Efficient RGB-T Object Detection via Sparse Cross-Modality Fusion
Pith reviewed 2026-06-30 06:14 UTC · model grok-4.3
The pith
A sparse cross-modality fusion approach enables efficient RGB-T object detection by first identifying high-recall proposals with lightweight single-modality models and then fusing features only on those sparse regions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
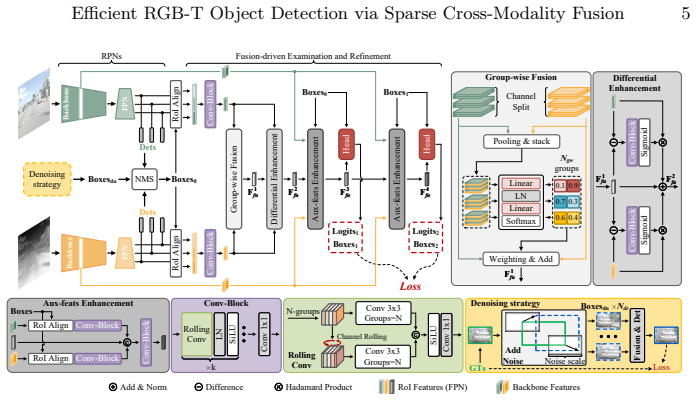
The paper establishes that efficient RGB-T object detection is achievable through a sparse cross-modality fusion mechanism implemented as a two-stage framework. In the first stage, modality-specific lightweight detectors rapidly produce high-recall regions of interest across the image. The second stage then performs feature fusion and refinement exclusively on these sparse proposals, filtering false positives and adjusting bounding boxes. This allows the system to allocate computational resources adaptively to potential foreground areas rather than processing the entire image uniformly.
What carries the argument
The sparse fusion mechanism that restricts cross-modality feature fusion to high-recall RoIs identified by lightweight single-modality detectors.
If this is right
- Competitive detection performance is maintained despite using substantially fewer parameters.
- Computational cost is significantly reduced compared to exhaustive fusion methods.
- The approach scales effectively to high-resolution input images.
- Detection accuracy remains high under challenging conditions by leveraging complementary modality strengths only where needed.
Where Pith is reading between the lines
- Similar sparse strategies could apply to other sensor fusion tasks in computer vision where background regions predominate.
- The method might enable real-time RGB-T detection on resource-constrained devices like drones or mobile cameras.
- If the first-stage recall drops in certain environments, overall system performance could degrade more than in dense-fusion baselines.
Load-bearing premise
The assumption that most image regions consist of smooth backgrounds easily processed by lightweight single-modality models without missing objects.
What would settle it
A test on images where backgrounds contain many false-object-like textures or small objects are distributed evenly would show if the lightweight first stage fails to achieve high recall, causing the overall detector to underperform full-fusion alternatives.
Figures



read the original abstract
RGB-T detectors leverage the complementary strengths of visible and thermal infrared modalities, achieving robust performance under challenging conditions. Many of them resort to heavy dual backbones and exhaustive cross-modality fusion across the entire image, leading to impractically high computational costs. We observe that most image regions are smooth backgrounds (e.g., sky, ground) that can be easily handled by lightweight single-modality models. In light of this observation, we propose a sparse fusion mechanism for efficient RGB-T detection: first rapidly scanning the image to identify the proposals and then carefully examining the remaining sparse proposals via feature fusion. We propose a two-stage framework to instantiate this mechanism, which performs detection in two stages: 1) a lightweight and modality-specific detection stage that produces high-recall RoIs, and 2) a fusion-driven examination and refinement stage that filters out the false positives and refines the bounding boxes. This design enables the detector to adaptively allocate more computational resources to the potential foregrounds, improving the efficiency while ensuring detection accuracy. Extensive experiments show that our method achieves competitive performance with substantially fewer parameters and lower cost, while maintaining strong scalability to high-resolution images.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a two-stage sparse cross-modality fusion framework for efficient RGB-T object detection. A lightweight modality-specific first stage rapidly generates high-recall RoIs by exploiting the observation that most regions are smooth backgrounds; a second stage then performs feature fusion only on the sparse proposals to filter false positives and refine boxes. The authors claim this adaptively allocates compute to foregrounds, yielding competitive accuracy with substantially fewer parameters, lower cost, and good scalability to high-resolution images.
Significance. If the performance claims are substantiated, the work would provide a practical route to reducing the computational burden of dual-backbone RGB-T detectors by exploiting foreground sparsity, with relevance to real-time or resource-limited applications. The design choice is a direct response to the cost of exhaustive fusion and could influence subsequent efficient multi-modal architectures.
major comments (2)
- [Abstract] Abstract: the central claims of 'competitive performance with substantially fewer parameters and lower cost' are asserted without any quantitative tables, ablation studies, error bars, implementation details, or baseline comparisons, leaving the efficiency and accuracy assertions unsupported by visible evidence.
- [Abstract] Abstract: the load-bearing assumption that the lightweight single-modality first stage reliably produces high-recall RoIs (so that no object is irrecoverably missed before the fusion stage) is justified only by the qualitative 'smooth backgrounds' observation; no recall bounds, failure-mode analysis, or cross-condition validation is supplied, making the two-stage guarantee unverified.
minor comments (1)
- [Abstract] Abstract: the terms 'high-recall RoIs' and 'sparse proposals' are used without quantitative thresholds or definitions, which would help clarify the sparsity mechanism.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the abstract. We agree that the abstract can be strengthened to better substantiate its claims and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claims of 'competitive performance with substantially fewer parameters and lower cost' are asserted without any quantitative tables, ablation studies, error bars, implementation details, or baseline comparisons, leaving the efficiency and accuracy assertions unsupported by visible evidence.
Authors: The abstract is a concise summary, with the supporting quantitative evidence (including parameter counts, FLOPs, mAP comparisons to baselines, ablations, and implementation details) presented in the Experiments section of the full manuscript. We will revise the abstract to incorporate key quantitative highlights from those results to make the efficiency and accuracy claims more directly supported within the abstract itself. revision: yes
-
Referee: [Abstract] Abstract: the load-bearing assumption that the lightweight single-modality first stage reliably produces high-recall RoIs (so that no object is irrecoverably missed before the fusion stage) is justified only by the qualitative 'smooth backgrounds' observation; no recall bounds, failure-mode analysis, or cross-condition validation is supplied, making the two-stage guarantee unverified.
Authors: The abstract motivates the high-recall first stage via the smooth-background observation, with the full method and overall validation in later sections. To directly address the concern about verification of the two-stage guarantee, we will add a targeted analysis (including first-stage recall metrics, discussion of failure modes, and cross-condition checks) to the revised manuscript. revision: yes
Circularity Check
No circularity: architectural proposal with no derivation chain
full rationale
The paper advances a two-stage RGB-T detector design motivated by the observation that most image regions are smooth backgrounds. No equations, fitted parameters, predictions, or self-citations appear in the provided text. The high-recall RoI stage is presented as an empirical assumption enabling the sparse-fusion architecture rather than a quantity derived from or equivalent to the final result. The contribution is therefore a self-contained engineering choice validated externally by experiments, with no load-bearing step that reduces by construction to its own inputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Most image regions are smooth backgrounds that can be easily handled by lightweight single-modality models
Reference graph
Works this paper leans on
-
[1]
YOLOv4: Optimal Speed and Accuracy of Object Detection
Bochkovskiy, A., Wang, C.Y., Liao, H.Y.M.: Yolov4: Optimal speed and accuracy of object detection. arXiv preprint arXiv:2004.10934 (2020)
work page internal anchor Pith review Pith/arXiv arXiv 2004
-
[2]
Knowledge-Based Systems268, 110423 (May 2023).https://doi
Chen, K., Liu, J., Zhang, H.: Igt: Illumination-guided rgb-t object detection with transformers. Knowledge-Based Systems268, 110423 (May 2023).https://doi. org/10.1016/j.knosys.2023.110423
-
[3]
In: European Conference on Computer Vision
Chen, Y.T., Shi, J., Ye, Z., Mertz, C., Ramanan, D., Kong, S.: Multimodal ob- ject detection via probabilistic ensembling. In: European Conference on Computer Vision. pp. 139–158. Springer (2022)
2022
-
[4]
In: Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision
Deevi, S.A., Lee, C., Gan, L., Nagesh, S., Pandey, G., Chung, S.J.: Rgb-x ob- ject detection via scene-specific fusion modules. In: Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision. pp. 7366–7375 (2024)
2024
-
[6]
IEEE Transactions on Multimedia p
Dong, W., Zhu, H., Lin, S., Luo, X., Shen, Y., Guo, G., Zhang, B.: Fusion-mamba for cross-modality object detection. IEEE Transactions on Multimedia p. 1–15 (2025).https://doi.org/10.1109/TMM.2025.3599020
-
[7]
In: 2021 IEEE/CVF International Conference on Computer Vision (ICCV)
Feng, C., Zhong, Y., Gao, Y., Scott, M.R., Huang, W.: Tood: Task-aligned one- stage object detection. In: 2021 IEEE/CVF International Conference on Computer Vision (ICCV). pp. 3490–3499. IEEE Computer Society (2021)
2021
-
[8]
YOLOX: Exceeding YOLO Series in 2021
Ge, Z., Liu, S., Wang, F., Li, Z., Sun, J.: Yolox: Exceeding yolo series in 2021. arXiv preprint arXiv:2107.08430 (2021)
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[9]
In: First conference on language modeling (2024)
Gu, A., Dao, T.: Mamba: Linear-time sequence modeling with selective state spaces. In: First conference on language modeling (2024)
2024
-
[10]
In: Proceedings of the IEEE international conference on computer vision
He, K., Gkioxari, G., Dollár, P., Girshick, R.: Mask r-cnn. In: Proceedings of the IEEE international conference on computer vision. pp. 2961–2969 (2017)
2017
-
[11]
In: Proceedings of the 31st ACM International Conference on Multimedia
He, X., Tang, C., Zou, X., Zhang, W.: Multispectral object detection via cross- modal conflict-aware learning. In: Proceedings of the 31st ACM International Conference on Multimedia. p. 1465–1474. ACM, Ottawa ON Canada (Oct 2023). https://doi.org/10.1145/3581783.3612651,https://dl.acm.org/doi/10. 1145/3581783.3612651
-
[12]
Hu, K., He, Y., Li, Y., Zhao, J., Chen, S., Kang, Y.: Ei²det: Edge-guided illumination-aware interactive learning for visible-infrared object detection. IEEE Transactions on Circuits and Systems for Video Technology35(7), 7101–7115 (July 2025).https://doi.org/10.1109/TCSVT.2025.3539625
-
[13]
In: Proceedings of the IEEE conference on computer vision and pattern recognition
Hwang, S., Park, J., Kim, N., Choi, Y., So Kweon, I.: Multispectral pedestrian detection: Benchmark dataset and baseline. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 1037–1045 (2015)
2015
-
[14]
In: Proceedings of the IEEE/CVF international con- ference on computer vision
Jia, X., Zhu, C., Li, M., Tang, W., Zhou, W.: Llvip: A visible-infrared paired dataset for low-light vision. In: Proceedings of the IEEE/CVF international con- ference on computer vision. pp. 3496–3504 (2021)
2021
-
[15]
Kim, J.U., Park, S., Ro, Y.M.: Uncertainty-guided cross-modal learning for robust multispectral pedestrian detection. IEEE Transactions on Circuits and Systems for Video Technology32(3), 1510–1523 (Mar 2022).https://doi.org/10.1109/ TCSVT.2021.3076466
-
[16]
Pattern Recognition Letters179, 144–150 (2024) Efficient RGB-T Object Detection via Sparse Cross-Modality Fusion 17
Lee, S., Park, J., Park, J.: Crossformer: Cross-guided attention for multi-modal object detection. Pattern Recognition Letters179, 144–150 (2024) Efficient RGB-T Object Detection via Sparse Cross-Modality Fusion 17
2024
-
[17]
In: Proceedings of the IEEE/CVF con- ference on computer vision and pattern recognition
Li, F., Zhang, H., Liu, S., Guo, J., Ni, L.M., Zhang, L.: Dn-detr: Accelerate detr training by introducing query denoising. In: Proceedings of the IEEE/CVF con- ference on computer vision and pattern recognition. pp. 13619–13627 (2022)
2022
-
[18]
IEEE Transactions on Multi- media (2022)
Li, Q., Zhang, C., Hu, Q., Fu, H., Zhu, P.: Confidence-aware fusion using dempster- shafer theory for multispectral pedestrian detection. IEEE Transactions on Multi- media (2022)
2022
-
[19]
Advances in neural information processing systems33, 21002–21012 (2020)
Li, X., Wang, W., Wu, L., Chen, S., Hu, X., Li, J., Tang, J., Yang, J.: General- ized focal loss: Learning qualified and distributed bounding boxes for dense object detection. Advances in neural information processing systems33, 21002–21012 (2020)
2020
-
[20]
Multispectral Deep Neural Networks for Pedestrian Detection
Liu, J., Zhang, S., Wang, S., Metaxas, D.N.: Multispectral deep neural networks for pedestrian detection. arXiv preprint arXiv:1611.02644 (2016)
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[21]
In: Proceedings of the IEEE/CVF con- ference on computer vision and pattern recognition
Liu, J., Fan, X., Huang, Z., Wu, G., Liu, R., Zhong, W., Luo, Z.: Target-aware dual adversarial learning and a multi-scenario multi-modality benchmark to fuse infrared and visible for object detection. In: Proceedings of the IEEE/CVF con- ference on computer vision and pattern recognition. pp. 5802–5811 (2022)
2022
-
[22]
Cross-modality fusion transformer for multispectral object detection,
Qingyun, F., Dapeng, H., Zhaokui, W.: Cross-modality fusion transformer for mul- tispectral object detection. arXiv preprint arXiv:2111.00273 (2021)
-
[23]
In: Proceedings of the IEEE conference on computer vision and pattern recognition
Redmon, J., Divvala, S., Girshick, R., Farhadi, A.: You only look once: Unified, real-time object detection. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 779–788 (2016)
2016
-
[24]
YOLOv3: An Incremental Improvement
Redmon, J., Farhadi, A.: Yolov3: An incremental improvement. arXiv preprint arXiv:1804.02767 (2018)
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[25]
Pattern Recog- nition145, 109913 (2024)
Shen, J., Chen, Y., Liu, Y., Zuo, X., Fan, H., Yang, W.: Icafusion: Iterative cross- attention guided feature fusion for multispectral object detection. Pattern Recog- nition145, 109913 (2024)
2024
-
[26]
Tian, C., Yang, C., Zhu, G., Wang, Q., He, Z.: Learning a robust rgb-thermal detector for extreme modality imbalance. Pattern Recognition Letters196, 1–8 (2025).https://doi.org/https://doi.org/10.1016/j.patrec.2025.05.005
-
[27]
IEEE Transactions on Multimedia26, 6449–6461 (2024)
Tian, C., Zhou, Z., Huang, Y., Li, G., He, Z.: Cross-modality proposal-guided fea- ture mining for unregistered rgb-thermal pedestrian detection. IEEE Transactions on Multimedia26, 6449–6461 (2024)
2024
-
[28]
Ultralytics:https://github.com/ultralytics/ultralytics
-
[29]
Computational Intelligence (2016)
Wagner, J., Fischer, V., Herman, M., Behnke, S.: Multispectral pedestrian detec- tion using deep fusion convolutional neural networks. Computational Intelligence (2016)
2016
-
[30]
Advances in Neural Information Processing Systems 37, 107984–108011 (2024)
Wang, A., Chen, H., Liu, L., Chen, K., Lin, Z., Han, J., et al.: Yolov10: Real-time end-to-end object detection. Advances in Neural Information Processing Systems 37, 107984–108011 (2024)
2024
-
[31]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Wang, C.Y., Bochkovskiy, A., Liao, H.Y.M.: Yolov7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 7464–7475 (2023)
2023
-
[32]
PP-YOLOE: An evolved version of YOLO,
Xu, S., Wang, X., Lv, W., Chang, Q., Cui, C., Deng, K., Wang, G., Dang, Q., Wei, S., Du, Y., et al.: Pp-yoloe: An evolved version of yolo. arXiv preprint arXiv:2203.16250 (2022)
-
[34]
Yang, F., Liang, B., Li, W., Zhang, J.: Multidimensional fusion network for mul- tispectral object detection. IEEE Transactions on Circuits and Systems for Video Technology35(1), 547–560 (Jan 2025).https://doi.org/10.1109/TCSVT.2024. 3454631
-
[35]
DINO: DETR with Improved DeNoising Anchor Boxes for End-to-End Object Detection
Zhang, H., Li, F., Liu, S., Zhang, L., Su, H., Zhu, J., Ni, L.M., Shum, H.Y.: Dino: Detr with improved denoising anchor boxes for end-to-end object detection. arXiv preprint arXiv:2203.03605 (2022)
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[36]
In: 2020 IEEE International conference on image processing (ICIP)
Zhang, H., Fromont, E., Lefevre, S., Avignon, B.: Multispectral fusion for object detection with cyclic fuse-and-refine blocks. In: 2020 IEEE International conference on image processing (ICIP). pp. 276–280. IEEE (2020)
2020
-
[37]
In: Proceedings of the IEEE/CVF winter conference on applications of computer vision
Zhang, H., Fromont, E., Lefèvre, S., Avignon, B.: Guided attentive feature fusion for multispectral pedestrian detection. In: Proceedings of the IEEE/CVF winter conference on applications of computer vision. pp. 72–80 (2021)
2021
-
[38]
In: Proceedings of the IEEE/CVF international conference on computer vision
Zhang, L., Zhu, X., Chen, X., Yang, X., Lei, Z., Liu, Z.: Weakly aligned cross-modal learning for multispectral pedestrian detection. In: Proceedings of the IEEE/CVF international conference on computer vision. pp. 5127–5137 (2019)
2019
-
[39]
In: Proceedings of the IEEE conference on computer vision and pattern recognition
Zhang, X., Zhou, X., Lin, M., Sun, J.: Shufflenet: An extremely efficient convolu- tional neural network for mobile devices. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 6848–6856 (2018)
2018
-
[40]
Zhang, X., Cao, S.Y., Wang, F., Zhang, R., Wu, Z., Zhang, X., Bai, X., Shen, H.L.: Rethinking early-fusion strategies for improved multispectral object detec- tion. IEEE Transactions on Intelligent Vehicles p. 1–15 (2024).https://doi.org/ 10.1109/TIV.2024.3462488
-
[41]
In: 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Zhao, Y., Lv, W., Xu, S., Wei, J., Wang, G., Dang, Q., Liu, Y., Chen, J.: Detrs beat yolos on real-time object detection. In: 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). p. 16965–16974. IEEE, Seattle, WA, USA (june 2024).https://doi.org/10.1109/CVPR52733.2024.01605,https: //ieeexplore.ieee.org/document/10657220/
-
[42]
In: European conference on computer vi- sion
Zhou, K., Chen, L., Cao, X.: Improving multispectral pedestrian detection by ad- dressing modality imbalance problems. In: European conference on computer vi- sion. pp. 787–803. Springer (2020)
2020
-
[43]
IEEE TransactionsonMultimediap.1–15(2025).https://doi.org/10.1109/TMM.2025
Zhou, M., Li, Y., Yang, G., Wei, X., Pu, H., Luo, J., Jia, W.: Cofnet: Contrastive object-aware fusion using box-level masks for multispectral object detection. IEEE TransactionsonMultimediap.1–15(2025).https://doi.org/10.1109/TMM.2025. 3599097
-
[44]
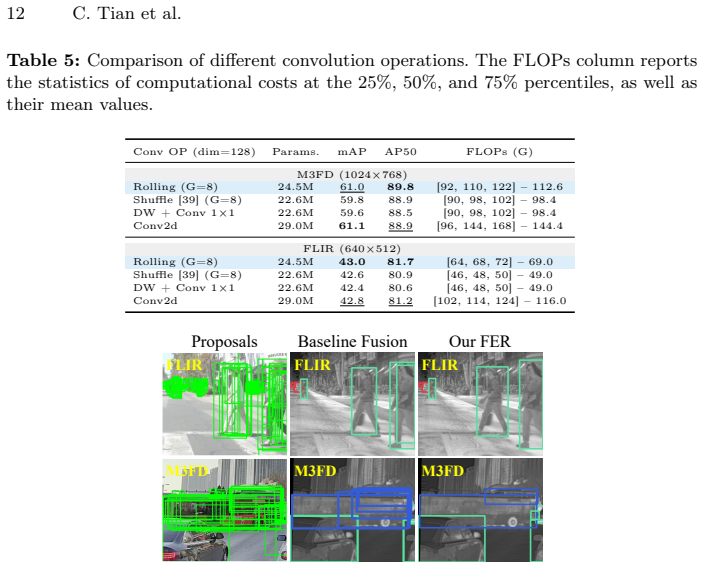
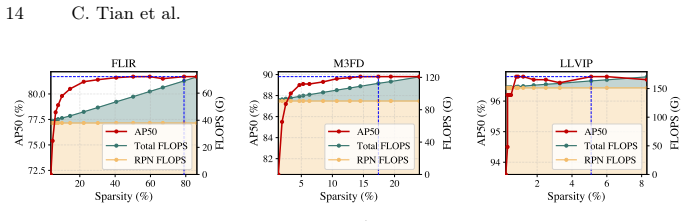
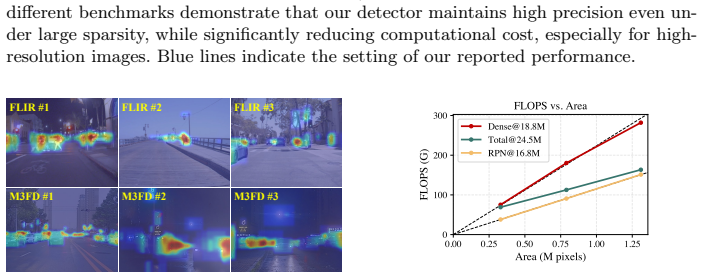
Zhu, X., Su, W., Lu, L., Li, B., Wang, X., Dai, J.: Deformable detr: Deformable transformers for end-to-end object detection. In: International Conference on Learning Representations (2021) Efficient RGB-T Object Detection via Sparse Cross-Modality Fusion 1 Appendix A Effect of the proposed FER We conduct a comparison to evaluate the effectiveness of the ...
2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.