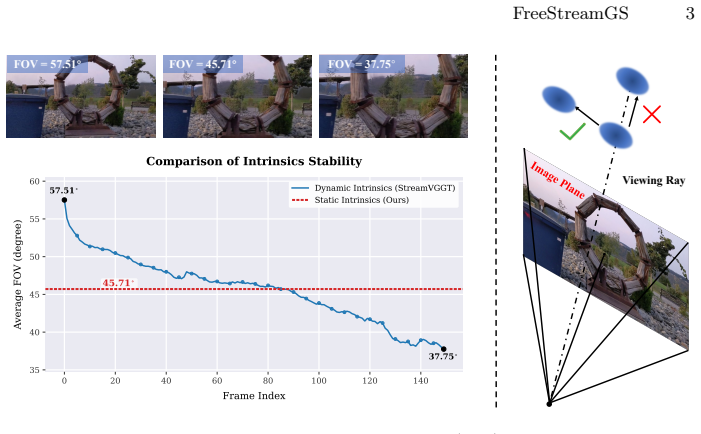
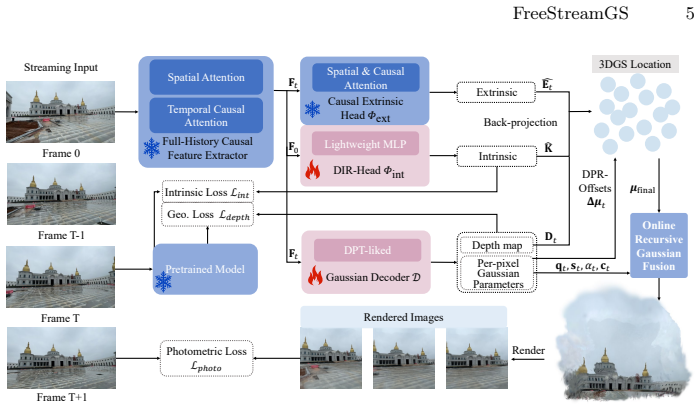
FreeStreamGS is a robust online feed-forward framework for efficient and high-quality novel view synthesis. It introduces a Decoupled Intrinsic Recovery Head that removes cumulative camera intrinsic bias and prevents scene scale jitter during long-term streaming, and a Dynamic Point Refinement Offset strategy that relaxes rigid unprojection to correct coupled pose-depth drift. Extensive experiments show that FreeStreamGS achieves rendering quality competitive with state-of-the-art offline feed-forward 3DGS methods, despite operating without access to future frames.
What carries the argument
Decoupled Intrinsic Recovery Head and Dynamic Point Refinement Offset, which together enforce multi-view consistency in Gaussian scales and pose-geometry alignment for streaming inputs.
If this is right
- Online novel view synthesis becomes feasible from unposed streaming inputs without future frames.
- Cumulative camera intrinsic bias no longer produces scene scale jitter in extended streams.
- Pose-depth drift can be corrected without rigid unprojection, preserving rendering fidelity.
- Rendering quality remains competitive with offline methods when the two mechanisms are applied.
Where Pith is reading between the lines
- The approach could support live applications such as real-time AR overlays if paired with low-latency pose estimation.
- The consistency fixes might transfer to other streaming 3D reconstruction tasks beyond Gaussian splatting.
- Longer test sequences would reveal whether drift correction remains stable beyond the evaluated lengths.
Load-bearing premise
The two new mechanisms maintain multi-view consistency in Gaussian scales and pose-geometry alignment over long streams without introducing new artifacts or needing future frames.
What would settle it
A long unposed image stream on which FreeStreamGS produces visibly worse rendering artifacts or scale jitter than an offline feed-forward 3DGS baseline after several hundred frames.
Figures




read the original abstract
Feed-forward 3D Gaussian Splatting (3DGS) allows efficient and high-fidelity novel view synthesis (NVS) from an offline recorded image sequence. However, achieving online NVS from streaming and unposed image inputs remains challenging. Although online feed-forward geometric estimation methods have been proposed for streaming depth and point cloud recovery, they cannot be adapted to NVS due to severe rendering artifacts. This is because NVS demands stricter multi-view consistency in Gaussian scales and pose-geometry alignment; even minor deviations would accumulate over time and visibly degrade rendering quality. To this end, we propose FreeStreamGS, a robust online feed-forward framework for efficient and high-quality NVS. We introduce two key mechanisms: a Decoupled Intrinsic Recovery Head that removes cumulative camera intrinsic bias and prevents scene scale jitter during long-term streaming, and a Dynamic Point Refinement Offset strategy that relaxes rigid unprojection to correct coupled pose-depth drift. Extensive experiments show that FreeStreamGS achieves rendering quality competitive with state-of-the-art offline feed-forward 3DGS methods, despite operating without access to future frames.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces FreeStreamGS, an online feed-forward framework for 3D Gaussian Splatting from unposed streaming image inputs. It proposes two mechanisms—a Decoupled Intrinsic Recovery Head to eliminate cumulative camera intrinsic bias and prevent long-term scene scale jitter, and a Dynamic Point Refinement Offset strategy to relax rigid unprojection and correct coupled pose-depth drift—to enforce the multi-view consistency in Gaussian scales and pose-geometry alignment required for high-quality novel view synthesis. The central claim, supported by extensive experiments, is that FreeStreamGS achieves rendering quality competitive with state-of-the-art offline feed-forward 3DGS methods while operating without access to future frames.
Significance. If the two proposed mechanisms demonstrably sustain multi-view consistency over long streams without introducing compensating artifacts or implicit future-frame dependence, the work would meaningfully advance online NVS, enabling practical deployment in streaming scenarios where offline batch methods are inapplicable. The explicit identification of scale jitter and coupled drift as the precise failure modes of prior geometric approaches, together with targeted architectural fixes, strengthens the contribution if the empirical validation holds.
major comments (3)
- [Abstract, §4] Abstract and §4 (experiments): the claim of 'competitive' rendering quality with offline SOTA methods is asserted but the abstract provides no quantitative metrics, baselines, error bars, or dataset details; without these, the central claim that the two mechanisms succeed in preventing accumulation of deviations cannot be evaluated.
- [§3.2] §3.2 (Decoupled Intrinsic Recovery Head): the mechanism is described as removing cumulative intrinsic bias, but no derivation or ablation is referenced showing that the head operates without access to future frames or without reintroducing scale jitter over sequences longer than those tested; this is load-bearing for the no-future-frames claim.
- [§3.3] §3.3 (Dynamic Point Refinement Offset): the strategy relaxes rigid unprojection to correct pose-depth drift, yet the manuscript does not report quantitative tracking of multi-view consistency (e.g., scale variance or alignment error) across streaming length, leaving the assumption that it prevents visible degradation unverified.
minor comments (2)
- [§3.3] Notation for the refinement offset should be defined explicitly with respect to the unprojection equation to avoid ambiguity in how the relaxation is parameterized.
- [Figures 4-6] Figure captions for qualitative results should include the exact sequence length and number of frames to allow readers to assess long-term stability.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and will revise the manuscript to strengthen the presentation of quantitative results and validation of the proposed mechanisms.
read point-by-point responses
-
Referee: [Abstract, §4] Abstract and §4 (experiments): the claim of 'competitive' rendering quality with offline SOTA methods is asserted but the abstract provides no quantitative metrics, baselines, error bars, or dataset details; without these, the central claim that the two mechanisms succeed in preventing accumulation of deviations cannot be evaluated.
Authors: The detailed quantitative results, including metrics, baselines, error bars, and dataset information, are presented in Section 4. However, we agree that the abstract would benefit from including key quantitative highlights to support the claim. We will revise the abstract to incorporate representative metrics from our experiments. revision: yes
-
Referee: [§3.2] §3.2 (Decoupled Intrinsic Recovery Head): the mechanism is described as removing cumulative intrinsic bias, but no derivation or ablation is referenced showing that the head operates without access to future frames or without reintroducing scale jitter over sequences longer than those tested; this is load-bearing for the no-future-frames claim.
Authors: The architecture of the Decoupled Intrinsic Recovery Head is explicitly feed-forward and processes frames sequentially without future information, as described in §3.2 and illustrated in the method figure. To strengthen this, we will add a derivation explaining the decoupling and an ablation study on extended sequence lengths to verify the prevention of scale jitter. revision: yes
-
Referee: [§3.3] §3.3 (Dynamic Point Refinement Offset): the strategy relaxes rigid unprojection to correct pose-depth drift, yet the manuscript does not report quantitative tracking of multi-view consistency (e.g., scale variance or alignment error) across streaming length, leaving the assumption that it prevents visible degradation unverified.
Authors: While the overall rendering quality in long streaming scenarios is demonstrated in our experiments, we acknowledge the value of direct quantitative tracking. We will include additional analysis and metrics for multi-view consistency (such as scale variance and alignment errors) over varying streaming lengths in the revised version. revision: yes
Circularity Check
No significant circularity; empirical validation of independent mechanisms
full rationale
The paper introduces two new architectural components (Decoupled Intrinsic Recovery Head and Dynamic Point Refinement Offset) to solve identified failure modes in online feed-forward 3DGS, then reports competitive rendering quality from experiments on streaming inputs. No derivation, prediction, or first-principles result is claimed that reduces by construction to fitted parameters, self-citations, or renamed inputs. The central claim rests on empirical comparison rather than any self-referential loop, making the work self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Charatan, D., Li, S.L., Tagliasacchi, A., Sitzmann, V.: Pixelsplat: 3d gaussian splatsfromimagepairsforscalablegeneralizable3dreconstruction.In:Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 19457–19467 (2024)
2024
-
[2]
In: European Conference on Computer Vision
Chen, Y., Xu, H., Zheng, C., Zhuang, B., Pollefeys, M., Geiger, A., Cham, T.J., Cai, J.: Mvsplat: Efficient 3d gaussian splatting from sparse multi-view images. In: European Conference on Computer Vision. pp. 370–386. Springer (2024)
2024
-
[3]
Guo, J., Guan, T., Dong, W., Zheng, W., Wang, W., Wang, Y., Yam, Y., Liu, Y.H.: Salon3r: Structure-aware long-term generalizable 3d reconstruction from unposed images. arXiv preprint arXiv:2510.15072 (2025)
-
[4]
arXiv preprint arXiv:2410.22128 (2024) 3, 8
Hong, S., Jung, J., Shin, H., Han, J., Yang, J., Luo, C., Kim, S.: Pf3plat: Pose-free feed-forward 3d gaussian splatting. arXiv preprint arXiv:2410.22128 (2024)
-
[5]
arXiv preprint arXiv:2507.16144 (2025) 22 R
Huang, G., Wang, R., Gao, X., Sun, C., Wu, Y., Gao, S., Jia, Y.: Longsplat: On- line generalizable 3d gaussian splatting from long sequence images. arXiv preprint arXiv:2507.16144 (2025) 22 R. Chen et al
-
[6]
ACM Transactions on Graphics (TOG)44(6), 1–16 (2025)
Jiang, L., Mao, Y., Xu, L., Lu, T., Ren, K., Jin, Y., Xu, X., Yu, M., Pang, J., Zhao, F., et al.: Anysplat: Feed-forward 3d gaussian splatting from unconstrained views. ACM Transactions on Graphics (TOG)44(6), 1–16 (2025)
2025
-
[7]
In: ACM SIGGRAPH 2024 conference papers
Jiang, Y., Yu, C., Xie, T., Li, X., Feng, Y., Wang, H., Li, M., Lau, H., Gao, F., Yang, Y., et al.: Vr-gs: A physical dynamics-aware interactive gaussian splatting system in virtual reality. In: ACM SIGGRAPH 2024 conference papers. pp. 1–1 (2024)
2024
-
[8]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Keetha, N., Karhade, J., Jatavallabhula, K.M., Yang, G., Scherer, S., Ramanan, D., Luiten, J.: Splatam: Splat track & map 3d gaussians for dense rgb-d slam. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 21357–21366 (2024)
2024
-
[9]
In: International Conference on Learning Representations (2026)
Lan,Y.,Luo,Y.,Hong,F.,Zhou,S.,Chen,H.,Lyu,Z.,Yang,S.,Dai,B.,Loy,C.C., Pan, X.: STream3R: Scalable sequential 3D reconstruction with causal transformer. In: International Conference on Learning Representations (2026)
2026
-
[10]
arXiv preprint arXiv:2510.08551 , year=
Li, G., Ren, K., Xu, L., Zheng, Z., Jiang, C., Gao, X., Dai, B., Pu, J., Yu, M., Pang, J.: Artdeco: Towards efficient and high-fidelity on-the-fly 3d reconstruction with structured scene representation. arXiv preprint arXiv:2510.08551 (2025)
-
[11]
arXiv preprint arXiv:2503.06235 (2025)
Li, Y., Wang, J., Chu, L., Li, X., Kao, S.h., Chen, Y.C., Lu, Y.: Streamgs: Online generalizable gaussian splatting reconstruction for unposed image streams. arXiv preprint arXiv:2503.06235 (2025)
-
[12]
arXiv preprint arXiv:2503.10286 (2025)
Li, Z., Dong, C., Chen, Y., Huang, Z., Liu, P.: Vicasplat: A single run is all you need for 3d gaussian splatting and camera estimation from unposed video frames. arXiv preprint arXiv:2503.10286 (2025)
-
[13]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Lin, C.Y., Sun, C., Yang, F.E., Chen, M.H., Lin, Y.Y., Liu, Y.L.: Longsplat: Ro- bust unposed 3d gaussian splatting for casual long videos. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 27412–27422 (2025)
2025
-
[14]
Depth Anything 3: Recovering the Visual Space from Any Views
Lin, H., Chen, S., Liew, J.H., Chen, D.Y., Li, Z., Shi, G., Feng, J., Kang, B.: Depth anything 3: Recovering the visual space from any views. arXiv preprint arXiv:2511.10647 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[15]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Ling, L., Sheng, Y., Tu, Z., Zhao, W., Xin, C., Wan, K., Yu, L., Guo, Q., Yu, Z., Lu, Y., et al.: Dl3dv-10k: A large-scale scene dataset for deep learning-based 3d vision. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 22160–22169 (2024)
2024
- [16]
-
[17]
Decoupled Weight Decay Regularization
Loshchilov, I., Hutter, F.: Decoupled weight decay regularization. arXiv preprint arXiv:1711.05101 (2017)
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[18]
ACM Transactions on Graphics (TOG)44(4) (2025)
Meuleman, A., Shah, I., Lanvin, A., Kerbl, B., Drettakis, G.: On-the-fly reconstruc- tion for large-scale novel view synthesis from unposed images. ACM Transactions on Graphics (TOG)44(4) (2025)
2025
-
[19]
In: European Conference on Computer Vision (2012)
Nathan Silberman, Derek Hoiem, P.K., Fergus, R.: Indoor segmentation and sup- port inference from rgbd images. In: European Conference on Computer Vision (2012)
2012
-
[20]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Ranftl, R., Bochkovskiy, A., Koltun, V.: Vision transformers for dense prediction. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 12179–12188 (2021)
2021
-
[21]
Analytical chemistry36(8), 1627–1639 (1964) FreeStreamGS 23
Savitzky, A., Golay, M.J.: Smoothing and differentiation of data by simplified least squares procedures. Analytical chemistry36(8), 1627–1639 (1964) FreeStreamGS 23
1964
-
[22]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Wang, J., Chen, M., Karaev, N., Vedaldi, A., Rupprecht, C., Novotny, D.: Vggt: Visual geometry grounded transformer. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 5294–5306 (2025)
2025
-
[23]
Advances in Neural Infor- mation Processing Systems37, 107326–107349 (2024)
Wang, Y., Huang, T., Chen, H., Lee, G.H.: Freesplat: Generalizable 3d gaussian splatting towards free view synthesis of indoor scenes. Advances in Neural Infor- mation Processing Systems37, 107326–107349 (2024)
2024
-
[24]
arXiv preprint arXiv:2506.08862 (2025)
Wu, Z., Yan, Q., Yi, X., Wang, L., Liao, R.: Streamsplat: Towards online dynamic 3d reconstruction from uncalibrated video streams. arXiv preprint arXiv:2506.08862 (2025)
-
[25]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Xie, T., Zong, Z., Qiu, Y., Li, X., Feng, Y., Yang, Y., Jiang, C.: Physgaussian: Physics-integrated 3d gaussians for generative dynamics. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 4389–4398 (2024)
2024
-
[26]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Xu, H., Peng, S., Wang, F., Blum, H., Barath, D., Geiger, A., Pollefeys, M.: Depth- splat: Connecting gaussian splatting and depth. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 16453–16463 (2025)
2025
-
[27]
IEEE Robotics and Automation Letters11(1), 426–433 (2025)
Xu, Y., Yu, Y., Gan, W., Wang, T., Zhan, Z., Cheng, H., Wang, X.: Gaussian on-the-fly splatting: A progressive framework for robust near real-time 3dgs opti- mization. IEEE Robotics and Automation Letters11(1), 426–433 (2025)
2025
-
[28]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Yan, C., Qu, D., Xu, D., Zhao, B., Wang, Z., Wang, D., Li, X.: Gs-slam: Dense visual slam with 3d gaussian splatting. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 19595–19604 (2024)
2024
-
[29]
Ye, B., Liu, S., Xu, H., Li, X., Pollefeys, M., Yang, M.H., Peng, S.: No pose, no problem: Surprisingly simple 3d gaussian splats from sparse unposed images. arXiv preprint arXiv:2410.24207 (2024)
-
[30]
In: Pro- ceedings of the Special Interest Group on Computer Graphics and Interactive Tech- niques Conference Conference Papers
You, Z., Georgoulis, S., Chen, A., Tang, S., Dai, D.: Gavs: 3d-grounded video stabilization via temporally-consistent local reconstruction and rendering. In: Pro- ceedings of the Special Interest Group on Computer Graphics and Interactive Tech- niques Conference Conference Papers. pp. 1–12 (2025)
2025
-
[31]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Zhang, S., Wang, J., Xu, Y., Xue, N., Rupprecht, C., Zhou, X., Shen, Y., Wet- zstein, G.: Flare: Feed-forward geometry, appearance and camera estimation from uncalibrated sparse views. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 21936–21947 (2025)
2025
-
[32]
In: Proceedings of the Computer Vision and Pattern Recognition Confer- ence
Zheng, S., Zhou, B., Shao, R., Liu, B., Zhang, S., Nie, L., Liu, Y.: Gps-gaussian: Generalizable pixel-wise 3d gaussian splatting for real-time human novel view syn- thesis. In: Proceedings of the Computer Vision and Pattern Recognition Confer- ence. pp. 19680–19690 (2024)
2024
-
[33]
Zhou, T., Tucker, R., Flynn, J., Fyffe, G., Snavely, N.: Stereo magnification: Learn- ingviewsynthesisusingmultiplaneimages.arXivpreprintarXiv:1805.09817(2018)
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[34]
Streaming 4D Visual Geometry Transformer
Zhuo, D., Zheng, W., Guo, J., Wu, Y., Zhou, J., Lu, J.: Streaming 4d visual geometry transformer. arXiv preprint arXiv:2507.11539 (2025) 24 R. Chen et al. GT Ours OnTheFly- NVS [18] World Mirror [16] AnySplat [6] FLARE [31] Fig. E.5:Qualitative comparison on DL3DV-140 [15] datasets under 10 input views. FreeStreamGS 25 GT Ours OnTheFly- NVS [18] World Mir...
work page internal anchor Pith review Pith/arXiv arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.