Agent-Native Immune System: Architecture, Taxonomy, and Engineering
Pith reviewed 2026-06-29 03:48 UTC · model grok-4.3
The pith
The Agent-Native Immune System places biologically inspired defenses inside an AI agent's cognitive loop to handle runtime attacks that external measures miss.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We introduce the Agent-Native Immune System (ANIS), the first biologically inspired, endogenous defense architecture embedded directly within the agent's cognitive loop, with a six-layer Immune Tower, a taxonomy of Agent Viruses and Agent Vaccines, the Harness Triad for Continual Immune Learning, and a demarcation that treats alignment as a static constitutional foundation while ANIS acts as runtime law enforcement.
What carries the argument
The Harness Triad of Meta, Self, and Auto components, which supplies the self-monitoring and meta-cognitive automation backbone for Continual Immune Learning.
If this is right
- Vaccines adapt dynamically to novel threats through continual immune learning driven by the Harness Triad.
- Agents receive protection against runtime attacks including memory poisoning, tool-chain manipulation, and multi-agent protocol exploits.
- A clear separation holds between static training-time alignment and dynamic runtime immunity enforcement.
- New evaluation metrics such as the Autoimmunity Rate become relevant for measuring false-positive interventions.
- Immune protocol standardization and co-evolutionary dynamics between pathogens and vaccines emerge as open challenges in collective agent systems.
Where Pith is reading between the lines
- Embedding ANIS would require changes to how agent memory and tool interfaces are structured so that immune monitoring can operate inside the loop.
- In multi-agent environments the system could create feedback loops where one agent's immune response influences another's threat exposure.
- Practical deployment would need to test whether the non-cognitive Barrier Immunity layer at L1 actually isolates logical components from higher cognitive layers under attack.
Load-bearing premise
Current defense mechanisms such as perimeter security and training-time alignment remain external to the agent's active reasoning loop.
What would settle it
A controlled test in which an agent equipped with the full ANIS architecture, including the Immune Tower and Harness Triad, is successfully hijacked through memory poisoning or tool-chain manipulation.
Figures
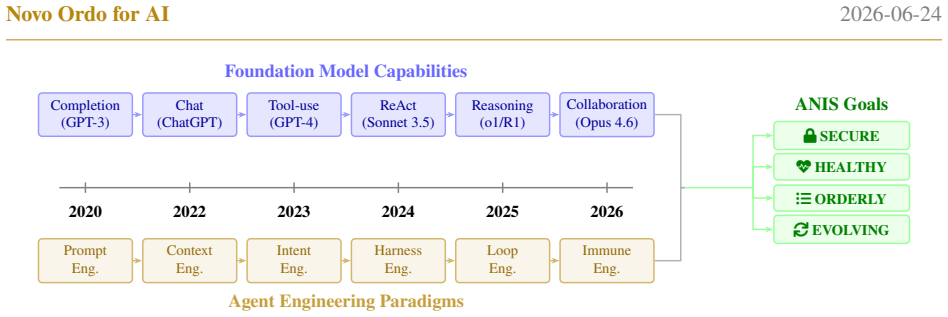
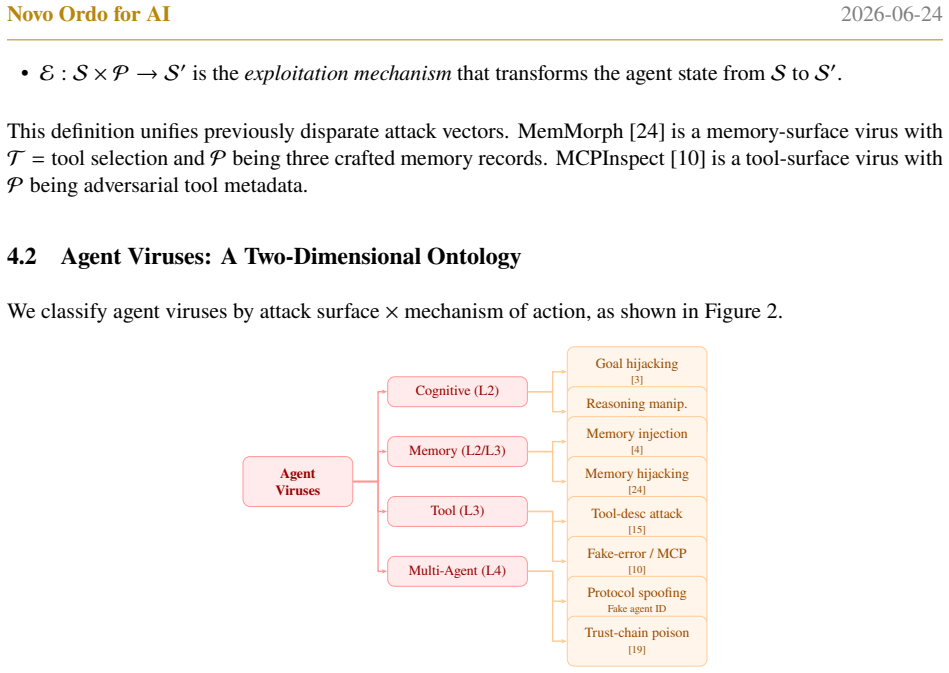

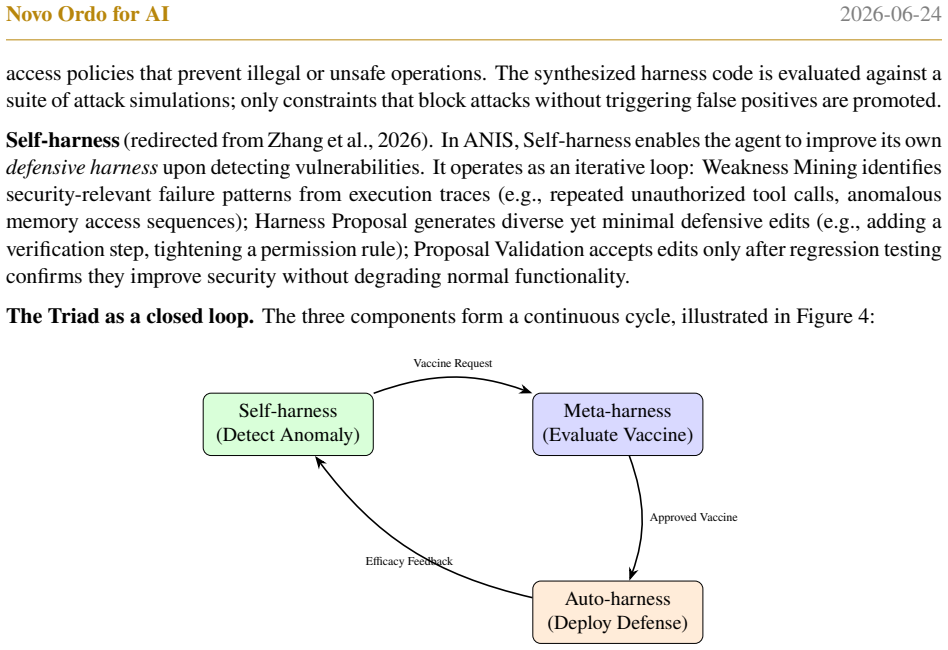
read the original abstract
The transition from static chat bots to autonomous agents--equipped with persistent memory, tool-use protocols, and multi-agent collaboration--has fundamentally expanded the AI threat landscape. Current defense mechanisms, such as perimeter security and training-time alignment, remain external to the agent's active reasoning loop. Consequently, they fall short: a fully aligned agent remains highly vulnerable to runtime hijacking via memory poisoning, tool-chain manipulation, or multi-agent protocol attacks. To address this critical gap, we introduce the Agent-Native Immune System (ANIS), the first biologically inspired, endogenous defense architecture embedded directly within the agent's cognitive loop. Our framework presents four primary contributions. First, we design a six-layer Immune Tower (L0-L5), distinctly incorporating Barrier Immunity (L1) as a non-cognitive, physical-and-logical isolation layer. Second, we establish a unified taxonomy of Agent Viruses and Agent Vaccines, formalizing the critical distinction between superficial non-parametric defenses and robust parametric vaccines. Third, we conceptualize the Harness Triad--Meta, Self, and Auto--a self-monitoring, meta-cognitive automation backbone that drives Continual Immune Learning (CIL), enabling vaccines to dynamically adapt to novel threats. Finally, we establish a rigorous theoretical demarcation between model alignment and agent immunity: while alignment provides a static "constitutional" value foundation during training, ANIS serves as the dynamic "law enforcement" mechanism during runtime. We conclude by framing open challenges for the field, including immune protocol standardization, novel evaluation metrics such as the Autoimmunity Rate (false-positive intervention rate), and the co-evolutionary dynamics between pathogens and vaccines within collective intelligence ecosystems.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to introduce the Agent-Native Immune System (ANIS) as the first biologically inspired endogenous defense architecture embedded in autonomous agents' cognitive loops. It presents a six-layer Immune Tower (L0-L5) with non-cognitive Barrier Immunity at L1, a taxonomy distinguishing Agent Viruses from parametric Agent Vaccines, the Harness Triad (Meta/Self/Auto) to drive Continual Immune Learning, and a demarcation of ANIS as runtime 'law enforcement' versus static training-time alignment. The work concludes with open challenges including immune protocol standardization and the Autoimmunity Rate metric.
Significance. If the architecture were concretely specified with integration mechanisms, data flows, and empirical validation showing superiority over external defenses against runtime attacks such as memory poisoning, it could meaningfully advance runtime security for tool-using and multi-agent systems. As a purely taxonomic proposal without such grounding, its significance is limited to suggesting a new conceptual framing rather than delivering a verifiable advance.
major comments (3)
- [Abstract] Abstract, first contribution: The claim that the six-layer Immune Tower is 'embedded directly within the agent's cognitive loop' as an endogenous runtime mechanism is not supported by any description of interfaces, observation points, or modification rules linking layers (including L1 Barrier Immunity) to the agent's persistent memory, tool invocations, or multi-agent protocols.
- [Abstract] Abstract, third contribution: The Harness Triad is asserted to drive Continual Immune Learning that enables dynamic vaccine adaptation, yet no algorithms, update rules, state representations, or data-flow diagrams are supplied for how Meta/Self/Auto components monitor or alter agent behavior at runtime.
- [Abstract] Abstract, final contribution: The 'rigorous theoretical demarcation' between model alignment (static constitutional foundation) and agent immunity (dynamic law enforcement) is stated without derivation, comparison to prior alignment or security literature, or formal criteria that would allow evaluation of the claimed distinction.
minor comments (1)
- The manuscript would benefit from explicit section numbering and subsection headings to allow precise citation of the taxonomy and architecture details.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our conceptual proposal for the Agent-Native Immune System. The comments accurately note that the manuscript focuses on high-level architecture and taxonomy rather than concrete implementations or empirical results. We will revise the paper to clarify these boundaries and expand explanatory elements where feasible.
read point-by-point responses
-
Referee: [Abstract] Abstract, first contribution: The claim that the six-layer Immune Tower is 'embedded directly within the agent's cognitive loop' as an endogenous runtime mechanism is not supported by any description of interfaces, observation points, or modification rules linking layers (including L1 Barrier Immunity) to the agent's persistent memory, tool invocations, or multi-agent protocols.
Authors: We agree that the current text presents the embedding at an architectural level without specifying interfaces or data flows. The manuscript's intent is to introduce the overall structure and the role of Barrier Immunity as a non-cognitive layer. In revision we will add a subsection describing candidate observation points and high-level integration patterns with memory, tools, and protocols, while explicitly noting that full protocol definitions remain future work. revision: yes
-
Referee: [Abstract] Abstract, third contribution: The Harness Triad is asserted to drive Continual Immune Learning that enables dynamic vaccine adaptation, yet no algorithms, update rules, state representations, or data-flow diagrams are supplied for how Meta/Self/Auto components monitor or alter agent behavior at runtime.
Authors: The Harness Triad is offered as a conceptual meta-cognitive backbone rather than an implemented controller. No concrete algorithms appear because the contribution centers on identifying the three components and their collective role in Continual Immune Learning. We will incorporate a high-level data-flow diagram and pseudocode sketches in the revised manuscript to illustrate the intended monitoring and adaptation loops. revision: yes
-
Referee: [Abstract] Abstract, final contribution: The 'rigorous theoretical demarcation' between model alignment (static constitutional foundation) and agent immunity (dynamic law enforcement) is stated without derivation, comparison to prior alignment or security literature, or formal criteria that would allow evaluation of the claimed distinction.
Authors: The demarcation is drawn from the timing distinction (training-time static values versus runtime dynamic enforcement) and is supported by brief references in the text. We accept that a more formal derivation and explicit comparison table would strengthen the claim. The revision will expand the related-work discussion, add citations to alignment and runtime-security literature, and include a side-by-side criteria table. revision: yes
Circularity Check
No significant circularity; conceptual taxonomy paper with no load-bearing derivations.
full rationale
The manuscript is a high-level architecture proposal that defines new terms (ANIS, six-layer Immune Tower, Agent Viruses/Vaccines taxonomy, Harness Triad, Autoimmunity Rate) and states distinctions such as alignment versus immunity. No equations, fitted parameters, predictions, or first-principles derivations appear in the abstract or described contributions. No self-citations are invoked as external justification for uniqueness theorems or ansatzes. The central claims rest on definitional introduction rather than any reduction of outputs to inputs by construction, satisfying the default expectation of no circularity for such papers.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Biological immune systems supply a transferable model for designing runtime defenses in AI agents
- domain assumption Runtime hijacking threats cannot be adequately addressed by external or training-time methods
invented entities (4)
-
Agent-Native Immune System (ANIS)
no independent evidence
-
Immune Tower (L0-L5) with Barrier Immunity (L1)
no independent evidence
-
Harness Triad (Meta, Self, Auto)
no independent evidence
-
Agent Viruses and Agent Vaccines
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Bowman, Zac Hatfield-Dodds,BenMann,DarioAmodei,NicholasJoseph,SamMcCandlish,TomBrown,andJared Kaplan
Yuntao Bai, Saurav Kadavath, Sandipan Kundu, Amanda Askell, Jackson Kernion, Andy Jones, Anna Chen, Anna Goldie, Azalia Mirhoseini, Cameron McKinnon, Carol Chen, Catherine Olsson, Danny 15 Novo Ordo for AI2026-06-24 Hernandez, Deep Drain, Dustin Ganguli, Eli Li, Ethan Tran-Johnson, Ethan Perez, Jamie Kerr, Jared Mueller, Joshua Ladish, Joshua Landau, Kama...
Pith/arXiv arXiv 2022
-
[2]
Varun Pratap Bhardwaj et al. Agent behavioral contracts: Formal runtime constraints for autonomous ai systems.arXiv preprint arXiv:2602.22302, 2026
arXiv 2026
-
[3]
Patrick Chao, Alexander Robey, Edgar Dobriban, Hamed Hassani, George J. Pappas, and Eric Wong. Jailbreaking black box large language models in twenty queries.arXiv preprint arXiv:2310.08419, 2024
Pith/arXiv arXiv 2024
-
[4]
Agentpoison: Red-teaming llm agents via memory and knowledge base injection
Zhen Chen et al. Agentpoison: Red-teaming llm agents via memory and knowledge base injection. In Advances in Neural Information Processing Systems (NeurIPS), volume 37, pages 1–15, 2024
2024
-
[5]
Hofmeyr, and Anil Somayaji
Stephanie Forrest, Steven A. Hofmeyr, and Anil Somayaji. A sense of self for unix processes. pages 120–128, 1997
1997
-
[6]
Yuxin Hou et al. Model context protocol (mcp): Landscape, security threats, and future research directions.arXiv preprint arXiv:2503.23278, 2025
Pith/arXiv arXiv 2025
-
[7]
Wenxin Hu et al. Lying with truths: Open-channel multi-agent collusion for belief manipulation via generative montage.arXiv preprint arXiv:2601.01685, 2026
Pith/arXiv arXiv 2026
-
[8]
Trustagent: Aframeworkforsafeandtrustworthyllm-basedagents
YansongHuaetal. Trustagent: Aframeworkforsafeandtrustworthyllm-basedagents. InProceedings of the AAAI Conference on Artificial Intelligence, volume 38, pages 1–10, 2024
2024
-
[9]
Meta-harness: End-to-end optimization of model harnesses.arXiv preprint arXiv:2603.28052, 2026
Jinhyuk Lee et al. Meta-harness: End-to-end optimization of model harnesses.arXiv preprint arXiv:2603.28052, 2026
Pith/arXiv arXiv 2026
-
[10]
Xinran Li et al. Mcpinspect: A systematic study of cross-entity security risks in the model context protocolecosystem.InProceedingsoftheACMSIGSACConferenceonComputerandCommunications Security (CCS), 2025. To appear
2025
-
[11]
Autoharness: Improving llm agents by automatically synthesizing a code harness
Jianning Lou et al. Autoharness: Improving llm agents by automatically synthesizing a code harness. arXiv preprint arXiv:2603.03329, 2026
arXiv 2026
-
[12]
Adam Massimo Mazzocchetti et al. Aegis: Cryptographic runtime governance for autonomous ai agents.arXiv preprint arXiv:2603.16938, 2026
arXiv 2026
-
[13]
Amplified vulnerabilities: Structured jailbreak attacks on llm-based multi-agent debate
Jiaqi Qi et al. Amplified vulnerabilities: Structured jailbreak attacks on llm-based multi-agent debate. arXiv preprint arXiv:2504.16489, 2025
arXiv 2025
-
[14]
Christian Schroeder de Witt et al. Open challenges in multi-agent security: Towards secure systems of interacting ai agents.arXiv preprint arXiv:2505.02077, 2025
Pith/arXiv arXiv 2025
-
[15]
Yujia Shi et al. Toolhijacker: Prompt injection attack to tool selection in llm agents.arXiv preprint arXiv:2504.19793, 2025
Pith/arXiv arXiv 2025
-
[16]
Say what you think: Unfaithful chain-of-thought explanations in llms
Miles Turpin et al. Say what you think: Unfaithful chain-of-thought explanations in llms. InAdvances in Neural Information Processing Systems (NeurIPS), volume 36, pages 1–15, 2023. 16 Novo Ordo for AI2026-06-24
2023
-
[17]
AnayVijayvargiyaetal. Openagentsafety: Aframeworkforevaluatingreal-worldaiagentsafety.arXiv preprint arXiv:2507.06134, 2026
arXiv 2026
-
[18]
V. V. Vishnyakova et al. From prompts to corporate multi-agent architecture: The intent engineering layer.arXiv preprint arXiv:2603.09619, 2026. To appear
arXiv 2026
-
[19]
JonasWeckbecker,PaulMüller,AmirHagag,andThomasMulet. Thoughtviruses: Viralmisalignment in multi-agent systems via subliminal prompting.arXiv preprint arXiv:2603.00131, 2026
arXiv 2026
-
[20]
Injecagent: Benchmarking indirect prompt injection in tool-integrated llm agents
Qinlin Zhan et al. Injecagent: Benchmarking indirect prompt injection in tool-integrated llm agents. InFindings of the Association for Computational Linguistics (ACL Findings), pages 1–15, 2024
2024
-
[21]
Agent security bench (asb): A comprehensive benchmark for real-world agent safety
Tianlin Zhang et al. Agent security bench (asb): A comprehensive benchmark for real-world agent safety. InInternational Conference on Learning Representations (ICLR), 2025. To appear
2025
-
[22]
Self-harness: Harnesses that improve themselves.arXiv preprint arXiv:2606.09498, 2026
Tianyuan Zhang et al. Self-harness: Harnesses that improve themselves.arXiv preprint arXiv:2606.09498, 2026
Pith/arXiv arXiv 2026
-
[23]
Wei Zhang et al. Hijackrag: Hijacking retrieval-augmented generation in llm agents.arXiv preprint arXiv:2410.22832, 2024
arXiv 2024
-
[24]
Memmorph: Memory poisoning for llm agents via structured record injection
Xuanye Zhang et al. Memmorph: Memory poisoning for llm agents via structured record injection. arXiv preprint arXiv:2605.26154, 2026
Pith/arXiv arXiv 2026
-
[25]
Mcpsecuritybench: Alarge-scalebenchmarkformodelcontextprotocolsecurity
YimingZhangetal. Mcpsecuritybench: Alarge-scalebenchmarkformodelcontextprotocolsecurity. InInternational Conference on Learning Representations (ICLR), 2026. To appear. 17
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.