EasyVFX: Frequency-Driven Decoupling for Resource-Efficient VFX Generation
Pith reviewed 2026-05-22 06:25 UTC · model grok-4.3
The pith
EasyVFX decouples high-frequency spatial textures from low-frequency motion dynamics to generate realistic VFX with far less data and compute.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
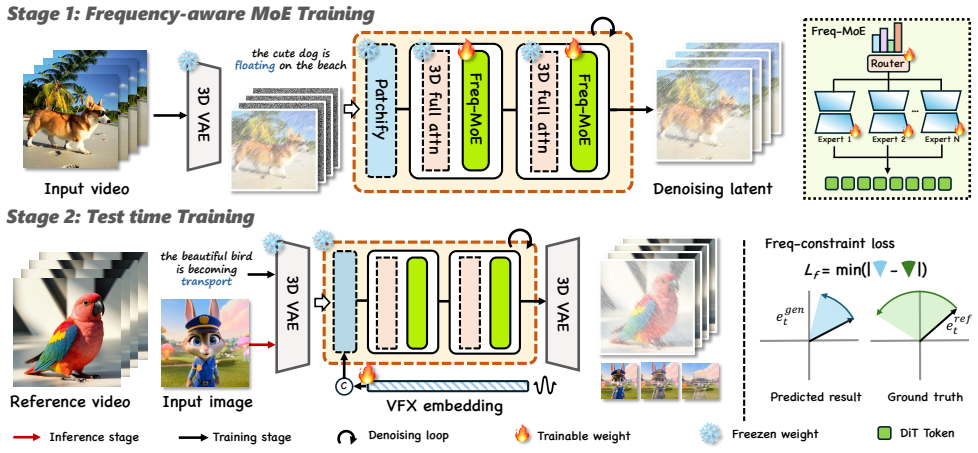
By decomposing VFX into high-frequency components that capture intricate spatial appearances and low-frequency components that capture global motion dynamics, the high-dimensional learning task reduces to manageable sub-problems. This spectral disentanglement is realized through a Frequency-aware Mixture-of-Experts architecture with soft routing across spectral bands, followed by test-time training that uses a Frequency-constraint Loss to adapt the pre-trained model to specific unseen effects with minimal steps and resources.
What carries the argument
Frequency-aware Mixture-of-Experts (Freq-MoE) that routes experts to distinct spectral bands via soft assignment, combined with a Frequency-constraint Loss for rapid test-time adaptation.
If this is right
- Specialized experts acquire foundational VFX knowledge using fewer GPU resources than standard end-to-end training.
- New effects can be synthesized after only about 100 adaptation steps on a single GPU.
- The resulting outputs maintain structural consistency while matching the visual fidelity of high-cost pipelines.
- Overall data requirements drop because each sub-task focuses on a narrower frequency range.
Where Pith is reading between the lines
- The same frequency split might simplify other generative video or animation tasks where fine detail and coarse motion already separate naturally.
- If adaptation stays this light, on-device or small-studio VFX editing tools become feasible without cloud-scale training.
- Extending the routing mechanism to additional frequency bands or modalities could further reduce compute for longer sequences.
Load-bearing premise
Separating high-frequency spatial appearances from low-frequency global motion dynamics substantially reduces VFX complexity and makes optimization easier.
What would settle it
A controlled experiment that trains identical models with and without the frequency decomposition on the same VFX dataset and shows whether the non-decomposed version requires significantly more data, more GPU hours, or more than roughly 100 adaptation steps to reach comparable structural consistency and visual quality.
Figures









read the original abstract
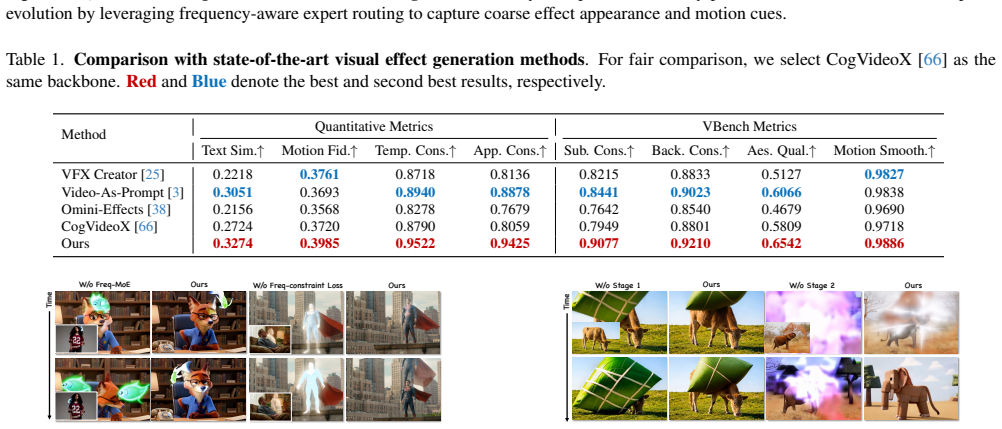
Generating high-fidelity visual effects (VFX) typically demands massive datasets and prohibitive computational power due to the intricate coupling of spatial textures and temporal dynamics. In this paper, we introduce EasyVFX, a resource-efficient framework that achieves realistic VFX synthesis under stringent constraints. Our core philosophy lies in frequency-domain decomposition: we observe that the complexity of VFX can be significantly mitigated by decoupling high-frequency components, which represent intricate spatial appearances, from low-frequency components that encapsulate global motion dynamics. This spectral disentanglement transforms a high-dimensional learning problem into manageable sub-tasks, thereby lowering the optimization barrier and reducing data dependency. Building upon this insight, we propose a two-stage training paradigm. First, we design a Frequency-aware Mixture-of-Experts (Freq-MoE) architecture. By utilizing a soft routing mechanism, our model assigns specialized experts to distinct spectral bands, enabling them to cultivate robust priors for appearance and motion dynamics. This specialization allows the model to acquire foundational VFX knowledge with fewer GPU resources. Second, we introduce a Test-Time Training strategy powered by a novel Frequency-constraint Loss. This allows the pre-trained model to swiftly adapt to specific, unseen effects through localized optimizations, requiring only about 100 steps on a single GPU. Experimental results demonstrate that EasyVFX produces structurally consistent and visually stunning effects, proving that frequency-aware learning is a key catalyst for democratizing professional-grade VFX.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces EasyVFX, a resource-efficient framework for high-fidelity VFX generation. It claims that frequency-domain decomposition decouples high-frequency components (intricate spatial appearances) from low-frequency components (global motion dynamics), transforming a coupled high-dimensional problem into independent sub-tasks. The approach uses a two-stage paradigm with a Frequency-aware Mixture-of-Experts (Freq-MoE) architecture employing soft routing for spectral-band specialization, followed by test-time training via a novel Frequency-constraint Loss that enables adaptation to unseen effects in roughly 100 steps on a single GPU. The abstract asserts that this yields structurally consistent and visually stunning results while lowering data dependency and computational barriers.
Significance. If the central claims are substantiated with rigorous evidence, the work could meaningfully advance resource-efficient generative modeling in computer vision by demonstrating that frequency-aware specialization reduces the optimization barrier for complex VFX synthesis. This would support broader accessibility to professional-grade effects without massive datasets or GPU clusters, with the Freq-MoE and frequency-constraint mechanisms offering a concrete architectural path toward that goal.
major comments (2)
- [Abstract] Abstract: the manuscript asserts that 'experimental results demonstrate that EasyVFX produces structurally consistent and visually stunning effects' yet supplies no quantitative metrics, baselines, datasets, ablation studies, or implementation details. This absence directly prevents evaluation of whether the reported resource savings and lowered optimization barrier are supported by the data.
- [Abstract] Abstract: the core philosophy states that high-frequency components represent 'intricate spatial appearances' while low-frequency components 'encapsulate global motion dynamics,' underpinning both Freq-MoE routing and the Frequency-constraint Loss. This clean spectral split is load-bearing for the claimed complexity reduction; however, many VFX phenomena (fast particle motion, fluid turbulence, flickering lights) contain high-frequency content in the temporal domain, which risks misrouting and undermines the decoupling premise.
minor comments (1)
- [Abstract] The phrase 'about 100 steps' is imprecise; reporting the exact step count, learning-rate schedule, or convergence criterion used in the test-time training would improve reproducibility.
Simulated Author's Rebuttal
We thank the referee for their careful reading of the manuscript and for highlighting these important points. We respond to each comment below, indicating where revisions will be made.
read point-by-point responses
-
Referee: [Abstract] Abstract: the manuscript asserts that 'experimental results demonstrate that EasyVFX produces structurally consistent and visually stunning effects' yet supplies no quantitative metrics, baselines, datasets, ablation studies, or implementation details. This absence directly prevents evaluation of whether the reported resource savings and lowered optimization barrier are supported by the data.
Authors: We acknowledge that the abstract does not contain specific quantitative metrics or other details. These are provided in the body of the manuscript, particularly in the Experiments and Implementation sections, where we present comparisons, ablations, and resource usage statistics. To improve clarity for readers, we will revise the abstract to include a short statement summarizing the key quantitative results and efficiency gains. revision: yes
-
Referee: [Abstract] Abstract: the core philosophy states that high-frequency components represent 'intricate spatial appearances' while low-frequency components 'encapsulate global motion dynamics,' underpinning both Freq-MoE routing and the Frequency-constraint Loss. This clean spectral split is load-bearing for the claimed complexity reduction; however, many VFX phenomena (fast particle motion, fluid turbulence, flickering lights) contain high-frequency content in the temporal domain, which risks misrouting and undermines the decoupling premise.
Authors: We appreciate the referee raising this potential issue with the frequency decoupling assumption. In our framework, the frequency decomposition is applied spatially to disentangle appearance details from motion structures, while temporal aspects are handled through the video sequence modeling and the specialized experts. The soft routing in Freq-MoE provides adaptability, and the Frequency-constraint Loss during test-time training helps in capturing complex dynamics. We will expand the manuscript with a discussion on handling temporal high-frequency VFX elements and include supporting examples. revision: yes
Circularity Check
No circularity: core claim rests on stated observation, not self-referential derivation
full rationale
The paper presents frequency-domain decomposition as an initial observation that high-frequency components capture spatial appearances while low-frequency ones capture motion dynamics. This observation is used to motivate the Freq-MoE architecture and Frequency-constraint Loss, but no equations, derivations, or fitted parameters are shown to reduce back to themselves by construction. No self-citations are invoked as load-bearing uniqueness theorems, and no predictions are claimed from subsets of data that would force the result. The framework is therefore self-contained against external benchmarks rather than internally forced.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Complexity of VFX can be significantly mitigated by decoupling high-frequency components (intricate spatial appearances) from low-frequency components (global motion dynamics)
invented entities (2)
-
Frequency-aware Mixture-of-Experts (Freq-MoE)
no independent evidence
-
Frequency-constraint Loss
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/Breath1024.lean, IndisputableMonolith/Foundation/AlexanderDuality.leanreality_from_one_distinction, alexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
decoupling high-frequency components, which represent intricate spatial appearances, from low-frequency components that encapsulate global motion dynamics... Frequency-aware Mixture-of-Experts (Freq-MoE) architecture... Frequency-constraint Loss
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Civitai: Ai model sharing platform.https://civitai. com/models, 2026. Accessed: 2026-04-28. 1, 3
work page 2026
-
[2]
Cosmos World Foundation Model Platform for Physical AI
Niket Agarwal, Arslan Ali, Maciej Bala, Yogesh Balaji, Erik Barker, Tiffany Cai, Prithvijit Chattopadhyay, Yongxin Chen, Yin Cui, Yifan Ding, et al. Cosmos world foun- dation model platform for physical ai.arXiv preprint arXiv:2501.03575, 2025. 2
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
Yuxuan Bian, Xin Chen, Zenan Li, Tiancheng Zhi, Shen Sang, Linjie Luo, and Qiang Xu. Video-as-prompt: Uni- fied semantic control for video generation.arXiv preprint arXiv:2510.20888, 2025. 2, 7, 8
-
[4]
Video generation models as world simulators.OpenAI Blog, 1(8):1, 2024
Tim Brooks, Bill Peebles, Connor Holmes, Will DePue, Yufei Guo, Li Jing, David Schnurr, Joe Taylor, Troy Luh- man, Eric Luhman, et al. Video generation models as world simulators.OpenAI Blog, 1(8):1, 2024. 3
work page 2024
-
[5]
Skyreels-a2: Compose anything in video diffusion transformers.arXiv preprint arXiv:2504.02436, 2025
Zhengcong Fei, Debang Li, Di Qiu, Jiahua Wang, Yikun Dou, Rui Wang, Jingtao Xu, Mingyuan Fan, Guibin Chen, Yang Li, et al. Skyreels-a2: Compose anything in video dif- fusion transformers.arXiv preprint arXiv:2504.02436, 2025. 3
-
[6]
Dit4edit: Dif- fusion transformer for image editing
Kunyu Feng, Yue Ma, Bingyuan Wang, Chenyang Qi, Haozhe Chen, Qifeng Chen, and Zeyu Wang. Dit4edit: Dif- fusion transformer for image editing. InProceedings of the AAAI Conference on Artificial Intelligence, pages 2969– 2977, 2025. 3
work page 2025
-
[7]
Motion prompting: Controlling video generation with motion trajec- tories
Daniel Geng, Charles Herrmann, Junhwa Hur, Forrester Cole, Serena Zhang, Tobias Pfaff, Tatiana Lopez-Guevara, Yusuf Aytar, Michael Rubinstein, Chen Sun, et al. Motion prompting: Controlling video generation with motion trajec- tories. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 1–12, 2025. 3
work page 2025
-
[8]
Magicvfx: Visual effects synthesis in just minutes
Jiaqi Guo, Lianli Gao, Junchen Zhu, Jiaxin Zhang, Siyang Li, and Jingkuan Song. Magicvfx: Visual effects synthesis in just minutes. InProceedings of the 32nd ACM International Conference on Multimedia, pages 8238–8246, 2024. 4
work page 2024
-
[9]
Jianzhu Guo, Dingyun Zhang, Xiaoqiang Liu, Zhizhou Zhong, Yuan Zhang, Pengfei Wan, and Di Zhang. Livepor- trait: Efficient portrait animation with stitching and retarget- ing control.arXiv preprint arXiv:2407.03168, 2024. 3
-
[10]
Sparsectrl: Adding sparse controls to text-to-video diffusion models
Yuwei Guo, Ceyuan Yang, Anyi Rao, Maneesh Agrawala, Dahua Lin, and Bo Dai. Sparsectrl: Adding sparse controls to text-to-video diffusion models. InEuropean Conference on Computer Vision, pages 330–348. Springer, 2024. 3
work page 2024
-
[11]
CameraCtrl: Enabling Camera Control for Text-to-Video Generation
Hao He, Yinghao Xu, Yuwei Guo, Gordon Wetzstein, Bo Dai, Hongsheng Li, and Ceyuan Yang. Cameractrl: Enabling camera control for text-to-video generation.arXiv preprint arXiv:2404.02101, 2024. 3
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[12]
Classifier-free diffusion guidance, 2022
Jonathan Ho and Tim Salimans. Classifier-free diffusion guidance, 2022. S1
work page 2022
-
[13]
Lora: Low-rank adaptation of large language models.ICLR, 1(2):3, 2022
Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen- Zhu, Yuanzhi Li, Shean Wang, Lu Wang, Weizhu Chen, et al. Lora: Low-rank adaptation of large language models.ICLR, 1(2):3, 2022. 2
work page 2022
-
[14]
Animate anyone: Consistent and controllable image- to-video synthesis for character animation
Li Hu. Animate anyone: Consistent and controllable image- to-video synthesis for character animation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 8153–8163, 2024. 3
work page 2024
-
[15]
Embedding-perturbed Exploration Preference Optimization for Flow Models
Sujie Hu, Chubin Chen, Jiashu Zhu, Jiahong Wu, Xiangx- iang Chu, and Xiu Li. Embedding-perturbed exploration preference optimization for flow models.arXiv preprint arXiv:2605.15803, 2026. 3
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[16]
Video- mage: Multi-subject and motion customization of text-to- video diffusion models
Chi-Pin Huang, Yen-Siang Wu, Hung-Kai Chung, Kai-Po Chang, Fu-En Yang, and Yu-Chiang Frank Wang. Video- mage: Multi-subject and motion customization of text-to- video diffusion models. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 17603– 17612, 2025. 3
work page 2025
-
[17]
Vbench: Comprehensive bench- mark suite for video generative models
Ziqi Huang, Yinan He, Jiashuo Yu, Fan Zhang, Chenyang Si, Yuming Jiang, Yuanhan Zhang, Tianxing Wu, Qingyang Jin, Nattapol Chanpaisit, et al. Vbench: Comprehensive bench- mark suite for video generative models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 21807–21818, 2024. 7
work page 2024
-
[18]
VACE: All-in-One Video Creation and Editing
Zeyinzi Jiang, Zhen Han, Chaojie Mao, Jingfeng Zhang, Yulin Pan, and Yu Liu. Vace: All-in-one video creation and editing.arXiv preprint arXiv:2503.07598, 2025. 3
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[19]
Auto-Encoding Variational Bayes
Diederik P Kingma and Max Welling. Auto-encoding varia- tional bayes.arXiv preprint arXiv:1312.6114, 2013. 5
work page internal anchor Pith review Pith/arXiv arXiv 2013
-
[20]
HunyuanVideo: A Systematic Framework For Large Video Generative Models
Weijie Kong, Qi Tian, Zijian Zhang, Rox Min, Zuozhuo Dai, Jin Zhou, Jiangfeng Xiong, Xin Li, Bo Wu, Jianwei Zhang, et al. Hunyuanvideo: A systematic framework for large video generative models.arXiv:2412.03603, 2024. 3, S2
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[21]
Cheng Lei, Jiayu Zhang, Yue Ma, Xinyu Wang, Long Chen, Liang Tang, Yiqiang Yan, Fei Su, and Zhicheng Zhao. Di- traj: training-free trajectory control for video diffusion trans- former.arXiv preprint arXiv:2509.21839, 2025. 3
-
[22]
Baolu Li, Yiming Zhang, Qinghe Wang, Liqian Ma, Xi- aoyu Shi, Xintao Wang, Pengfei Wan, Zhenfei Yin, Yun- zhi Zhuge, Huchuan Lu, et al. Vfxmaster: Unlocking dy- namic visual effect generation via in-context learning.arXiv preprint arXiv:2510.25772, 2025. 2, 4, 7
-
[23]
Pengyang Ling, Jiazi Bu, Pan Zhang, Xiaoyi Dong, Yuhang Zang, Tong Wu, Huaian Chen, Jiaqi Wang, and Yi Jin. Motionclone: Training-free motion cloning for controllable video generation.arXiv preprint arXiv:2406.05338, 2024. 3
-
[24]
Avatarartist: Open-domain 4d avatarization
Hongyu Liu, Xuan Wang, Ziyu Wan, Yue Ma, Jingye Chen, Yanbo Fan, Yujun Shen, Yibing Song, and Qifeng Chen. Avatarartist: Open-domain 4d avatarization. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 10758–10769, 2025. 3
work page 2025
-
[25]
Xinyu Liu, Ailing Zeng, Wei Xue, Harry Yang, Wenhan Luo, Qifeng Liu, and Yike Guo. Vfx creator: Animated visual ef- fect generation with controllable diffusion transformer.arXiv preprint arXiv:2502.05979, 2025. 2, 4, 7, 8, S3
-
[26]
Zeqian Long, Mingzhe Zheng, Kunyu Feng, Xinhua Zhang, Hongyu Liu, Harry Yang, Linfeng Zhang, Qifeng Chen, and Yue Ma. Follow-your-shape: Shape-aware image edit- ing via trajectory-guided region control.arXiv preprint arXiv:2508.08134, 2025. 3
-
[27]
Decoupled Weight Decay Regularization
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization.arXiv preprint arXiv:1711.05101, 2017. 7
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[28]
Visual knowledge graph for human action rea- soning in videos
Yue Ma, Yali Wang, Yue Wu, Ziyu Lyu, Siran Chen, Xiu Li, and Yu Qiao. Visual knowledge graph for human action rea- soning in videos. InProceedings of the 30th ACM Interna- tional Conference on Multimedia, pages 4132–4141, 2022. 3
work page 2022
-
[29]
Follow your pose: Pose- guided text-to-video generation using pose-free videos
Yue Ma, Yingqing He, Xiaodong Cun, Xintao Wang, Siran Chen, Xiu Li, and Qifeng Chen. Follow your pose: Pose- guided text-to-video generation using pose-free videos. In Proceedings of the AAAI Conference on Artificial Intelli- gence, pages 4117–4125, 2024. 3
work page 2024
-
[30]
Follow-your-emoji: Fine-controllable and expressive freestyle portrait animation
Yue Ma, Hongyu Liu, Hongfa Wang, Heng Pan, Yingqing He, Junkun Yuan, Ailing Zeng, Chengfei Cai, Heung-Yeung Shum, Wei Liu, et al. Follow-your-emoji: Fine-controllable and expressive freestyle portrait animation. InSIGGRAPH Asia 2024 Conference Papers, pages 1–12, 2024. 3
work page 2024
-
[31]
Controllable video generation: A survey.arXiv preprint arXiv:2507.16869,
Yue Ma, Kunyu Feng, Zhongyuan Hu, Xinyu Wang, Yucheng Wang, Mingzhe Zheng, Xuanhua He, Chenyang Zhu, Hongyu Liu, Yingqing He, et al. Controllable video generation: A survey.arXiv preprint arXiv:2507.16869,
-
[32]
Yue Ma, Kunyu Feng, Xinhua Zhang, Hongyu Liu, David Junhao Zhang, Jinbo Xing, Yinhan Zhang, Ayden Yang, Zeyu Wang, and Qifeng Chen. Follow-your-creation: Empowering 4d creation through video inpainting.arXiv preprint arXiv:2506.04590, 2025. 3
-
[33]
Follow-your-click: Open-domain regional image animation via motion prompts
Yue Ma, Yingqing He, Hongfa Wang, Andong Wang, Leqi Shen, Chenyang Qi, Jixuan Ying, Chengfei Cai, Zhifeng Li, Heung-Yeung Shum, et al. Follow-your-click: Open-domain regional image animation via motion prompts. InProceed- ings of the AAAI Conference on Artificial Intelligence, pages 6018–6026, 2025. 3
work page 2025
-
[34]
Yue Ma, Yulong Liu, Qiyuan Zhu, Ayden Yang, Kunyu Feng, Xinhua Zhang, Zhifeng Li, Sirui Han, Chenyang Qi, and Qifeng Chen. Follow-your-motion: Video motion transfer via efficient spatial-temporal decoupled finetuning.arXiv preprint arXiv:2506.05207, 2025. 3
-
[35]
Yue Ma, Zexuan Yan, Hongyu Liu, Hongfa Wang, Heng Pan, Yingqing He, Junkun Yuan, Ailing Zeng, Chengfei Cai, Heung-Yeung Shum, et al. Follow-your-emoji-faster: To- wards efficient, fine-controllable, and expressive freestyle portrait animation.arXiv preprint arXiv:2509.16630, 2025
-
[36]
Group editing: Edit multiple im- ages in one go.arXiv preprint arXiv:2603.22883, 2026
Yue Ma, Xinyu Wang, Qianli Ma, Qinghe Wang, Mingzhe Zheng, Xiangpeng Yang, Hao Li, Chongbo Zhao, Jixuan Ying, Harry Yang, et al. Group editing: Edit multiple im- ages in one go.arXiv preprint arXiv:2603.22883, 2026
-
[37]
Fastvmt: Eliminat- ing redundancy in video motion transfer.arXiv preprint arXiv:2602.05551, 2026
Yue Ma, Zhikai Wang, Tianhao Ren, Mingzhe Zheng, Hongyu Liu, Jiayi Guo, Mark Fong, Yuxuan Xue, Zixi- ang Zhao, Konrad Schindler, et al. Fastvmt: Eliminat- ing redundancy in video motion transfer.arXiv preprint arXiv:2602.05551, 2026. 3
-
[38]
Fangyuan Mao, Aiming Hao, Jintao Chen, Dongxia Liu, Xiaokun Feng, Jiashu Zhu, Meiqi Wu, Chubin Chen, Ji- ahong Wu, and Xiangxiang Chu. Omni-effects: Unified and spatially-controllable visual effects generation.arXiv preprint arXiv:2508.07981, 2025. 4, 7, 8, S3
-
[39]
Bohao Peng, Jian Wang, Yuechen Zhang, Wenbo Li, Ming- Chang Yang, and Jiaya Jia. Controlnext: Powerful and effi- cient control for image and video generation.arXiv preprint arXiv:2408.06070, 2024. 3
-
[40]
Jensen, Zhenli Sheng, and Bin Yang
Xiangfei Qiu, Jilin Hu, Lekui Zhou, Xingjian Wu, Junyang Du, Buang Zhang, Chenjuan Guo, Aoying Zhou, Christian S. Jensen, Zhenli Sheng, and Bin Yang. TFB: Towards com- prehensive and fair benchmarking of time series forecasting methods. InProc. VLDB Endow., pages 2363–2377, 2024. 3
work page 2024
-
[41]
Dbloss: Decomposition-based loss function for time series forecast- ing
Xiangfei Qiu, Xingjian Wu, Hanyin Cheng, Xvyuan Liu, Chenjuan Guo, Jilin Hu, and Bin Yang. Dbloss: Decomposition-based loss function for time series forecast- ing. InNeurIPS, 2025
work page 2025
-
[42]
DUET: Dual clustering enhanced mul- tivariate time series forecasting
Xiangfei Qiu, Xingjian Wu, Yan Lin, Chenjuan Guo, Jilin Hu, and Bin Yang. DUET: Dual clustering enhanced mul- tivariate time series forecasting. InSIGKDD, pages 1185– 1196, 2025
work page 2025
-
[43]
Dag: A dual correlation network for time series forecasting with exogenous variables
Xiangfei Qiu, Yuhan Zhu, Zhengyu Li, Xingjian Wu, Bin Yang, and Jilin Hu. Dag: A dual correlation network for time series forecasting with exogenous variables. InICML,
-
[44]
Learning transferable visual models from natural language supervi- sion
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervi- sion. InInternational conference on machine learning, pages 8748–8763. PmLR, 2021. 7
work page 2021
-
[45]
Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer
Noam Shazeer, Azalia Mirhoseini, Krzysztof Maziarz, Andy Davis, Quoc Le, Geoffrey Hinton, and Jeff Dean. Outra- geously large neural networks: The sparsely-gated mixture- of-experts layer.arXiv preprint arXiv:1701.06538, 2017. 5
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[46]
Yutao Shen, Junkun Yuan, Toru Aonishi, Hideki Nakayama, and Yue Ma. Follow-your-preference: Towards preference- aligned image inpainting.arXiv preprint arXiv:2509.23082,
-
[47]
Yiren Song, Danze Chen, and Mike Zheng Shou. Layer- tracer: Cognitive-aligned layered svg synthesis via diffusion transformer.arXiv preprint arXiv:2502.01105, 2025. 3
-
[48]
Yiren Song, Cheng Liu, and Mike Zheng Shou. Makeany- thing: Harnessing diffusion transformers for multi- domain procedural sequence generation.arXiv preprint arXiv:2502.01572, 2025. 3
-
[49]
Kling Team, Jialu Chen, Yuanzheng Ci, Xiangyu Du, Zipeng Feng, Kun Gai, Sainan Guo, Feng Han, Jingbin He, Kang He, et al. Kling-omni technical report.arXiv preprint arXiv:2512.16776, 2025. 2
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[50]
Boyang Wang, Xuweiyi Chen, Matheus Gadelha, and Zezhou Cheng. Frame in-n-out: Unbounded con- trollable image-to-video generation.arXiv preprint arXiv:2505.21491, 2025. 3
-
[51]
Tam- ing rectified flow for inversion and editing.arXiv preprint arXiv:2411.04746, 2024
Jiangshan Wang, Junfu Pu, Zhongang Qi, Jiayi Guo, Yue Ma, Nisha Huang, Yuxin Chen, Xiu Li, and Ying Shan. Tam- ing rectified flow for inversion and editing.arXiv preprint arXiv:2411.04746, 2024. 3
-
[52]
Point-to-point video gen- eration
Tsun-Hsuan Wang, Yen-Chi Cheng, Chieh Hubert Lin, Hwann-Tzong Chen, and Min Sun. Point-to-point video gen- eration. InProceedings of the IEEE/CVF international con- ference on computer vision, pages 10491–10500, 2019. 3
work page 2019
-
[53]
Xiang Wang, Shiwei Zhang, Changxin Gao, Jiayu Wang, Xi- aoqiang Zhou, Yingya Zhang, Luxin Yan, and Nong Sang. Unianimate: Taming unified video diffusion models for con- sistent human image animation.Science China Information Sciences, 68(10):1–14, 2025. 3
work page 2025
-
[54]
Customvideo: Customizing text-to-video generation with multiple subjects.arXiv:2401.09962, 2024
Zhao Wang et al. Customvideo: Customizing text-to-video generation with multiple subjects.arXiv:2401.09962, 2024. 3
-
[55]
Dreamvideo: Composing your dream videos with customized subject and motion
Yujie Wei et al. Dreamvideo: Composing your dream videos with customized subject and motion. InCVPR, 2024. 3
work page 2024
-
[56]
Draganything: Motion control for any- thing using entity representation
Weijia Wu, Zhuang Li, Yuchao Gu, Rui Zhao, Yefei He, David Junhao Zhang, Mike Zheng Shou, Yan Li, Tingting Gao, and Di Zhang. Draganything: Motion control for any- thing using entity representation. InEuropean Conference on Computer Vision, pages 331–348. Springer, 2024. 3
work page 2024
-
[57]
Jinbo Xing, Menghan Xia, Yuxin Liu, Yuechen Zhang, Yong Zhang, Yingqing He, Hanyuan Liu, Haoxin Chen, Xiaodong Cun, Xintao Wang, et al. Make-your-video: Customized video generation using textual and structural guidance.IEEE Transactions on Visualization and Computer Graphics, 31 (2):1526–1541, 2024. 3
work page 2024
-
[58]
Xuancheng Xu, Yaning Li, Sisi You, and Bing-Kun Bao. Smrabooth: Subject and motion representation align- ment for customized video generation.arXiv preprint arXiv:2512.12193, 2025. 3
-
[59]
Clgc: Con- tinuous layout guidance for consistent text-to-video editing
Xuancheng Xu, Ming Tao, and Bing-Kun Bao. Clgc: Con- tinuous layout guidance for consistent text-to-video editing. In2025 IEEE International Conference on Multimedia and Expo (ICME), pages 1–6. IEEE, 2025. 3
work page 2025
-
[60]
Magicanimate: Temporally consistent human im- age animation using diffusion model
Zhongcong Xu, Jianfeng Zhang, Jun Hao Liew, Hanshu Yan, Jia-Wei Liu, Chenxu Zhang, Jiashi Feng, and Mike Zheng Shou. Magicanimate: Temporally consistent human im- age animation using diffusion model. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 1481–1490, 2024. 3
work page 2024
-
[61]
Yuxuan Xue, Xianghui Xie, Riccardo Marin, and Gerard Pons-Moll. Human-3diffusion: realistic avatar creation via explicit 3d consistent diffusion models.Advances in Neural Information Processing Systems, 37:99601–99645, 2024. 3
work page 2024
-
[62]
Infinihuman: Realistic 3d human creation with precise control
Yuxuan Xue, Xianghui Xie, Margaret Kostyrko, and Gerard Pons-Moll. Infinihuman: Realistic 3d human creation with precise control. InProceedings of the SIGGRAPH Asia 2025 Conference Papers, pages 1–12, 2025. 3
work page 2025
-
[63]
Yuxuan Xue, Ruofan Liang, Egor Zakharov, Timur Bagaut- dinov, Chen Cao, Giljoo Nam, Shunsuke Saito, Gerard Pons-Moll, and Javier Romero. Georelight: Learning joint geometrical relighting and reconstruction with flex- ible multi-modal diffusion transformers.arXiv preprint arXiv:2604.20715, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[64]
Eedit: Rethinking the spatial and temporal redundancy for efficient image editing
Zexuan Yan, Yue Ma, Chang Zou, Wenteng Chen, Qifeng Chen, and Linfeng Zhang. Eedit: Rethinking the spatial and temporal redundancy for efficient image editing. InProceed- ings of the IEEE/CVF International Conference on Com- puter Vision, pages 17474–17484, 2025. 3
work page 2025
-
[65]
VideoCoF: Unified Video Editing with Temporal Reasoner
Xiangpeng Yang, Ji Xie, Yiyuan Yang, Yan Huang, Min Xu, and Qiang Wu. Unified video editing with temporal reasoner. arXiv preprint arXiv:2512.07469, 2025. 2
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[66]
CogVideoX: Text-to-Video Diffusion Models with An Expert Transformer
Zhuoyi Yang, Jiayan Teng, et al. Cogvideox: Text-to-video diffusion models with an expert transformer.arXiv preprint arXiv:2408.06072, 2024. 2, 7, 8, S1, S3
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[67]
Through-the-mask: Mask-based motion trajecto- ries for image-to-video generation
Guy Yariv, Yuval Kirstain, Amit Zohar, Shelly Sheynin, Yaniv Taigman, Yossi Adi, Sagie Benaim, and Adam Polyak. Through-the-mask: Mask-based motion trajecto- ries for image-to-video generation. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 18198–18208, 2025. 3
work page 2025
-
[68]
Fera: Frequency-energy con- strained routing for effective diffusion adaptation fine- tuning, 2025
Bo Yin, Xiaobin Hu, Xingyu Zhou, Peng-Tao Jiang, Yue Liao, Junwei Zhu, Jiangning Zhang, Ying Tai, Chengjie Wang, and Shuicheng Yan. Fera: Frequency-energy con- strained routing for effective diffusion adaptation fine- tuning, 2025. 5
work page 2025
-
[69]
Xinlei Yu, Zhangquan Chen, Yongbo He, Tianyu Fu, Cheng Yang, Chengming Xu, Yue Ma, Xiaobin Hu, Zhe Cao, Jie Xu, et al. The latent space: Foundation, evolution, mecha- nism, ability, and outlook.arXiv preprint arXiv:2604.02029,
-
[70]
Flexiact: Towards flexible action control in heterogeneous scenarios
Shiyi Zhang, Junhao Zhuang, Zhaoyang Zhang, Ying Shan, and Yansong Tang. Flexiact: Towards flexible action control in heterogeneous scenarios. InProceedings of the Special Interest Group on Computer Graphics and Interactive Tech- niques Conference Conference Papers, pages 1–11, 2025. 3
work page 2025
-
[71]
Flexiact: Towards flexible action control in heterogeneous scenarios, 2025
Shiyi Zhang, Junhao Zhuang, Zhaoyang Zhang, Ying Shan, and Yansong Tang. Flexiact: Towards flexible action control in heterogeneous scenarios, 2025. 5
work page 2025
-
[72]
Ssr-encoder: Encoding selective subject representation for subject-driven generation
Yuxuan Zhang, Yiren Song, Jiaming Liu, Rui Wang, Jinpeng Yu, Hao Tang, Huaxia Li, Xu Tang, Yao Hu, Han Pan, et al. Ssr-encoder: Encoding selective subject representation for subject-driven generation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 8069–8078, 2024. 3
work page 2024
-
[73]
Yuxuan Zhang, Yirui Yuan, Yiren Song, Haofan Wang, and Jiaming Liu. Easycontrol: Adding efficient and flexible control for diffusion transformer.arXiv preprint arXiv:2503.07027, 2025. 3
-
[74]
Motionpro: A precise mo- tion controller for image-to-video generation
Zhongwei Zhang, Fuchen Long, Zhaofan Qiu, Yingwei Pan, Wu Liu, Ting Yao, and Tao Mei. Motionpro: A precise mo- tion controller for image-to-video generation. InProceed- ings of the Computer Vision and Pattern Recognition Con- ference, pages 27957–27967, 2025. 3
work page 2025
-
[75]
Holotime: Taming video dif- fusion models for panoramic 4d scene generation
Haiyang Zhou, Wangbo Yu, Jiawen Guan, Xinhua Cheng, Yonghong Tian, and Li Yuan. Holotime: Taming video dif- fusion models for panoramic 4d scene generation. InPro- ceedings of the 33rd ACM International Conference on Mul- timedia, pages 9763–9772, 2025. 3
work page 2025
-
[76]
Champ: Controllable and consistent human image an- imation with 3d parametric guidance
Shenhao Zhu, Junming Leo Chen, Zuozhuo Dai, Zilong Dong, Yinghui Xu, Xun Cao, Yao Yao, Hao Zhu, and Siyu Zhu. Champ: Controllable and consistent human image an- imation with 3d parametric guidance. InEuropean Confer- ence on Computer Vision, pages 145–162. Springer, 2024. 3
work page 2024
-
[77]
Synthesizing videos from images for image-to-video adaptation
Junbao Zhuo, Xingyu Zhao, Shuhui Wang, Huimin Ma, and Qingming Huang. Synthesizing videos from images for image-to-video adaptation. InProceedings of the 31st ACM International Conference on Multimedia, pages 8294–8303,
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.