Accelerating Experimental Design by Incorporating Experimenter Hunches
Pith reviewed 2026-05-24 18:28 UTC · model grok-4.3
The pith
A two-stage Gaussian process folds experimenter monotonic hunches into Bayesian optimization while preserving convergence guarantees.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
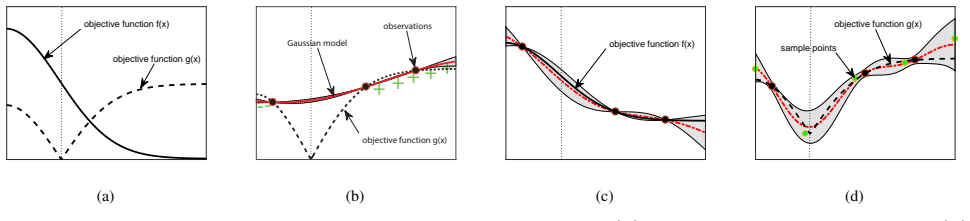
The central claim is that a two-stage Gaussian process, where the first stage models the underlying property using the supplied monotonicity information and the second stage models the target optimization function from virtual samples drawn from the first stage, together with an adjustment factor in the posterior, lets the monotonicity information be used to its fullest extent while the convergence guarantee of the overall procedure remains intact.
What carries the argument
Two-stage Gaussian process with virtual samples drawn from the monotonic first-stage model and an explicit adjustment factor added to the second-stage posterior.
If this is right
- Faster convergence than standard Bayesian optimization is observed in simulation benchmarks.
- Fewer physical experiments suffice to reach target length in the short polymer fiber design task.
- Fewer physical experiments suffice to reach target porosity in the three-dimensional scaffold design task.
- The theoretical convergence guarantee of the acquisition strategy is preserved despite the use of virtual samples.
Where Pith is reading between the lines
- The same two-stage construction could be applied to any optimization problem in which experts can reliably state directional effects of individual variables.
- If the method is deployed in a materials lab, the reduction in trials would translate directly into lower material and instrument time costs.
- A natural next test is to measure performance when the supplied monotonic trends are only partially correct rather than perfectly accurate.
- The adjustment-factor device might be reusable in other settings where one model is used to generate synthetic data for a second model.
Load-bearing premise
The monotonic trends supplied by the experimenter are accurate enough that feeding them directly into the first-stage model does not introduce bias that would invalidate the second-stage optimization or the adjustment factor's consistency guarantee.
What would settle it
A controlled simulation in which the true response surface deliberately violates the assumed per-variable monotonic trends; if the two-stage method then requires more evaluations than standard Bayesian optimization or loses its regret bound, the claim fails.
Figures






read the original abstract
Experimental design is a process of obtaining a product with target property via experimentation. Bayesian optimization offers a sample-efficient tool for experimental design when experiments are expensive. Often, expert experimenters have 'hunches' about the behavior of the experimental system, offering potentials to further improve the efficiency. In this paper, we consider per-variable monotonic trend in the underlying property that results in a unimodal trend in those variables for a target value optimization. For example, sweetness of a candy is monotonic to the sugar content. However, to obtain a target sweetness, the utility of the sugar content becomes a unimodal function, which peaks at the value giving the target sweetness and falls off both ways. In this paper, we propose a novel method to solve such problems that achieves two main objectives: a) the monotonicity information is used to the fullest extent possible, whilst ensuring that b) the convergence guarantee remains intact. This is achieved by a two-stage Gaussian process modeling, where the first stage uses the monotonicity trend to model the underlying property, and the second stage uses `virtual' samples, sampled from the first, to model the target value optimization function. The process is made theoretically consistent by adding appropriate adjustment factor in the posterior computation, necessitated because of using the `virtual' samples. The proposed method is evaluated through both simulations and real world experimental design problems of a) new short polymer fiber with the target length, and b) designing of a new three dimensional porous scaffolding with a target porosity. In all scenarios our method demonstrates faster convergence than the basic Bayesian optimization approach not using such `hunches'.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that a two-stage Gaussian process model can accelerate Bayesian optimization for experimental design by incorporating experimenter-provided per-variable monotonic trends. The first stage models the underlying property using these trends to generate virtual samples; the second stage optimizes the resulting unimodal target-value function, with an adjustment factor added to the posterior to restore theoretical consistency. Faster convergence than standard BO is reported in simulations and two real tasks (short polymer fiber length targeting and 3D porous scaffold porosity targeting).
Significance. If the consistency guarantee and empirical gains hold under realistic conditions, the approach would offer a practical way to inject domain knowledge into BO without sacrificing sample efficiency, which is valuable for expensive physical experiments. The virtual-sample construction with an explicit adjustment is a technically interesting idea that could generalize beyond the monotonic case.
major comments (3)
- [Abstract] Abstract and method description: the claim that the adjustment factor restores posterior consistency (and thereby preserves convergence guarantees) is stated without a derivation, explicit formula for the factor, or proof sketch showing how it corrects the bias introduced by virtual samples drawn from the stage-1 posterior.
- [Method] Method (two-stage construction): the procedure feeds the experimenter-supplied monotonic trends directly into the first-stage GP and draws virtual samples from it; no robustness analysis, misspecification bound, or sensitivity experiment is supplied to show what happens when the monotonicity is only approximately correct. Because any bias in the stage-1 mean/variance is inherited by the virtual samples, the second-stage optimization and the claimed consistency become conditional on perfect hunches.
- [Experiments] Empirical evaluation: the abstract asserts faster convergence on the polymer-fiber and scaffold tasks, yet supplies neither the number of independent runs, error bars, nor a statistical test; without these, it is impossible to judge whether the reported improvement is reliable or merely an artifact of a single favorable seed.
minor comments (2)
- [Method] Notation for the adjustment factor and the virtual-sample sampling distribution should be introduced with explicit equations rather than descriptive prose.
- [Experiments] The real-world experiment descriptions omit key protocol details (measurement noise model, exact target values, how the monotonic trends were elicited from the experimenters).
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment below, indicating the revisions we will incorporate to strengthen the paper while preserving its core contributions.
read point-by-point responses
-
Referee: [Abstract] Abstract and method description: the claim that the adjustment factor restores posterior consistency (and thereby preserves convergence guarantees) is stated without a derivation, explicit formula for the factor, or proof sketch showing how it corrects the bias introduced by virtual samples drawn from the stage-1 posterior.
Authors: We agree that the manuscript would be improved by including supporting details for the consistency claim. In the revised version, we will add an appendix containing the explicit formula for the adjustment factor along with a proof sketch that demonstrates how the factor corrects the bias induced by the virtual samples, thereby restoring posterior consistency and the associated convergence guarantees. revision: yes
-
Referee: [Method] Method (two-stage construction): the procedure feeds the experimenter-supplied monotonic trends directly into the first-stage GP and draws virtual samples from it; no robustness analysis, misspecification bound, or sensitivity experiment is supplied to show what happens when the monotonicity is only approximately correct. Because any bias in the stage-1 mean/variance is inherited by the virtual samples, the second-stage optimization and the claimed consistency become conditional on perfect hunches.
Authors: The method is formulated under the assumption of accurate hunches, consistent with the problem statement of incorporating reliable domain knowledge. To address concerns about approximate correctness, we will include a new sensitivity analysis subsection in the experiments, evaluating performance degradation under controlled levels of monotonicity misspecification. revision: yes
-
Referee: [Experiments] Empirical evaluation: the abstract asserts faster convergence on the polymer-fiber and scaffold tasks, yet supplies neither the number of independent runs, error bars, nor a statistical test; without these, it is impossible to judge whether the reported improvement is reliable or merely an artifact of a single favorable seed.
Authors: The reported results were obtained from multiple independent runs using different random seeds. We will revise the experimental section and figures to report the exact number of runs, display error bars, and include appropriate statistical tests (such as Wilcoxon signed-rank tests) to confirm the significance of the observed improvements. revision: yes
Circularity Check
No circularity; two-stage GP with adjustment factor is independent construction
full rationale
The derivation introduces a first-stage GP that directly encodes supplied monotonic trends, draws virtual samples, and applies an explicit adjustment factor to the second-stage posterior to restore consistency. This adjustment is defined from the virtual-sample approximation rather than from the target optimization objective itself. No equation reduces the claimed faster convergence to a fitted parameter or to the hunches by construction. No load-bearing self-citation or uniqueness theorem is invoked. The method remains self-contained against external benchmarks once the monotonic trends are treated as external inputs.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Gaussian processes provide valid posterior distributions for both the underlying monotonic property and the derived target-optimization function
- domain assumption Experimenter hunches supply correct per-variable monotonic trends that can be used without introducing model misspecification
invented entities (1)
-
virtual samples
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
two-stage Gaussian process modeling, where the first stage uses the monotonicity trend to model the underlying property, and the second stage uses `virtual' samples... adjustment factor in the posterior computation
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
regret bound RT ... with βt = exp(2C)αt
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
E. Brochu, V . M. Cora, and N. De Freitas, “A tutorial on Bayesian optimization of expensive cost functions, with application to active user modeling and hierarchical reinforcement learning,” arXiv preprint arXiv:1012.2599, 2010
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[2]
Gaussian process optimization in the bandit setting: No regret and experimental design,
N. Srinivas, A. Krause, S. Kakade, and M. Seeger, “Gaussian process optimization in the bandit setting: No regret and experimental design,” in ICML, 2010
work page 2010
-
[3]
Adaptive strategies for materials design using uncertainties,
P. V . Balachandran, D. Xue, J. Theiler, J. Hogden, and T. Lookman, “Adaptive strategies for materials design using uncertainties,” in Scien- tific reports, 2016
work page 2016
-
[4]
Budgeted batch bayesian optimization,
V . Nguyen, S. Rana, S. K. Gupta, C. Li, and S. Venkatesh, “Budgeted batch bayesian optimization,” in ICDM, Spain, 2016
work page 2016
-
[5]
Rapid bayesian optimisation for synthesis of short polymer fiber materials,
C. Li, D. Rubin de Celis Leal, S. Rana, S. Gupta, A. Sutti, S. Greenhill, T. Slezak, M. Height, and S. Venkatesh, “Rapid bayesian optimisation for synthesis of short polymer fiber materials,” Scientific Reports, vol. 7, 2017
work page 2017
-
[6]
Initializing bayesian hyper- parameter optimization via meta-learning,
M. Feurer, T. Springenberg, and F. Hutter, “Initializing bayesian hyper- parameter optimization via meta-learning,” inProceedings of the Twenty- Ninth AAAI Conference on Artificial Intelligence , 2015
work page 2015
-
[7]
High dimensional bayesian optimization using dropout,
C. Li, S. Gupta, S. Rana, V . Nguyen, S. Venkatesh, and A. Shilton, “High dimensional bayesian optimization using dropout,” in International Joint Conference on Artificial Intelligence , 2017
work page 2017
-
[8]
High dimensional Bayesian optimization with elastic Gaussian process,
S. Rana, C. Li, S. Gupta, V . Nguyen, and S. Venkatesh, “High dimensional Bayesian optimization with elastic Gaussian process,” in Proceedings of the 34th International Conference on Machine Learning, ser. Proceedings of Machine Learning Research, D. Precup and Y . W. Teh, Eds., vol. 70. International Convention Centre, Sydney, Australia: PMLR, 06–11 Aug ...
work page 2017
-
[9]
Gaussian processes with monotonicity information,
J. Riihimaki and A. Vehtari, “Gaussian processes with monotonicity information,” in Proceedings of the Thirteenth International Conference on Artificial Intelligence and Statistics , vol. 9, 2010, pp. 645–652
work page 2010
-
[10]
Estimating shape constrained functions using gaussian processes,
X. Wang and J. O. Berger, “Estimating shape constrained functions using gaussian processes,” SIAM/ASA Journal on Uncertainty Quantification , vol. 4, no. 1, pp. 1–25, 2016
work page 2016
-
[11]
Bayesian analysis of shape-restricted functions using gaussian process priors,
T. Choi and P. J. Lenk, “Bayesian analysis of shape-restricted functions using gaussian process priors,” Statistica Sinica, vol. 27, no. 1, pp. 43– 69, 2017
work page 2017
-
[12]
Bayesian opti- mization with gradients,
J. Wu, M. Poloczek, A. G. Wilson, and P. Frazier, “Bayesian opti- mization with gradients,” in Advances in Neural Information Processing Systems 30, I. Guyon, U. V . Luxburg, S. Bengio, H. Wallach, R. Fergus, S. Vishwanathan, and R. Garnett, Eds., 2017, pp. 5273–5284
work page 2017
-
[13]
Bayesian optimization with shape con- straints,
M. Jauch and victor pena, “Bayesian optimization with shape con- straints,” in Advances in Neural Information Processing Systems 2017 Workshop, 2016
work page 2017
-
[14]
Bayesian optimization of unimodal functions,
M. R. Andersen, E. Siivola, and A. Vehtari, “Bayesian optimization of unimodal functions,” in NIPS workshop on Bayesian optimization, 2017
work page 2017
-
[15]
Parallelizing exploration ex- ploitation tradeoffs in gaussian process bandit optimization,
T. Desautels, A. Krause, and J. Burdick, “Parallelizing exploration ex- ploitation tradeoffs in gaussian process bandit optimization,” Journal of Machine Learning Research (JMLR) , vol. 15, p. 4053?4103, December 2014
work page 2014
-
[16]
C. E. Rasmussen and C. K. I. Williams, Gaussian Processes for Machine Learning. The MIT Press, 2005
work page 2005
-
[17]
Expectation propagation for approximate bayesian inference,
T. P. Minka, “Expectation propagation for approximate bayesian inference,” in Proceedings of the Seventeenth Conference on Uncertainty in Artificial Intelligence , ser. UAI’01. San Francisco, CA, USA: Morgan Kaufmann Publishers Inc., 2001, pp. 362–369. [Online]. Available: http://dl.acm.org/citation.cfm?id=2074022.2074067
-
[18]
Entropy search for information-efficient global optimization,
P. Hennig and C. J. Schuler, “Entropy search for information-efficient global optimization,” J. Mach. Learn. Res., vol. 13, pp. 1809–1837, Jun. 2012
work page 2012
-
[19]
Near-optimal nonmyopic value of informa- tion in graphical models,
A. Krause and C. Guestrin, “Near-optimal nonmyopic value of informa- tion in graphical models,” in Proceedings of the Twenty-First Conference on Uncertainty in Artificial Intelligence, ser. UAI’05, 2005, pp. 324–331
work page 2005
-
[20]
Gpstuff: Bayesian modeling with gaussian processes,
J. Vanhatalo, J. Riihim ¨aki, J. Hartikainen, P. Jyl ¨anki, V . Tolvanen, and A. Vehtari, “Gpstuff: Bayesian modeling with gaussian processes,” J. Mach. Learn. Res. , vol. 14, no. 1, pp. 1175–1179, Apr. 2013
work page 2013
-
[21]
An apparatus for producing nano-bodies,
A. SUTTI, M. Kirkland, P. Collins, and R. GEORGE, “An apparatus for producing nano-bodies,” Sep. 12 2014, wO Patent App. PCT/AU2014/000,204. [Online]. Available: https://www.google. ch/patents/WO2014134668A1?cl=en
work page 2014
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.