Sample-Efficient Diffusion-based Reinforcement Learning with Critic Guidance
Pith reviewed 2026-06-29 07:19 UTC · model grok-4.3
The pith
Critic guidance during diffusion denoising steers RL policies toward high-value actions without extra training steps.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
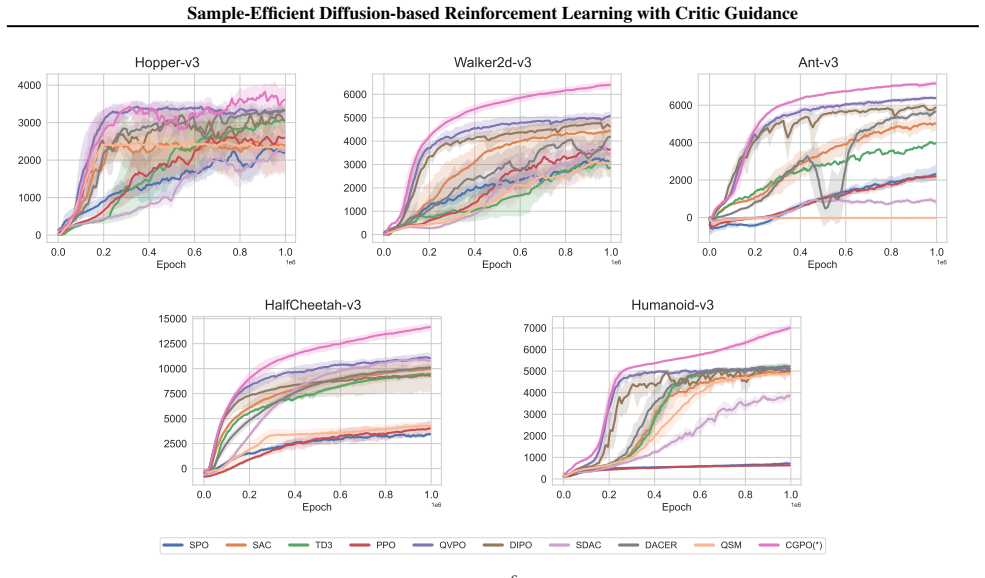
CGPO steers action generation toward high-value regions defined by the critic network and uses the guided actions as regression objectives. In this manner, CGPO reduces the time required to obtain high-quality actions and improves final performance with better balance between the exploration-exploitation tradeoff.
What carries the argument
Training-free critic guidance inserted into the diffusion denoising process, which redirects each denoising step toward regions favored by the critic before the policy is regressed on the resulting actions.
If this is right
- Policy optimization converges in fewer environment steps than pure sampling-based diffusion RL.
- Action distributions retain higher diversity than gradient-based diffusion RL methods.
- The same guided-denoising procedure transfers to a real Franka arm and outperforms prior diffusion policies on grasping.
- State-of-the-art returns are reached on five standard MuJoCo locomotion benchmarks.
Where Pith is reading between the lines
- The approach may extend naturally to offline RL settings where the critic is already trained on a fixed dataset.
- If the critic is inaccurate early in training, the guidance could initially reinforce suboptimal modes until the critic improves.
- Replacing the critic with a learned value model from a different architecture could test whether the guidance benefit is specific to the Q-network used here.
Load-bearing premise
The critic network supplies sufficiently accurate high-value regions that can be used for training-free guidance inside the diffusion denoising process without introducing harmful bias or requiring additional optimization.
What would settle it
A controlled ablation on the same MuJoCo tasks in which CGPO with the critic guidance removed shows no reduction in sample complexity or final return compared with standard diffusion RL baselines.
Figures






read the original abstract
Recent advances in reinforcement learning (RL) have achieved great successes by leveraging the multimodality and exploration capability of diffusion policies. Among these approaches, one representative branch focuses on the sampling-based policy optimization. This design enables better exploration capability of the diffusion model, particularly at the beginning of training, but suffer from low exploitation in Q-value information, resulting in a slow policy convergence. Another branch pays attention to gradient-based policy optimization, which sufficiently exploits the gradient of the Q function yet tends to collapse into a unimodal policy with low diversity. To address this issue, we propose CGPO, \textbf{C}ritic-\textbf{G}uided diffusion \textbf{P}olicy \textbf{O}ptimization, which effectively balances exploration and exploitation with the training-free guidance technique integrated into the denoising process of diffusion policy. Concretely, CGPO steers action generation toward high-value regions defined by the critic network and uses the guided actions as regression objectives. In this manner, CGPO reduces the time required to obtain high-quality actions and improves final performance with better balance between the exploration-exploitation tradeoff. We validate the effectiveness of CGPO on 5 MuJoCo locomotion tasks, and CGPO achieves state-of-the-art performance compared with existing diffusion-based RL methods. Notably, CGPO is the first success to incorporate diffusion policy into real-world RL, with its superior performance on Franka robot arm grasping tasks. Our official page is released at https://dingsht.tech/cgpo-webpage.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes CGPO (Critic-Guided diffusion Policy Optimization), a diffusion-based RL method that integrates training-free critic guidance into the denoising process to steer generated actions toward high-value regions from the critic network; these guided actions then serve as regression targets. The approach is claimed to better balance exploration and exploitation compared to prior sampling-based or gradient-based diffusion RL methods, yielding SOTA results on 5 MuJoCo locomotion tasks and the first reported real-world success of diffusion policies on Franka robot arm grasping.
Significance. If the empirical claims hold with proper validation, the work would be significant for demonstrating a practical way to inject critic information into diffusion policies without additional optimization steps, potentially improving sample efficiency in continuous control. The real-world robot deployment, if substantiated, would mark a notable milestone for diffusion policies in RL.
major comments (3)
- [Abstract] Abstract: The central performance claims (SOTA results on MuJoCo tasks and superior real-world performance on Franka) are stated without any reference to experimental protocol, baselines, number of random seeds, error bars, statistical significance, or ablation studies. This absence makes the soundness of the empirical contribution impossible to evaluate from the manuscript text.
- [Abstract (mechanism description)] The core mechanism (critic-guided denoising treated as training-free) assumes the critic supplies sufficiently accurate high-value modes even early in training; no analysis, error propagation study, or safeguard against bias from inaccurate early Q-values is provided. This assumption is load-bearing for the sample-efficiency and convergence claims.
- [Abstract] No equations, derivations, or pseudocode for the guidance step appear in the abstract, and the full text provides no self-contained derivation showing how the guided samples avoid introducing harmful bias into the regression objective.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and indicate where revisions will be made to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central performance claims (SOTA results on MuJoCo tasks and superior real-world performance on Franka) are stated without any reference to experimental protocol, baselines, number of random seeds, error bars, statistical significance, or ablation studies. This absence makes the soundness of the empirical contribution impossible to evaluate from the manuscript text.
Authors: We acknowledge that the abstract prioritizes brevity and does not detail the experimental protocol. The full manuscript (Section 4) specifies evaluation on 5 MuJoCo locomotion tasks against diffusion-based RL baselines, results averaged over 5 random seeds with error bars, and ablations on guidance components. We will revise the abstract to include a concise reference to the evaluation protocol and statistical validation to improve self-containment. revision: partial
-
Referee: [Abstract (mechanism description)] The core mechanism (critic-guided denoising treated as training-free) assumes the critic supplies sufficiently accurate high-value modes even early in training; no analysis, error propagation study, or safeguard against bias from inaccurate early Q-values is provided. This assumption is load-bearing for the sample-efficiency and convergence claims.
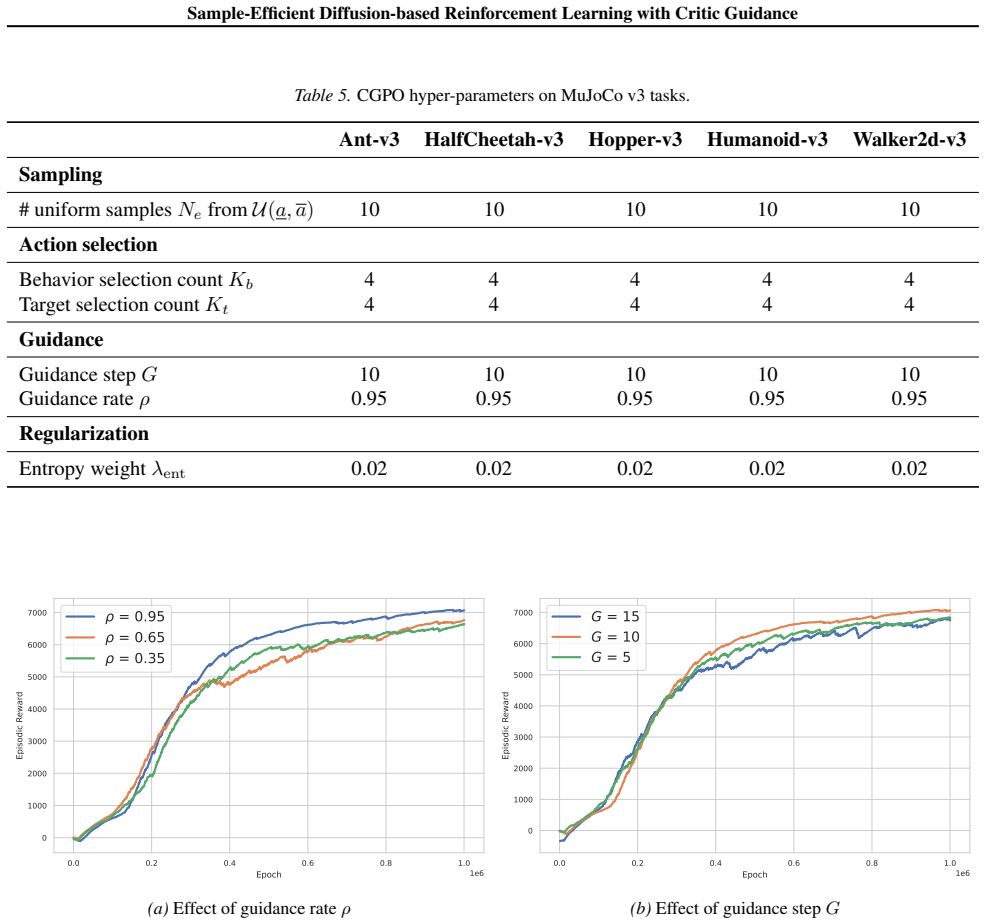
Authors: The paper notes that the critic is updated in tandem with the policy and that guidance is applied with a schedule to limit early influence. We agree an explicit analysis of early-training bias would strengthen the claims. We will add a discussion subsection addressing potential error propagation from inaccurate early Q-values and introduce safeguards such as a delayed target critic. revision: yes
-
Referee: [Abstract] No equations, derivations, or pseudocode for the guidance step appear in the abstract, and the full text provides no self-contained derivation showing how the guided samples avoid introducing harmful bias into the regression objective.
Authors: The abstract omits equations for length reasons. Section 3 of the manuscript formulates the guidance step as a Q-gradient adjustment to the denoising process and states that the resulting actions serve as regression targets. To address the request for a self-contained derivation, we will add explicit pseudocode and a short proof sketch in the revised main text or appendix clarifying that the guidance approximates a policy improvement step without additional bias beyond the critic's own approximation error. revision: yes
Circularity Check
No circularity; no derivations or equations present
full rationale
The abstract and description contain no equations, derivations, or mathematical steps. Claims rest on empirical validation against external MuJoCo and robot benchmarks rather than any self-referential fitting, self-citation chains, or reductions of predictions to inputs by construction. The method description (critic-guided denoising used as regression targets) is presented at a conceptual level without load-bearing math that could be inspected for circularity. This is the expected honest outcome when no derivation chain exists to analyze.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Critic network outputs define reliable high-value regions usable for guidance without retraining.
Reference graph
Works this paper leans on
-
[1]
Simple hierarchical planning with diffusion.arXiv preprint arXiv:2401.02644,
Chen, C., Deng, F., Kawaguchi, K., Gulcehre, C., and Ahn, S. Simple hierarchical planning with diffusion.arXiv preprint arXiv:2401.02644,
-
[2]
Diffusion Policy: Visuomotor Policy Learning via Action Diffusion
Chi, C., Feng, S., Du, Y ., Xu, Z., Cousineau, E., Burch- fiel, B., and Song, S. Diffusion policy: Visuomotor policy learning via action diffusion.arXiv preprint arXiv:2303.04137,
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
T., Klasky, M
Chung, H., Kim, J., McCann, M. T., Klasky, M. L., and Ye, J. C. Diffusion posterior sampling for general noisy inverse problems. In11th International Conference on Learning Representations, ICLR 2023,
2023
-
[4]
Ding, S., Hu, K., Zhong, S., Luo, H., Zhang, W., Wang, J., Wang, J., and Shi, Y . Genpo: Generative diffusion models meet on-policy reinforcement learning.arXiv preprint arXiv:2505.18763,
-
[5]
Classifier-Free Diffusion Guidance
Ho, J. and Salimans, T. Classifier-free diffusion guidance. arXiv preprint arXiv:2207.12598,
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
Offline Reinforcement Learning: Tutorial, Review, and Perspectives on Open Problems
Levine, S., Kumar, A., Tucker, G., and Fu, J. Offline rein- forcement learning: Tutorial, review, and perspectives on open problems.arXiv preprint arXiv:2005.01643,
work page internal anchor Pith review Pith/arXiv arXiv 2005
-
[7]
Flow matching policy gradients.arXiv preprint arXiv:2507.21053, 2025
McAllister, D., Ge, S., Yi, B., Kim, C. M., Weber, E., Choi, H., Feng, H., and Kanazawa, A. Flow matching policy gradients.arXiv preprint arXiv:2507.21053,
-
[8]
Flow q-learning.arXiv preprint arXiv:2502.02538,
Park, S., Li, Q., and Levine, S. Flow q-learning.arXiv preprint arXiv:2502.02538,
-
[9]
Psenka, M., Escontrela, A., Abbeel, P., and Ma, Y . Learn- ing a diffusion model policy from rewards via q-score matching.arXiv preprint arXiv:2312.11752,
-
[10]
Diffusion Policy Policy Optimization
Ren, A. Z., Lidard, J., Ankile, L. L., Simeonov, A., Agrawal, P., Majumdar, A., Burchfiel, B., Dai, H., and Simchowitz, M. Diffusion policy policy optimization.arXiv preprint arXiv:2409.00588,
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
Proximal Policy Optimization Algorithms
Schulman, J., Wolski, F., Dhariwal, P., Radford, A., and Klimov, O. Proximal policy optimization algorithms. arXiv preprint arXiv:1707.06347,
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
Denoising Diffusion Implicit Models
Song, J., Meng, C., and Ermon, S. Denoising diffusion im- plicit models.arXiv preprint arXiv:2010.02502, 2020a. Song, J., Zhang, Q., Yin, H., Mardani, M., Liu, M.-Y ., Kautz, J., Chen, Y ., and Vahdat, A. Loss-guided diffu- sion models for plug-and-play controllable generation. InInternational Conference on Machine Learning, pp. 32483–32498. PMLR,
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[13]
Score-Based Generative Modeling through Stochastic Differential Equations
Song, Y ., Sohl-Dickstein, J., Kingma, D. P., Kumar, A., Er- mon, S., and Poole, B. Score-based generative modeling through stochastic differential equations.arXiv preprint arXiv:2011.13456, 2020b. Sutton, R. S., McAllester, D., Singh, S., and Mansour, Y . Policy gradient methods for reinforcement learning with function approximation.Advances in neural in...
work page internal anchor Pith review Pith/arXiv arXiv 2011
-
[14]
doi: 10.1109/IROS.2012. 6386109. Van Hasselt, H., Guez, A., and Silver, D. Deep reinforce- ment learning with double q-learning. InProceedings of the AAAI conference on artificial intelligence, volume 30,
-
[15]
Steering Your Diffusion Policy with Latent Space Reinforcement Learning
Wagenmaker, A., Nakamoto, M., Zhang, Y ., Park, S., Yagoub, W., Nagabandi, A., Gupta, A., and Levine, S. Steering your diffusion policy with latent space reinforce- ment learning.arXiv preprint arXiv:2506.15799,
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
Policy representation via diffusion probability model for reinforcement learning
Yang, L., Huang, Z., Lei, F., Zhong, Y ., Yang, Y ., Fang, C., Wen, S., Zhou, B., and Lin, Z. Policy representation via diffusion probability model for reinforcement learning. arXiv preprint arXiv:2305.13122,
-
[17]
Real-world reinforcement learning from suboptimal interventions
Zhao, Y ., Jin, H., Jiang, L., Zhang, X., Wu, K., Ren, P., Xu, Z., Che, Z., Sun, L., Wu, D., et al. Real-world reinforcement learning from suboptimal interventions. arXiv preprint arXiv:2512.24288,
-
[18]
Zhu, Y ., Joshi, A., Stone, P., and Zhu, Y . Viola: Imitation learning for vision-based manipulation with object pro- posal priors.arXiv preprint arXiv:2210.11339,
-
[19]
doi: 10.48550/arXiv.2210.11339. 11 Sample-Efficient Diffusion-based Reinforcement Learning with Critic Guidance A. Proofs A.1. Relative Entropy Policy Search Relative Entropy Policy Search (REPS) derives a closed-form update for a new sampling distribution by maximizing expected return while constraining the KL divergence to a reference distribution: πk+1...
-
[20]
i (45) ≈ ∇ at logπ t(at) +∇ at Eπ(a0|at) [f(a0)](46) ≈ ∇ at logπ t(at) +∇ at f(E π(a0|at)[a0])(47) =s θ(at) +∇ at Q(s,ˆa0(at)),(48) wheres θ(at)is the score of the diffusion model andˆa0(at)is the posterior estimation via tweedie’s formula. B. More Details on Practical Implementation B.1. Diffusion Guidance with Spherical Gaussian Algorithm This appendix ...
2024
-
[21]
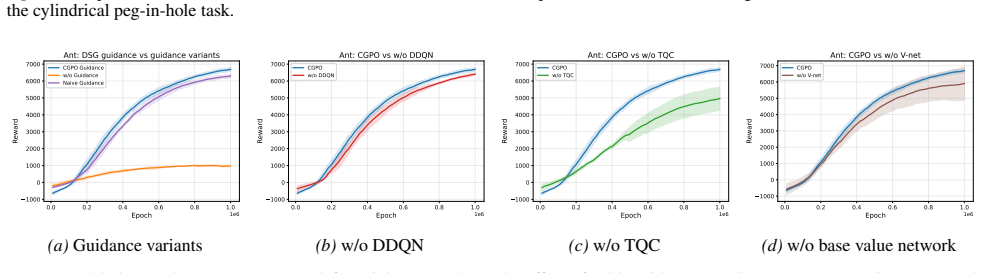
The left panel compares DSG guidance with unguided target generation and naive guidance. Removing guidance leads to weaker learning, while naive guidance improves over the unguided variant but still underperforms full CGPO, indicating that the form of guidance is important. This supports the use of DSG as a structured guidance rule that is better aligned ...
2000
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.