TriPAH: Imbalance-Aware Tri-Prompt Affinity Hashing for Cross-Modal Medical Retrieval
Pith reviewed 2026-06-26 02:14 UTC · model grok-4.3
The pith
TriPAH uses ontology-grounded patient-level prompts and an asymmetric multi-task objective to achieve better semantic alignment in cross-modal medical hashing retrieval.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
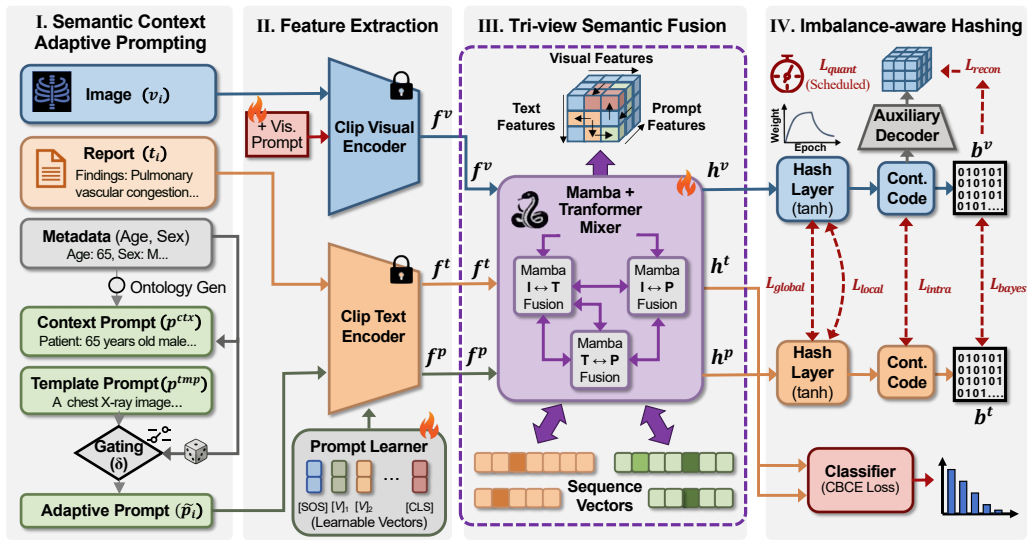
TriPAH synthesizes ontology-grounded, patient-level prompts conditioned on normalized clinical cues for low-noise text representations, uses a lightweight prompt-token mixer for hierarchical multi-granularity alignment under an asymmetric multi-task objective of multi-positive contrastive alignment, imbalance-aware classification, and progressive quantization regularization, and adds a patient-level consistency module to stabilize codes across views.
What carries the argument
Tri-Prompt Affinity Hashing framework that produces quantization-ready features via ontology-grounded prompts and an asymmetric multi-task objective coupling contrastive, classification, and quantization terms.
If this is right
- More reliable binary codes for image-text search despite clinical language noise.
- Better handling of long-tailed labels through the imbalance-aware term.
- Stabilized codes across complementary patient views via the consistency module.
- Support for downstream medical tasks such as case-based reasoning.
Where Pith is reading between the lines
- Prompt synthesis conditioned on clinical cues could transfer to other noisy-text retrieval domains like legal documents.
- Progressive quantization regularization might reduce code degradation in other hashing applications with limited data.
- The full framework could be tested for robustness on non-public hospital data with real-world label imbalances.
Load-bearing premise
That the ontology-grounded prompts and asymmetric multi-task objective produce genuinely better semantic alignment rather than dataset-specific fitting.
What would settle it
Evaluating TriPAH on a new medical dataset with different noise patterns and long-tailed distributions and finding no outperformance over existing methods would falsify the claim of improved alignment.
Figures

read the original abstract
In the era of big medical data, efficient cross-modal retrieval is pivotal for evidence-based diagnosis and large-scale case management. Cross-modal medical hashing retrieval aims to enable efficient image-text search and support downstream tasks such as case-based reasoning and decision support by learning compact, semantically aligned binary codes. However, current methods suffer from semantic fragmentation due to noisy clinical language, long-tailed labels, and brittle quantization that weakens alignment. We propose TriPAH, a Tri-Prompt Affinity Hashing framework. TriPAH synthesizes ontology-grounded, patient-level prompts conditioned on normalized clinical cues to yield low-noise textual representations for initial alignment. A lightweight prompt-token mixer performs hierarchical, multi-granularity alignment and produces quantization-ready features under an asymmetric multi-task objective coupling multi-positive contrastive alignment, imbalance-aware classification, and progressive quantization regularization. A patient-level consistency module further stabilizes codes across complementary views. Extensive experiments on three public datasets demonstrate that TriPAH significantly outperforms state-of-the-art methods.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes TriPAH, a Tri-Prompt Affinity Hashing framework for cross-modal medical retrieval. It synthesizes ontology-grounded patient-level prompts conditioned on normalized clinical cues, employs a lightweight prompt-token mixer for hierarchical multi-granularity alignment and quantization-ready features, and optimizes under an asymmetric multi-task objective that couples multi-positive contrastive alignment, imbalance-aware classification, and progressive quantization regularization, plus a patient-level consistency module. The central claim is that extensive experiments on three public datasets show TriPAH significantly outperforms state-of-the-art methods.
Significance. If the experimental claims hold with proper ablations and statistical support, the approach could advance cross-modal hashing in medicine by mitigating semantic fragmentation from noisy clinical text and long-tailed labels. The combination of ontology-grounded prompts and the multi-task objective represents a potentially useful direction for improving alignment stability, though the lack of any reported metrics prevents evaluation of whether gains exceed what could be achieved by standard contrastive hashing baselines.
major comments (1)
- [Abstract] Abstract: The central claim that 'Extensive experiments on three public datasets demonstrate that TriPAH significantly outperforms state-of-the-art methods' is unsupported because the abstract (and provided manuscript text) supplies no quantitative results, ablation studies, error bars, dataset statistics, or training details. This absence is load-bearing for the outperformance assertion and prevents verification of whether reported gains arise from the proposed components or from dataset-specific fitting.
minor comments (1)
- [Abstract] Abstract: The phrase 'asymmetric multi-task objective' is introduced without any indication of how the three loss terms are weighted or combined, leaving the optimization procedure underspecified even at a high level.
Simulated Author's Rebuttal
We thank the referee for highlighting the lack of supporting quantitative evidence in the abstract. We agree this is a substantive issue that requires revision.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that 'Extensive experiments on three public datasets demonstrate that TriPAH significantly outperforms state-of-the-art methods' is unsupported because the abstract (and provided manuscript text) supplies no quantitative results, ablation studies, error bars, dataset statistics, or training details. This absence is load-bearing for the outperformance assertion and prevents verification of whether reported gains arise from the proposed components or from dataset-specific fitting.
Authors: We acknowledge that the provided manuscript text, including the abstract, contains no numerical results, ablations, error bars, dataset statistics, or training details, rendering the outperformance claim unsupported as written. We will revise the abstract to incorporate key quantitative metrics (e.g., mAP or recall improvements on the three datasets relative to baselines) drawn from the experimental sections, along with brief references to ablation findings and dataset characteristics. The full manuscript will be updated to ensure all supporting tables, statistics, and implementation details are clearly presented and cross-referenced from the abstract. revision: yes
Circularity Check
No significant circularity identified
full rationale
The provided abstract describes a proposed framework with ontology-grounded prompts and an asymmetric multi-task objective but contains no equations, parameter-fitting details, or self-citations. No derivation chain is visible that reduces predictions or results to inputs by construction. The central claim of outperformance on public datasets is presented as an empirical result without any indicated reduction to fitted parameters or self-referential definitions. This is the normal case of a self-contained method proposal where circularity cannot be assessed from the given text.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Multi-modal hashing for efficient multimedia retrieval: A survey,
L. Zhu, C. Zheng, W. Guan, J. Li, Y . Yang, and H. T. Shen, “Multi-modal hashing for efficient multimedia retrieval: A survey,”IEEE Trans. Knowl. Data Eng., vol. 36, no. 1, pp. 239–260, 2024
2024
-
[2]
Mimic-cxr, a de-identified publicly available database of chest radiographs with free-text reports,
A. E. W. Johnson, T. J. Pollard, S. J. Berkowitz, N. R. Greenbaum, M. P. Lungren, C.-Y . Deng, R. G. Mark, and S. Horng, “Mimic-cxr, a de-identified publicly available database of chest radiographs with free-text reports,”Sci. Data, vol. 6, no. 1, p. 317, 2019
2019
-
[3]
Large-scale long-tailed disease diagnosis on radiology images,
Q. Zheng, W. Zhao, C. Wuet al., “Large-scale long-tailed disease diagnosis on radiology images,”Nature Communications, vol. 15, no. 1, p. 10147, 2024
2024
-
[4]
Medclip: Contrastive learning from unpaired medical images and text,
Z. Wang, Z. Wu, D. Agarwal, and J. Sun, “Medclip: Contrastive learning from unpaired medical images and text,” inProceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, 2022, pp. 3876–3887
2022
-
[5]
Hashnet: Deep learning to hash by continuation,
Z. Cao, M. Long, J. Wang, and P. S. Yu, “Hashnet: Deep learning to hash by continuation,” inProc. IEEE Int. Conf. Comput. Vis. (ICCV), 2017, pp. 5609–5618
2017
-
[6]
Deep cross-modal hashing,
Q.-Y . Jiang and W.-J. Li, “Deep cross-modal hashing,” inProc. IEEE Conf. Comput. Vis. Pattern Recognit. (CVPR), 2017, pp. 3232–3240
2017
-
[7]
Differentiable cross- modal hashing via multimodal transformers,
J. Tu, X. Liu, Z. Lin, R. Hong, and M. Wang, “Differentiable cross- modal hashing via multimodal transformers,” inProc. ACM Int. Conf. Multimedia (ACM MM), 2022, pp. 453–461
2022
-
[8]
Multi-granularity interactive transformer hashing for cross-modal retrieval,
Y . Liu, Q. Wu, Z. Zhang, J. Zhang, and G. Lu, “Multi-granularity interactive transformer hashing for cross-modal retrieval,” inProc. ACM Int. Conf. Multimedia (ACM MM), 2023, pp. 893–902
2023
-
[9]
Deep semantic-aware proxy hashing for multi-label cross-modal retrieval,
Y . Huo, Q. Qin, J. Dai, L. Wang, W. Zhang, L. Huang, and C. Wang, “Deep semantic-aware proxy hashing for multi-label cross-modal retrieval,” IEEE Trans. Circuits Syst. Video Technol., vol. 34, no. 1, pp. 576–589, 2024
2024
-
[10]
Contrastive multi-bit collaborative learning for deep cross-modal hashing,
Q. Wu, Z. Zhang, Y . Liu, J. Zhang, and L. Nie, “Contrastive multi-bit collaborative learning for deep cross-modal hashing,”IEEE Trans. Knowl. Data Eng., vol. 36, no. 11, pp. 5835–5848, 2024
2024
-
[11]
Contrastive incomplete cross-modal hashing,
H. Luo, Z. Zhang, and L. Nie, “Contrastive incomplete cross-modal hashing,”IEEE Trans. Knowl. Data Eng., vol. 36, no. 11, pp. 5823–5834, 2024
2024
-
[12]
Multi-modal semantic feature alignment medical cross-modal hashing,
Q. Liu, Q. Wu, L. Tang, L. Xu, and Q. Chen, “Multi-modal semantic feature alignment medical cross-modal hashing,”Eng. Appl. Artif. Intell., vol. 157, p. 111158, 2025
2025
-
[13]
Medical cross-modal prompt hashing with robust noisy correspondence learning,
Y . Liu, Z. Wu, B. Chenet al., “Medical cross-modal prompt hashing with robust noisy correspondence learning,” inMedical Image Computing and Computer Assisted Intervention – MICCAI 2024, 2024, pp. 250–261
2024
-
[14]
Noisy correspondence learning with meta similarity correction,
H. Han, K. Miao, Q. Zheng, and M. Luo, “Noisy correspondence learning with meta similarity correction,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2023, pp. 7517–7526
2023
-
[15]
Ugncl: Uncertainty-guided noisy correspondence learning for efficient cross-modal matching,
Q. Zha, X. Liu, Y .-M. Cheunget al., “Ugncl: Uncertainty-guided noisy correspondence learning for efficient cross-modal matching,” in Proceedings of the International ACM SIGIR Conference on Research and Development in Information Retrieval, 2024, pp. 852–861
2024
-
[16]
Maple: Multi-modal prompt learning,
M. U. Khattak, H. Cholakkal, R. M. Anweret al., “Maple: Multi-modal prompt learning,” inProc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR), 2023, pp. 19 113–19 122
2023
-
[17]
S. Zhang, Y . Xu, N. Usuyamaet al., “Biomedclip: A multimodal biomedical foundation model pretrained from fifteen million scientific image-text pairs,”arXiv preprint arXiv:2303.00915, 2023
Pith/arXiv arXiv 2023
-
[18]
Prompthash: Affinity-prompted collaborative cross-modal learning for adaptive hashing retrieval,
Q. Zou, S. Cheng, and J. Chen, “Prompthash: Affinity-prompted collaborative cross-modal learning for adaptive hashing retrieval,” in Proc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR), 2025, pp. 19 649–19 658
2025
-
[19]
Odir-2019: Grand challenge on ocular disease intelligent recognition,
N. Li, T. Li, X. Liet al., “Odir-2019: Grand challenge on ocular disease intelligent recognition,” https://odir2019.grand-challenge.org/, 2019, accessed: 2025-01-01
2019
-
[20]
Preparing a collection of radiology examinations for distribution and retrieval,
D. Demner-Fushman, M. D. Kohli, M. B. Rosenmanet al., “Preparing a collection of radiology examinations for distribution and retrieval,” Journal of the American Medical Informatics Association, vol. 23, no. 2, pp. 304–310, 2016
2016
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.