Ranking Companion: A Visual Analytics Approach to Item-Based Ranking with Hybrid Item Selection
Pith reviewed 2026-06-26 07:21 UTC · model grok-4.3
The pith
A visual analytics system combines six item-selection methods with active learning so users can build personalized rankings by judging known items.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By integrating model-driven active learning with six complementary human-driven item-selection methods inside one interactive space, users can externalize listwise preferences through judgments on selected candidates; an iterative ranking model then produces results accompanied by explanations, and a formative study with ten participants across three iterations reveals tradeoffs among perceived ranking quality dimensions.
What carries the argument
The hybrid item-selection space that unifies six complementary methods with active-learning updates to a ranking model.
If this is right
- Users can express ranking preferences without first learning which attributes exist or how to weight them.
- Different selection methods shift the balance among accuracy, diversity, novelty, transparency, control, and satisfaction in the produced rankings.
- Explanations attached to each ranking let users inspect and refine the model output over successive iterations.
- A single unified interface supports switching among methods so that users can adapt their strategy as the ranking evolves.
Where Pith is reading between the lines
- The same hybrid selection pattern could be tested in other preference-elicitation tasks such as playlist creation or product recommendation.
- Larger-scale studies could check whether the observed tradeoffs persist when users work with bigger item sets or over longer sessions.
- Designers might add automatic method-switching rules that respond to early user feedback on the quality dimensions.
Load-bearing premise
That the hybrid use of six different item-selection methods will produce observable and meaningful differences in how users rate the resulting rankings on accuracy, diversity, novelty, transparency, control, and satisfaction.
What would settle it
A controlled study in which participants report no measurable differences across the six methods on any of the six quality dimensions after repeated iterations would falsify the claim of useful tradeoffs.
Figures
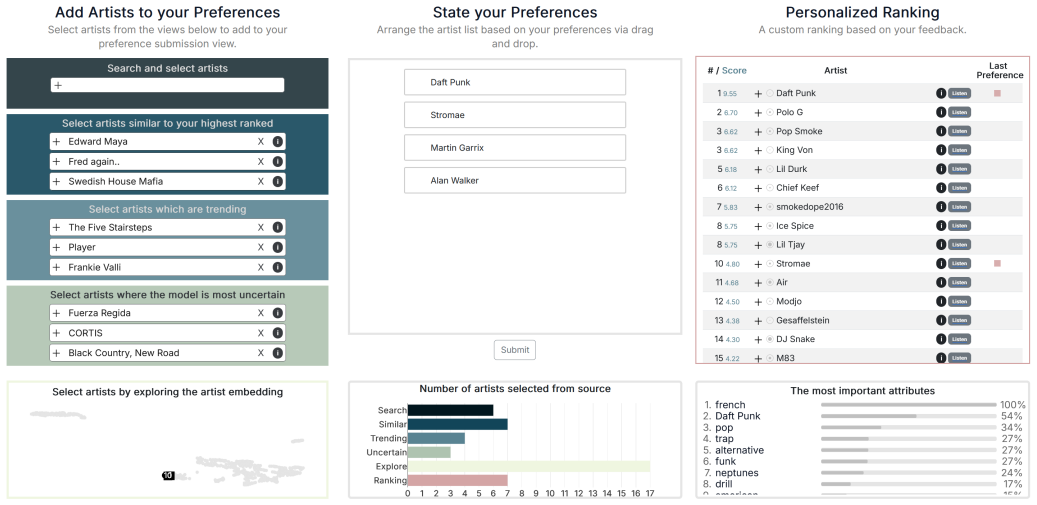


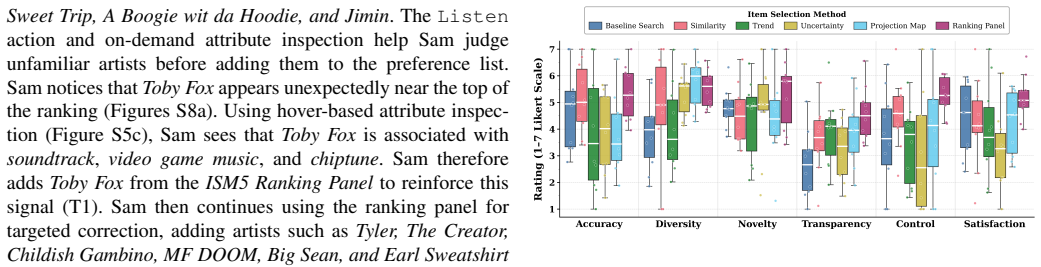
read the original abstract
Personalizing item ranking creation is a challenging task, especially when users lack knowledge of data attributes or the ability to express and formalize their attribute preferences. Item-based ranking creation is an approach allowing users to directly externalize preferences through known-item judgments rather than attribute-based scoring. However, a core challenge of item-based ranking is identifying and selecting representative candidate items for externalizing preferences. Existing approaches rely on singular item-selection methods, limiting flexibility and user control. To address this challenge, we present Ranking Companion, a visual analytics approach for item-based ranking that combines model-driven active learning with human-driven item-selection methods. By drawing from six complementary item-selection methods, users can externalize listwise preferences based on selected candidate items, while an iterative machine learning process with a ranking model calculates ranking results, presented to users alongside explanations for interpretation. We evaluated Ranking Companion in a formative user study with 10 participants, in which participants used each item-selection method across three iterations, revealing tradeoffs in perceived ranking quality across accuracy, diversity, novelty, transparency, control, and satisfaction. Ranking Companion contributes a unified interactive item selection space and provides preliminary empirical guidance toward the hybrid use of multiple complementary item-selection methods in personalized item-based ranking creation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents Ranking Companion, a visual analytics system for item-based ranking creation. It integrates model-driven active learning with six complementary human-driven item-selection methods, allowing users to externalize listwise preferences via candidate items. An iterative ML ranking model then computes results, displayed with explanations. A formative user study with 10 participants (each using the methods across three iterations) is reported to reveal tradeoffs in perceived ranking quality across accuracy, diversity, novelty, transparency, control, and satisfaction. The work contributes a unified interactive selection space and preliminary empirical guidance on hybrid method use.
Significance. If the claimed tradeoffs hold under more rigorous evaluation, the hybrid approach would meaningfully advance visual analytics for personalized ranking by overcoming limitations of single-method item selection and supporting users who cannot easily articulate attribute preferences. The integration of active learning with human-driven strategies, combined with explanatory feedback, addresses a practical HCI challenge in recommendation interfaces. The preliminary guidance on method tradeoffs could inform future system designs, though the small-scale formative study currently constrains the strength of this contribution.
major comments (2)
- [Evaluation / formative user study description] The central empirical claim—that the hybrid combination of six methods produces observable and meaningful tradeoffs across six quality dimensions—rests on a single formative user study with N=10. The provided description supplies no quantitative metrics, statistical tests, effect sizes, or controls for order effects/individual variance, which is load-bearing for the claim that the hybrid mechanism itself drives the differences (as opposed to demand characteristics or participant variability).
- [System overview and abstract] Implementation details of the six item-selection methods and their integration into the visual analytics interface (including how model-driven active learning interacts with the human-driven approaches) are absent from the abstract and high-level evaluation summary. This prevents assessment of whether the hybrid design is reproducible or genuinely novel relative to prior singular-method baselines.
minor comments (1)
- [Abstract] The abstract would be clearer if it briefly named or categorized the six complementary item-selection methods rather than referring to them generically.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major point below and indicate where revisions will be made to improve clarity and contextualization.
read point-by-point responses
-
Referee: [Evaluation / formative user study description] The central empirical claim—that the hybrid combination of six methods produces observable and meaningful tradeoffs across six quality dimensions—rests on a single formative user study with N=10. The provided description supplies no quantitative metrics, statistical tests, effect sizes, or controls for order effects/individual variance, which is load-bearing for the claim that the hybrid mechanism itself drives the differences (as opposed to demand characteristics or participant variability).
Authors: We agree the study is formative and exploratory. Its purpose was to surface qualitative patterns in perceived tradeoffs (accuracy, diversity, etc.) rather than to support statistical inference. No quantitative metrics or tests were collected because the protocol was not designed for hypothesis testing or effect-size estimation. We will revise the evaluation section to explicitly label the work as formative, state the absence of order-effect controls and statistical analysis, and frame the tradeoffs as preliminary observations that motivate future controlled studies. revision: yes
-
Referee: [System overview and abstract] Implementation details of the six item-selection methods and their integration into the visual analytics interface (including how model-driven active learning interacts with the human-driven approaches) are absent from the abstract and high-level evaluation summary. This prevents assessment of whether the hybrid design is reproducible or genuinely novel relative to prior singular-method baselines.
Authors: The abstract follows standard length constraints and therefore remains high-level; the six methods, their algorithmic realizations, and the precise interaction protocol with the active-learning ranking model are described in the System and Implementation sections of the manuscript. To address the concern about immediate assessability, we will expand the abstract with one sentence naming the six complementary strategies and will add a short cross-reference in the evaluation summary that points readers to the integration details. These changes improve accessibility while preserving the manuscript’s existing technical depth. revision: yes
Circularity Check
No circularity: design paper with external user study evaluation
full rationale
The paper presents a visual analytics system for item-based ranking using hybrid selection methods and evaluates it via a formative user study (N=10). No equations, derivations, fitted parameters, or predictions appear in the provided text. The central claim rests on the described system design and study observations rather than any self-referential reduction, self-citation chain, or renaming of known results. No load-bearing steps match the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Bradley Knox, and Todd Kulesza
S. Amershi, M. Cakmak, W. B. Knox, and T. Kulesza, “Power to the People: The Role of Humans in Interactive Machine Learning,”AI Magazine, vol. 35, no. 4, pp. 105–120, Dec. 2014. [Online]. Available: https://doi.org/10.1609/aimag.v35i4.2513
-
[2]
A Review of User Interface Design for Interactive Machine Learning,
J. J. Dudley and P. O. Kristensson, “A Review of User Interface Design for Interactive Machine Learning,”ACM Transactions on Interactive Intelligent Systems, vol. 8, no. 2, pp. 1–37, Jun. 2018. [Online]. Available: https://doi.org/10.1145/3185517
-
[3]
The human is the loop: new directions for visual analytics,
A. Endert, M. S. Hossain, N. Ramakrishnan, C. North, P. Fiaux, and C. Andrews, “The human is the loop: new directions for visual analytics,”Intelligent Information Systems, vol. 43, no. 3, pp. 411–435, Dec. 2014. [Online]. Available: https://doi.org/10.1007/ s10844-014-0304-9
2014
-
[5]
WeightLifter: Visual weight space exploration for multi-criteria decision making,
S. Pajer, M. Streit, T. Torsney-Weir, F. Spechtenhauser, T. M ¨oller, and H. Piringer, “WeightLifter: Visual weight space exploration for multi-criteria decision making,”IEEE Transactions on Visualization and Computer Graphics, vol. 23, no. 1, pp. 611–620, 2017. [Online]. Available: https://doi.org/10.1109/TVCG.2016.2598589
-
[6]
LineUp: Visual Analysis of Multi-Attribute Rankings,
S. Gratzl, A. Lex, N. Gehlenborg, H. Pfister, and M. Streit, “LineUp: Visual Analysis of Multi-Attribute Rankings,”IEEE Transactions on Visualization and Computer Graphics, vol. 19, no. 12, pp. 2277–2286, Dec. 2013. [Online]. Available: https://doi.org/10.1109/TVCG.2013.173
-
[8]
PA VED: pareto front visualization for engineering design,
L. Cibulski, H. Mitterhofer, T. May, and J. Kohlhammer, “PA VED: pareto front visualization for engineering design,”Computer Graphics Forum (CGF), vol. 39, no. 3, pp. 405–416, 2020. [Online]. Available: https://doi.org/10.1111/cgf.13990
-
[9]
How applicable are attribute-based approaches for human- centered ranking creation?
C.-M. Barth, J. Schmid, I. Al-Hazwani, M. Sachdeva, L. Cibulski, and J. Bernard, “How applicable are attribute-based approaches for human- centered ranking creation?”Computers & Graphics, vol. 114, pp. 45–58,
-
[10]
Available: https://doi.org/10.1016/j.cag.2023.05.004
[Online]. Available: https://doi.org/10.1016/j.cag.2023.05.004
-
[11]
Here or There: Preference Judgments for Relevance,
B. Carterette, P. Bennett, M. Chickering, and S. Dumais, “Here or There: Preference Judgments for Relevance,” inProceedings of ECIR. Springer, Jan. 2008. [On- line]. Available: https://www.microsoft.com/en-us/research/publication/ here-or-there-preference-judgments-for-relevance/
2008
-
[12]
Learning to Rank for Information Retrieval,
T.-Y . Liu, “Learning to Rank for Information Retrieval,”Foundations and Trends® in Information Retrieval, vol. 3, no. 3, pp. 225–331,
-
[13]
doi:10.1561/1500000016 , url =
[Online]. Available: https://doi.org/10.1561/1500000016
-
[14]
F. Xia, T.-Y . Liu, J. Wang, W. Zhang, and H. Li, “Listwise approach to learning to rank: theory and algorithm,” inInternational conference on Machine learning - ICML. ACM Press, 2008, pp. 1192–1199. [Online]. Available: https://doi.org/10.1145/1390156.1390306
-
[15]
Podium: Ranking Data Using Mixed-Initiative Visual Analytics,
E. Wall, S. Das, R. Chawla, B. Kalidindi, E. T. Brown, and A. Endert, “Podium: Ranking Data Using Mixed-Initiative Visual Analytics,”IEEE Transactions on Visualization and Computer Graphics, vol. 24, no. 1, pp. 288–297, Jan. 2018. [Online]. Available: https://doi.org/10.1109/TVCG.2017.2745078
-
[16]
Preference- driven interactive ranking system for personalized decision support,
C. Kuhlman, S. Yang, X. Sun, and E. A. Rundensteiner, “Preference- driven interactive ranking system for personalized decision support,” inACM International Conference on Information and Knowledge Management. ACM, 2018, pp. 1931–1934. [Online]. Available: https://doi.org/10.1145/3269206.3269227
-
[17]
Active Learning Literature Survey,
B. Settles, “Active Learning Literature Survey,” University of Wiscon- sin–Madison, Computer Sciences Technical Report 1648, 2009
2009
-
[18]
A survey on instance selection for active learning,
Y . Fu, X. Zhu, and B. Li, “A survey on instance selection for active learning,”Knowledge and Information Systems, vol. 35, no. 2, pp. 249–283, May 2013. [Online]. Available: http://link.springer.com/10. 1007/s10115-012-0507-8
2013
-
[19]
About Last.fm,
Last.fm Ltd., “About Last.fm,” publication Title: Last.fm. [Online]. Available: https://www.last.fm/about
-
[20]
How much metadata do we need in music recommendation? A subjective evaluation using preference sets,
D. Bogdanov and P. Herrera, “How much metadata do we need in music recommendation? A subjective evaluation using preference sets,” inInternational Society for Music Information Retrieval Conference, (ISMIR). University of Miami, 2011, pp. 97–102. [Online]. Available: http://ismir2011.ismir.net/papers/PS1-10.pdf
2011
-
[21]
C. Seifert and M. Granitzer, “User-based active learning,” inIEEE Conference on Data Mining Workshops (ICDMW). IEEE, 2010, pp. 418–425. [Online]. Available: https://doi.org/10.1109/ICDMW.2010.181
-
[22]
Inter-active learning of ad-hoc classifiers for video visual analytics,
B. H ¨oferlin, R. Netzel, M. H ¨oferlin, D. Weiskopf, and G. Heidemann, “Inter-active learning of ad-hoc classifiers for video visual analytics,” in IEEE Visual Analytics Science and Technology (VAST). IEEE, 2012, pp. 23–32. [Online]. Available: https://doi.org/10.1109/V AST.2012.6400492
work page doi:10.1109/v 2012
-
[23]
VIAL: a unified process for visual interactive labeling,
J. Bernard, M. Zeppelzauer, M. Sedlmair, and W. Aigner, “VIAL: a unified process for visual interactive labeling,”The Visual Computer, vol. 34, no. 9, pp. 1189–1207, Sep. 2018. [Online]. Available: https://doi.org/10.1007/s00371-018-1500-3
-
[24]
J. Bernard, M. Hutter, M. Sedlmair, M. Zeppelzauer, and T. Munzner, “A Taxonomy of Property Measures to Unify Active Learning and Human-centered Approaches to Data Labeling,”ACM Transactions on Interactive Intelligent Systems, vol. 11, no. 3-4, pp. 1–42, Dec. 2021. [Online]. Available: https://doi.org/10.1145/3439333
-
[25]
Towards User-Centered Active Learning Algorithms,
J. Bernard, M. Zeppelzauer, M. Lehmann, M. M ¨uller, and M. Sedlmair, “Towards User-Centered Active Learning Algorithms,”Computer Graphics Forum, vol. 37, no. 3, pp. 121–132, Jun. 2018. [Online]. Available: https://doi.org/10.1111/cgf.13406
-
[26]
Comparing visual-interactive labeling with active learning: An experimental study,
J. Bernard, M. Hutter, M. Zeppelzauer, D. Fellner, and M. Sedlmair, “Comparing visual-interactive labeling with active learning: An experimental study,”IEEE Transactions on Visualization and Computer Graphics (TCVG), vol. 24, no. 1, pp. 298–308, 2018. [Online]. Available: https://doi.org/10.1109/TVCG.2017.2744818
-
[27]
Interactive visual labelling versus active learning: An experimental comparison,
M. Chegini, J. Bernard, J. Cui, F. Chegini, A. Sourin, K. Andrews, and T. Schreck, “Interactive visual labelling versus active learning: An experimental comparison,”Frontiers of Information Technology & Electronic Engineering (FITEE), vol. 21, no. 4, pp. 524–535, 2020. [Online]. Available: https://doi.org/10.1631/FITEE.1900549
-
[28]
Personalized Visual-Interactive Music Classification,
C. Ritter, C. Altenhofen, M. Zeppelzauer, A. Kuijper, T. Schreck, and J. Bernard, “Personalized Visual-Interactive Music Classification,” EuroVis Workshop on Visual Analytics (EuroVA), p. 5 pages, 2018. [Online]. Available: https://doi.org/10.2312/EUROV A.20181109
-
[29]
R. Sevastjanova, W. Jentner, F. Sperrle, R. Kehlbeck, J. Bernard, and M. El-Assady, “Questioncomb: A gamification approach for the visual explanation of linguistic phenomena through interactive labeling,”ACM Transactions on Interactive Intelligent Systems (TiiS), vol. 11, no. 3–4, pp. 1–38, 2021. [Online]. Available: https://doi.org/10.1145/3429448
-
[30]
M. A. Hearst,Search User Interfaces, 1st ed. Cam- bridge University Press, Sep. 2009. [Online]. Available: https://doi.org/10.1017/CBO9781139644082
-
[31]
Celma,Music Recommendation and Discovery: The Long Tail, Long Fail, and Long Play in the Digital Music Space
O. Celma,Music Recommendation and Discovery: The Long Tail, Long Fail, and Long Play in the Digital Music Space. Springer Berlin Heidelberg, 2010. [Online]. Available: https://doi.org/10.1007/ 978-3-642-13287-2
2010
-
[32]
UMAP: Uniform Manifold Approximation and Projection for Dimension Reduction,
L. McInnes, J. Healy, and J. Melville, “UMAP: Uniform Manifold Approximation and Projection for Dimension Reduction,”arXiv preprint arXiv:1802.03426, 2018. [Online]. Available: https://doi.org/10.48550/ ARXIV .1802.03426
Pith/arXiv arXiv 2018
-
[33]
LightGBM: A Highly Efficient Gradient Boosting Decision Tree,
G. Ke, Q. Meng, T. Finley, T. Wang, W. Chen, W. Ma, Q. Ye, and T.-Y . Liu, “LightGBM: A Highly Efficient Gradient Boosting Decision Tree,” inAdvances in Neural Information Processing Systems, vol. 30. Curran Associates, Inc., 2017. [Online]. Available: https://proceedings.neurips. cc/paper/2017/file/6449f44a102fde848669bdd9eb6b76fa-Paper.pdf
2017
-
[34]
LightGBM - Features - Revision 24af9fa5,
Microsoft Corporation, “LightGBM - Features - Revision 24af9fa5,”
-
[35]
Available: https://lightgbm.readthedocs.io/en/latest/ Features.html
[Online]. Available: https://lightgbm.readthedocs.io/en/latest/ Features.html
-
[36]
A unified approach to interpreting model predictions,
S. M. Lundberg and S.-I. Lee, “A unified approach to interpreting model predictions,”Advances in Neural Information Processing Systems, vol. 30, 2017. [Online]. Available: https://proceedings.neurips. cc/paper/2017/file/8a20a8621978632d76c43dfd28b67767-Paper.pdf
2017
-
[37]
In: Medical Imaging with Deep Learning (MIDL)
I. A. Hazwani, J. Schmid, M. Sachdeva, and J. Bernard, “A Design Space for Explainable Ranking and Ranking Models,” arXiv preprint arXiv:2205.15305, 2022. [Online]. Available: https: //doi.org/10.48550/ARXIV .2205.15305
work page internal anchor Pith review doi:10.48550/arxiv 2022
-
[38]
A survey of visual analytics for Explainable Artificial Intelligence methods,
G. Alicioglu and B. Sun, “A survey of visual analytics for Explainable Artificial Intelligence methods,”Computers & Graphics, vol. 102, pp. 502–520, Feb. 2022. [Online]. Available: https: //doi.org/10.1016/j.cag.2021.09.002
-
[39]
A user-centric evaluation framework for recommender systems,
P. Pu, L. Chen, and R. Hu, “A user-centric evaluation framework for recommender systems,” inACM conference on Recommender systems. ACM, Oct. 2011, pp. 157–164. [Online]. Available: https://doi.org/10.1145/2043932.2043962
-
[40]
S. G. Hart and L. E. Staveland, “Development of nasa-tlx (task load index): Results of empirical and theoretical research,” inAdvances in psychology. Elsevier, 1988, vol. 52, pp. 139–183. [Online]. Available: https://doi.org/10.1016/S0166-4115(08)62386-9
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.